
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
MoViNets(移动视频网络)提供了一系列高效的视频分类模型,支持对流式视频进行推理。在本教程中,您将使用预训练的 MoViNet 模型对视频进行分类,特别是针对来自 UCF101 数据集 的动作识别任务。预训练模型是一个保存的网络,之前在更大的数据集上进行过训练。您可以在 MoViNets:用于高效视频识别的移动视频网络 论文中找到有关 MoViNets 的更多详细信息,该论文由 Kondratyuk, D. 等人 (2021) 撰写。在本教程中,您将
- 学习如何下载预训练的 MoViNet 模型
- 通过冻结 MoViNet 模型的卷积基础,使用预训练模型和新的分类器创建一个新模型
- 用新数据集的标签数量替换分类器头部
- 对 UCF101 数据集 执行迁移学习
在本教程中下载的模型来自 official/projects/movinet。此存储库包含 TF Hub 在 TensorFlow 2 SavedModel 格式中使用的 MoViNet 模型集合。
此迁移学习教程是 TensorFlow 视频教程系列的第三部分。以下是另外三个教程
- 加载视频数据:本教程解释了本文档中使用的许多代码;特别是,如何通过
FrameGenerator类预处理和加载数据将在更详细地解释。 - 构建用于视频分类的 3D CNN 模型。请注意,本教程使用 (2+1)D CNN 将 3D 数据的空间和时间方面分解;如果您使用的是体积数据(如 MRI 扫描),请考虑使用 3D CNN 而不是 (2+1)D CNN。
- 用于流式动作识别的 MoViNet:熟悉 TF Hub 上可用的 MoViNet 模型。
设置
首先安装并导入一些必要的库,包括:remotezip 用于检查 ZIP 文件的内容,tqdm 用于使用进度条,OpenCV 用于处理视频文件(确保 opencv-python 和 opencv-python-headless 版本相同),以及 TensorFlow 模型 (tf-models-official) 用于下载预训练的 MoViNet 模型。TensorFlow 模型包是使用 TensorFlow 的高级 API 的模型集合。
pip install remotezip tqdm opencv-python==4.5.2.52 opencv-python-headless==4.5.2.52 tf-models-official
import tqdm
import random
import pathlib
import itertools
import collections
import cv2
import numpy as np
import remotezip as rz
import seaborn as sns
import matplotlib.pyplot as plt
import keras
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy
# Import the MoViNet model from TensorFlow Models (tf-models-official) for the MoViNet model
from official.projects.movinet.modeling import movinet
from official.projects.movinet.modeling import movinet_model
加载数据
下面的隐藏单元定义了辅助函数,用于从 UCF-101 数据集下载数据切片,并将其加载到 tf.data.Dataset 中。 加载视频数据教程 提供了此代码的详细演练。
隐藏块末尾的 FrameGenerator 类是这里最重要的实用程序。它创建一个可迭代对象,可以将数据馈送到 TensorFlow 数据管道。具体来说,此类包含一个 Python 生成器,它加载视频帧及其编码标签。生成器 (__call__) 函数生成由 frames_from_video_file 生成的帧数组和与帧集关联的标签的单热编码向量。
URL = 'https://storage.googleapis.com/thumos14_files/UCF101_videos.zip'
download_dir = pathlib.Path('./UCF101_subset/')
subset_paths = download_ufc_101_subset(URL,
num_classes = 10,
splits = {"train": 30, "test": 20},
download_dir = download_dir)
创建训练和测试数据集
batch_size = 8
num_frames = 8
output_signature = (tf.TensorSpec(shape = (None, None, None, 3), dtype = tf.float32),
tf.TensorSpec(shape = (), dtype = tf.int16))
train_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['train'], num_frames, training = True),
output_signature = output_signature)
train_ds = train_ds.batch(batch_size)
test_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['test'], num_frames),
output_signature = output_signature)
test_ds = test_ds.batch(batch_size)
这里生成的标签表示类的编码。例如,'ApplyEyeMakeup' 映射到整数。查看训练数据的标签,以确保数据集已充分洗牌。
for frames, labels in train_ds.take(10):
print(labels)
查看数据的形状。
print(f"Shape: {frames.shape}")
print(f"Label: {labels.shape}")
什么是 MoViNets?
如前所述,MoViNets 是用于流式视频或在线推理的视频分类模型,用于动作识别等任务。考虑使用 MoViNets 对您的视频数据进行分类以进行动作识别。
基于 2D 帧的分类器效率高且易于在整个视频或逐帧流式传输时运行。由于它们无法考虑时间上下文,因此它们的准确性有限,并且可能在帧与帧之间产生不一致的输出。
简单的 3D CNN 使用双向时间上下文,这可以提高准确性和时间一致性。这些网络可能需要更多资源,并且由于它们会展望未来,因此无法用于流式数据。
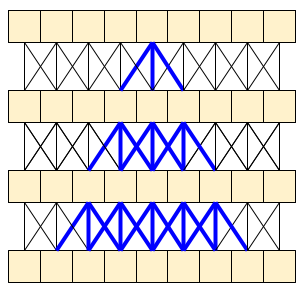
MoViNet 架构使用沿时间轴“因果”的 3D 卷积(如 layers.Conv1D,其中 padding="causal")。这带来了两种方法的一些优势,主要体现在它允许高效的流式传输。
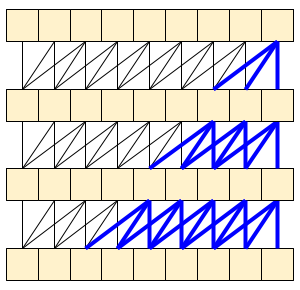
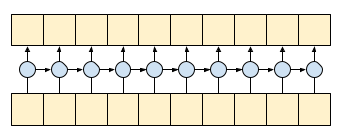
因果卷积确保时间 *t* 处的输出仅使用时间 *t* 之前的输入计算。为了演示这如何使流式传输更高效,从您可能熟悉的更简单的示例开始:RNN。RNN 将状态向前传递到时间
gru = layers.GRU(units=4, return_sequences=True, return_state=True)
inputs = tf.random.normal(shape=[1, 10, 8]) # (batch, sequence, channels)
result, state = gru(inputs) # Run it all at once
通过设置 RNN 的 return_sequences=True 参数,您要求它返回计算结束时的状态。这使您能够暂停,然后从您停止的地方继续,以获得完全相同的结果
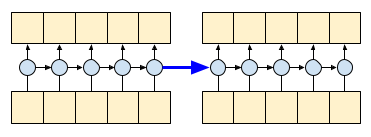
first_half, state = gru(inputs[:, :5, :]) # run the first half, and capture the state
second_half, _ = gru(inputs[:,5:, :], initial_state=state) # Use the state to continue where you left off.
print(np.allclose(result[:, :5,:], first_half))
print(np.allclose(result[:, 5:,:], second_half))
因果卷积可以以相同的方式使用,如果处理得当。此技术在 Le Paine 等人的 快速 Wavenet 生成算法 中使用。在 MoVinet 论文 中,state 被称为“流缓冲区”。
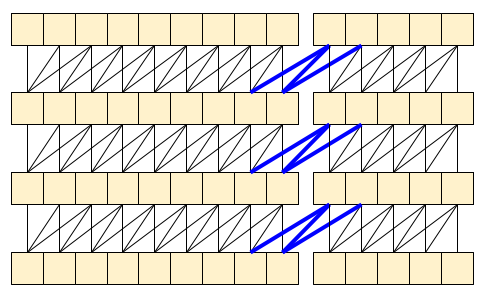
通过将这部分状态向前传递,您可以避免重新计算上面显示的整个感受野。
下载预训练的 MoViNet 模型
在本节中,您将
- 您可以使用 TensorFlow 模型中
official/projects/movinet提供的开源代码创建 MoViNet 模型。 - 加载预训练权重。
- 冻结卷积基础或除最终分类器头部之外的所有其他层,以加快微调速度。
要构建模型,您可以从 a0 配置开始,因为在与其他模型进行基准测试时,它是训练速度最快的。查看 TensorFlow 模型花园中可用的 MoViNet 模型,以找到适合您的用例的模型。
model_id = 'a0'
resolution = 224
tf.keras.backend.clear_session()
backbone = movinet.Movinet(model_id=model_id)
backbone.trainable = False
# Set num_classes=600 to load the pre-trained weights from the original model
model = movinet_model.MovinetClassifier(backbone=backbone, num_classes=600)
model.build([None, None, None, None, 3])
# Load pre-trained weights
!wget https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz -O movinet_a0_base.tar.gz -q
!tar -xvf movinet_a0_base.tar.gz
checkpoint_dir = f'movinet_{model_id}_base'
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
checkpoint = tf.train.Checkpoint(model=model)
status = checkpoint.restore(checkpoint_path)
status.assert_existing_objects_matched()
要构建分类器,请创建一个函数,该函数接受主干和数据集中的类数。 build_classifier 函数将接受主干和数据集中的类数来构建分类器。在本例中,新的分类器将接受 num_classes 输出(对于此 UCF101 子集,为 10 个类)。
def build_classifier(batch_size, num_frames, resolution, backbone, num_classes):
"""Builds a classifier on top of a backbone model."""
model = movinet_model.MovinetClassifier(
backbone=backbone,
num_classes=num_classes)
model.build([batch_size, num_frames, resolution, resolution, 3])
return model
model = build_classifier(batch_size, num_frames, resolution, backbone, 10)
在本教程中,选择 tf.keras.optimizers.Adam 优化器和 tf.keras.losses.SparseCategoricalCrossentropy 损失函数。使用度量参数查看模型性能在每一步的准确性。
num_epochs = 2
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001)
model.compile(loss=loss_obj, optimizer=optimizer, metrics=['accuracy'])
训练模型。在两个时期后,观察训练集和测试集的损失较低,准确率较高。
results = model.fit(train_ds,
validation_data=test_ds,
epochs=num_epochs,
validation_freq=1,
verbose=1)
评估模型
该模型在训练数据集上取得了很高的准确率。接下来,使用 Keras Model.evaluate 在测试集上对其进行评估。
model.evaluate(test_ds, return_dict=True)
要进一步可视化模型性能,请使用 混淆矩阵。混淆矩阵使您能够评估分类模型的性能,而不仅仅是准确率。要构建此多类分类问题的混淆矩阵,请获取测试集中的实际值和预测值。
def get_actual_predicted_labels(dataset):
"""
Create a list of actual ground truth values and the predictions from the model.
Args:
dataset: An iterable data structure, such as a TensorFlow Dataset, with features and labels.
Return:
Ground truth and predicted values for a particular dataset.
"""
actual = [labels for _, labels in dataset.unbatch()]
predicted = model.predict(dataset)
actual = tf.stack(actual, axis=0)
predicted = tf.concat(predicted, axis=0)
predicted = tf.argmax(predicted, axis=1)
return actual, predicted
def plot_confusion_matrix(actual, predicted, labels, ds_type):
cm = tf.math.confusion_matrix(actual, predicted)
ax = sns.heatmap(cm, annot=True, fmt='g')
sns.set(rc={'figure.figsize':(12, 12)})
sns.set(font_scale=1.4)
ax.set_title('Confusion matrix of action recognition for ' + ds_type)
ax.set_xlabel('Predicted Action')
ax.set_ylabel('Actual Action')
plt.xticks(rotation=90)
plt.yticks(rotation=0)
ax.xaxis.set_ticklabels(labels)
ax.yaxis.set_ticklabels(labels)
fg = FrameGenerator(subset_paths['train'], num_frames, training = True)
label_names = list(fg.class_ids_for_name.keys())
actual, predicted = get_actual_predicted_labels(test_ds)
plot_confusion_matrix(actual, predicted, label_names, 'test')
后续步骤
现在您已经熟悉了 MoViNet 模型以及如何利用各种 TensorFlow API(例如,用于迁移学习),请尝试将本教程中的代码与您自己的数据集一起使用。数据不必局限于视频数据。体积数据(如 MRI 扫描)也可以与 3D CNN 一起使用。 基于脑部 MRI 的 3D 卷积神经网络用于精神分裂症和对照组的分类 中提到的 NUSDAT 和 IMH 数据集可以是 MRI 数据的两个来源。
特别是,使用本教程中使用的 FrameGenerator 类以及其他视频数据和分类教程将帮助您将数据加载到您的模型中。
要了解有关在 TensorFlow 中使用视频数据的更多信息,请查看以下教程