TensorFlow 的文本处理工具
TensorFlow 提供两个用于文本和自然语言处理的库:KerasNLP 和 TensorFlow Text。KerasNLP 是一个高级自然语言处理 (NLP) 库,它包含现代基于 Transformer 的模型以及更低级的标记化实用程序。它是大多数 NLP 用例的推荐解决方案。KerasNLP 基于 TensorFlow Text,将低级文本处理操作抽象到一个易于使用的 API 中。但是,如果您不想使用 Keras API,或者需要访问更低级的文本处理操作,您可以直接使用 TensorFlow Text。
KerasNLP
import keras_nlp
import tensorflow_datasets as tfds
imdb_train, imdb_test = tfds.load(
"imdb_reviews",
split=["train", "test"],
as_supervised=True,
batch_size=16,
)
# Load a BERT model.
classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased")
# Fine-tune on IMDb movie reviews.
classifier.fit(imdb_train, validation_data=imdb_test)
# Predict two new examples.
classifier.predict(["What an amazing movie!", "A total waste of my time."])
查看 GitHub 上的快速入门指南。
在 TensorFlow 中开始处理文本的最简单方法是使用 KerasNLP。KerasNLP 是一个自然语言处理库,支持由模块化组件构建的工作流程,这些组件具有最先进的预设权重和架构。您可以将 KerasNLP 组件与其开箱即用的配置一起使用。如果您需要更多控制,可以轻松自定义组件。KerasNLP 强调所有工作流程中的图内计算,因此您可以期望使用 TensorFlow 生态系统轻松实现生产化。
KerasNLP 是核心 Keras API 的扩展,所有高级 KerasNLP 模块都是层或模型。如果您熟悉 Keras,那么您已经了解了 KerasNLP 的大部分内容。
要了解更多信息,请参阅 KerasNLP。
TensorFlow Text
import tensorflow as tf
import tensorflow_text as tf_text
def preprocess(vocab_lookup_table, example_text):
# Normalize text
tf_text.normalize_utf8(example_text)
# Tokenize into words
word_tokenizer = tf_text.WhitespaceTokenizer()
tokens = word_tokenizer.tokenize(example_text)
# Tokenize into subwords
subword_tokenizer = tf_text.WordpieceTokenizer(
vocab_lookup_table, token_out_type=tf.int64)
subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1)
# Apply padding
padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16)
return padded_inputs
在 笔记本 中运行
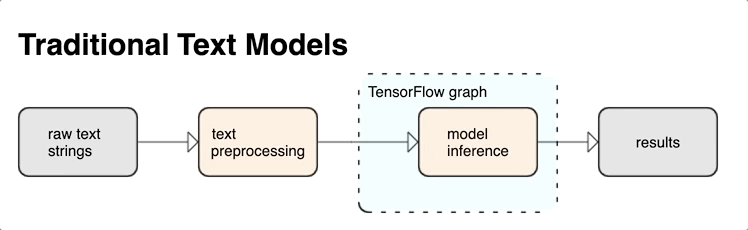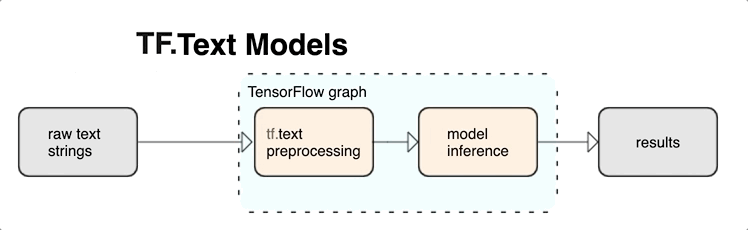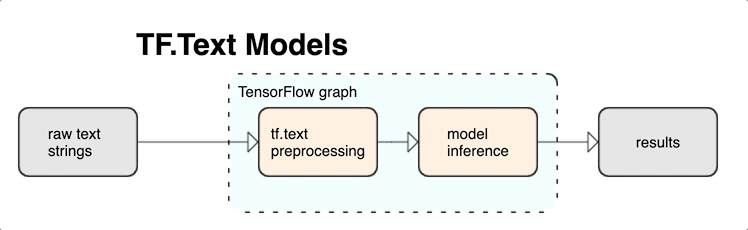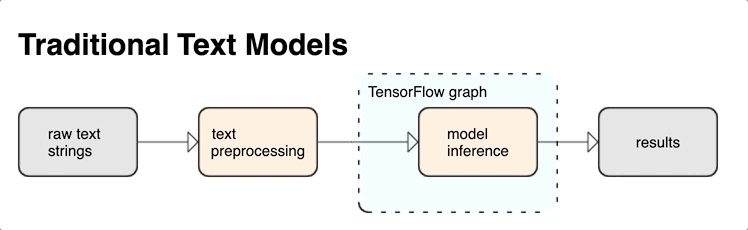
KerasNLP 提供作为层或模型提供的高级文本处理模块。如果您需要访问更低级的工具,可以使用 TensorFlow Text。TensorFlow Text 为您提供丰富的操作和库集合,以帮助您处理文本形式的输入,例如原始文本字符串或文档。这些库可以执行文本模型通常需要的预处理,并包含对序列建模有用的其他功能。
您可以从 TensorFlow 图中提取强大的句法和语义文本特征作为神经网络的输入。
将预处理与 TensorFlow 图集成提供以下好处
- 为处理文本提供大型工具包
- 允许与大型 TensorFlow 工具套件集成,以支持从问题定义到训练、评估和发布的项目
- 减少服务时的复杂性并防止训练服务偏差
除了上述内容外,您无需担心训练中的标记化与推理中的标记化不同,也不需要管理预处理脚本。