
|
|
|
 在 GitHub 上查看 在 GitHub 上查看
|
|
|
来自 TF-Hub 的 CORD-19 枢纽文本嵌入模块 (https://tfhub.dev/tensorflow/cord-19/swivel-128d/3) 是为了支持研究人员分析与 COVID-19 相关的自然语言文本而构建的。这些嵌入是在 CORD-19 数据集 中的文章标题、作者、摘要、正文和参考文献标题上训练的。
在这个 colab 中,我们将
- 分析嵌入空间中语义相似的词
- 使用 CORD-19 嵌入在 SciCite 数据集上训练分类器
设置
import functools
import itertools
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
from tqdm import trange
2023-10-09 22:29:39.063949: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-10-09 22:29:39.064004: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-10-09 22:29:39.064046: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
分析嵌入
让我们从通过计算和绘制不同术语之间的相关矩阵来分析嵌入开始。如果嵌入成功地学习了如何捕捉不同词的含义,那么语义相似的词的嵌入向量应该彼此靠近。让我们看看一些与 COVID-19 相关的术语。
# Use the inner product between two embedding vectors as the similarity measure
def plot_correlation(labels, features):
corr = np.inner(features, features)
corr /= np.max(corr)
sns.heatmap(corr, xticklabels=labels, yticklabels=labels)
# Generate embeddings for some terms
queries = [
# Related viruses
'coronavirus', 'SARS', 'MERS',
# Regions
'Italy', 'Spain', 'Europe',
# Symptoms
'cough', 'fever', 'throat'
]
module = hub.load('https://tfhub.dev/tensorflow/cord-19/swivel-128d/3')
embeddings = module(queries)
plot_correlation(queries, embeddings)
2023-10-09 22:29:44.568345: E tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:268] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
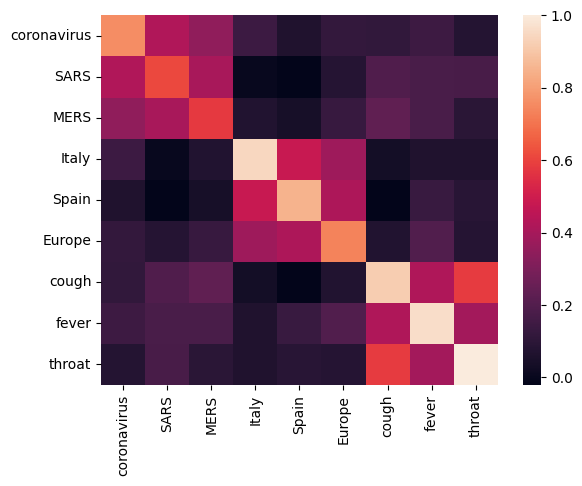
我们可以看到,嵌入成功地捕捉了不同术语的含义。每个词都与其集群中的其他词相似(例如,“冠状病毒”与“SARS”和“MERS”高度相关),而它们与其他集群的术语不同(例如,“SARS”和“西班牙”之间的相似度接近 0)。
现在让我们看看如何使用这些嵌入来解决特定任务。
SciCite:引用意图分类
本节展示了如何将嵌入用于下游任务,例如文本分类。我们将使用 TensorFlow 数据集中的 SciCite 数据集 来对学术论文中的引用意图进行分类。给定包含来自学术论文的引用的句子,对引用的主要意图进行分类,例如背景信息、方法使用或结果比较。
builder = tfds.builder(name='scicite')
builder.download_and_prepare()
train_data, validation_data, test_data = builder.as_dataset(
split=('train', 'validation', 'test'),
as_supervised=True)
让我们看看训练集中的一些带标签的示例
训练引用意图分类器
我们将使用 Keras 在 SciCite 数据集 上训练分类器。让我们构建一个模型,该模型使用 CORD-19 嵌入,并在其顶部使用一个分类层。
超参数
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 128) 17301632
dense (Dense) (None, 3) 387
=================================================================
Total params: 17302019 (132.00 MB)
Trainable params: 387 (1.51 KB)
Non-trainable params: 17301632 (132.00 MB)
_________________________________________________________________
训练和评估模型
让我们训练和评估模型,看看它在 SciCite 任务上的表现
EPOCHS = 35
BATCH_SIZE = 32
history = model.fit(train_data.shuffle(10000).batch(BATCH_SIZE),
epochs=EPOCHS,
validation_data=validation_data.batch(BATCH_SIZE),
verbose=1)
Epoch 1/35 257/257 [==============================] - 2s 4ms/step - loss: 0.8391 - accuracy: 0.6421 - val_loss: 0.7495 - val_accuracy: 0.7020 Epoch 2/35 257/257 [==============================] - 1s 3ms/step - loss: 0.6784 - accuracy: 0.7282 - val_loss: 0.6634 - val_accuracy: 0.7380 Epoch 3/35 257/257 [==============================] - 1s 3ms/step - loss: 0.6175 - accuracy: 0.7562 - val_loss: 0.6269 - val_accuracy: 0.7478 Epoch 4/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5858 - accuracy: 0.7706 - val_loss: 0.6035 - val_accuracy: 0.7533 Epoch 5/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5674 - accuracy: 0.7780 - val_loss: 0.5914 - val_accuracy: 0.7576 Epoch 6/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5553 - accuracy: 0.7817 - val_loss: 0.5822 - val_accuracy: 0.7653 Epoch 7/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5464 - accuracy: 0.7847 - val_loss: 0.5784 - val_accuracy: 0.7609 Epoch 8/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5399 - accuracy: 0.7872 - val_loss: 0.5723 - val_accuracy: 0.7707 Epoch 9/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5352 - accuracy: 0.7906 - val_loss: 0.5690 - val_accuracy: 0.7707 Epoch 10/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5303 - accuracy: 0.7924 - val_loss: 0.5630 - val_accuracy: 0.7806 Epoch 11/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5268 - accuracy: 0.7939 - val_loss: 0.5610 - val_accuracy: 0.7773 Epoch 12/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5236 - accuracy: 0.7929 - val_loss: 0.5601 - val_accuracy: 0.7762 Epoch 13/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5213 - accuracy: 0.7952 - val_loss: 0.5586 - val_accuracy: 0.7773 Epoch 14/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5188 - accuracy: 0.7959 - val_loss: 0.5560 - val_accuracy: 0.7751 Epoch 15/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5169 - accuracy: 0.7963 - val_loss: 0.5566 - val_accuracy: 0.7817 Epoch 16/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5150 - accuracy: 0.7950 - val_loss: 0.5521 - val_accuracy: 0.7795 Epoch 17/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5136 - accuracy: 0.7974 - val_loss: 0.5551 - val_accuracy: 0.7795 Epoch 18/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5122 - accuracy: 0.7966 - val_loss: 0.5490 - val_accuracy: 0.7795 Epoch 19/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5106 - accuracy: 0.7973 - val_loss: 0.5508 - val_accuracy: 0.7849 Epoch 20/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5097 - accuracy: 0.7974 - val_loss: 0.5503 - val_accuracy: 0.7806 Epoch 21/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5086 - accuracy: 0.7981 - val_loss: 0.5467 - val_accuracy: 0.7817 Epoch 22/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5072 - accuracy: 0.8003 - val_loss: 0.5518 - val_accuracy: 0.7838 Epoch 23/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5066 - accuracy: 0.7994 - val_loss: 0.5485 - val_accuracy: 0.7871 Epoch 24/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5060 - accuracy: 0.7991 - val_loss: 0.5477 - val_accuracy: 0.7849 Epoch 25/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5049 - accuracy: 0.8003 - val_loss: 0.5481 - val_accuracy: 0.7849 Epoch 26/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5046 - accuracy: 0.7985 - val_loss: 0.5465 - val_accuracy: 0.7871 Epoch 27/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5035 - accuracy: 0.7999 - val_loss: 0.5457 - val_accuracy: 0.7828 Epoch 28/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5030 - accuracy: 0.8011 - val_loss: 0.5474 - val_accuracy: 0.7838 Epoch 29/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5025 - accuracy: 0.8007 - val_loss: 0.5484 - val_accuracy: 0.7871 Epoch 30/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5016 - accuracy: 0.8023 - val_loss: 0.5440 - val_accuracy: 0.7904 Epoch 31/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5011 - accuracy: 0.8003 - val_loss: 0.5487 - val_accuracy: 0.7849 Epoch 32/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5011 - accuracy: 0.8012 - val_loss: 0.5451 - val_accuracy: 0.7882 Epoch 33/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5005 - accuracy: 0.8011 - val_loss: 0.5464 - val_accuracy: 0.7882 Epoch 34/35 257/257 [==============================] - 1s 3ms/step - loss: 0.5000 - accuracy: 0.8014 - val_loss: 0.5486 - val_accuracy: 0.7871 Epoch 35/35 257/257 [==============================] - 1s 3ms/step - loss: 0.4995 - accuracy: 0.8006 - val_loss: 0.5485 - val_accuracy: 0.7871
from matplotlib import pyplot as plt
def display_training_curves(training, validation, title, subplot):
if subplot%10==1: # set up the subplots on the first call
plt.subplots(figsize=(10,10), facecolor='#F0F0F0')
plt.tight_layout()
ax = plt.subplot(subplot)
ax.set_facecolor('#F8F8F8')
ax.plot(training)
ax.plot(validation)
ax.set_title('model '+ title)
ax.set_ylabel(title)
ax.set_xlabel('epoch')
ax.legend(['train', 'valid.'])
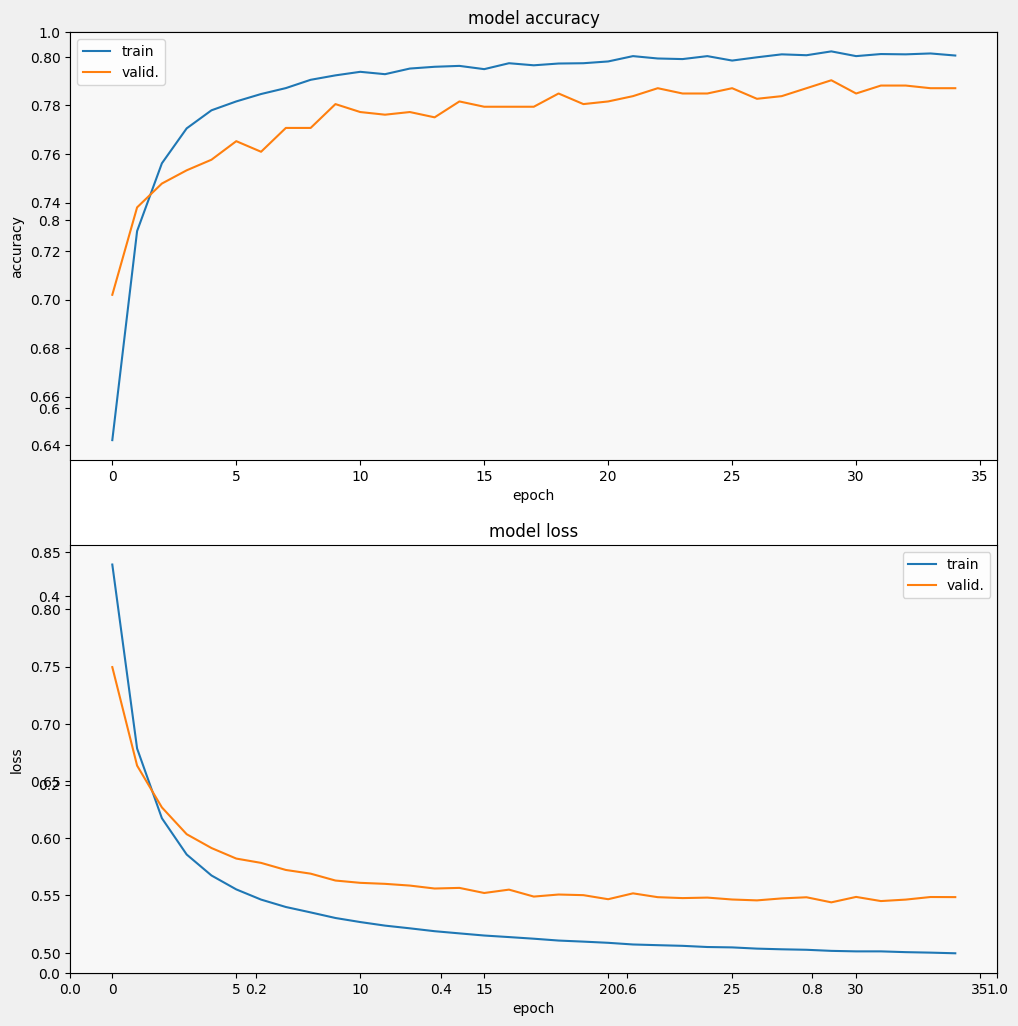
display_training_curves(history.history['accuracy'], history.history['val_accuracy'], 'accuracy', 211)
display_training_curves(history.history['loss'], history.history['val_loss'], 'loss', 212)
评估模型
让我们看看模型的表现。将返回两个值。损失(表示误差的数字,值越低越好)和准确率。
results = model.evaluate(test_data.batch(512), verbose=2)
for name, value in zip(model.metrics_names, results):
print('%s: %.3f' % (name, value))
4/4 - 0s - loss: 0.5406 - accuracy: 0.7805 - 293ms/epoch - 73ms/step loss: 0.541 accuracy: 0.781
我们可以看到,损失迅速下降,而准确率则迅速上升。让我们绘制一些示例,以检查预测与真实标签之间的关系
prediction_dataset = next(iter(test_data.batch(20)))
prediction_texts = [ex.numpy().decode('utf8') for ex in prediction_dataset[0]]
prediction_labels = [label2str(x) for x in prediction_dataset[1]]
predictions = [
label2str(x) for x in np.argmax(model.predict(prediction_texts), axis=-1)]
pd.DataFrame({
TEXT_FEATURE_NAME: prediction_texts,
LABEL_NAME: prediction_labels,
'prediction': predictions
})
1/1 [==============================] - 0s 122ms/step
我们可以看到,对于这个随机样本,模型在大多数情况下预测了正确的标签,这表明它可以很好地嵌入科学句子。
下一步是什么?
现在您已经对来自 TF-Hub 的 CORD-19 Swivel 嵌入有了更多了解,我们鼓励您参与 CORD-19 Kaggle 竞赛,为从 COVID-19 相关学术文本中获取科学见解做出贡献。
- 参加 CORD-19 Kaggle 挑战赛
- 了解更多关于 COVID-19 开放研究数据集 (CORD-19)
- 查看 TF-Hub 嵌入的文档和更多信息,请访问 https://tfhub.dev/tensorflow/cord-19/swivel-128d/3
- 使用 TensorFlow 嵌入投影仪 探索 CORD-19 嵌入空间