
|
|
|
 在 GitHub 上查看 在 GitHub 上查看
|
|
此 Colab 演示了如何使用 Tensorflow Hub 对非英语/本地语言进行文本分类。在这里,我们选择 孟加拉语 作为本地语言,并使用预训练词嵌入来解决多类分类任务,其中我们将孟加拉语新闻文章分为 5 类。孟加拉语的预训练嵌入来自 fastText,它是 Facebook 的一个库,发布了 157 种语言的预训练词向量。
我们将首先使用 TF-Hub 的预训练嵌入导出器将词嵌入转换为文本嵌入模块,然后使用该模块使用 tf.keras(Tensorflow 的高级用户友好 API,用于构建深度学习模型)训练分类器。即使我们在这里使用 fastText 嵌入,也可以从其他任务中导出任何其他预训练嵌入,并使用 Tensorflow hub 快速获得结果。
设置
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-25ubuntu1.1). The following packages were automatically installed and are no longer required: libatasmart4 libblockdev-fs2 libblockdev-loop2 libblockdev-part-err2 libblockdev-part2 libblockdev-swap2 libblockdev-utils2 libblockdev2 libparted-fs-resize0 libxmlb2 Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 159 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
2024-02-02 12:29:03.681459: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-02-02 12:29:03.681511: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-02-02 12:29:03.683037: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
数据集
我们将使用 BARD(孟加拉语文章数据集),该数据集包含从不同孟加拉语新闻门户网站收集的约 376,226 篇文章,并标注了 5 类:经济、国家、国际、体育和娱乐。我们从 Google Drive 下载文件,此 (bit.ly/BARD_DATASET) 链接是指从 这里 GitHub 存储库。
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
将预训练词向量导出到 TF-Hub 模块
TF-Hub 提供了一些有用的脚本,用于将词嵌入转换为 TF-hub 文本嵌入模块 这里。要为孟加拉语或任何其他语言创建模块,我们只需将词嵌入 .txt 或 .vec 文件下载到与 export_v2.py 相同的目录中,然后运行该脚本。
导出器读取嵌入向量并将其导出到 Tensorflow SavedModel。SavedModel 包含一个完整的 TensorFlow 程序,包括权重和图。TF-Hub 可以将 SavedModel 加载为 模块,我们将使用它来构建文本分类模型。由于我们使用 tf.keras 构建模型,因此我们将使用 hub.KerasLayer,它为 TF-Hub 模块提供了一个包装器,可以用作 Keras 层。
首先,我们将从 fastText 和 TF-Hub repo 获取词嵌入。
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 42.9M 0 0:00:19 0:00:19 --:--:-- 40.4M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7500 100 7500 0 0 56818 0 --:--:-- --:--:-- --:--:-- 56818
然后,我们将对嵌入文件运行导出器脚本。由于 fastText 嵌入具有标题行并且非常大(转换为模块后孟加拉语约为 3.3 GB),因此我们忽略第一行,并将前 100,000 个标记导出到文本嵌入模块。
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
2024-02-02 12:30:25.110154: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-02-02 12:30:25.110207: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-02-02 12:30:25.111689: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2024-02-02 12:30:27.321508: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:274] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected INFO:tensorflow:Assets written to: text_module/assets I0202 12:30:40.352254 140300656232256 builder_impl.py:801] Assets written to: text_module/assets I0202 12:30:40.356071 140300656232256 fingerprinting_utils.py:49] Writing fingerprint to text_module/fingerprint.pb
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
2024-02-02 12:30:41.057019: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:274] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
文本嵌入模块将一维字符串张量中的句子批次作为输入,并输出与句子相对应的形状为 (batch_size, embedding_dim) 的嵌入向量。它通过空格分割来预处理输入。词嵌入使用 sqrtn 组合器组合成句子嵌入(参见 这里)。为了演示,我们将孟加拉语单词列表作为输入,并获得相应的嵌入向量。
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
转换为 Tensorflow 数据集
由于数据集非常大,因此我们不会将整个数据集加载到内存中,而是使用生成器来使用 Tensorflow 数据集 函数以批次在运行时生成样本。数据集也非常不平衡,因此,在使用生成器之前,我们将对数据集进行洗牌。
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
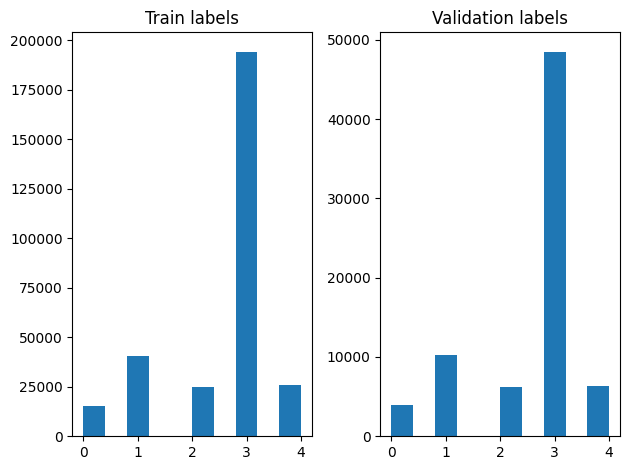
在洗牌后,我们可以检查训练和验证示例中标签的分布。
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
要使用生成器创建 Dataset,我们首先编写一个生成器函数,该函数从 file_paths 中读取每篇文章,从标签数组中读取标签,并在每一步生成一个训练示例。我们将此生成器函数传递给 tf.data.Dataset.from_generator 方法并指定输出类型。每个训练示例都是一个元组,包含一个 tf.string 数据类型的文章和一个独热编码的标签。我们使用 tf.data.Dataset.skip 和 tf.data.Dataset.take 方法将数据集按 80-20 的比例进行训练-验证拆分。
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
模型训练和评估
由于我们已经在模块周围添加了一个包装器,以便将其用作 Keras 中的任何其他层,因此我们可以创建一个小的 Sequential 模型,它是一个线性堆叠的层。我们可以像任何其他层一样使用 model.add 添加文本嵌入模块。我们通过指定损失和优化器来编译模型,并对其进行 10 个 epochs 的训练。 tf.keras API 可以处理 Tensorflow 数据集作为输入,因此我们可以将 Dataset 实例传递给 fit 方法进行模型训练。由于我们使用的是生成器函数,因此 tf.data 将处理生成样本、将它们批处理并将其馈送到模型。
模型
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
训练
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 40s 33ms/step - loss: 0.2137 - accuracy: 0.9283 - val_loss: 0.1510 - val_accuracy: 0.9491 Epoch 2/5 1176/1176 [==============================] - 39s 33ms/step - loss: 0.1420 - accuracy: 0.9503 - val_loss: 0.1348 - val_accuracy: 0.9531 Epoch 3/5 1176/1176 [==============================] - 39s 33ms/step - loss: 0.1296 - accuracy: 0.9533 - val_loss: 0.1254 - val_accuracy: 0.9556 Epoch 4/5 1176/1176 [==============================] - 39s 33ms/step - loss: 0.1220 - accuracy: 0.9558 - val_loss: 0.1236 - val_accuracy: 0.9553 Epoch 5/5 1176/1176 [==============================] - 39s 33ms/step - loss: 0.1164 - accuracy: 0.9574 - val_loss: 0.1177 - val_accuracy: 0.9575
评估
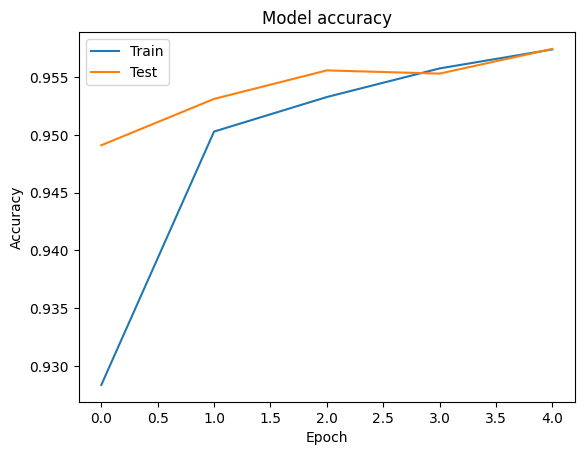
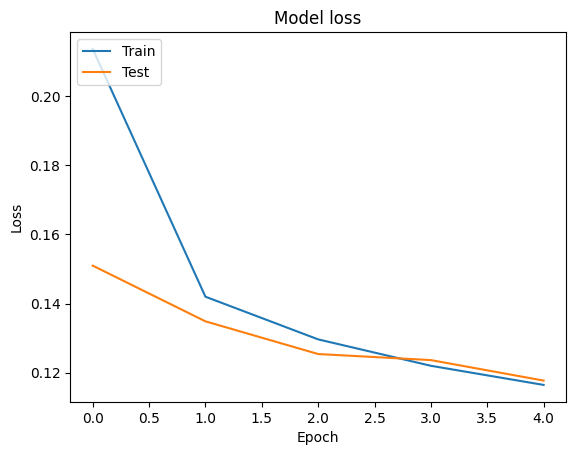
我们可以使用 tf.keras.callbacks.History 对象来可视化训练和验证数据的准确率和损失曲线,该对象由 tf.keras.Model.fit 方法返回,其中包含每个 epoch 的损失和准确率值。
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
预测
我们可以获取验证数据的预测,并检查混淆矩阵以查看模型对 5 个类别的每个类别的性能。因为 tf.keras.Model.predict 方法返回一个 n 维数组,表示每个类别的概率,所以可以使用 np.argmax 将它们转换为类别标签。
y_pred = model.predict(validation_data)
294/294 [==============================] - 8s 26ms/step
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
বৃহস্পতিবার বিকেল। রাজধানীর তেজগাঁওয়ের কোক স্টুডিওর প্রধান ফটক পেরিয়ে ভেতরে ঢুকতেই দেখা গেল, পুলিশ True Class: entertainment Predicted Class: state মানিকগঞ্জ পৌর এলাকার ছিদ্দিকনগরে আজ বুধবার থেকে তিন দিনব্যাপী ইজতেমা শুরু হচ্ছে। বাদ জোহর এর আনুষ্ঠ True Class: state Predicted Class: state ফিল হিউজ অ্যাডিলেডে থাকবেন না। আবার থাকবেনও।সতীর্থর অকালমৃত্যুর শোকে এখনো আচ্ছন্ন অস্ট্রেলিয়ান খেল True Class: sports Predicted Class: state
比较性能
现在,我们可以从 labels 中获取验证数据的正确标签,并将它们与我们的预测进行比较,以获得 classification_report。
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.77 0.80 3897
sports 0.98 0.99 0.98 10204
entertainment 0.91 0.93 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.94 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
我们还可以将模型的性能与原始 论文 中发布的结果进行比较,该论文的精度为 0.96。原始作者描述了对数据集执行的许多预处理步骤,例如删除标点符号和数字,删除前 25 个最频繁的停用词。正如我们在 classification_report 中看到的,我们也设法在仅训练 5 个 epochs 且没有任何预处理的情况下获得了 0.96 的精度和准确率!
在本例中,当我们从嵌入模块创建 Keras 层时,我们设置了参数 trainable=False,这意味着嵌入权重在训练期间不会更新。尝试将其设置为 True,以便仅在 2 个 epochs 后使用此数据集达到大约 97% 的准确率。