
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
1 简介
在这个 colab 中,我们将使用线性混合效应回归模型拟合一个流行的玩具数据集。我们将使用 R 的 lme4、Stan 的混合效应包和 TensorFlow Probability (TFP) 原语进行三次拟合。最后,我们将展示所有三种方法都给出了大致相同的拟合参数和后验分布。
我们的主要结论是,TFP 拥有拟合类似 HLM 模型所需的通用组件,并且它产生的结果与其他软件包(即 lme4、rstanarm)一致。这个 colab 并没有准确反映所比较的任何包的计算效率。
%matplotlib inline
import os
from six.moves import urllib
import numpy as np
import pandas as pd
import warnings
from matplotlib import pyplot as plt
import seaborn as sns
from IPython.core.pylabtools import figsize
figsize(11, 9)
import tensorflow.compat.v1 as tf
import tensorflow_datasets as tfds
import tensorflow_probability as tfp
2 分层线性模型
为了比较 R、Stan 和 TFP,我们将使用 分层线性模型 (HLM) 拟合 氡数据集,该数据集在 贝叶斯数据分析,作者:Gelman 等人(第二版第 559 页;第三版第 250 页)中广为人知。
我们假设以下生成模型
\[\begin{align*} \text{for } & c=1\ldots \text{NumCounties}:\\ & \beta_c \sim \text{Normal}\left(\text{loc}=0, \text{scale}=\sigma_C \right) \\ \text{for } & i=1\ldots \text{NumSamples}:\\ &\eta_i = \underbrace{\omega_0 + \omega_1 \text{Floor}_i}_\text{固定效应} + \underbrace{\beta_{ \text{County}_i} \log( \text{UraniumPPM}_{\text{County}_i}))}_\text{随机效应} \\ &\log(\text{Radon}_i) \sim \text{Normal}(\text{loc}=\eta_i , \text{scale}=\sigma_N) \end{align*}\]
在 R 的 lme4 “波浪号符号” 中,此模型等效于
log_radon ~ 1 + floor + (0 + log_uranium_ppm | county)
我们将使用 \(\{\beta_c\}_{c=1}^\text{NumCounties}\) 的后验分布(以证据为条件)找到 \(\omega, \sigma_C, \sigma_N\) 的 MLE。
对于本质上相同的模型,但包含随机截距,请参见附录 A。
对于 HLM 的更一般规范,请参见附录 B。
3 数据整理
在本节中,我们将获取 radon 数据集,并进行一些最小的预处理,使其符合我们假设的模型。
def load_and_preprocess_radon_dataset(state='MN'):
"""Preprocess Radon dataset as done in "Bayesian Data Analysis" book.
We filter to Minnesota data (919 examples) and preprocess to obtain the
following features:
- `log_uranium_ppm`: Log of soil uranium measurements.
- `county`: Name of county in which the measurement was taken.
- `floor`: Floor of house (0 for basement, 1 for first floor) on which the
measurement was taken.
The target variable is `log_radon`, the log of the Radon measurement in the
house.
"""
ds = tfds.load('radon', split='train')
radon_data = tfds.as_dataframe(ds)
radon_data.rename(lambda s: s[9:] if s.startswith('feat') else s, axis=1, inplace=True)
df = radon_data[radon_data.state==state.encode()].copy()
# For any missing or invalid activity readings, we'll use a value of `0.1`.
df['radon'] = df.activity.apply(lambda x: x if x > 0. else 0.1)
# Make county names look nice.
df['county'] = df.county.apply(lambda s: s.decode()).str.strip().str.title()
# Remap categories to start from 0 and end at max(category).
county_name = sorted(df.county.unique())
df['county'] = df.county.astype(
pd.api.types.CategoricalDtype(categories=county_name)).cat.codes
county_name = list(map(str.strip, county_name))
df['log_radon'] = df['radon'].apply(np.log)
df['log_uranium_ppm'] = df['Uppm'].apply(np.log)
df = df[['idnum', 'log_radon', 'floor', 'county', 'log_uranium_ppm']]
return df, county_name
radon, county_name = load_and_preprocess_radon_dataset()
# We'll use the following directory to store our preprocessed dataset.
CACHE_DIR = os.path.join(os.sep, 'tmp', 'radon')
# Save processed data. (So we can later read it in R.)
if not tf.gfile.Exists(CACHE_DIR):
tf.gfile.MakeDirs(CACHE_DIR)
with tf.gfile.Open(os.path.join(CACHE_DIR, 'radon.csv'), 'w') as f:
radon.to_csv(f, index=False)
3.1 了解您的数据
在本节中,我们将探索 radon 数据集,以更好地了解为什么提出的模型可能是合理的。
radon.head()
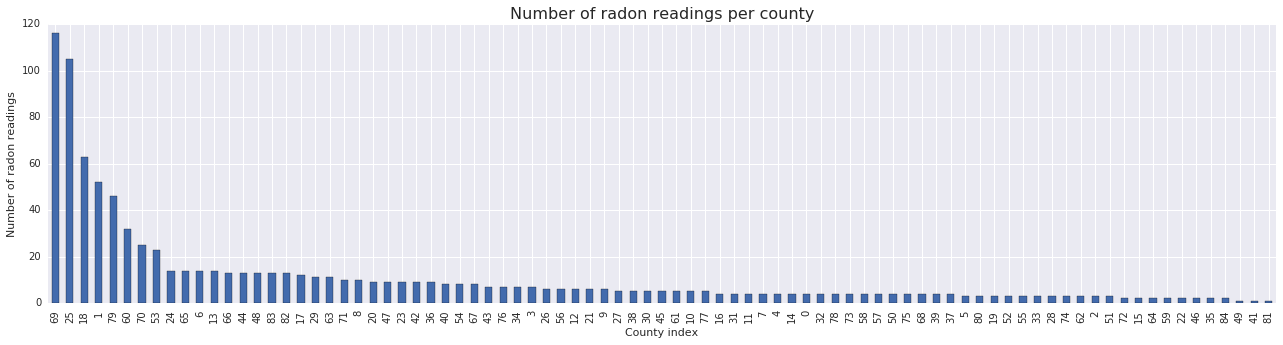
fig, ax = plt.subplots(figsize=(22, 5));
county_freq = radon['county'].value_counts()
county_freq.plot(kind='bar', color='#436bad');
plt.xlabel('County index')
plt.ylabel('Number of radon readings')
plt.title('Number of radon readings per county', fontsize=16)
county_freq = np.array(zip(county_freq.index, county_freq.values)) # We'll use this later.
fig, ax = plt.subplots(ncols=2, figsize=[10, 4]);
radon['log_radon'].plot(kind='density', ax=ax[0]);
ax[0].set_xlabel('log(radon)')
radon['floor'].value_counts().plot(kind='bar', ax=ax[1]);
ax[1].set_xlabel('Floor');
ax[1].set_ylabel('Count');
fig.subplots_adjust(wspace=0.25)
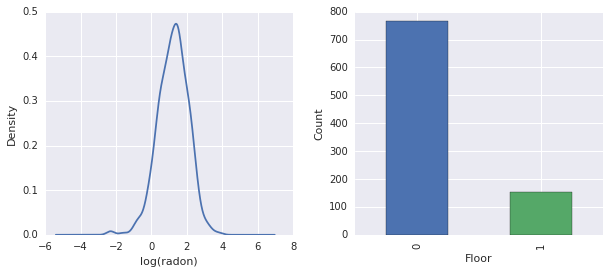
结论
- 有 85 个县的尾部很长。(在 GLMM 中很常见。)
- 实际上,\(\log(\text{Radon})\) 是无约束的。(因此线性回归可能是有意义的。)
- 读数主要是在第 \(0\) 层进行的;没有读数是在第 \(1\) 层以上的。(因此我们的固定效应将只有两个权重。)
4 R 中的 HLM
在本节中,我们将使用 R 的 lme4 包拟合上面描述的概率模型。
suppressMessages({
library('bayesplot')
library('data.table')
library('dplyr')
library('gfile')
library('ggplot2')
library('lattice')
library('lme4')
library('plyr')
library('rstanarm')
library('tidyverse')
RequireInitGoogle()
})
data = read_csv(gfile::GFile('/tmp/radon/radon.csv'))
Parsed with column specification: cols( log_radon = col_double(), floor = col_integer(), county = col_integer(), log_uranium_ppm = col_double() )
head(data)
# A tibble: 6 x 4
log_radon floor county log_uranium_ppm
<dbl> <int> <int> <dbl>
1 0.788 1 0 -0.689
2 0.788 0 0 -0.689
3 1.06 0 0 -0.689
4 0 0 0 -0.689
5 1.13 0 1 -0.847
6 0.916 0 1 -0.847
# https://github.com/stan-dev/example-models/wiki/ARM-Models-Sorted-by-Chapter
radon.model <- lmer(log_radon ~ 1 + floor + (0 + log_uranium_ppm | county), data = data)
summary(radon.model)
Linear mixed model fit by REML ['lmerMod']
Formula: log_radon ~ 1 + floor + (0 + log_uranium_ppm | county)
Data: data
REML criterion at convergence: 2166.3
Scaled residuals:
Min 1Q Median 3Q Max
-4.5202 -0.6064 0.0107 0.6334 3.4111
Random effects:
Groups Name Variance Std.Dev.
county log_uranium_ppm 0.7545 0.8686
Residual 0.5776 0.7600
Number of obs: 919, groups: county, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.47585 0.03899 37.85
floor -0.67974 0.06963 -9.76
Correlation of Fixed Effects:
(Intr)
floor -0.330
qqmath(ranef(radon.model, condVar=TRUE))
$county
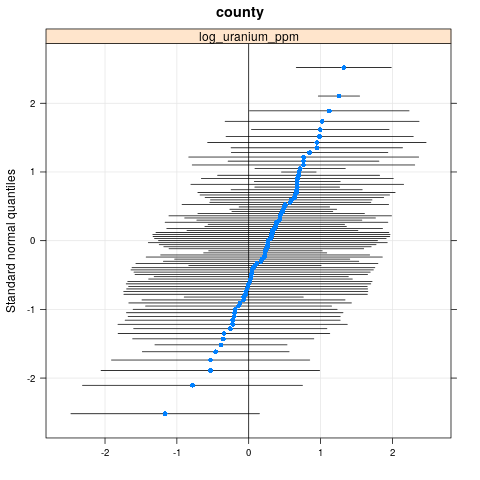
write.csv(as.data.frame(ranef(radon.model, condVar = TRUE)), '/tmp/radon/lme4_fit.csv')
5 Stan 中的 HLM
在本节中,我们将使用 rstanarm 使用与上面 lme4 模型相同的公式/语法拟合 Stan 模型。
与 lme4 和下面的 TF 模型不同,rstanarm 是一个完全贝叶斯模型,即所有参数都被假定从一个正态分布中抽取,而参数本身又从一个分布中抽取。
fit <- stan_lmer(log_radon ~ 1 + floor + (0 + log_uranium_ppm | county), data = data)
SAMPLING FOR MODEL 'continuous' NOW (CHAIN 1).
Chain 1, Iteration: 1 / 2000 [ 0%] (Warmup)
Chain 1, Iteration: 200 / 2000 [ 10%] (Warmup)
Chain 1, Iteration: 400 / 2000 [ 20%] (Warmup)
Chain 1, Iteration: 600 / 2000 [ 30%] (Warmup)
Chain 1, Iteration: 800 / 2000 [ 40%] (Warmup)
Chain 1, Iteration: 1000 / 2000 [ 50%] (Warmup)
Chain 1, Iteration: 1001 / 2000 [ 50%] (Sampling)
Chain 1, Iteration: 1200 / 2000 [ 60%] (Sampling)
Chain 1, Iteration: 1400 / 2000 [ 70%] (Sampling)
Chain 1, Iteration: 1600 / 2000 [ 80%] (Sampling)
Chain 1, Iteration: 1800 / 2000 [ 90%] (Sampling)
Chain 1, Iteration: 2000 / 2000 [100%] (Sampling)
Elapsed Time: 7.73495 seconds (Warm-up)
2.98852 seconds (Sampling)
10.7235 seconds (Total)
SAMPLING FOR MODEL 'continuous' NOW (CHAIN 2).
Chain 2, Iteration: 1 / 2000 [ 0%] (Warmup)
Chain 2, Iteration: 200 / 2000 [ 10%] (Warmup)
Chain 2, Iteration: 400 / 2000 [ 20%] (Warmup)
Chain 2, Iteration: 600 / 2000 [ 30%] (Warmup)
Chain 2, Iteration: 800 / 2000 [ 40%] (Warmup)
Chain 2, Iteration: 1000 / 2000 [ 50%] (Warmup)
Chain 2, Iteration: 1001 / 2000 [ 50%] (Sampling)
Chain 2, Iteration: 1200 / 2000 [ 60%] (Sampling)
Chain 2, Iteration: 1400 / 2000 [ 70%] (Sampling)
Chain 2, Iteration: 1600 / 2000 [ 80%] (Sampling)
Chain 2, Iteration: 1800 / 2000 [ 90%] (Sampling)
Chain 2, Iteration: 2000 / 2000 [100%] (Sampling)
Elapsed Time: 7.51252 seconds (Warm-up)
3.08653 seconds (Sampling)
10.5991 seconds (Total)
SAMPLING FOR MODEL 'continuous' NOW (CHAIN 3).
Chain 3, Iteration: 1 / 2000 [ 0%] (Warmup)
Chain 3, Iteration: 200 / 2000 [ 10%] (Warmup)
Chain 3, Iteration: 400 / 2000 [ 20%] (Warmup)
Chain 3, Iteration: 600 / 2000 [ 30%] (Warmup)
Chain 3, Iteration: 800 / 2000 [ 40%] (Warmup)
Chain 3, Iteration: 1000 / 2000 [ 50%] (Warmup)
Chain 3, Iteration: 1001 / 2000 [ 50%] (Sampling)
Chain 3, Iteration: 1200 / 2000 [ 60%] (Sampling)
Chain 3, Iteration: 1400 / 2000 [ 70%] (Sampling)
Chain 3, Iteration: 1600 / 2000 [ 80%] (Sampling)
Chain 3, Iteration: 1800 / 2000 [ 90%] (Sampling)
Chain 3, Iteration: 2000 / 2000 [100%] (Sampling)
Elapsed Time: 8.14628 seconds (Warm-up)
3.01001 seconds (Sampling)
11.1563 seconds (Total)
SAMPLING FOR MODEL 'continuous' NOW (CHAIN 4).
Chain 4, Iteration: 1 / 2000 [ 0%] (Warmup)
Chain 4, Iteration: 200 / 2000 [ 10%] (Warmup)
Chain 4, Iteration: 400 / 2000 [ 20%] (Warmup)
Chain 4, Iteration: 600 / 2000 [ 30%] (Warmup)
Chain 4, Iteration: 800 / 2000 [ 40%] (Warmup)
Chain 4, Iteration: 1000 / 2000 [ 50%] (Warmup)
Chain 4, Iteration: 1001 / 2000 [ 50%] (Sampling)
Chain 4, Iteration: 1200 / 2000 [ 60%] (Sampling)
Chain 4, Iteration: 1400 / 2000 [ 70%] (Sampling)
Chain 4, Iteration: 1600 / 2000 [ 80%] (Sampling)
Chain 4, Iteration: 1800 / 2000 [ 90%] (Sampling)
Chain 4, Iteration: 2000 / 2000 [100%] (Sampling)
Elapsed Time: 7.6801 seconds (Warm-up)
3.23663 seconds (Sampling)
10.9167 seconds (Total)
fit
stan_lmer(formula = log_radon ~ 1 + floor + (0 + log_uranium_ppm |
county), data = data)
Estimates:
Median MAD_SD
(Intercept) 1.5 0.0
floor -0.7 0.1
sigma 0.8 0.0
Error terms:
Groups Name Std.Dev.
county log_uranium_ppm 0.87
Residual 0.76
Num. levels: county 85
Sample avg. posterior predictive
distribution of y (X = xbar):
Median MAD_SD
mean_PPD 1.2 0.0
Observations: 919 Number of unconstrained parameters: 90
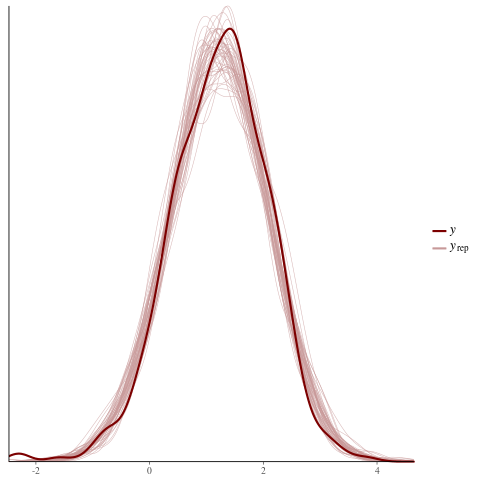
color_scheme_set("red")
ppc_dens_overlay(y = fit$y,
yrep = posterior_predict(fit, draws = 50))
color_scheme_set("brightblue")
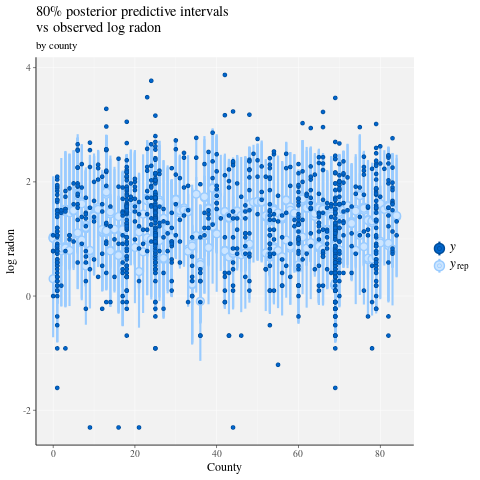
ppc_intervals(
y = data$log_radon,
yrep = posterior_predict(fit),
x = data$county,
prob = 0.8
) +
labs(
x = "County",
y = "log radon",
title = "80% posterior predictive intervals \nvs observed log radon",
subtitle = "by county"
) +
panel_bg(fill = "gray95", color = NA) +
grid_lines(color = "white")
# Write the posterior samples (4000 for each variable) to a CSV.
write.csv(tidy(as.matrix(fit)), "/tmp/radon/stan_fit.csv")
with tf.gfile.Open('/tmp/radon/lme4_fit.csv', 'r') as f:
lme4_fit = pd.read_csv(f, index_col=0)
lme4_fit.head()
检索 lme4 中组随机效应的点估计和条件标准差,以便稍后进行可视化。
posterior_random_weights_lme4 = np.array(lme4_fit.condval, dtype=np.float32)
lme4_prior_scale = np.array(lme4_fit.condsd, dtype=np.float32)
print(posterior_random_weights_lme4.shape, lme4_prior_scale.shape)
(85,) (85,)
使用 lme4 估计的均值和标准差绘制县权重样本。
with tf.Session() as sess:
lme4_dist = tfp.distributions.Independent(
tfp.distributions.Normal(
loc=posterior_random_weights_lme4,
scale=lme4_prior_scale),
reinterpreted_batch_ndims=1)
posterior_random_weights_lme4_final_ = sess.run(lme4_dist.sample(4000))
posterior_random_weights_lme4_final_.shape
(4000, 85)
我们还从 Stan 拟合中检索县权重的后验样本。
with tf.gfile.Open('/tmp/radon/stan_fit.csv', 'r') as f:
samples = pd.read_csv(f, index_col=0)
samples.head()
posterior_random_weights_cols = [
col for col in samples.columns if 'b.log_uranium_ppm.county' in col
]
posterior_random_weights_final_stan = samples[
posterior_random_weights_cols].values
print(posterior_random_weights_final_stan.shape)
(4000, 85)
这个 Stan 示例展示了如何以更接近 TFP 的风格实现 LMER,即通过直接指定概率模型。
6 TF 概率中的 HLM
在本节中,我们将使用低级 TensorFlow Probability 原语(Distributions)来指定我们的分层线性模型以及拟合未知参数。
# Handy snippet to reset the global graph and global session.
with warnings.catch_warnings():
warnings.simplefilter('ignore')
tf.reset_default_graph()
try:
sess.close()
except:
pass
sess = tf.InteractiveSession()
6.1 指定模型
在本节中,我们使用 TFP 原语指定了氡线性混合效应模型。为此,我们指定了两个函数,它们生成两个 TFP 分布
make_weights_prior:随机权重的多元正态先验(这些权重乘以 \(\log(\text{UraniumPPM}_{c_i})\) 来计算线性预测器)。make_log_radon_likelihood:每个观察到的 \(\log(\text{Radon}_i)\) 因变量上的Normal分布批次。
由于我们将拟合这些分布中的每一个的参数,因此我们必须使用 TF 变量(即 tf.get_variable)。但是,由于我们希望使用无约束优化,因此我们必须找到一种方法来约束实数值以实现必要的语义,例如表示标准差的正值。
inv_scale_transform = lambda y: np.log(y) # Not using TF here.
fwd_scale_transform = tf.exp
以下函数构建了我们的先验,\(p(\beta|\sigma_C)\),其中 \(\beta\) 表示随机效应权重,\(\sigma_C\) 表示标准差。
我们使用 tf.make_template 来确保对该函数的第一次调用实例化它使用的 TF 变量,并且所有后续调用都重用变量的当前值。
def _make_weights_prior(num_counties, dtype):
"""Returns a `len(log_uranium_ppm)` batch of univariate Normal."""
raw_prior_scale = tf.get_variable(
name='raw_prior_scale',
initializer=np.array(inv_scale_transform(1.), dtype=dtype))
return tfp.distributions.Independent(
tfp.distributions.Normal(
loc=tf.zeros(num_counties, dtype=dtype),
scale=fwd_scale_transform(raw_prior_scale)),
reinterpreted_batch_ndims=1)
make_weights_prior = tf.make_template(
name_='make_weights_prior', func_=_make_weights_prior)
以下函数构建了我们的似然,\(p(y|x,\omega,\beta,\sigma_N)\),其中 \(y,x\) 表示响应和证据,\(\omega,\beta\) 表示固定效应和随机效应权重,\(\sigma_N\) 表示标准差。
在这里,我们再次使用 tf.make_template 来确保 TF 变量在调用之间被重用。
def _make_log_radon_likelihood(random_effect_weights, floor, county,
log_county_uranium_ppm, init_log_radon_stddev):
raw_likelihood_scale = tf.get_variable(
name='raw_likelihood_scale',
initializer=np.array(
inv_scale_transform(init_log_radon_stddev), dtype=dtype))
fixed_effect_weights = tf.get_variable(
name='fixed_effect_weights', initializer=np.array([0., 1.], dtype=dtype))
fixed_effects = fixed_effect_weights[0] + fixed_effect_weights[1] * floor
random_effects = tf.gather(
random_effect_weights * log_county_uranium_ppm,
indices=tf.to_int32(county),
axis=-1)
linear_predictor = fixed_effects + random_effects
return tfp.distributions.Normal(
loc=linear_predictor, scale=fwd_scale_transform(raw_likelihood_scale))
make_log_radon_likelihood = tf.make_template(
name_='make_log_radon_likelihood', func_=_make_log_radon_likelihood)
最后,我们使用先验和似然生成器来构建联合对数密度。
def joint_log_prob(random_effect_weights, log_radon, floor, county,
log_county_uranium_ppm, dtype):
num_counties = len(log_county_uranium_ppm)
rv_weights = make_weights_prior(num_counties, dtype)
rv_radon = make_log_radon_likelihood(
random_effect_weights,
floor,
county,
log_county_uranium_ppm,
init_log_radon_stddev=radon.log_radon.values.std())
return (rv_weights.log_prob(random_effect_weights)
+ tf.reduce_sum(rv_radon.log_prob(log_radon), axis=-1))
6.2 训练(期望最大化算法的随机近似)
为了拟合我们的线性混合效应回归模型,我们将使用期望最大化算法(SAEM)的随机近似版本。基本思想是使用后验样本近似期望联合对数密度(E 步)。然后,我们找到使此计算最大化的参数(M 步)。更具体地说,不动点迭代由下式给出
\[\begin{align*} \text{E}[ \log p(x, Z | \theta) | \theta_0] &\approx \frac{1}{M} \sum_{m=1}^M \log p(x, z_m | \theta), \quad Z_m\sim p(Z | x, \theta_0) && \text{E-step}\\ &=: Q_M(\theta, \theta_0) \\ \theta_0 &= \theta_0 - \eta \left.\nabla_\theta Q_M(\theta, \theta_0)\right|_{\theta=\theta_0} && \text{M-step} \end{align*}\]
其中 \(x\) 表示证据,\(Z\) 表示需要边缘化的某些潜在变量,\(\theta,\theta_0\) 表示可能的参数化。
有关更详细的解释,请参阅 EM 算法的随机近似版本的收敛性,作者为 Bernard Delyon、Marc Lavielle、Eric、Moulines(Ann. Statist.,1999)。
为了计算 E 步,我们需要从后验中采样。由于我们的后验不容易采样,因此我们使用哈密顿蒙特卡罗(HMC)。HMC 是一种蒙特卡罗马尔可夫链过程,它使用未归一化后验对数密度的梯度(相对于状态,而不是参数)来提出新的样本。
指定未归一化后验对数密度很简单——它仅仅是联合对数密度“固定”在我们想要条件化的任何地方。
# Specify unnormalized posterior.
dtype = np.float32
log_county_uranium_ppm = radon[
['county', 'log_uranium_ppm']].drop_duplicates().values[:, 1]
log_county_uranium_ppm = log_county_uranium_ppm.astype(dtype)
def unnormalized_posterior_log_prob(random_effect_weights):
return joint_log_prob(
random_effect_weights=random_effect_weights,
log_radon=dtype(radon.log_radon.values),
floor=dtype(radon.floor.values),
county=np.int32(radon.county.values),
log_county_uranium_ppm=log_county_uranium_ppm,
dtype=dtype)
我们现在通过创建 HMC 转换内核来完成 E 步设置。
注意
我们使用
state_stop_gradient=True来防止 M 步反向传播通过从 MCMC 中绘制的样本。(回想一下,我们不需要反向传播,因为我们的 E 步有意地参数化在先前的最佳已知估计器处。)我们使用
tf.placeholder,以便当我们最终执行我们的 TF 图时,我们可以将前一次迭代的随机 MCMC 样本作为下一次迭代的链的值馈送。我们使用 TFP 的自适应
step_size启发式方法,tfp.mcmc.hmc_step_size_update_fn。
# Set-up E-step.
step_size = tf.get_variable(
'step_size',
initializer=np.array(0.2, dtype=dtype),
trainable=False)
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unnormalized_posterior_log_prob,
num_leapfrog_steps=2,
step_size=step_size,
step_size_update_fn=tfp.mcmc.make_simple_step_size_update_policy(
num_adaptation_steps=None),
state_gradients_are_stopped=True)
init_random_weights = tf.placeholder(dtype, shape=[len(log_county_uranium_ppm)])
posterior_random_weights, kernel_results = tfp.mcmc.sample_chain(
num_results=3,
num_burnin_steps=0,
num_steps_between_results=0,
current_state=init_random_weights,
kernel=hmc)
我们现在设置 M 步。这本质上与您可能在 TF 中执行的优化相同。
# Set-up M-step.
loss = -tf.reduce_mean(kernel_results.accepted_results.target_log_prob)
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.train.exponential_decay(
learning_rate=0.1,
global_step=global_step,
decay_steps=2,
decay_rate=0.99)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss, global_step=global_step)
我们以一些家务事结束。我们必须告诉 TF 所有变量都已初始化。我们还创建了我们 TF 变量的句柄,以便我们可以在过程的每次迭代中print 它们的值。
# Initialize all variables.
init_op = tf.initialize_all_variables()
# Grab variable handles for diagnostic purposes.
with tf.variable_scope('make_weights_prior', reuse=True):
prior_scale = fwd_scale_transform(tf.get_variable(
name='raw_prior_scale', dtype=dtype))
with tf.variable_scope('make_log_radon_likelihood', reuse=True):
likelihood_scale = fwd_scale_transform(tf.get_variable(
name='raw_likelihood_scale', dtype=dtype))
fixed_effect_weights = tf.get_variable(
name='fixed_effect_weights', dtype=dtype)
6.3 执行
在本节中,我们执行我们的 SAEM TF 图。这里的主要技巧是将我们从 HMC 内核中最后绘制的样本馈送到下一次迭代。这是通过我们在 sess.run 调用中使用 feed_dict 实现的。
init_op.run()
w_ = np.zeros([len(log_county_uranium_ppm)], dtype=dtype)
%%time
maxiter = int(1500)
num_accepted = 0
num_drawn = 0
for i in range(maxiter):
[
_,
global_step_,
loss_,
posterior_random_weights_,
kernel_results_,
step_size_,
prior_scale_,
likelihood_scale_,
fixed_effect_weights_,
] = sess.run([
train_op,
global_step,
loss,
posterior_random_weights,
kernel_results,
step_size,
prior_scale,
likelihood_scale,
fixed_effect_weights,
], feed_dict={init_random_weights: w_})
w_ = posterior_random_weights_[-1, :]
num_accepted += kernel_results_.is_accepted.sum()
num_drawn += kernel_results_.is_accepted.size
acceptance_rate = num_accepted / num_drawn
if i % 100 == 0 or i == maxiter - 1:
print('global_step:{:>4} loss:{: 9.3f} acceptance:{:.4f} '
'step_size:{:.4f} prior_scale:{:.4f} likelihood_scale:{:.4f} '
'fixed_effect_weights:{}'.format(
global_step_, loss_.mean(), acceptance_rate, step_size_,
prior_scale_, likelihood_scale_, fixed_effect_weights_))
global_step: 0 loss: 1966.948 acceptance:1.0000 step_size:0.2000 prior_scale:1.0000 likelihood_scale:0.8529 fixed_effect_weights:[ 0. 1.] global_step: 100 loss: 1165.385 acceptance:0.6205 step_size:0.2040 prior_scale:0.9568 likelihood_scale:0.7611 fixed_effect_weights:[ 1.47523439 -0.66043079] global_step: 200 loss: 1149.851 acceptance:0.6766 step_size:0.2081 prior_scale:0.7465 likelihood_scale:0.7665 fixed_effect_weights:[ 1.48918796 -0.67058587] global_step: 300 loss: 1163.464 acceptance:0.6811 step_size:0.2040 prior_scale:0.8445 likelihood_scale:0.7594 fixed_effect_weights:[ 1.46291411 -0.67586178] global_step: 400 loss: 1158.846 acceptance:0.6808 step_size:0.2081 prior_scale:0.8377 likelihood_scale:0.7574 fixed_effect_weights:[ 1.47349834 -0.68823022] global_step: 500 loss: 1154.193 acceptance:0.6766 step_size:0.1961 prior_scale:0.8546 likelihood_scale:0.7564 fixed_effect_weights:[ 1.47703862 -0.67521363] global_step: 600 loss: 1163.903 acceptance:0.6783 step_size:0.2040 prior_scale:0.9491 likelihood_scale:0.7587 fixed_effect_weights:[ 1.48268366 -0.69667786] global_step: 700 loss: 1163.894 acceptance:0.6767 step_size:0.1961 prior_scale:0.8644 likelihood_scale:0.7617 fixed_effect_weights:[ 1.4719094 -0.66897118] global_step: 800 loss: 1153.689 acceptance:0.6742 step_size:0.2123 prior_scale:0.8366 likelihood_scale:0.7609 fixed_effect_weights:[ 1.47345769 -0.68343043] global_step: 900 loss: 1155.312 acceptance:0.6718 step_size:0.2040 prior_scale:0.8633 likelihood_scale:0.7581 fixed_effect_weights:[ 1.47426116 -0.6748783 ] global_step:1000 loss: 1151.278 acceptance:0.6690 step_size:0.2081 prior_scale:0.8737 likelihood_scale:0.7581 fixed_effect_weights:[ 1.46990883 -0.68891817] global_step:1100 loss: 1156.858 acceptance:0.6676 step_size:0.2040 prior_scale:0.8716 likelihood_scale:0.7584 fixed_effect_weights:[ 1.47386014 -0.6796245 ] global_step:1200 loss: 1166.247 acceptance:0.6653 step_size:0.2000 prior_scale:0.8748 likelihood_scale:0.7588 fixed_effect_weights:[ 1.47389269 -0.67626756] global_step:1300 loss: 1165.263 acceptance:0.6636 step_size:0.2040 prior_scale:0.8771 likelihood_scale:0.7581 fixed_effect_weights:[ 1.47612262 -0.67752427] global_step:1400 loss: 1158.108 acceptance:0.6640 step_size:0.2040 prior_scale:0.8748 likelihood_scale:0.7587 fixed_effect_weights:[ 1.47534692 -0.6789524 ] global_step:1499 loss: 1161.030 acceptance:0.6638 step_size:0.1941 prior_scale:0.8738 likelihood_scale:0.7589 fixed_effect_weights:[ 1.47624075 -0.67875224] CPU times: user 1min 16s, sys: 17.6 s, total: 1min 33s Wall time: 27.9 s
看起来在约 1500 步之后,我们对参数的估计已经稳定下来。
6.4 结果
现在我们已经拟合了参数,让我们生成大量后验样本并研究结果。
%%time
posterior_random_weights_final, kernel_results_final = tfp.mcmc.sample_chain(
num_results=int(15e3),
num_burnin_steps=int(1e3),
current_state=init_random_weights,
kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unnormalized_posterior_log_prob,
num_leapfrog_steps=2,
step_size=step_size))
[
posterior_random_weights_final_,
kernel_results_final_,
] = sess.run([
posterior_random_weights_final,
kernel_results_final,
], feed_dict={init_random_weights: w_})
CPU times: user 1min 42s, sys: 26.6 s, total: 2min 8s Wall time: 35.1 s
print('prior_scale: ', prior_scale_)
print('likelihood_scale: ', likelihood_scale_)
print('fixed_effect_weights: ', fixed_effect_weights_)
print('acceptance rate final: ', kernel_results_final_.is_accepted.mean())
prior_scale: 0.873799 likelihood_scale: 0.758913 fixed_effect_weights: [ 1.47624075 -0.67875224] acceptance rate final: 0.7448
我们现在构建 \(\beta_c \log(\text{UraniumPPM}_c)\) 随机效应的箱线图。我们将按县频率递减的顺序排列随机效应。
x = posterior_random_weights_final_ * log_county_uranium_ppm
I = county_freq[:, 0]
x = x[:, I]
cols = np.array(county_name)[I]
pw = pd.DataFrame(x)
pw.columns = cols
fig, ax = plt.subplots(figsize=(25, 4))
ax = pw.boxplot(rot=80, vert=True);
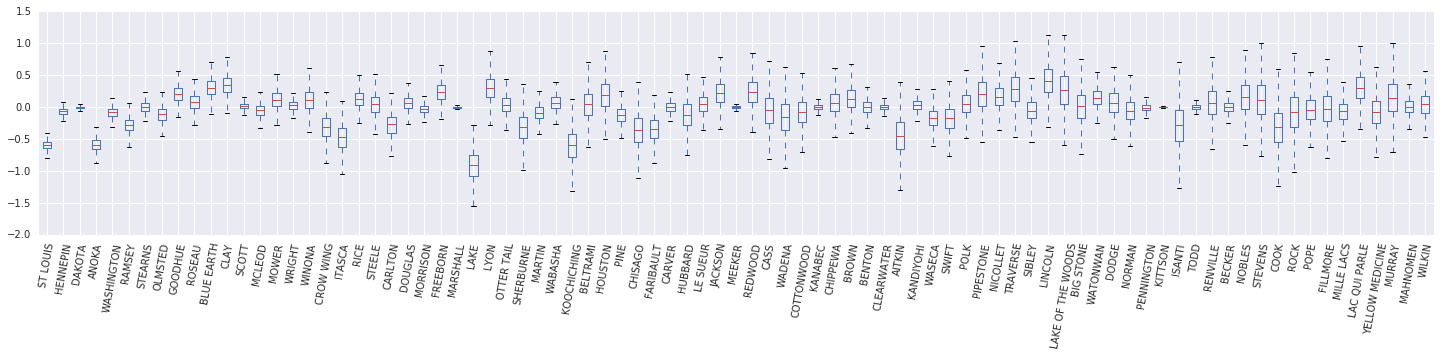
从这个箱线图中,我们观察到县级 \(\log(\text{UraniumPPM})\) 随机效应的方差随着县在数据集中所占比例的减少而增加。直观地说,这是有道理的——如果我们对某个县的证据较少,那么我们对该县的影响应该不太确定。
7 逐个比较
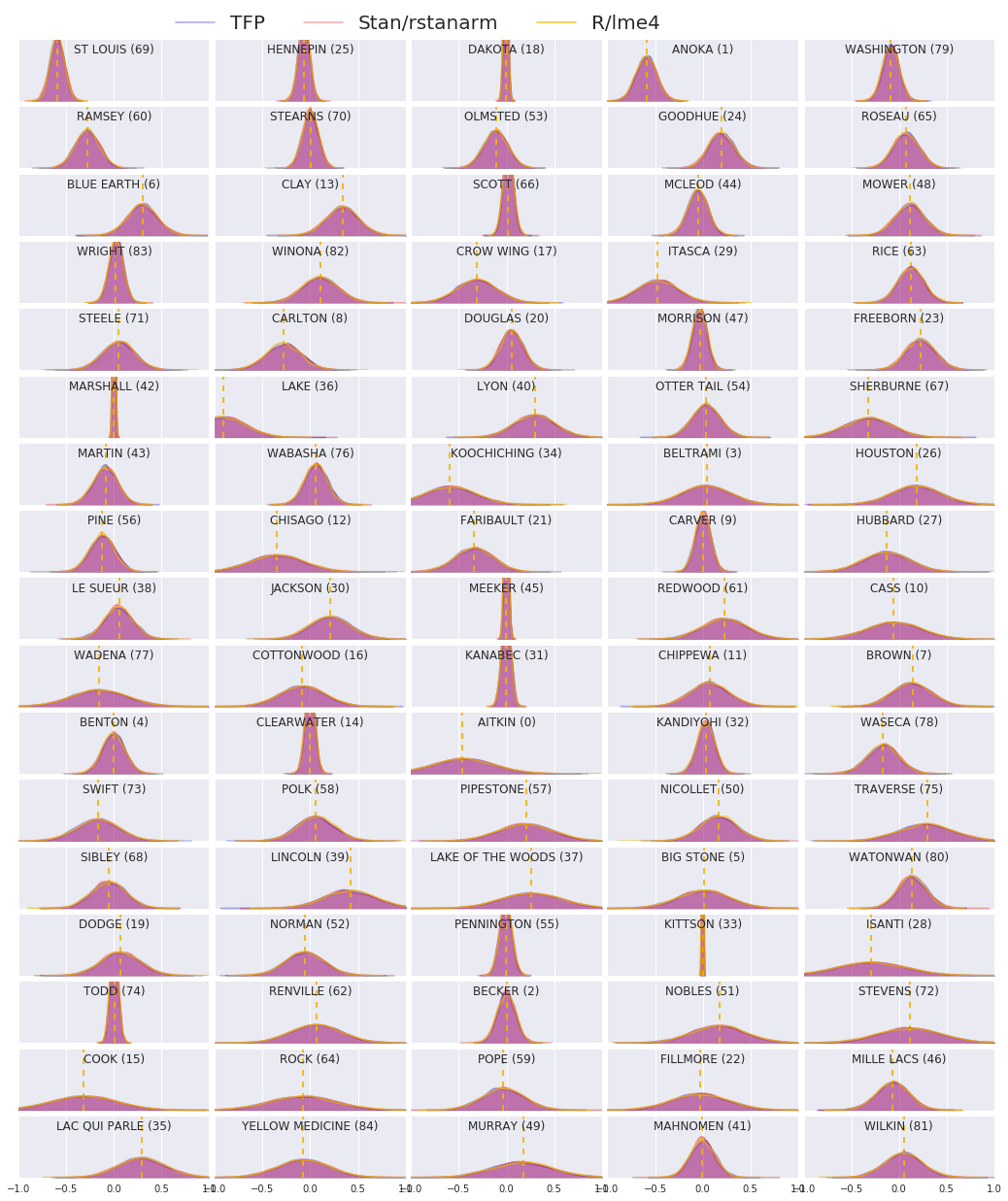
我们现在比较所有三种过程的结果。为此,我们将计算 Stan 和 TFP 生成的后验样本的非参数估计。我们还将与 R 的 lme4 包生成的参数(近似)估计进行比较。
以下图示了明尼苏达州每个县的每个权重的后验分布。我们展示了 Stan(红色)、TFP(蓝色)和 R 的 lme4(橙色)的结果。我们对 Stan 和 TFP 的结果进行了阴影处理,因此预计当两者一致时会看到紫色。为简单起见,我们没有对 R 的结果进行阴影处理。每个子图代表一个县,并按光栅扫描顺序(即从左到右,然后从上到下)按频率降序排列。
nrows = 17
ncols = 5
fig, ax = plt.subplots(nrows, ncols, figsize=(18, 21), sharey=True, sharex=True)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
ii = -1
for r in range(nrows):
for c in range(ncols):
ii += 1
idx = county_freq[ii, 0]
sns.kdeplot(
posterior_random_weights_final_[:, idx] * log_county_uranium_ppm[idx],
color='blue',
alpha=.3,
shade=True,
label='TFP',
ax=ax[r][c])
sns.kdeplot(
posterior_random_weights_final_stan[:, idx] *
log_county_uranium_ppm[idx],
color='red',
alpha=.3,
shade=True,
label='Stan/rstanarm',
ax=ax[r][c])
sns.kdeplot(
posterior_random_weights_lme4_final_[:, idx] *
log_county_uranium_ppm[idx],
color='#F4B400',
alpha=.7,
shade=False,
label='R/lme4',
ax=ax[r][c])
ax[r][c].vlines(
posterior_random_weights_lme4[idx] * log_county_uranium_ppm[idx],
0,
5,
color='#F4B400',
linestyle='--')
ax[r][c].set_title(county_name[idx] + ' ({})'.format(idx), y=.7)
ax[r][c].set_ylim(0, 5)
ax[r][c].set_xlim(-1., 1.)
ax[r][c].get_yaxis().set_visible(False)
if ii == 2:
ax[r][c].legend(bbox_to_anchor=(1.4, 1.7), fontsize=20, ncol=3)
else:
ax[r][c].legend_.remove()
fig.subplots_adjust(wspace=0.03, hspace=0.1)
8 结论
在这个 colab 中,我们对氡数据集拟合了一个线性混合效应回归模型。我们尝试了三种不同的软件包:R、Stan 和 TensorFlow Probability。最后,我们绘制了三种不同的软件包计算的 85 个后验分布。
附录 A:替代氡 HLM(添加随机截距)
在本节中,我们描述了另一种 HLM,它还与每个县相关联一个随机截距。
\[\begin{align*} \text{for } & c=1\ldots \text{NumCounties}:\\ & \beta_c \sim \text{MultivariateNormal}\left(\text{loc}=\left[ \begin{array}{c} 0 \\ 0 \end{array}\right] , \text{scale}=\left[\begin{array}{cc} \sigma_{11} & 0 \\ \sigma_{12} & \sigma_{22} \end{array}\right] \right) \\ \text{for } & i=1\ldots \text{NumSamples}:\\ & c_i := \text{County}_i \\ &\eta_i = \underbrace{\omega_0 + \omega_1\text{Floor}_i \vphantom{\log( \text{CountyUraniumPPM}_{c_i}))} }_{\text{fixed effects} } + \underbrace{\beta_{c_i,0} + \beta_{c_i,1}\log( \text{CountyUraniumPPM}_{c_i}))}_{\text{random effects} } \\ &\log(\text{Radon}_i) \sim \text{Normal}(\text{loc}=\eta_i , \text{scale}=\sigma) \end{align*}\]
在 R 的 lme4 “波浪号符号” 中,此模型等效于
log_radon ~ 1 + floor + (1 + log_county_uranium_ppm | county)
附录 B:广义线性混合效应模型
在本节中,我们给出了比主体中使用的更一般的分层线性模型表征。这种更一般的模型被称为广义线性混合效应模型(GLMM)。
GLMM 是广义线性模型(GLM)的推广。GLMM 通过将样本特定的随机噪声纳入预测的线性响应中来扩展 GLM。这在一定程度上是有用的,因为它允许很少见的特征与更常见的特征共享信息。
作为生成过程,广义线性混合效应模型 (GLMM) 的特征在于
\begin{align} \text{for } & r = 1\ldots R: \hspace{2.45cm}\text{# 对于每个随机效应组}\ &\begin{aligned} \text{for } &c = 1\ldots |Cr|: \hspace{1.3cm}\text{# 对于组 \(r\) 的每个类别(“级别”)}\ &\begin{aligned} \beta{rc} &\sim \text{MultivariateNormal}(\text{loc}=0_{D_r}, \text{scale}=\Sigma_r^{1/2}) \end{aligned} \end{aligned}\\ \text{for } & i = 1 \ldots N: \hspace{2.45cm}\text{# 对于每个样本}\ &\begin{aligned} &\etai = \underbrace{\vphantom{\sum{r=1}^R}xi^\top\omega}\text{固定效应} + \underbrace{\sum{r=1}^R z{r,i}^\top \beta_{r,Cr(i) } }\text{随机效应} \ &Y_i|xi,\omega,{z{r,i} , \betar}{r=1}^R \sim \text{Distribution}(\text{mean}= g^{-1}(\eta_i)) \end{aligned} \end{align}
其中
\begin{align} R &= \text{随机效应组的数量}\ |C_r| &= \text{组 \(r\) 的类别数量}\ N &= \text{训练样本的数量}\ x_i,\omega &\in \mathbb{R}^{D_0}\ D_0 &= \text{固定效应的数量}\ Cr(i) &= \text{第 \(i\) 个样本的类别(在组 \(r\) 下)}\ z{r,i} &\in \mathbb{R}^{D_r}\ Dr &= \text{与组 \(r\) 相关的随机效应的数量}\ \Sigma{r} &\in {S\in\mathbb{R}^{D_r \times D_r} : S \succ 0 }\ \eta_i\mapsto g^{-1}(\eta_i) &= \mu_i, \text{逆链接函数}\ \text{Distribution} &=\text{仅由其均值参数化的某个分布} \end{align}
换句话说,这意味着每个组的每个类别都与一个 iid MVN,\(\beta_{rc}\) 相关联。虽然 \(\beta_{rc}\) 绘制始终是独立的,但它们仅对于组 \(r\) 而言是相同分布的;请注意,每个 \(r\in\{1,\ldots,R\}\) 只有一个 \(\Sigma_r\)。
当与样本组的特征 \(z_{r,i}\) 进行仿射组合时,结果是第 \(i\) 个预测线性响应上的样本特定噪声(否则为 \(x_i^\top\omega\))。
当我们估计 \(\{\Sigma_r:r\in\{1,\ldots,R\}\}\) 时,我们实际上是在估计随机效应组所携带的噪声量,否则这些噪声会淹没 \(x_i^\top\omega\) 中存在的信号。
对于 \(\text{Distribution}\) 和逆链接函数,\(g^{-1}\) 有多种选择。常见的选择是
- \(Y_i\sim\text{Normal}(\text{mean}=\eta_i, \text{scale}=\sigma)\),
- \(Y_i\sim\text{Binomial}(\text{mean}=n_i \cdot \text{sigmoid}(\eta_i), \text{total_count}=n_i)\),以及
- \(Y_i\sim\text{Poisson}(\text{mean}=\exp(\eta_i))\)。
有关更多可能性,请参阅 tfp.glm 模块。