
|
|
|
 在 GitHub 上查看 在 GitHub 上查看
|
|
|
BERT 可用于解决自然语言处理中的许多问题。您将学习如何针对 GLUE 基准 中的许多任务微调 BERT
CoLA(语言可接受性语料库):句子语法正确吗?
SST-2(斯坦福情感树库):任务是预测给定句子的情感。
MRPC(微软研究院释义语料库):确定一对句子在语义上是否等效。
QQP(Quora 问答对2):确定一对问题在语义上是否等效。
MNLI(多体裁自然语言推理):给定一个前提句和一个假设句,任务是预测前提是否蕴含假设(蕴含)、与假设矛盾(矛盾)或两者都不是(中性)。
QNLI(问答自然语言推理):任务是确定上下文句子是否包含问题的答案。
RTE(识别文本蕴含):确定句子是否蕴含给定的假设。
WNLI(温诺格拉德自然语言推理):任务是预测用代词替换后的句子是否蕴含原始句子。
本教程包含在 TPU 上训练这些模型的完整端到端代码。您也可以通过更改一行代码(如下所述)在 GPU 上运行此笔记本。
在本笔记本中,您将
- 从 TensorFlow Hub 加载 BERT 模型
- 选择一个 GLUE 任务并下载数据集
- 预处理文本
- 微调 BERT(针对单句和多句数据集提供了示例)
- 保存训练后的模型并使用它
设置
您将使用一个单独的模型在使用它微调 BERT 之前预处理文本。此模型依赖于 tensorflow/text,您将在下面安装它。
pip install -q -U "tensorflow-text==2.8.*"
您将使用来自 tensorflow/models 的 AdamW 优化器来微调 BERT,您也将安装它。
pip install -q -U tf-models-official==2.7.0
pip install -U tfds-nightly
import os
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import tensorflow_text as text # A dependency of the preprocessing model
import tensorflow_addons as tfa
from official.nlp import optimization
import numpy as np
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_addons/utils/ensure_tf_install.py:53: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.9.0 and strictly below 2.12.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.4 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons warnings.warn(
接下来,配置 TFHub 以直接从 TFHub 的云存储桶读取检查点。仅当在 TPU 上运行 TFHub 模型时才建议这样做。
没有此设置,TFHub 将下载压缩文件并在本地解压缩检查点。尝试从这些本地文件加载将导致以下错误
InvalidArgumentError: Unimplemented: File system scheme '[local]' not implemented
这是因为 TPU 只能直接从云存储桶读取。
os.environ["TFHUB_MODEL_LOAD_FORMAT"]="UNCOMPRESSED"
连接到 TPU 工作器
以下代码连接到 TPU 工作器并将 TensorFlow 的默认设备更改为 TPU 工作器上的 CPU 设备。它还定义了一个 TPU 分布策略,您将使用它将模型训练分布到此一个 TPU 工作器上可用的 8 个独立的 TPU 内核。有关更多信息,请参阅 TensorFlow 的 TPU 指南。
import os
if os.environ['COLAB_TPU_ADDR']:
cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='')
tf.config.experimental_connect_to_cluster(cluster_resolver)
tf.tpu.experimental.initialize_tpu_system(cluster_resolver)
strategy = tf.distribute.TPUStrategy(cluster_resolver)
print('Using TPU')
elif tf.config.list_physical_devices('GPU'):
strategy = tf.distribute.MirroredStrategy()
print('Using GPU')
else:
raise ValueError('Running on CPU is not recommended.')
2022-12-15 12:12:12.050007: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected Using TPU
从 TensorFlow Hub 加载模型
在这里,您可以选择要从 TensorFlow Hub 加载和微调的 BERT 模型。有多个 BERT 模型可供选择。
- BERT-Base、未分词 和 七个更多模型,这些模型具有由原始 BERT 作者发布的训练权重。
- 小型 BERT 具有相同的通用架构,但 Transformer 块更少或更小,这使您可以探索速度、大小和质量之间的权衡。
- ALBERT:四种不同大小的“A Lite BERT”,通过在层之间共享参数来减小模型大小(但不会减少计算时间)。
- BERT 专家:八个模型都具有 BERT-base 架构,但提供不同预训练域的选择,以更紧密地与目标任务对齐。
- Electra 具有与 BERT 相同的架构(三种不同尺寸),但在类似生成对抗网络 (GAN) 的设置中作为鉴别器进行预训练。
- 具有 Talking-Heads 注意力和 Gated GELU 的 BERT [base,large] 对 Transformer 架构的核心进行了两项改进。
有关更多详细信息,请参阅上面链接的模型文档。
在本教程中,您将从 BERT-base 开始。您可以使用更大、更新的模型来提高准确性,或者使用更小的模型来缩短训练时间。要更改模型,您只需更改一行代码(如下所示)。所有差异都封装在您将从 TensorFlow Hub 下载的 SavedModel 中。
选择要微调的 BERT 模型
BERT model selected : https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3 Preprocessing model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
预处理文本
在 使用 BERT colab 对文本进行分类 中,预处理模型直接与 BERT 编码器嵌入在一起。
本教程演示了如何在训练的输入管道中使用 Dataset.map 进行预处理,然后将其合并到用于推理的导出模型中。这样,训练和推理都可以从原始文本输入工作,尽管 TPU 本身需要数字输入。
除了 TPU 要求之外,在输入管道中异步进行预处理可以提高性能(您可以在 tf.data 性能指南 中了解更多信息)。
本教程还演示了如何构建多输入模型,以及如何调整 BERT 输入的序列长度。
让我们演示预处理模型。
bert_preprocess = hub.load(tfhub_handle_preprocess)
tok = bert_preprocess.tokenize(tf.constant(['Hello TensorFlow!']))
print(tok)
<tf.RaggedTensor [[[7592], [23435, 12314], [999]]]>
每个预处理模型还提供一个方法,.bert_pack_inputs(tensors, seq_length),它接受一个标记列表(如上面的 tok)和一个序列长度参数。这将打包输入以创建 BERT 模型预期格式的张量字典。
text_preprocessed = bert_preprocess.bert_pack_inputs([tok, tok], tf.constant(20))
print('Shape Word Ids : ', text_preprocessed['input_word_ids'].shape)
print('Word Ids : ', text_preprocessed['input_word_ids'][0, :16])
print('Shape Mask : ', text_preprocessed['input_mask'].shape)
print('Input Mask : ', text_preprocessed['input_mask'][0, :16])
print('Shape Type Ids : ', text_preprocessed['input_type_ids'].shape)
print('Type Ids : ', text_preprocessed['input_type_ids'][0, :16])
Shape Word Ids : (1, 20)
Word Ids : tf.Tensor(
[ 101 7592 23435 12314 999 102 7592 23435 12314 999 102 0
0 0 0 0], shape=(16,), dtype=int32)
Shape Mask : (1, 20)
Input Mask : tf.Tensor([1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0], shape=(16,), dtype=int32)
Shape Type Ids : (1, 20)
Type Ids : tf.Tensor([0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0], shape=(16,), dtype=int32)
以下是一些需要注意的细节
input_mask掩码允许模型清楚地区分内容和填充。掩码与input_word_ids的形状相同,并且在input_word_ids不是填充的任何地方都包含 1。input_type_ids与input_mask的形状相同,但在非填充区域内,包含 0 或 1,指示标记属于哪个句子。
接下来,您将创建一个预处理模型,它封装了所有这些逻辑。您的模型将以字符串作为输入,并返回格式正确的对象,这些对象可以传递给 BERT。
每个 BERT 模型都有一个特定的预处理模型,请确保使用 BERT 模型文档中描述的正确模型。
def make_bert_preprocess_model(sentence_features, seq_length=128):
"""Returns Model mapping string features to BERT inputs.
Args:
sentence_features: a list with the names of string-valued features.
seq_length: an integer that defines the sequence length of BERT inputs.
Returns:
A Keras Model that can be called on a list or dict of string Tensors
(with the order or names, resp., given by sentence_features) and
returns a dict of tensors for input to BERT.
"""
input_segments = [
tf.keras.layers.Input(shape=(), dtype=tf.string, name=ft)
for ft in sentence_features]
# Tokenize the text to word pieces.
bert_preprocess = hub.load(tfhub_handle_preprocess)
tokenizer = hub.KerasLayer(bert_preprocess.tokenize, name='tokenizer')
segments = [tokenizer(s) for s in input_segments]
# Optional: Trim segments in a smart way to fit seq_length.
# Simple cases (like this example) can skip this step and let
# the next step apply a default truncation to approximately equal lengths.
truncated_segments = segments
# Pack inputs. The details (start/end token ids, dict of output tensors)
# are model-dependent, so this gets loaded from the SavedModel.
packer = hub.KerasLayer(bert_preprocess.bert_pack_inputs,
arguments=dict(seq_length=seq_length),
name='packer')
model_inputs = packer(truncated_segments)
return tf.keras.Model(input_segments, model_inputs)
让我们演示预处理模型。您将创建一个包含两个句子输入(input1 和 input2)的测试。输出是 BERT 模型期望作为输入的内容:input_word_ids、input_masks 和 input_type_ids。
test_preprocess_model = make_bert_preprocess_model(['my_input1', 'my_input2'])
test_text = [np.array(['some random test sentence']),
np.array(['another sentence'])]
text_preprocessed = test_preprocess_model(test_text)
print('Keys : ', list(text_preprocessed.keys()))
print('Shape Word Ids : ', text_preprocessed['input_word_ids'].shape)
print('Word Ids : ', text_preprocessed['input_word_ids'][0, :16])
print('Shape Mask : ', text_preprocessed['input_mask'].shape)
print('Input Mask : ', text_preprocessed['input_mask'][0, :16])
print('Shape Type Ids : ', text_preprocessed['input_type_ids'].shape)
print('Type Ids : ', text_preprocessed['input_type_ids'][0, :16])
Keys : ['input_type_ids', 'input_mask', 'input_word_ids']
Shape Word Ids : (1, 128)
Word Ids : tf.Tensor(
[ 101 2070 6721 3231 6251 102 2178 6251 102 0 0 0 0 0
0 0], shape=(16,), dtype=int32)
Shape Mask : (1, 128)
Input Mask : tf.Tensor([1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0], shape=(16,), dtype=int32)
Shape Type Ids : (1, 128)
Type Ids : tf.Tensor([0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0], shape=(16,), dtype=int32)
让我们看一下模型的结构,注意您刚刚定义的两个输入。
tf.keras.utils.plot_model(test_preprocess_model, show_shapes=True, show_dtype=True)
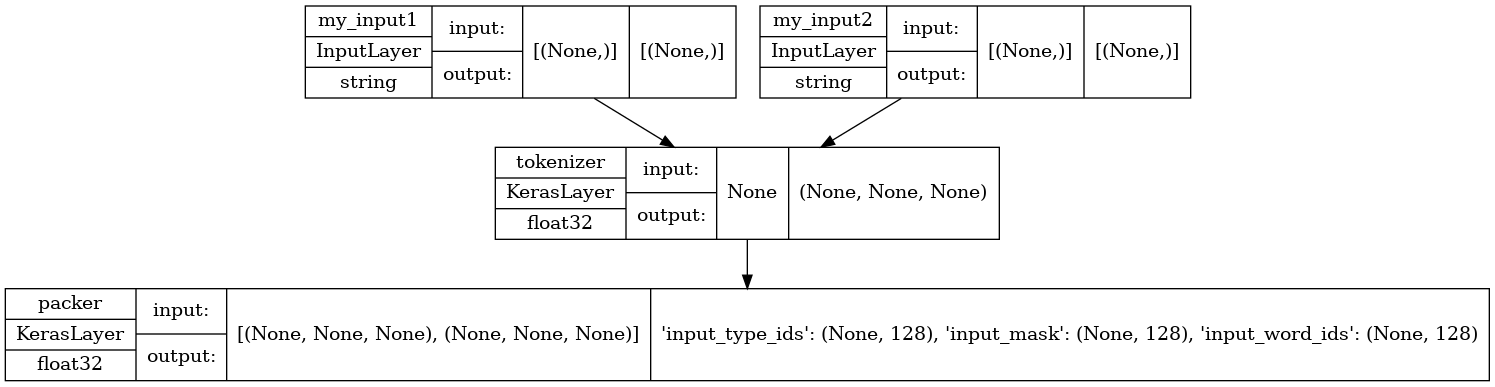
为了将预处理应用于数据集中的所有输入,您将使用数据集的 map 函数。然后将结果缓存以 提高性能。
AUTOTUNE = tf.data.AUTOTUNE
def load_dataset_from_tfds(in_memory_ds, info, split, batch_size,
bert_preprocess_model):
is_training = split.startswith('train')
dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[split])
num_examples = info.splits[split].num_examples
if is_training:
dataset = dataset.shuffle(num_examples)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.map(lambda ex: (bert_preprocess_model(ex), ex['label']))
dataset = dataset.cache().prefetch(buffer_size=AUTOTUNE)
return dataset, num_examples
定义您的模型
您现在可以定义用于句子或句子对分类的模型,方法是将预处理后的输入通过 BERT 编码器,并在其顶部放置一个线性分类器(或您喜欢的其他层排列),并使用 dropout 进行正则化。
def build_classifier_model(num_classes):
class Classifier(tf.keras.Model):
def __init__(self, num_classes):
super(Classifier, self).__init__(name="prediction")
self.encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True)
self.dropout = tf.keras.layers.Dropout(0.1)
self.dense = tf.keras.layers.Dense(num_classes)
def call(self, preprocessed_text):
encoder_outputs = self.encoder(preprocessed_text)
pooled_output = encoder_outputs["pooled_output"]
x = self.dropout(pooled_output)
x = self.dense(x)
return x
model = Classifier(num_classes)
return model
让我们尝试对一些预处理后的输入运行模型。
test_classifier_model = build_classifier_model(2)
bert_raw_result = test_classifier_model(text_preprocessed)
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.65279955 0.30029675]], shape=(1, 2), dtype=float32)
从 GLUE 中选择一个任务
您将使用来自 GLUE 基准套件的 TensorFlow DataSet。
Colab 允许您将这些小型数据集下载到本地文件系统,下面的代码将它们全部读入内存,因为单独的 TPU 工作器主机无法访问 colab 运行时的本地文件系统。
对于更大的数据集,您需要创建自己的 Google Cloud Storage 存储桶,并让 TPU 工作器从那里读取数据。您可以在 TPU 指南 中了解更多信息。
建议从 CoLa 数据集(用于单句)或 MRPC(用于多句)开始,因为它们很小,微调时间不长。
Using glue/cola from TFDS This dataset has 10657 examples Number of classes: 2 Features ['sentence'] Splits ['train', 'validation', 'test'] Here are some sample rows from glue/cola dataset ['unacceptable', 'acceptable'] sample row 1 b'It is this hat that it is certain that he was wearing.' label: 1 (acceptable) sample row 2 b'Her efficient looking up of the answer pleased the boss.' label: 1 (acceptable) sample row 3 b'Both the workers will wear carnations.' label: 1 (acceptable) sample row 4 b'John enjoyed drawing trees for his syntax homework.' label: 1 (acceptable) sample row 5 b'We consider Leslie rather foolish, and Lou a complete idiot.' label: 1 (acceptable)
数据集还确定问题类型(分类或回归)以及用于训练的适当损失函数。
def get_configuration(glue_task):
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
if glue_task == 'glue/cola':
metrics = tfa.metrics.MatthewsCorrelationCoefficient(num_classes=2)
else:
metrics = tf.keras.metrics.SparseCategoricalAccuracy(
'accuracy', dtype=tf.float32)
return metrics, loss
训练您的模型
最后,您可以对您选择的数据集进行端到端模型训练。
分布
回想一下顶部的设置代码,它已将 colab 运行时连接到具有多个 TPU 设备的 TPU 工作器。为了将训练分布到它们,您将在 TPU 分布策略的范围内创建和编译您的主要 Keras 模型。(有关详细信息,请参阅 使用 Keras 进行分布式训练。)
另一方面,预处理在工作器主机的 CPU 上运行,而不是 TPU 上,因此用于预处理的 Keras 模型以及使用它映射的训练和验证数据集是在分布策略范围之外构建的。对 Model.fit() 的调用将负责将传入的数据集分发到模型副本。
优化器
微调遵循 BERT 预训练中的优化器设置(如 使用 BERT 对文本进行分类):它使用 AdamW 优化器,该优化器对名义上的初始学习率进行线性衰减,并以在训练步骤的前 10%(num_warmup_steps)内进行线性预热阶段为前缀。与 BERT 论文一致,初始学习率对于微调来说更小(最佳值为 5e-5、3e-5、2e-5)。
epochs = 3
batch_size = 32
init_lr = 2e-5
print(f'Fine tuning {tfhub_handle_encoder} model')
bert_preprocess_model = make_bert_preprocess_model(sentence_features)
with strategy.scope():
# metric have to be created inside the strategy scope
metrics, loss = get_configuration(tfds_name)
train_dataset, train_data_size = load_dataset_from_tfds(
in_memory_ds, tfds_info, train_split, batch_size, bert_preprocess_model)
steps_per_epoch = train_data_size // batch_size
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = num_train_steps // 10
validation_dataset, validation_data_size = load_dataset_from_tfds(
in_memory_ds, tfds_info, validation_split, batch_size,
bert_preprocess_model)
validation_steps = validation_data_size // batch_size
classifier_model = build_classifier_model(num_classes)
optimizer = optimization.create_optimizer(
init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
classifier_model.compile(optimizer=optimizer, loss=loss, metrics=[metrics])
classifier_model.fit(
x=train_dataset,
validation_data=validation_dataset,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
validation_steps=validation_steps)
Fine tuning https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3 model
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['idx', 'label'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
Epoch 1/3
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/framework/indexed_slices.py:444: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("AdamWeightDecay/gradients/StatefulPartitionedCall:1", shape=(None,), dtype=int32), values=Tensor("clip_by_global_norm/clip_by_global_norm/_0:0", dtype=float32), dense_shape=Tensor("AdamWeightDecay/gradients/StatefulPartitionedCall:2", shape=(None,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
warnings.warn(
267/267 [==============================] - 76s 78ms/step - loss: 0.5383 - MatthewsCorrelationCoefficient: 0.0000e+00 - val_loss: 0.4666 - val_MatthewsCorrelationCoefficient: 0.0000e+00
Epoch 2/3
267/267 [==============================] - 15s 56ms/step - loss: 0.3595 - MatthewsCorrelationCoefficient: 0.0000e+00 - val_loss: 0.5112 - val_MatthewsCorrelationCoefficient: 0.0000e+00
Epoch 3/3
267/267 [==============================] - 15s 56ms/step - loss: 0.2482 - MatthewsCorrelationCoefficient: 0.0000e+00 - val_loss: 0.6271 - val_MatthewsCorrelationCoefficient: 0.0000e+00
导出以供推理
您将创建一个最终模型,该模型包含预处理部分和我们刚刚微调的 BERT。
在推理时,预处理需要成为模型的一部分(因为不再像训练数据那样有一个单独的输入队列来执行它)。预处理不仅仅是计算;它有自己的资源(词汇表),这些资源必须附加到要保存以供导出的 Keras 模型。这个最终的组装将被保存。
您将在 colab 上保存模型,稍后您可以下载以备将来使用(查看 -> 目录 -> 文件)。
main_save_path = './my_models'
bert_type = tfhub_handle_encoder.split('/')[-2]
saved_model_name = f'{tfds_name.replace("/", "_")}_{bert_type}'
saved_model_path = os.path.join(main_save_path, saved_model_name)
preprocess_inputs = bert_preprocess_model.inputs
bert_encoder_inputs = bert_preprocess_model(preprocess_inputs)
bert_outputs = classifier_model(bert_encoder_inputs)
model_for_export = tf.keras.Model(preprocess_inputs, bert_outputs)
print('Saving', saved_model_path)
# Save everything on the Colab host (even the variables from TPU memory)
save_options = tf.saved_model.SaveOptions(experimental_io_device='/job:localhost')
model_for_export.save(saved_model_path, include_optimizer=False,
options=save_options)
Saving ./my_models/glue_cola_bert_en_uncased_L-12_H-768_A-12 2022-12-15 12:14:54.576109: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 364). These functions will not be directly callable after loading.
测试模型
最后一步是测试导出模型的结果。
为了进行一些比较,让我们重新加载模型并使用来自数据集测试拆分的某些输入对其进行测试。
with tf.device('/job:localhost'):
reloaded_model = tf.saved_model.load(saved_model_path)
实用程序方法
测试
with tf.device('/job:localhost'):
test_dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[test_split])
for test_row in test_dataset.shuffle(1000).map(prepare).take(5):
if len(sentence_features) == 1:
result = reloaded_model(test_row[0])
else:
result = reloaded_model(list(test_row))
print_bert_results(test_row, result, tfds_name)
sentence: [b'Susan thinks that nobody likes her.'] This sentence is acceptable BERT raw results: tf.Tensor([-1.8933294 3.5275488], shape=(2,), dtype=float32) sentence: [b'Once Janet left, Fred became a lot crazier.'] This sentence is acceptable BERT raw results: tf.Tensor([-1.7920495 2.6326442], shape=(2,), dtype=float32) sentence: [b'What we donated a chopper to was the new hospital'] This sentence is unacceptable BERT raw results: tf.Tensor([ 1.3995948 -0.19624823], shape=(2,), dtype=float32) sentence: [b'I was told that by a little bird.'] This sentence is acceptable BERT raw results: tf.Tensor([-1.386563 3.435152], shape=(2,), dtype=float32) sentence: [b'For to do that would be a mistake.'] This sentence is unacceptable BERT raw results: tf.Tensor([ 2.3502376 -1.3375548], shape=(2,), dtype=float32)
如果您想在 TF Serving 上使用您的模型,请记住它将通过其命名签名之一调用您的 SavedModel。请注意,输入有一些细微的差异。在 Python 中,您可以按如下方式测试它们
with tf.device('/job:localhost'):
serving_model = reloaded_model.signatures['serving_default']
for test_row in test_dataset.shuffle(1000).map(prepare_serving).take(5):
result = serving_model(**test_row)
# The 'prediction' key is the classifier's defined model name.
print_bert_results(list(test_row.values()), result['prediction'], tfds_name)
sentence: b'They said that they would all work on that, and all work on that they did.' This sentence is unacceptable BERT raw results: tf.Tensor([ 0.71320724 -0.01210704], shape=(2,), dtype=float32) sentence: b'All of his conversation was reported to me.' This sentence is acceptable BERT raw results: tf.Tensor([-1.7974513 2.5984342], shape=(2,), dtype=float32) sentence: b'Mickey looked it up.' This sentence is acceptable BERT raw results: tf.Tensor([-2.4198797 3.6533701], shape=(2,), dtype=float32) sentence: b'A unicorn is in the garden.' This sentence is acceptable BERT raw results: tf.Tensor([-2.2405655 3.7187355], shape=(2,), dtype=float32) sentence: b'Chris handed Bo a ticket.' This sentence is acceptable BERT raw results: tf.Tensor([-2.416213 3.539216], shape=(2,), dtype=float32)
您做到了!您的保存模型可用于服务或在进程中进行简单的推理,使用更简单的 API,代码更少,更易于维护。
后续步骤
现在您已经尝试了基本 BERT 模型之一,您可以尝试其他模型以获得更高的准确性,或者使用更小的模型版本。
您也可以尝试其他数据集。