
|
|
|
 在 GitHub 上查看 在 GitHub 上查看
|
|
简介
决策森林 (DF) 是一系列用于监督分类、回归和排序的机器学习算法。顾名思义,DF 使用决策树作为构建块。如今,两种最流行的 DF 训练算法是 随机森林 和 梯度提升决策树。
TensorFlow 决策森林 (TF-DF) 是一个用于训练、评估、解释和推断决策森林模型的库。
在本教程中,您将学习如何
- 在包含数值、分类和缺失特征的数据集上训练一个多类分类随机森林。
- 在测试数据集上评估模型。
- 为 TensorFlow Serving 准备模型。
- 检查模型的整体结构以及每个特征的重要性。
- 使用不同的学习算法(梯度提升决策树)重新训练模型。
- 使用不同的输入特征集。
- 更改模型的超参数。
- 预处理特征。
- 训练回归模型。
详细文档可在 用户手册 中找到。 示例目录 包含其他端到端示例。
安装 TensorFlow 决策森林
运行以下单元格安装 TF-DF。
pip install tensorflow_decision_forests
Wurlitzer 可以在 Colabs 中显示详细的训练日志(在模型构造函数中使用 verbose=2 时)。
pip install wurlitzer
导入库
import os
# Keep using Keras 2
os.environ['TF_USE_LEGACY_KERAS'] = '1'
import tensorflow_decision_forests as tfdf
import numpy as np
import pandas as pd
import tensorflow as tf
import tf_keras
import math
隐藏的代码单元格限制了 colab 中的输出高度。
# Check the version of TensorFlow Decision Forests
print("Found TensorFlow Decision Forests v" + tfdf.__version__)
Found TensorFlow Decision Forests v1.9.0
训练随机森林模型
在本节中,我们将训练、评估、分析和导出在 Palmer's Penguins 数据集上训练的多类分类随机森林。

加载数据集并将其转换为 tf.Dataset
此数据集非常小(300 个示例)并存储为 .csv 类文件。因此,使用 Pandas 加载它。
让我们将数据集组装到一个 csv 文件中(即添加标题),并加载它
# Download the dataset
!wget -q https://storage.googleapis.com/download.tensorflow.org/data/palmer_penguins/penguins.csv -O /tmp/penguins.csv
# Load a dataset into a Pandas Dataframe.
dataset_df = pd.read_csv("/tmp/penguins.csv")
# Display the first 3 examples.
dataset_df.head(3)
数据集包含数值(例如 bill_depth_mm)、分类(例如 island)和缺失特征的混合。TF-DF 本地支持所有这些特征类型(与基于 NN 的模型不同),因此无需以独热编码、归一化或额外的 is_present 特征形式进行预处理。
标签略有不同:Keras 度量指标需要整数。标签 (species) 存储为字符串,因此让我们将其转换为整数。
# Encode the categorical labels as integers.
#
# Details:
# This stage is necessary if your classification label is represented as a
# string since Keras expects integer classification labels.
# When using `pd_dataframe_to_tf_dataset` (see below), this step can be skipped.
# Name of the label column.
label = "species"
classes = dataset_df[label].unique().tolist()
print(f"Label classes: {classes}")
dataset_df[label] = dataset_df[label].map(classes.index)
Label classes: ['Adelie', 'Gentoo', 'Chinstrap']
接下来将数据集拆分为训练集和测试集
# Split the dataset into a training and a testing dataset.
def split_dataset(dataset, test_ratio=0.30):
"""Splits a panda dataframe in two."""
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples for testing.".format(
len(train_ds_pd), len(test_ds_pd)))
234 examples in training, 110 examples for testing.
最后,将 pandas 数据帧 (pd.Dataframe) 转换为 tensorflow 数据集 (tf.data.Dataset)
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_ds_pd, label=label)
注意:请记住,pd_dataframe_to_tf_dataset 会在必要时将字符串标签转换为整数。
如果您想自己创建 tf.data.Dataset,需要记住以下几点
- 学习算法使用单轮数据集,不进行洗牌。
- 批次大小不会影响训练算法,但较小的值可能会减慢数据集读取速度。
训练模型
%set_cell_height 300
# Specify the model.
model_1 = tfdf.keras.RandomForestModel(verbose=2)
# Train the model.
model_1.fit(train_ds)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpgl42iu7y as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'island': <tf.Tensor 'data:0' shape=(None,) dtype=string>, 'bill_length_mm': <tf.Tensor 'data_1:0' shape=(None,) dtype=float64>, 'bill_depth_mm': <tf.Tensor 'data_2:0' shape=(None,) dtype=float64>, 'flipper_length_mm': <tf.Tensor 'data_3:0' shape=(None,) dtype=float64>, 'body_mass_g': <tf.Tensor 'data_4:0' shape=(None,) dtype=float64>, 'sex': <tf.Tensor 'data_5:0' shape=(None,) dtype=string>, 'year': <tf.Tensor 'data_6:0' shape=(None,) dtype=int64>}
Label: Tensor("data_7:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'island': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data:0' shape=(None,) dtype=string>), 'bill_length_mm': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast:0' shape=(None,) dtype=float32>), 'bill_depth_mm': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_1:0' shape=(None,) dtype=float32>), 'flipper_length_mm': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_2:0' shape=(None,) dtype=float32>), 'body_mass_g': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_3:0' shape=(None,) dtype=float32>), 'sex': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_5:0' shape=(None,) dtype=string>), 'year': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_4:0' shape=(None,) dtype=float32>)}
Training dataset read in 0:00:03.563002. Found 234 examples.
Training model...
Standard output detected as not visible to the user e.g. running in a notebook. Creating a training log redirection. If training gets stuck, try calling tfdf.keras.set_training_logs_redirection(False).
[INFO 24-04-20 11:27:20.3668 UTC kernel.cc:771] Start Yggdrasil model training
[INFO 24-04-20 11:27:20.3669 UTC kernel.cc:772] Collect training examples
[INFO 24-04-20 11:27:20.3669 UTC kernel.cc:785] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 24-04-20 11:27:20.3673 UTC kernel.cc:391] Number of batches: 1
[INFO 24-04-20 11:27:20.3673 UTC kernel.cc:392] Number of examples: 234
[INFO 24-04-20 11:27:20.3674 UTC kernel.cc:792] Training dataset:
Number of records: 234
Number of columns: 8
Number of columns by type:
NUMERICAL: 5 (62.5%)
CATEGORICAL: 3 (37.5%)
Columns:
NUMERICAL: 5 (62.5%)
1: "bill_depth_mm" NUMERICAL num-nas:2 (0.854701%) mean:17.3017 min:13.1 max:21.5 sd:1.99344
2: "bill_length_mm" NUMERICAL num-nas:2 (0.854701%) mean:43.6638 min:33.1 max:58 sd:5.51148
3: "body_mass_g" NUMERICAL num-nas:2 (0.854701%) mean:4169.07 min:2700 max:6000 sd:769.201
4: "flipper_length_mm" NUMERICAL num-nas:2 (0.854701%) mean:200.017 min:172 max:231 sd:13.7577
7: "year" NUMERICAL mean:2008.02 min:2007 max:2009 sd:0.818831
CATEGORICAL: 3 (37.5%)
0: "__LABEL" CATEGORICAL integerized vocab-size:4 no-ood-item
5: "island" CATEGORICAL has-dict vocab-size:4 zero-ood-items most-frequent:"Biscoe" 104 (44.4444%)
6: "sex" CATEGORICAL num-nas:10 (4.2735%) has-dict vocab-size:3 zero-ood-items most-frequent:"male" 113 (50.4464%)
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute whose type is manually defined by the user, i.e., the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 24-04-20 11:27:20.3674 UTC kernel.cc:808] Configure learner
[INFO 24-04-20 11:27:20.3676 UTC kernel.cc:822] Training config:
learner: "RANDOM_FOREST"
features: "^bill_depth_mm$"
features: "^bill_length_mm$"
features: "^body_mass_g$"
features: "^flipper_length_mm$"
features: "^island$"
features: "^sex$"
features: "^year$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 123456
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 300
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
[INFO 24-04-20 11:27:20.3679 UTC kernel.cc:825] Deployment config:
cache_path: "/tmpfs/tmp/tmpgl42iu7y/working_cache"
num_threads: 32
try_resume_training: true
[INFO 24-04-20 11:27:20.3680 UTC kernel.cc:887] Train model
[INFO 24-04-20 11:27:20.3681 UTC random_forest.cc:416] Training random forest on 234 example(s) and 7 feature(s).
[INFO 24-04-20 11:27:20.3735 UTC random_forest.cc:802] Training of tree 1/300 (tree index:1) done accuracy:0.965116 logloss:1.25734
[INFO 24-04-20 11:27:20.3737 UTC random_forest.cc:802] Training of tree 11/300 (tree index:15) done accuracy:0.933628 logloss:1.02455
[INFO 24-04-20 11:27:20.3738 UTC random_forest.cc:802] Training of tree 21/300 (tree index:23) done accuracy:0.943478 logloss:0.407439
[INFO 24-04-20 11:27:20.3741 UTC random_forest.cc:802] Training of tree 31/300 (tree index:19) done accuracy:0.956897 logloss:0.407383
[INFO 24-04-20 11:27:20.3742 UTC random_forest.cc:802] Training of tree 41/300 (tree index:43) done accuracy:0.961538 logloss:0.244551
[INFO 24-04-20 11:27:20.3744 UTC random_forest.cc:802] Training of tree 51/300 (tree index:45) done accuracy:0.970085 logloss:0.236479
[INFO 24-04-20 11:27:20.3748 UTC random_forest.cc:802] Training of tree 62/300 (tree index:61) done accuracy:0.982906 logloss:0.237691
[INFO 24-04-20 11:27:20.3753 UTC random_forest.cc:802] Training of tree 73/300 (tree index:71) done accuracy:0.978632 logloss:0.232261
[INFO 24-04-20 11:27:20.3756 UTC random_forest.cc:802] Training of tree 83/300 (tree index:82) done accuracy:0.978632 logloss:0.232691
[INFO 24-04-20 11:27:20.3759 UTC random_forest.cc:802] Training of tree 93/300 (tree index:91) done accuracy:0.970085 logloss:0.233783
[INFO 24-04-20 11:27:20.3763 UTC random_forest.cc:802] Training of tree 103/300 (tree index:104) done accuracy:0.965812 logloss:0.237368
[INFO 24-04-20 11:27:20.3766 UTC random_forest.cc:802] Training of tree 113/300 (tree index:113) done accuracy:0.970085 logloss:0.233664
[INFO 24-04-20 11:27:20.3770 UTC random_forest.cc:802] Training of tree 123/300 (tree index:121) done accuracy:0.965812 logloss:0.23413
[INFO 24-04-20 11:27:20.3773 UTC random_forest.cc:802] Training of tree 134/300 (tree index:134) done accuracy:0.965812 logloss:0.235113
[INFO 24-04-20 11:27:20.3777 UTC random_forest.cc:802] Training of tree 144/300 (tree index:141) done accuracy:0.974359 logloss:0.234239
[INFO 24-04-20 11:27:20.3779 UTC random_forest.cc:802] Training of tree 154/300 (tree index:153) done accuracy:0.974359 logloss:0.2342
[INFO 24-04-20 11:27:20.3782 UTC random_forest.cc:802] Training of tree 164/300 (tree index:165) done accuracy:0.970085 logloss:0.234106
[INFO 24-04-20 11:27:20.3785 UTC random_forest.cc:802] Training of tree 176/300 (tree index:176) done accuracy:0.965812 logloss:0.234139
[INFO 24-04-20 11:27:20.3789 UTC random_forest.cc:802] Training of tree 188/300 (tree index:188) done accuracy:0.974359 logloss:0.233883
[INFO 24-04-20 11:27:20.3792 UTC random_forest.cc:802] Training of tree 198/300 (tree index:196) done accuracy:0.970085 logloss:0.235074
[INFO 24-04-20 11:27:20.3796 UTC random_forest.cc:802] Training of tree 209/300 (tree index:207) done accuracy:0.974359 logloss:0.234659
[INFO 24-04-20 11:27:20.3800 UTC random_forest.cc:802] Training of tree 219/300 (tree index:217) done accuracy:0.974359 logloss:0.235555
[INFO 24-04-20 11:27:20.3803 UTC random_forest.cc:802] Training of tree 230/300 (tree index:228) done accuracy:0.978632 logloss:0.235329
[INFO 24-04-20 11:27:20.3806 UTC random_forest.cc:802] Training of tree 240/300 (tree index:236) done accuracy:0.978632 logloss:0.235235
[INFO 24-04-20 11:27:20.3810 UTC random_forest.cc:802] Training of tree 252/300 (tree index:255) done accuracy:0.982906 logloss:0.100556
[INFO 24-04-20 11:27:20.3812 UTC random_forest.cc:802] Training of tree 262/300 (tree index:261) done accuracy:0.982906 logloss:0.100609
[INFO 24-04-20 11:27:20.3816 UTC random_forest.cc:802] Training of tree 272/300 (tree index:270) done accuracy:0.982906 logloss:0.100364
[INFO 24-04-20 11:27:20.3818 UTC random_forest.cc:802] Training of tree 282/300 (tree index:281) done accuracy:0.982906 logloss:0.100134
[INFO 24-04-20 11:27:20.3821 UTC random_forest.cc:802] Training of tree 293/300 (tree index:289) done accuracy:0.982906 logloss:0.0974547
[INFO 24-04-20 11:27:20.3825 UTC random_forest.cc:802] Training of tree 300/300 (tree index:299) done accuracy:0.982906 logloss:0.0978464
[INFO 24-04-20 11:27:20.3838 UTC random_forest.cc:882] Final OOB metrics: accuracy:0.982906 logloss:0.0978464
[INFO 24-04-20 11:27:20.3845 UTC kernel.cc:919] Export model in log directory: /tmpfs/tmp/tmpgl42iu7y with prefix 961cde2ce225418a
[INFO 24-04-20 11:27:20.3878 UTC kernel.cc:937] Save model in resources
[INFO 24-04-20 11:27:20.3910 UTC abstract_model.cc:881] Model self evaluation:
Number of predictions (without weights): 234
Number of predictions (with weights): 234
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.982906 CI95[W][0.961312 0.994141]
LogLoss: : 0.0978464
ErrorRate: : 0.017094
Default Accuracy: : 0.470085
Default LogLoss: : 1.043
Default ErrorRate: : 0.529914
Confusion Table:
truth\prediction
1 2 3
1 110 0 0
2 1 76 0
3 3 0 44
Total: 234
[INFO 24-04-20 11:27:20.4014 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpgl42iu7y/model/ with prefix 961cde2ce225418a
[INFO 24-04-20 11:27:20.4150 UTC decision_forest.cc:734] Model loaded with 300 root(s), 4240 node(s), and 7 input feature(s).
[INFO 24-04-20 11:27:20.4150 UTC abstract_model.cc:1344] Engine "RandomForestGeneric" built
[INFO 24-04-20 11:27:20.4151 UTC kernel.cc:1061] Use fast generic engine
Model trained in 0:00:00.056720
Compiling model...
Model compiled.
<tf_keras.src.callbacks.History at 0x7f554a20a400>
备注
- 没有指定输入特征。因此,除了标签外,所有列都将用作输入特征。模型使用的特征显示在训练日志和
model.summary()中。 - DF 本身支持数值、分类、分类集和缺失值特征。数值特征不需要进行归一化。分类字符串值不需要在字典中编码。
- 没有指定训练超参数。因此将使用默认超参数。默认超参数在大多数情况下都能提供合理的结果。
- 在
fit之前调用模型上的compile是可选的。Compile 可用于提供额外的评估指标。 - 训练算法不需要验证数据集。如果提供了验证数据集,它将仅用于显示指标。
- 调整
RandomForestModel的verbose参数以控制显示的训练日志数量。将verbose=0设置为隐藏大部分日志。将verbose=2设置为显示所有日志。
评估模型
让我们在测试数据集上评估我们的模型。
model_1.compile(metrics=["accuracy"])
evaluation = model_1.evaluate(test_ds, return_dict=True)
print()
for name, value in evaluation.items():
print(f"{name}: {value:.4f}")
1/1 [==============================] - 4s 4s/step - loss: 0.0000e+00 - accuracy: 0.9727 loss: 0.0000 accuracy: 0.9727
备注:测试准确率接近训练日志中显示的袋外准确率。
有关更多评估方法,请参见下面的模型自我评估部分。
为 TensorFlow Serving 准备此模型。
将模型导出为 SavedModel 格式,以便以后重新使用,例如 TensorFlow Serving。
model_1.save("/tmp/my_saved_model")
INFO:tensorflow:Assets written to: /tmp/my_saved_model/assets INFO:tensorflow:Assets written to: /tmp/my_saved_model/assets
绘制模型
绘制决策树并跟踪第一个分支有助于了解决策森林。在某些情况下,绘制模型甚至可以用于调试。
由于训练方式不同,某些模型比其他模型更有趣。由于训练过程中注入的噪声和树的深度,绘制随机森林不如绘制 CART 或梯度提升树的第一棵树信息量大。
尽管如此,让我们绘制随机森林模型的第一棵树
tfdf.model_plotter.plot_model_in_colab(model_1, tree_idx=0, max_depth=3)
左侧的根节点包含第一个条件 (bill_depth_mm >= 16.55)、示例数量 (240) 和标签分布(红蓝绿条)。
对 bill_depth_mm >= 16.55 评估为真的示例将分支到绿色路径。其他示例将分支到红色路径。
节点越深,它们就越 纯净,即标签分布偏向于一组类别。
模型结构和特征重要性
模型的整体结构使用 .summary() 显示。您将看到
- 类型:用于训练模型的学习算法(在本例中为
Random Forest)。 - 任务:模型解决的问题(在本例中为
Classification)。 - 输入特征:模型的输入特征。
- 变量重要性:模型中每个特征重要性的不同度量。
- 袋外评估:模型的袋外评估。这是交叉验证的一种廉价且有效的替代方法。
- {树、节点} 数量和其他指标:有关决策森林结构的统计信息。
备注:摘要的内容取决于学习算法(例如,袋外评估仅适用于随机森林)和超参数(例如,平均准确率下降变量重要性可以在超参数中禁用)。
%set_cell_height 300
model_1.summary()
<IPython.core.display.Javascript object>
Model: "random_forest_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
=================================================================
Total params: 1 (1.00 Byte)
Trainable params: 0 (0.00 Byte)
Non-trainable params: 1 (1.00 Byte)
_________________________________________________________________
Type: "RANDOM_FOREST"
Task: CLASSIFICATION
Label: "__LABEL"
Input Features (7):
bill_depth_mm
bill_length_mm
body_mass_g
flipper_length_mm
island
sex
year
No weights
Variable Importance: INV_MEAN_MIN_DEPTH:
1. "bill_length_mm" 0.433248 ################
2. "flipper_length_mm" 0.425701 ###############
3. "bill_depth_mm" 0.339868 ########
4. "island" 0.310357 #####
5. "body_mass_g" 0.265660 ##
6. "year" 0.240946
7. "sex" 0.240878
Variable Importance: NUM_AS_ROOT:
1. "flipper_length_mm" 144.000000 ################
2. "bill_length_mm" 71.000000 ######
3. "bill_depth_mm" 70.000000 ######
4. "island" 15.000000
Variable Importance: NUM_NODES:
1. "bill_length_mm" 635.000000 ################
2. "bill_depth_mm" 429.000000 ##########
3. "flipper_length_mm" 361.000000 ########
4. "island" 270.000000 ######
5. "body_mass_g" 248.000000 ######
6. "year" 15.000000
7. "sex" 12.000000
Variable Importance: SUM_SCORE:
1. "bill_length_mm" 24225.575658 ################
2. "flipper_length_mm" 21710.896990 ##############
3. "bill_depth_mm" 12335.470280 ########
4. "island" 9906.132873 ######
5. "body_mass_g" 1778.457588 #
6. "sex" 105.098996
7. "year" 32.349991
Winner takes all: true
Out-of-bag evaluation: accuracy:0.982906 logloss:0.0978464
Number of trees: 300
Total number of nodes: 4240
Number of nodes by tree:
Count: 300 Average: 14.1333 StdDev: 2.74145
Min: 7 Max: 27 Ignored: 0
----------------------------------------------
[ 7, 8) 1 0.33% 0.33%
[ 8, 9) 0 0.00% 0.33%
[ 9, 10) 14 4.67% 5.00% ##
[ 10, 11) 0 0.00% 5.00%
[ 11, 12) 44 14.67% 19.67% #####
[ 12, 13) 0 0.00% 19.67%
[ 13, 14) 90 30.00% 49.67% ##########
[ 14, 15) 0 0.00% 49.67%
[ 15, 16) 93 31.00% 80.67% ##########
[ 16, 17) 0 0.00% 80.67%
[ 17, 18) 35 11.67% 92.33% ####
[ 18, 19) 0 0.00% 92.33%
[ 19, 20) 16 5.33% 97.67% ##
[ 20, 21) 0 0.00% 97.67%
[ 21, 22) 4 1.33% 99.00%
[ 22, 23) 0 0.00% 99.00%
[ 23, 24) 1 0.33% 99.33%
[ 24, 25) 0 0.00% 99.33%
[ 25, 26) 1 0.33% 99.67%
[ 26, 27] 1 0.33% 100.00%
Depth by leafs:
Count: 2270 Average: 3.22907 StdDev: 0.985105
Min: 1 Max: 7 Ignored: 0
----------------------------------------------
[ 1, 2) 28 1.23% 1.23%
[ 2, 3) 539 23.74% 24.98% #######
[ 3, 4) 828 36.48% 61.45% ##########
[ 4, 5) 669 29.47% 90.93% ########
[ 5, 6) 176 7.75% 98.68% ##
[ 6, 7) 26 1.15% 99.82%
[ 7, 7] 4 0.18% 100.00%
Number of training obs by leaf:
Count: 2270 Average: 30.9251 StdDev: 30.5457
Min: 5 Max: 114 Ignored: 0
----------------------------------------------
[ 5, 10) 1061 46.74% 46.74% ##########
[ 10, 16) 123 5.42% 52.16% #
[ 16, 21) 67 2.95% 55.11% #
[ 21, 27) 65 2.86% 57.97% #
[ 27, 32) 67 2.95% 60.93% #
[ 32, 38) 96 4.23% 65.15% #
[ 38, 43) 85 3.74% 68.90% #
[ 43, 49) 71 3.13% 72.03% #
[ 49, 54) 46 2.03% 74.05%
[ 54, 60) 45 1.98% 76.04%
[ 60, 65) 60 2.64% 78.68% #
[ 65, 71) 117 5.15% 83.83% #
[ 71, 76) 103 4.54% 88.37% #
[ 76, 82) 72 3.17% 91.54% #
[ 82, 87) 51 2.25% 93.79%
[ 87, 93) 47 2.07% 95.86%
[ 93, 98) 31 1.37% 97.22%
[ 98, 104) 32 1.41% 98.63%
[ 104, 109) 21 0.93% 99.56%
[ 109, 114] 10 0.44% 100.00%
Attribute in nodes:
635 : bill_length_mm [NUMERICAL]
429 : bill_depth_mm [NUMERICAL]
361 : flipper_length_mm [NUMERICAL]
270 : island [CATEGORICAL]
248 : body_mass_g [NUMERICAL]
15 : year [NUMERICAL]
12 : sex [CATEGORICAL]
Attribute in nodes with depth <= 0:
144 : flipper_length_mm [NUMERICAL]
71 : bill_length_mm [NUMERICAL]
70 : bill_depth_mm [NUMERICAL]
15 : island [CATEGORICAL]
Attribute in nodes with depth <= 1:
262 : bill_length_mm [NUMERICAL]
228 : flipper_length_mm [NUMERICAL]
190 : bill_depth_mm [NUMERICAL]
144 : island [CATEGORICAL]
48 : body_mass_g [NUMERICAL]
Attribute in nodes with depth <= 2:
432 : bill_length_mm [NUMERICAL]
336 : bill_depth_mm [NUMERICAL]
305 : flipper_length_mm [NUMERICAL]
228 : island [CATEGORICAL]
168 : body_mass_g [NUMERICAL]
5 : year [NUMERICAL]
3 : sex [CATEGORICAL]
Attribute in nodes with depth <= 3:
589 : bill_length_mm [NUMERICAL]
403 : bill_depth_mm [NUMERICAL]
351 : flipper_length_mm [NUMERICAL]
263 : island [CATEGORICAL]
231 : body_mass_g [NUMERICAL]
11 : year [NUMERICAL]
11 : sex [CATEGORICAL]
Attribute in nodes with depth <= 5:
633 : bill_length_mm [NUMERICAL]
429 : bill_depth_mm [NUMERICAL]
361 : flipper_length_mm [NUMERICAL]
270 : island [CATEGORICAL]
248 : body_mass_g [NUMERICAL]
15 : year [NUMERICAL]
12 : sex [CATEGORICAL]
Condition type in nodes:
1688 : HigherCondition
282 : ContainsBitmapCondition
Condition type in nodes with depth <= 0:
285 : HigherCondition
15 : ContainsBitmapCondition
Condition type in nodes with depth <= 1:
728 : HigherCondition
144 : ContainsBitmapCondition
Condition type in nodes with depth <= 2:
1246 : HigherCondition
231 : ContainsBitmapCondition
Condition type in nodes with depth <= 3:
1585 : HigherCondition
274 : ContainsBitmapCondition
Condition type in nodes with depth <= 5:
1686 : HigherCondition
282 : ContainsBitmapCondition
Node format: NOT_SET
Training OOB:
trees: 1, Out-of-bag evaluation: accuracy:0.965116 logloss:1.25734
trees: 11, Out-of-bag evaluation: accuracy:0.933628 logloss:1.02455
trees: 21, Out-of-bag evaluation: accuracy:0.943478 logloss:0.407439
trees: 31, Out-of-bag evaluation: accuracy:0.956897 logloss:0.407383
trees: 41, Out-of-bag evaluation: accuracy:0.961538 logloss:0.244551
trees: 51, Out-of-bag evaluation: accuracy:0.970085 logloss:0.236479
trees: 62, Out-of-bag evaluation: accuracy:0.982906 logloss:0.237691
trees: 73, Out-of-bag evaluation: accuracy:0.978632 logloss:0.232261
trees: 83, Out-of-bag evaluation: accuracy:0.978632 logloss:0.232691
trees: 93, Out-of-bag evaluation: accuracy:0.970085 logloss:0.233783
trees: 103, Out-of-bag evaluation: accuracy:0.965812 logloss:0.237368
trees: 113, Out-of-bag evaluation: accuracy:0.970085 logloss:0.233664
trees: 123, Out-of-bag evaluation: accuracy:0.965812 logloss:0.23413
trees: 134, Out-of-bag evaluation: accuracy:0.965812 logloss:0.235113
trees: 144, Out-of-bag evaluation: accuracy:0.974359 logloss:0.234239
trees: 154, Out-of-bag evaluation: accuracy:0.974359 logloss:0.2342
trees: 164, Out-of-bag evaluation: accuracy:0.970085 logloss:0.234106
trees: 176, Out-of-bag evaluation: accuracy:0.965812 logloss:0.234139
trees: 188, Out-of-bag evaluation: accuracy:0.974359 logloss:0.233883
trees: 198, Out-of-bag evaluation: accuracy:0.970085 logloss:0.235074
trees: 209, Out-of-bag evaluation: accuracy:0.974359 logloss:0.234659
trees: 219, Out-of-bag evaluation: accuracy:0.974359 logloss:0.235555
trees: 230, Out-of-bag evaluation: accuracy:0.978632 logloss:0.235329
trees: 240, Out-of-bag evaluation: accuracy:0.978632 logloss:0.235235
trees: 252, Out-of-bag evaluation: accuracy:0.982906 logloss:0.100556
trees: 262, Out-of-bag evaluation: accuracy:0.982906 logloss:0.100609
trees: 272, Out-of-bag evaluation: accuracy:0.982906 logloss:0.100364
trees: 282, Out-of-bag evaluation: accuracy:0.982906 logloss:0.100134
trees: 293, Out-of-bag evaluation: accuracy:0.982906 logloss:0.0974547
trees: 300, Out-of-bag evaluation: accuracy:0.982906 logloss:0.0978464
可以使用模型检查器以编程方式获取 summary 中的所有信息
# The input features
model_1.make_inspector().features()
["bill_depth_mm" (1; #1), "bill_length_mm" (1; #2), "body_mass_g" (1; #3), "flipper_length_mm" (1; #4), "island" (4; #5), "sex" (4; #6), "year" (1; #7)]
# The feature importances
model_1.make_inspector().variable_importances()
{'NUM_AS_ROOT': [("flipper_length_mm" (1; #4), 144.0),
("bill_length_mm" (1; #2), 71.0),
("bill_depth_mm" (1; #1), 70.0),
("island" (4; #5), 15.0)],
'INV_MEAN_MIN_DEPTH': [("bill_length_mm" (1; #2), 0.433247623310692),
("flipper_length_mm" (1; #4), 0.4257012578458594),
("bill_depth_mm" (1; #1), 0.33986815273566884),
("island" (4; #5), 0.3103574219243868),
("body_mass_g" (1; #3), 0.265660470712275),
("year" (1; #7), 0.24094560867958406),
("sex" (4; #6), 0.24087838553247407)],
'SUM_SCORE': [("bill_length_mm" (1; #2), 24225.575658487156),
("flipper_length_mm" (1; #4), 21710.89699044265),
("bill_depth_mm" (1; #1), 12335.470280339941),
("island" (4; #5), 9906.132873054594),
("body_mass_g" (1; #3), 1778.4575882293284),
("sex" (4; #6), 105.09899555891752),
("year" (1; #7), 32.34999070875347)],
'NUM_NODES': [("bill_length_mm" (1; #2), 635.0),
("bill_depth_mm" (1; #1), 429.0),
("flipper_length_mm" (1; #4), 361.0),
("island" (4; #5), 270.0),
("body_mass_g" (1; #3), 248.0),
("year" (1; #7), 15.0),
("sex" (4; #6), 12.0)]}
摘要和检查器的内容取决于学习算法(在本例中为 tfdf.keras.RandomForestModel)及其超参数(例如,compute_oob_variable_importances=True 将触发对随机森林学习器的袋外变量重要性的计算)。
模型自我评估
在训练期间,TFDF 模型可以自我评估,即使 fit() 方法没有提供验证数据集。确切的逻辑取决于模型。例如,随机森林将使用袋外评估,而梯度提升树将使用内部训练验证。
可以使用检查器的 evaluation() 获取模型自我评估
model_1.make_inspector().evaluation()
Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.09784645201940821, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)
绘制训练日志
训练日志显示了模型的质量(例如,在袋外或验证数据集上评估的准确率),根据模型中的树木数量。这些日志有助于研究模型大小和模型质量之间的平衡。
日志可以通过多种方式获取
- 如果
fit()包裹在with sys_pipes():中,则在训练期间显示(请参见上面的示例)。 - 在模型摘要的末尾,即
model.summary()(请参见上面的示例)。 - 以编程方式,使用模型检查器,即
model.make_inspector().training_logs()。 - 使用 TensorBoard
让我们尝试选项 2 和 3
%set_cell_height 150
model_1.make_inspector().training_logs()
<IPython.core.display.Javascript object> [TrainLog(num_trees=1, evaluation=Evaluation(num_examples=86, accuracy=0.9651162790697675, loss=1.2573366830515307, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=11, evaluation=Evaluation(num_examples=226, accuracy=0.9336283185840708, loss=1.0245515205032003, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=21, evaluation=Evaluation(num_examples=230, accuracy=0.9434782608695652, loss=0.4074386193700459, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=31, evaluation=Evaluation(num_examples=232, accuracy=0.9568965517241379, loss=0.40738303143659543, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=41, evaluation=Evaluation(num_examples=234, accuracy=0.9615384615384616, loss=0.2445512147158639, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=51, evaluation=Evaluation(num_examples=234, accuracy=0.9700854700854701, loss=0.23647892952729493, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=62, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.2376908617746881, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=73, evaluation=Evaluation(num_examples=234, accuracy=0.9786324786324786, loss=0.23226140116333452, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=83, evaluation=Evaluation(num_examples=234, accuracy=0.9786324786324786, loss=0.23269128901326758, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=93, evaluation=Evaluation(num_examples=234, accuracy=0.9700854700854701, loss=0.23378307322979483, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=103, evaluation=Evaluation(num_examples=234, accuracy=0.9658119658119658, loss=0.23736755182154667, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=113, evaluation=Evaluation(num_examples=234, accuracy=0.9700854700854701, loss=0.23366377585464054, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=123, evaluation=Evaluation(num_examples=234, accuracy=0.9658119658119658, loss=0.23413042780648693, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=134, evaluation=Evaluation(num_examples=234, accuracy=0.9658119658119658, loss=0.235113016074985, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=144, evaluation=Evaluation(num_examples=234, accuracy=0.9743589743589743, loss=0.23423931028884956, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=154, evaluation=Evaluation(num_examples=234, accuracy=0.9743589743589743, loss=0.2342000381511628, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=164, evaluation=Evaluation(num_examples=234, accuracy=0.9700854700854701, loss=0.23410625161969253, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=176, evaluation=Evaluation(num_examples=234, accuracy=0.9658119658119658, loss=0.23413927984447816, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=188, evaluation=Evaluation(num_examples=234, accuracy=0.9743589743589743, loss=0.23388283870891374, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=198, evaluation=Evaluation(num_examples=234, accuracy=0.9700854700854701, loss=0.23507367600249046, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=209, evaluation=Evaluation(num_examples=234, accuracy=0.9743589743589743, loss=0.23465900274359772, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=219, evaluation=Evaluation(num_examples=234, accuracy=0.9743589743589743, loss=0.23555457142667255, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=230, evaluation=Evaluation(num_examples=234, accuracy=0.9786324786324786, loss=0.23532893037439412, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=240, evaluation=Evaluation(num_examples=234, accuracy=0.9786324786324786, loss=0.23523502994296897, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=252, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.10055625600676633, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=262, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.10060906670112003, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=272, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.10036396928147501, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=282, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.10013380316762716, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=293, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.0974546640426812, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)), TrainLog(num_trees=300, evaluation=Evaluation(num_examples=234, accuracy=0.9829059829059829, loss=0.09784645201940821, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None))]
让我们绘制它
import matplotlib.pyplot as plt
logs = model_1.make_inspector().training_logs()
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Accuracy (out-of-bag)")
plt.subplot(1, 2, 2)
plt.plot([log.num_trees for log in logs], [log.evaluation.loss for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Logloss (out-of-bag)")
plt.show()
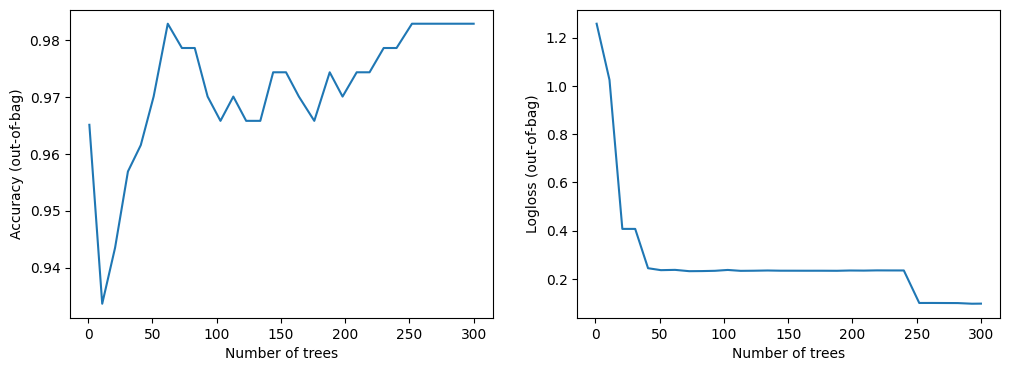
此数据集很小。您可以看到模型几乎立即收敛。
让我们使用 TensorBoard
# This cell start TensorBoard that can be slow.
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Google internal version
# %load_ext google3.learning.brain.tensorboard.notebook.extension
# Clear existing results (if any)rm -fr "/tmp/tensorboard_logs"
# Export the meta-data to tensorboard.
model_1.make_inspector().export_to_tensorboard("/tmp/tensorboard_logs")
# docs_infra: no_execute
# Start a tensorboard instance.
%tensorboard --logdir "/tmp/tensorboard_logs"
使用不同的学习算法重新训练模型
学习算法由模型类定义。例如,tfdf.keras.RandomForestModel() 训练随机森林,而 tfdf.keras.GradientBoostedTreesModel() 训练梯度提升决策树。
可以通过调用 tfdf.keras.get_all_models() 或在 学习器列表 中列出学习算法。
tfdf.keras.get_all_models()
[tensorflow_decision_forests.keras.RandomForestModel, tensorflow_decision_forests.keras.GradientBoostedTreesModel, tensorflow_decision_forests.keras.CartModel, tensorflow_decision_forests.keras.DistributedGradientBoostedTreesModel]
学习算法及其超参数的描述也包含在 API 参考 和内置帮助中
# help works anywhere.
help(tfdf.keras.RandomForestModel)
# ? only works in ipython or notebooks, it usually opens on a separate panel.
tfdf.keras.RandomForestModel?
Help on class RandomForestModel in module tensorflow_decision_forests.keras:
class RandomForestModel(tensorflow_decision_forests.keras.wrappers.RandomForestModel)
| RandomForestModel(*args, **kwargs)
|
| Method resolution order:
| RandomForestModel
| tensorflow_decision_forests.keras.wrappers.RandomForestModel
| tensorflow_decision_forests.keras.core.CoreModel
| tensorflow_decision_forests.keras.core_inference.InferenceCoreModel
| tf_keras.src.engine.training.Model
| tf_keras.src.engine.base_layer.Layer
| tensorflow.python.module.module.Module
| tensorflow.python.trackable.autotrackable.AutoTrackable
| tensorflow.python.trackable.base.Trackable
| tf_keras.src.utils.version_utils.LayerVersionSelector
| tf_keras.src.utils.version_utils.ModelVersionSelector
| builtins.object
|
| Methods inherited from tensorflow_decision_forests.keras.wrappers.RandomForestModel:
|
| __init__(self, task: Optional[ForwardRef('abstract_model_pb2.Task')] = 1, features: Optional[List[tensorflow_decision_forests.keras.core.FeatureUsage]] = None, exclude_non_specified_features: Optional[bool] = False, preprocessing: Optional[ForwardRef('tf_keras.models.Functional')] = None, postprocessing: Optional[ForwardRef('tf_keras.models.Functional')] = None, training_preprocessing: Optional[ForwardRef('tf_keras.models.Functional')] = None, ranking_group: Optional[str] = None, uplift_treatment: Optional[str] = None, temp_directory: Optional[str] = None, verbose: int = 1, hyperparameter_template: Optional[str] = None, advanced_arguments: Optional[tensorflow_decision_forests.keras.core_inference.AdvancedArguments] = None, num_threads: Optional[int] = None, name: Optional[str] = None, max_vocab_count: Optional[int] = 2000, try_resume_training: Optional[bool] = True, check_dataset: Optional[bool] = True, tuner: Optional[tensorflow_decision_forests.component.tuner.tuner.Tuner] = None, discretize_numerical_features: bool = False, num_discretized_numerical_bins: int = 255, multitask: Optional[List[tensorflow_decision_forests.keras.core_inference.MultiTaskItem]] = None, adapt_bootstrap_size_ratio_for_maximum_training_duration: Optional[bool] = False, allow_na_conditions: Optional[bool] = False, bootstrap_size_ratio: Optional[float] = 1.0, bootstrap_training_dataset: Optional[bool] = True, categorical_algorithm: Optional[str] = 'CART', categorical_set_split_greedy_sampling: Optional[float] = 0.1, categorical_set_split_max_num_items: Optional[int] = -1, categorical_set_split_min_item_frequency: Optional[int] = 1, compute_oob_performances: Optional[bool] = True, compute_oob_variable_importances: Optional[bool] = False, growing_strategy: Optional[str] = 'LOCAL', honest: Optional[bool] = False, honest_fixed_separation: Optional[bool] = False, honest_ratio_leaf_examples: Optional[float] = 0.5, in_split_min_examples_check: Optional[bool] = True, keep_non_leaf_label_distribution: Optional[bool] = True, max_depth: Optional[int] = 16, max_num_nodes: Optional[int] = None, maximum_model_size_in_memory_in_bytes: Optional[float] = -1.0, maximum_training_duration_seconds: Optional[float] = -1.0, min_examples: Optional[int] = 5, missing_value_policy: Optional[str] = 'GLOBAL_IMPUTATION', num_candidate_attributes: Optional[int] = 0, num_candidate_attributes_ratio: Optional[float] = -1.0, num_oob_variable_importances_permutations: Optional[int] = 1, num_trees: Optional[int] = 300, pure_serving_model: Optional[bool] = False, random_seed: Optional[int] = 123456, sampling_with_replacement: Optional[bool] = True, sorting_strategy: Optional[str] = 'PRESORT', sparse_oblique_max_num_projections: Optional[int] = None, sparse_oblique_normalization: Optional[str] = None, sparse_oblique_num_projections_exponent: Optional[float] = None, sparse_oblique_projection_density_factor: Optional[float] = None, sparse_oblique_weights: Optional[str] = None, split_axis: Optional[str] = 'AXIS_ALIGNED', uplift_min_examples_in_treatment: Optional[int] = 5, uplift_split_score: Optional[str] = 'KULLBACK_LEIBLER', winner_take_all: Optional[bool] = True, explicit_args: Optional[Set[str]] = None)
|
| ----------------------------------------------------------------------
| Static methods inherited from tensorflow_decision_forests.keras.wrappers.RandomForestModel:
|
| capabilities() -> yggdrasil_decision_forests.learner.abstract_learner_pb2.LearnerCapabilities
| Lists the capabilities of the learning algorithm.
|
| predefined_hyperparameters() -> List[tensorflow_decision_forests.keras.core.HyperParameterTemplate]
| Returns a better than default set of hyper-parameters.
|
| They can be used directly with the `hyperparameter_template` argument of the
| model constructor.
|
| These hyper-parameters outperform the default hyper-parameters (either
| generally or in specific scenarios). Like default hyper-parameters, existing
| pre-defined hyper-parameters cannot change.
|
| ----------------------------------------------------------------------
| Methods inherited from tensorflow_decision_forests.keras.core.CoreModel:
|
| collect_data_step(self, data, is_training_example)
| Collect examples e.g. training or validation.
|
| fit(self, x=None, y=None, callbacks=None, verbose: Optional[Any] = None, validation_steps: Optional[int] = None, validation_data: Optional[Any] = None, sample_weight: Optional[Any] = None, steps_per_epoch: Optional[Any] = None, class_weight: Optional[Any] = None, **kwargs) -> tf_keras.src.callbacks.History
| Trains the model.
|
| Local training
| ==============
|
| It is recommended to use a Pandas Dataframe dataset and to convert it to
| a TensorFlow dataset with `pd_dataframe_to_tf_dataset()`:
| ```python
| pd_dataset = pandas.Dataframe(...)
| tf_dataset = pd_dataframe_to_tf_dataset(dataset, label="my_label")
| model.fit(pd_dataset)
| ```
|
| The following dataset formats are supported:
|
| 1. "x" is a `tf.data.Dataset` containing a tuple "(features, labels)".
| "features" can be a dictionary a tensor, a list of tensors or a
| dictionary of tensors (recommended). "labels" is a tensor.
|
| 2. "x" is a tensor, list of tensors or dictionary of tensors containing
| the input features. "y" is a tensor.
|
| 3. "x" is a numpy-array, list of numpy-arrays or dictionary of
| numpy-arrays containing the input features. "y" is a numpy-array.
|
| IMPORTANT: This model trains on the entire dataset at once. This has the
| following consequences:
|
| 1. The dataset need to be read exactly once. If you use a TensorFlow
| dataset, make sure NOT to add a "repeat" operation.
| 2. The algorithm does not benefit from shuffling the dataset. If you use a
| TensorFlow dataset, make sure NOT to add a "shuffle" operation.
| 3. The dataset needs to be batched (i.e. with a "batch" operation).
| However, the number of elements per batch has not impact on the model.
| Generally, it is recommended to use batches as large as possible as its
| speeds-up reading the dataset in TensorFlow.
|
| Input features do not need to be normalized (e.g. dividing numerical values
| by the variance) or indexed (e.g. replacing categorical string values by
| an integer). Additionally, missing values can be consumed natively.
|
| Distributed training
| ====================
|
| Some of the learning algorithms will support distributed training with the
| ParameterServerStrategy.
|
| In this case, the dataset is read asynchronously in between the workers. The
| distribution of the training depends on the learning algorithm.
|
| Like for non-distributed training, the dataset should be read exactly once.
| The simplest solution is to divide the dataset into different files (i.e.
| shards) and have each of the worker read a non overlapping subset of shards.
|
| IMPORTANT: The training dataset should not be infinite i.e. the training
| dataset should not contain any repeat operation.
|
| Currently (to be changed), the validation dataset (if provided) is simply
| feed to the `model.evaluate()` method. Therefore, it should satisfy Keras'
| evaluate API. Notably, for distributed training, the validation dataset
| should be infinite (i.e. have a repeat operation).
|
| See https://tensorflowcn.cn/decision_forests/distributed_training for
| more details and examples.
|
| Here is a single example of distributed training using PSS for both dataset
| reading and training distribution.
|
| ```python
| def dataset_fn(context, paths, training=True):
| ds_path = tf.data.Dataset.from_tensor_slices(paths)
|
|
| if context is not None:
| # Train on at least 2 workers.
| current_worker = tfdf.keras.get_worker_idx_and_num_workers(context)
| assert current_worker.num_workers > 2
|
| # Split the dataset's examples among the workers.
| ds_path = ds_path.shard(
| num_shards=current_worker.num_workers,
| index=current_worker.worker_idx)
|
| def read_csv_file(path):
| numerical = tf.constant([math.nan], dtype=tf.float32)
| categorical_string = tf.constant([""], dtype=tf.string)
| csv_columns = [
| numerical, # age
| categorical_string, # workclass
| numerical, # fnlwgt
| ...
| ]
| column_names = [
| "age", "workclass", "fnlwgt", ...
| ]
| label_name = "label"
| return tf.data.experimental.CsvDataset(path, csv_columns, header=True)
|
| ds_columns = ds_path.interleave(read_csv_file)
|
| def map_features(*columns):
| assert len(column_names) == len(columns)
| features = {column_names[i]: col for i, col in enumerate(columns)}
| label = label_table.lookup(features.pop(label_name))
| return features, label
|
| ds_dataset = ds_columns.map(map_features)
| if not training:
| dataset = dataset.repeat(None)
| ds_dataset = ds_dataset.batch(batch_size)
| return ds_dataset
|
| strategy = tf.distribute.experimental.ParameterServerStrategy(...)
| sharded_train_paths = [list of dataset files]
| with strategy.scope():
| model = DistributedGradientBoostedTreesModel()
| train_dataset = strategy.distribute_datasets_from_function(
| lambda context: dataset_fn(context, sharded_train_paths))
|
| test_dataset = strategy.distribute_datasets_from_function(
| lambda context: dataset_fn(context, sharded_test_paths))
|
| model.fit(sharded_train_paths)
| evaluation = model.evaluate(test_dataset, steps=num_test_examples //
| batch_size)
| ```
|
| Args:
| x: Training dataset (See details above for the supported formats).
| y: Label of the training dataset. Only used if "x" does not contains the
| labels.
| callbacks: Callbacks triggered during the training. The training runs in a
| single epoch, itself run in a single step. Therefore, callback logic can
| be called equivalently before/after the fit function.
| verbose: Verbosity mode. 0 = silent, 1 = small details, 2 = full details.
| validation_steps: Number of steps in the evaluation dataset when
| evaluating the trained model with `model.evaluate()`. If not specified,
| evaluates the model on the entire dataset (generally recommended; not
| yet supported for distributed datasets).
| validation_data: Validation dataset. If specified, the learner might use
| this dataset to help training e.g. early stopping.
| sample_weight: Training weights. Note: training weights can also be
| provided as the third output in a `tf.data.Dataset` e.g. (features,
| label, weights).
| steps_per_epoch: [Parameter will be removed] Number of training batch to
| load before training the model. Currently, only supported for
| distributed training.
| class_weight: For binary classification only. Mapping class indices
| (integers) to a weight (float) value. Only available for non-Distributed
| training. For maximum compatibility, feed example weights through the
| tf.data.Dataset or using the `weight` argument of
| `pd_dataframe_to_tf_dataset`.
| **kwargs: Extra arguments passed to the core keras model's fit. Note that
| not all keras' model fit arguments are supported.
|
| Returns:
| A `History` object. Its `History.history` attribute is not yet
| implemented for decision forests algorithms, and will return empty.
| All other fields are filled as usual for `Keras.Mode.fit()`.
|
| fit_on_dataset_path(self, train_path: str, label_key: Optional[str] = None, weight_key: Optional[str] = None, valid_path: Optional[str] = None, dataset_format: Optional[str] = 'csv', max_num_scanned_rows_to_accumulate_statistics: Optional[int] = 100000, try_resume_training: Optional[bool] = True, input_model_signature_fn: Optional[Callable[[tensorflow_decision_forests.component.inspector.inspector.AbstractInspector], Any]] = <function build_default_input_model_signature at 0x7f5424d1e1f0>, num_io_threads: int = 10)
| Trains the model on a dataset stored on disk.
|
| This solution is generally more efficient and easier than loading the
| dataset with a `tf.Dataset` both for local and distributed training.
|
| Usage example:
|
| # Local training
| ```python
| model = keras.GradientBoostedTreesModel()
| model.fit_on_dataset_path(
| train_path="/path/to/dataset.csv",
| label_key="label",
| dataset_format="csv")
| model.save("/model/path")
| ```
|
| # Distributed training
| ```python
| with tf.distribute.experimental.ParameterServerStrategy(...).scope():
| model = model = keras.DistributedGradientBoostedTreesModel()
| model.fit_on_dataset_path(
| train_path="/path/to/dataset@10",
| label_key="label",
| dataset_format="tfrecord+tfe")
| model.save("/model/path")
| ```
|
| Args:
| train_path: Path to the training dataset. Supports comma separated files,
| shard and glob notation.
| label_key: Name of the label column.
| weight_key: Name of the weighing column.
| valid_path: Path to the validation dataset. If not provided, or if the
| learning algorithm does not supports/needs a validation dataset,
| `valid_path` is ignored.
| dataset_format: Format of the dataset. Should be one of the registered
| dataset format (see [User
| Manual](https://github.com/google/yggdrasil-decision-forests/blob/main/documentation/rtd/cli_user_manual#dataset-path-and-format)
| for more details). The format "csv" is always available but it is
| generally only suited for small datasets.
| max_num_scanned_rows_to_accumulate_statistics: Maximum number of examples
| to scan to determine the statistics of the features (i.e. the dataspec,
| e.g. mean value, dictionaries). (Currently) the "first" examples of the
| dataset are scanned (e.g. the first examples of the dataset is a single
| file). Therefore, it is important that the sampled dataset is relatively
| uniformly sampled, notably the scanned examples should contains all the
| possible categorical values (otherwise the not seen value will be
| treated as out-of-vocabulary). If set to None, the entire dataset is
| scanned. This parameter has no effect if the dataset is stored in a
| format that already contains those values.
| try_resume_training: If true, tries to resume training from the model
| checkpoint stored in the `temp_directory` directory. If `temp_directory`
| does not contain any model checkpoint, start the training from the
| start. Works in the following three situations: (1) The training was
| interrupted by the user (e.g. ctrl+c). (2) the training job was
| interrupted (e.g. rescheduling), ond (3) the hyper-parameter of the
| model were changed such that an initially completed training is now
| incomplete (e.g. increasing the number of trees).
| input_model_signature_fn: A lambda that returns the
| (Dense,Sparse,Ragged)TensorSpec (or structure of TensorSpec e.g.
| dictionary, list) corresponding to input signature of the model. If not
| specified, the input model signature is created by
| `build_default_input_model_signature`. For example, specify
| `input_model_signature_fn` if an numerical input feature (which is
| consumed as DenseTensorSpec(float32) by default) will be feed
| differently (e.g. RaggedTensor(int64)).
| num_io_threads: Number of threads to use for IO operations e.g. reading a
| dataset from disk. Increasing this value can speed-up IO operations when
| IO operations are either latency or cpu bounded.
|
| Returns:
| A `History` object. Its `History.history` attribute is not yet
| implemented for decision forests algorithms, and will return empty.
| All other fields are filled as usual for `Keras.Mode.fit()`.
|
| load_weights(self, *args, **kwargs)
| No-op for TensorFlow Decision Forests models.
|
| `load_weights` is not supported by TensorFlow Decision Forests models.
| To save and restore a model, use the SavedModel API i.e.
| `model.save(...)` and `tf_keras.models.load_model(...)`. To resume the
| training of an existing model, create the model with
| `try_resume_training=True` (default value) and with a similar
| `temp_directory` argument. See documentation of `try_resume_training`
| for more details.
|
| Args:
| *args: Passed through to base `keras.Model` implemenation.
| **kwargs: Passed through to base `keras.Model` implemenation.
|
| save(self, filepath: str, overwrite: Optional[bool] = True, **kwargs)
| Saves the model as a TensorFlow SavedModel.
|
| The exported SavedModel contains a standalone Yggdrasil Decision Forests
| model in the "assets" sub-directory. The Yggdrasil model can be used
| directly using the Yggdrasil API. However, this model does not contain the
| "preprocessing" layer (if any).
|
| Args:
| filepath: Path to the output model.
| overwrite: If true, override an already existing model. If false, raise an
| error if a model already exist.
| **kwargs: Arguments passed to the core keras model's save.
|
| support_distributed_training(self)
|
| train_on_batch(self, *args, **kwargs)
| No supported for Tensorflow Decision Forests models.
|
| Decision forests are not trained in batches the same way neural networks
| are. To avoid confusion, train_on_batch is disabled.
|
| Args:
| *args: Ignored
| **kwargs: Ignored.
|
| train_step(self, data)
| Collects training examples.
|
| valid_step(self, data)
| Collects validation examples.
|
| ----------------------------------------------------------------------
| Readonly properties inherited from tensorflow_decision_forests.keras.core.CoreModel:
|
| exclude_non_specified_features
| If true, only use the features specified in "features".
|
| learner
| Name of the learning algorithm used to train the model.
|
| learner_params
| Gets the dictionary of hyper-parameters passed in the model constructor.
|
| Changing this dictionary will impact the training.
|
| num_threads
| Number of threads used to train the model.
|
| num_training_examples
| Number of training examples.
|
| num_validation_examples
| Number of validation examples.
|
| training_model_id
| Identifier of the model.
|
| ----------------------------------------------------------------------
| Methods inherited from tensorflow_decision_forests.keras.core_inference.InferenceCoreModel:
|
| call(self, inputs, training=False)
| Inference of the model.
|
| This method is used for prediction and evaluation of a trained model.
|
| Args:
| inputs: Input tensors.
| training: Is the model being trained. Always False.
|
| Returns:
| Model predictions.
|
| call_get_leaves(self, inputs)
| Computes the index of the active leaf in each tree.
|
| The active leaf is the leave that that receive the example during inference.
|
| The returned value "leaves[i,j]" is the index of the active leave for the
| i-th example and the j-th tree. Leaves are indexed by depth first
| exploration with the negative child visited before the positive one
| (similarly as "iterate_on_nodes()" iteration). Leaf indices are also
| available with LeafNode.leaf_idx.
|
| Args:
| inputs: Input tensors. Same signature as the model's "call(inputs)".
|
| Returns:
| Index of the active leaf for each tree in the model.
|
| compile(self, metrics=None, weighted_metrics=None, **kwargs)
| Configure the model for training.
|
| Unlike for most Keras model, calling "compile" is optional before calling
| "fit".
|
| Args:
| metrics: List of metrics to be evaluated by the model during training and
| testing.
| weighted_metrics: List of metrics to be evaluated and weighted by
| `sample_weight` or `class_weight` during training and testing.
| **kwargs: Other arguments passed to compile.
|
| Raises:
| ValueError: Invalid arguments.
|
| get_config(self)
| Not supported by TF-DF, returning empty directory to avoid warnings.
|
| make_inspector(self, index: int = 0) -> tensorflow_decision_forests.component.inspector.inspector.AbstractInspector
| Creates an inspector to access the internal model structure.
|
| Usage example:
|
| ```python
| inspector = model.make_inspector()
| print(inspector.num_trees())
| print(inspector.variable_importances())
| ```
|
| Args:
| index: Index of the sub-model. Only used for multitask models.
|
| Returns:
| A model inspector.
|
| make_predict_function(self)
| Prediction of the model (!= evaluation).
|
| make_test_function(self)
| Predictions for evaluation.
|
| predict_get_leaves(self, x)
| Gets the index of the active leaf of each tree.
|
| The active leaf is the leave that that receive the example during inference.
|
| The returned value "leaves[i,j]" is the index of the active leave for the
| i-th example and the j-th tree. Leaves are indexed by depth first
| exploration with the negative child visited before the positive one
| (similarly as "iterate_on_nodes()" iteration). Leaf indices are also
| available with LeafNode.leaf_idx.
|
| Args:
| x: Input samples as a tf.data.Dataset.
|
| Returns:
| Index of the active leaf for each tree in the model.
|
| ranking_group(self) -> Optional[str]
|
| summary(self, line_length=None, positions=None, print_fn=None)
| Shows information about the model.
|
| uplift_treatment(self) -> Optional[str]
|
| yggdrasil_model_path_tensor(self, multitask_model_index: int = 0) -> Optional[tensorflow.python.framework.tensor.Tensor]
| Gets the path to yggdrasil model, if available.
|
| The effective path can be obtained with:
|
| ```python
| yggdrasil_model_path_tensor().numpy().decode("utf-8")
| ```
|
| Args:
| multitask_model_index: Index of the sub-model. Only used for multitask
| models.
|
| Returns:
| Path to the Yggdrasil model.
|
| yggdrasil_model_prefix(self, index: int = 0) -> str
| Gets the prefix of the internal yggdrasil model.
|
| ----------------------------------------------------------------------
| Readonly properties inherited from tensorflow_decision_forests.keras.core_inference.InferenceCoreModel:
|
| multitask
| Tasks to solve.
|
| task
| Task to solve (e.g. CLASSIFICATION, REGRESSION, RANKING).
|
| ----------------------------------------------------------------------
| Methods inherited from tf_keras.src.engine.training.Model:
|
| __call__(self, *args, **kwargs)
|
| __copy__(self)
|
| __deepcopy__(self, memo)
|
| __reduce__(self)
| Helper for pickle.
|
| __setattr__(self, name, value)
| Support self.foo = trackable syntax.
|
| build(self, input_shape)
| Builds the model based on input shapes received.
|
| This is to be used for subclassed models, which do not know at
| instantiation time what their inputs look like.
|
| This method only exists for users who want to call `model.build()` in a
| standalone way (as a substitute for calling the model on real data to
| build it). It will never be called by the framework (and thus it will
| never throw unexpected errors in an unrelated workflow).
|
| Args:
| input_shape: Single tuple, `TensorShape` instance, or list/dict of
| shapes, where shapes are tuples, integers, or `TensorShape`
| instances.
|
| Raises:
| ValueError:
| 1. In case of invalid user-provided data (not of type tuple,
| list, `TensorShape`, or dict).
| 2. If the model requires call arguments that are agnostic
| to the input shapes (positional or keyword arg in call
| signature).
| 3. If not all layers were properly built.
| 4. If float type inputs are not supported within the layers.
|
| In each of these cases, the user should build their model by calling
| it on real tensor data.
|
| compile_from_config(self, config)
| Compiles the model with the information given in config.
|
| This method uses the information in the config (optimizer, loss,
| metrics, etc.) to compile the model.
|
| Args:
| config: Dict containing information for compiling the model.
|
| compute_loss(self, x=None, y=None, y_pred=None, sample_weight=None)
| Compute the total loss, validate it, and return it.
|
| Subclasses can optionally override this method to provide custom loss
| computation logic.
|
| Example:
| ```python
| class MyModel(tf.keras.Model):
|
| def __init__(self, *args, **kwargs):
| super(MyModel, self).__init__(*args, **kwargs)
| self.loss_tracker = tf.keras.metrics.Mean(name='loss')
|
| def compute_loss(self, x, y, y_pred, sample_weight):
| loss = tf.reduce_mean(tf.math.squared_difference(y_pred, y))
| loss += tf.add_n(self.losses)
| self.loss_tracker.update_state(loss)
| return loss
|
| def reset_metrics(self):
| self.loss_tracker.reset_states()
|
| @property
| def metrics(self):
| return [self.loss_tracker]
|
| tensors = tf.random.uniform((10, 10)), tf.random.uniform((10,))
| dataset = tf.data.Dataset.from_tensor_slices(tensors).repeat().batch(1)
|
| inputs = tf.keras.layers.Input(shape=(10,), name='my_input')
| outputs = tf.keras.layers.Dense(10)(inputs)
| model = MyModel(inputs, outputs)
| model.add_loss(tf.reduce_sum(outputs))
|
| optimizer = tf.keras.optimizers.SGD()
| model.compile(optimizer, loss='mse', steps_per_execution=10)
| model.fit(dataset, epochs=2, steps_per_epoch=10)
| print('My custom loss: ', model.loss_tracker.result().numpy())
| ```
|
| Args:
| x: Input data.
| y: Target data.
| y_pred: Predictions returned by the model (output of `model(x)`)
| sample_weight: Sample weights for weighting the loss function.
|
| Returns:
| The total loss as a `tf.Tensor`, or `None` if no loss results (which
| is the case when called by `Model.test_step`).
|
| compute_metrics(self, x, y, y_pred, sample_weight)
| Update metric states and collect all metrics to be returned.
|
| Subclasses can optionally override this method to provide custom metric
| updating and collection logic.
|
| Example:
| ```python
| class MyModel(tf.keras.Sequential):
|
| def compute_metrics(self, x, y, y_pred, sample_weight):
|
| # This super call updates `self.compiled_metrics` and returns
| # results for all metrics listed in `self.metrics`.
| metric_results = super(MyModel, self).compute_metrics(
| x, y, y_pred, sample_weight)
|
| # Note that `self.custom_metric` is not listed in `self.metrics`.
| self.custom_metric.update_state(x, y, y_pred, sample_weight)
| metric_results['custom_metric_name'] = self.custom_metric.result()
| return metric_results
| ```
|
| Args:
| x: Input data.
| y: Target data.
| y_pred: Predictions returned by the model (output of `model.call(x)`)
| sample_weight: Sample weights for weighting the loss function.
|
| Returns:
| A `dict` containing values that will be passed to
| `tf.keras.callbacks.CallbackList.on_train_batch_end()`. Typically, the
| values of the metrics listed in `self.metrics` are returned. Example:
| `{'loss': 0.2, 'accuracy': 0.7}`.
|
| evaluate(self, x=None, y=None, batch_size=None, verbose='auto', sample_weight=None, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, return_dict=False, **kwargs)
| Returns the loss value & metrics values for the model in test mode.
|
| Computation is done in batches (see the `batch_size` arg.)
|
| Args:
| x: Input data. It could be:
| - A Numpy array (or array-like), or a list of arrays
| (in case the model has multiple inputs).
| - A TensorFlow tensor, or a list of tensors
| (in case the model has multiple inputs).
| - A dict mapping input names to the corresponding array/tensors,
| if the model has named inputs.
| - A `tf.data` dataset. Should return a tuple
| of either `(inputs, targets)` or
| `(inputs, targets, sample_weights)`.
| - A generator or `keras.utils.Sequence` returning `(inputs,
| targets)` or `(inputs, targets, sample_weights)`.
| A more detailed description of unpacking behavior for iterator
| types (Dataset, generator, Sequence) is given in the `Unpacking
| behavior for iterator-like inputs` section of `Model.fit`.
| y: Target data. Like the input data `x`, it could be either Numpy
| array(s) or TensorFlow tensor(s). It should be consistent with `x`
| (you cannot have Numpy inputs and tensor targets, or inversely).
| If `x` is a dataset, generator or `keras.utils.Sequence` instance,
| `y` should not be specified (since targets will be obtained from
| the iterator/dataset).
| batch_size: Integer or `None`. Number of samples per batch of
| computation. If unspecified, `batch_size` will default to 32. Do
| not specify the `batch_size` if your data is in the form of a
| dataset, generators, or `keras.utils.Sequence` instances (since
| they generate batches).
| verbose: `"auto"`, 0, 1, or 2. Verbosity mode.
| 0 = silent, 1 = progress bar, 2 = single line.
| `"auto"` becomes 1 for most cases, and to 2 when used with
| `ParameterServerStrategy`. Note that the progress bar is not
| particularly useful when logged to a file, so `verbose=2` is
| recommended when not running interactively (e.g. in a production
| environment). Defaults to 'auto'.
| sample_weight: Optional Numpy array of weights for the test samples,
| used for weighting the loss function. You can either pass a flat
| (1D) Numpy array with the same length as the input samples
| (1:1 mapping between weights and samples), or in the case of
| temporal data, you can pass a 2D array with shape `(samples,
| sequence_length)`, to apply a different weight to every
| timestep of every sample. This argument is not supported when
| `x` is a dataset, instead pass sample weights as the third
| element of `x`.
| steps: Integer or `None`. Total number of steps (batches of samples)
| before declaring the evaluation round finished. Ignored with the
| default value of `None`. If x is a `tf.data` dataset and `steps`
| is None, 'evaluate' will run until the dataset is exhausted. This
| argument is not supported with array inputs.
| callbacks: List of `keras.callbacks.Callback` instances. List of
| callbacks to apply during evaluation. See
| [callbacks](https://tensorflowcn.cn/api_docs/python/tf/tf_keras/callbacks).
| max_queue_size: Integer. Used for generator or
| `keras.utils.Sequence` input only. Maximum size for the generator
| queue. If unspecified, `max_queue_size` will default to 10.
| workers: Integer. Used for generator or `keras.utils.Sequence` input
| only. Maximum number of processes to spin up when using
| process-based threading. If unspecified, `workers` will default to
| 1.
| use_multiprocessing: Boolean. Used for generator or
| `keras.utils.Sequence` input only. If `True`, use process-based
| threading. If unspecified, `use_multiprocessing` will default to
| `False`. Note that because this implementation relies on
| multiprocessing, you should not pass non-pickleable arguments to
| the generator as they can't be passed easily to children
| processes.
| return_dict: If `True`, loss and metric results are returned as a
| dict, with each key being the name of the metric. If `False`, they
| are returned as a list.
| **kwargs: Unused at this time.
|
| See the discussion of `Unpacking behavior for iterator-like inputs` for
| `Model.fit`.
|
| Returns:
| Scalar test loss (if the model has a single output and no metrics)
| or list of scalars (if the model has multiple outputs
| and/or metrics). The attribute `model.metrics_names` will give you
| the display labels for the scalar outputs.
|
| Raises:
| RuntimeError: If `model.evaluate` is wrapped in a `tf.function`.
|
| evaluate_generator(self, generator, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, verbose=0)
| Evaluates the model on a data generator.
|
| DEPRECATED:
| `Model.evaluate` now supports generators, so there is no longer any
| need to use this endpoint.
|
| export(self, filepath)
| Create a SavedModel artifact for inference (e.g. via TF-Serving).
|
| This method lets you export a model to a lightweight SavedModel artifact
| that contains the model's forward pass only (its `call()` method)
| and can be served via e.g. TF-Serving. The forward pass is registered
| under the name `serve()` (see example below).
|
| The original code of the model (including any custom layers you may
| have used) is *no longer* necessary to reload the artifact -- it is
| entirely standalone.
|
| Args:
| filepath: `str` or `pathlib.Path` object. Path where to save
| the artifact.
|
| Example:
|
| ```python
| # Create the artifact
| model.export("path/to/location")
|
| # Later, in a different process / environment...
| reloaded_artifact = tf.saved_model.load("path/to/location")
| predictions = reloaded_artifact.serve(input_data)
| ```
|
| If you would like to customize your serving endpoints, you can
| use the lower-level `keras.export.ExportArchive` class. The `export()`
| method relies on `ExportArchive` internally.
|
| fit_generator(self, generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, validation_freq=1, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)
| Fits the model on data yielded batch-by-batch by a Python generator.
|
| DEPRECATED:
| `Model.fit` now supports generators, so there is no longer any need to
| use this endpoint.
|
| get_compile_config(self)
| Returns a serialized config with information for compiling the model.
|
| This method returns a config dictionary containing all the information
| (optimizer, loss, metrics, etc.) with which the model was compiled.
|
| Returns:
| A dict containing information for compiling the model.
|
| get_layer(self, name=None, index=None)
| Retrieves a layer based on either its name (unique) or index.
|
| If `name` and `index` are both provided, `index` will take precedence.
| Indices are based on order of horizontal graph traversal (bottom-up).
|
| Args:
| name: String, name of layer.
| index: Integer, index of layer.
|
| Returns:
| A layer instance.
|
| get_metrics_result(self)
| Returns the model's metrics values as a dict.
|
| If any of the metric result is a dict (containing multiple metrics),
| each of them gets added to the top level returned dict of this method.
|
| Returns:
| A `dict` containing values of the metrics listed in `self.metrics`.
| Example:
| `{'loss': 0.2, 'accuracy': 0.7}`.
|
| get_weight_paths(self)
| Retrieve all the variables and their paths for the model.
|
| The variable path (string) is a stable key to identify a `tf.Variable`
| instance owned by the model. It can be used to specify variable-specific
| configurations (e.g. DTensor, quantization) from a global view.
|
| This method returns a dict with weight object paths as keys
| and the corresponding `tf.Variable` instances as values.
|
| Note that if the model is a subclassed model and the weights haven't
| been initialized, an empty dict will be returned.
|
| Returns:
| A dict where keys are variable paths and values are `tf.Variable`
| instances.
|
| Example:
|
| ```python
| class SubclassModel(tf.keras.Model):
|
| def __init__(self, name=None):
| super().__init__(name=name)
| self.d1 = tf.keras.layers.Dense(10)
| self.d2 = tf.keras.layers.Dense(20)
|
| def call(self, inputs):
| x = self.d1(inputs)
| return self.d2(x)
|
| model = SubclassModel()
| model(tf.zeros((10, 10)))
| weight_paths = model.get_weight_paths()
| # weight_paths:
| # {
| # 'd1.kernel': model.d1.kernel,
| # 'd1.bias': model.d1.bias,
| # 'd2.kernel': model.d2.kernel,
| # 'd2.bias': model.d2.bias,
| # }
|
| # Functional model
| inputs = tf.keras.Input((10,), batch_size=10)
| x = tf.keras.layers.Dense(20, name='d1')(inputs)
| output = tf.keras.layers.Dense(30, name='d2')(x)
| model = tf.keras.Model(inputs, output)
| d1 = model.layers[1]
| d2 = model.layers[2]
| weight_paths = model.get_weight_paths()
| # weight_paths:
| # {
| # 'd1.kernel': d1.kernel,
| # 'd1.bias': d1.bias,
| # 'd2.kernel': d2.kernel,
| # 'd2.bias': d2.bias,
| # }
| ```
|
| get_weights(self)
| Retrieves the weights of the model.
|
| Returns:
| A flat list of Numpy arrays.
|
| make_train_function(self, force=False)
| Creates a function that executes one step of training.
|
| This method can be overridden to support custom training logic.
| This method is called by `Model.fit` and `Model.train_on_batch`.
|
| Typically, this method directly controls `tf.function` and
| `tf.distribute.Strategy` settings, and delegates the actual training
| logic to `Model.train_step`.
|
| This function is cached the first time `Model.fit` or
| `Model.train_on_batch` is called. The cache is cleared whenever
| `Model.compile` is called. You can skip the cache and generate again the
| function with `force=True`.
|
| Args:
| force: Whether to regenerate the train function and skip the cached
| function if available.
|
| Returns:
| Function. The function created by this method should accept a
| `tf.data.Iterator`, and return a `dict` containing values that will
| be passed to `tf.keras.Callbacks.on_train_batch_end`, such as
| `{'loss': 0.2, 'accuracy': 0.7}`.
|
| predict(self, x, batch_size=None, verbose='auto', steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
| Generates output predictions for the input samples.
|
| Computation is done in batches. This method is designed for batch
| processing of large numbers of inputs. It is not intended for use inside
| of loops that iterate over your data and process small numbers of inputs
| at a time.
|
| For small numbers of inputs that fit in one batch,
| directly use `__call__()` for faster execution, e.g.,
| `model(x)`, or `model(x, training=False)` if you have layers such as
| `tf.keras.layers.BatchNormalization` that behave differently during
| inference. You may pair the individual model call with a `tf.function`
| for additional performance inside your inner loop.
| If you need access to numpy array values instead of tensors after your
| model call, you can use `tensor.numpy()` to get the numpy array value of
| an eager tensor.
|
| Also, note the fact that test loss is not affected by
| regularization layers like noise and dropout.
|
| Note: See [this FAQ entry](
| https://keras.org.cn/getting_started/faq/#whats-the-difference-between-model-methods-predict-and-call)
| for more details about the difference between `Model` methods
| `predict()` and `__call__()`.
|
| Args:
| x: Input samples. It could be:
| - A Numpy array (or array-like), or a list of arrays
| (in case the model has multiple inputs).
| - A TensorFlow tensor, or a list of tensors
| (in case the model has multiple inputs).
| - A `tf.data` dataset.
| - A generator or `keras.utils.Sequence` instance.
| A more detailed description of unpacking behavior for iterator
| types (Dataset, generator, Sequence) is given in the `Unpacking
| behavior for iterator-like inputs` section of `Model.fit`.
| batch_size: Integer or `None`.
| Number of samples per batch.
| If unspecified, `batch_size` will default to 32.
| Do not specify the `batch_size` if your data is in the
| form of dataset, generators, or `keras.utils.Sequence` instances
| (since they generate batches).
| verbose: `"auto"`, 0, 1, or 2. Verbosity mode.
| 0 = silent, 1 = progress bar, 2 = single line.
| `"auto"` becomes 1 for most cases, and to 2 when used with
| `ParameterServerStrategy`. Note that the progress bar is not
| particularly useful when logged to a file, so `verbose=2` is
| recommended when not running interactively (e.g. in a production
| environment). Defaults to 'auto'.
| steps: Total number of steps (batches of samples)
| before declaring the prediction round finished.
| Ignored with the default value of `None`. If x is a `tf.data`
| dataset and `steps` is None, `predict()` will
| run until the input dataset is exhausted.
| callbacks: List of `keras.callbacks.Callback` instances.
| List of callbacks to apply during prediction.
| See [callbacks](
| https://tensorflowcn.cn/api_docs/python/tf/tf_keras/callbacks).
| max_queue_size: Integer. Used for generator or
| `keras.utils.Sequence` input only. Maximum size for the
| generator queue. If unspecified, `max_queue_size` will default
| to 10.
| workers: Integer. Used for generator or `keras.utils.Sequence` input
| only. Maximum number of processes to spin up when using
| process-based threading. If unspecified, `workers` will default
| to 1.
| use_multiprocessing: Boolean. Used for generator or
| `keras.utils.Sequence` input only. If `True`, use process-based
| threading. If unspecified, `use_multiprocessing` will default to
| `False`. Note that because this implementation relies on
| multiprocessing, you should not pass non-pickleable arguments to
| the generator as they can't be passed easily to children
| processes.
|
| See the discussion of `Unpacking behavior for iterator-like inputs` for
| `Model.fit`. Note that Model.predict uses the same interpretation rules
| as `Model.fit` and `Model.evaluate`, so inputs must be unambiguous for
| all three methods.
|
| Returns:
| Numpy array(s) of predictions.
|
| Raises:
| RuntimeError: If `model.predict` is wrapped in a `tf.function`.
| ValueError: In case of mismatch between the provided
| input data and the model's expectations,
| or in case a stateful model receives a number of samples
| that is not a multiple of the batch size.
|
| predict_generator(self, generator, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, verbose=0)
| Generates predictions for the input samples from a data generator.
|
| DEPRECATED:
| `Model.predict` now supports generators, so there is no longer any
| need to use this endpoint.
|
| predict_on_batch(self, x)
| Returns predictions for a single batch of samples.
|
| Args:
| x: Input data. It could be:
| - A Numpy array (or array-like), or a list of arrays (in case the
| model has multiple inputs).
| - A TensorFlow tensor, or a list of tensors (in case the model has
| multiple inputs).
|
| Returns:
| Numpy array(s) of predictions.
|
| Raises:
| RuntimeError: If `model.predict_on_batch` is wrapped in a
| `tf.function`.
|
| predict_step(self, data)
| The logic for one inference step.
|
| This method can be overridden to support custom inference logic.
| This method is called by `Model.make_predict_function`.
|
| This method should contain the mathematical logic for one step of
| inference. This typically includes the forward pass.
|
| Configuration details for *how* this logic is run (e.g. `tf.function`
| and `tf.distribute.Strategy` settings), should be left to
| `Model.make_predict_function`, which can also be overridden.
|
| Args:
| data: A nested structure of `Tensor`s.
|
| Returns:
| The result of one inference step, typically the output of calling the
| `Model` on data.
|
| reset_metrics(self)
| Resets the state of all the metrics in the model.
|
| Examples:
|
| >>> inputs = tf.keras.layers.Input(shape=(3,))
| >>> outputs = tf.keras.layers.Dense(2)(inputs)
| >>> model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
| >>> model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
|
| >>> x = np.random.random((2, 3))
| >>> y = np.random.randint(0, 2, (2, 2))
| >>> _ = model.fit(x, y, verbose=0)
| >>> assert all(float(m.result()) for m in model.metrics)
|
| >>> model.reset_metrics()
| >>> assert all(float(m.result()) == 0 for m in model.metrics)
|
| reset_states(self)
|
| save_spec(self, dynamic_batch=True)
| Returns the `tf.TensorSpec` of call args as a tuple `(args, kwargs)`.
|
| This value is automatically defined after calling the model for the
| first time. Afterwards, you can use it when exporting the model for
| serving:
|
| ```python
| model = tf.keras.Model(...)
|
| @tf.function
| def serve(*args, **kwargs):
| outputs = model(*args, **kwargs)
| # Apply postprocessing steps, or add additional outputs.
| ...
| return outputs
|
| # arg_specs is `[tf.TensorSpec(...), ...]`. kwarg_specs, in this
| # example, is an empty dict since functional models do not use keyword
| # arguments.
| arg_specs, kwarg_specs = model.save_spec()
|
| model.save(path, signatures={
| 'serving_default': serve.get_concrete_function(*arg_specs,
| **kwarg_specs)
| })
| ```
|
| Args:
| dynamic_batch: Whether to set the batch sizes of all the returned
| `tf.TensorSpec` to `None`. (Note that when defining functional or
| Sequential models with `tf.keras.Input([...], batch_size=X)`, the
| batch size will always be preserved). Defaults to `True`.
| Returns:
| If the model inputs are defined, returns a tuple `(args, kwargs)`. All
| elements in `args` and `kwargs` are `tf.TensorSpec`.
| If the model inputs are not defined, returns `None`.
| The model inputs are automatically set when calling the model,
| `model.fit`, `model.evaluate` or `model.predict`.
|
| save_weights(self, filepath, overwrite=True, save_format=None, options=None)
| Saves all layer weights.
|
| Either saves in HDF5 or in TensorFlow format based on the `save_format`
| argument.
|
| When saving in HDF5 format, the weight file has:
| - `layer_names` (attribute), a list of strings
| (ordered names of model layers).
| - For every layer, a `group` named `layer.name`
| - For every such layer group, a group attribute `weight_names`,
| a list of strings
| (ordered names of weights tensor of the layer).
| - For every weight in the layer, a dataset
| storing the weight value, named after the weight tensor.
|
| When saving in TensorFlow format, all objects referenced by the network
| are saved in the same format as `tf.train.Checkpoint`, including any
| `Layer` instances or `Optimizer` instances assigned to object
| attributes. For networks constructed from inputs and outputs using
| `tf.keras.Model(inputs, outputs)`, `Layer` instances used by the network
| are tracked/saved automatically. For user-defined classes which inherit
| from `tf.keras.Model`, `Layer` instances must be assigned to object
| attributes, typically in the constructor. See the documentation of
| `tf.train.Checkpoint` and `tf.keras.Model` for details.
|
| While the formats are the same, do not mix `save_weights` and
| `tf.train.Checkpoint`. Checkpoints saved by `Model.save_weights` should
| be loaded using `Model.load_weights`. Checkpoints saved using
| `tf.train.Checkpoint.save` should be restored using the corresponding
| `tf.train.Checkpoint.restore`. Prefer `tf.train.Checkpoint` over
| `save_weights` for training checkpoints.
|
| The TensorFlow format matches objects and variables by starting at a
| root object, `self` for `save_weights`, and greedily matching attribute
| names. For `Model.save` this is the `Model`, and for `Checkpoint.save`
| this is the `Checkpoint` even if the `Checkpoint` has a model attached.
| This means saving a `tf.keras.Model` using `save_weights` and loading
| into a `tf.train.Checkpoint` with a `Model` attached (or vice versa)
| will not match the `Model`'s variables. See the
| [guide to training checkpoints](
| https://tensorflowcn.cn/guide/checkpoint) for details on
| the TensorFlow format.
|
| Args:
| filepath: String or PathLike, path to the file to save the weights
| to. When saving in TensorFlow format, this is the prefix used
| for checkpoint files (multiple files are generated). Note that
| the '.h5' suffix causes weights to be saved in HDF5 format.
| overwrite: Whether to silently overwrite any existing file at the
| target location, or provide the user with a manual prompt.
| save_format: Either 'tf' or 'h5'. A `filepath` ending in '.h5' or
| '.keras' will default to HDF5 if `save_format` is `None`.
| Otherwise, `None` becomes 'tf'. Defaults to `None`.
| options: Optional `tf.train.CheckpointOptions` object that specifies
| options for saving weights.
|
| Raises:
| ImportError: If `h5py` is not available when attempting to save in
| HDF5 format.
|
| test_on_batch(self, x, y=None, sample_weight=None, reset_metrics=True, return_dict=False)
| Test the model on a single batch of samples.
|
| Args:
| x: Input data. It could be:
| - A Numpy array (or array-like), or a list of arrays (in case the
| model has multiple inputs).
| - A TensorFlow tensor, or a list of tensors (in case the model has
| multiple inputs).
| - A dict mapping input names to the corresponding array/tensors,
| if the model has named inputs.
| y: Target data. Like the input data `x`, it could be either Numpy
| array(s) or TensorFlow tensor(s). It should be consistent with `x`
| (you cannot have Numpy inputs and tensor targets, or inversely).
| sample_weight: Optional array of the same length as x, containing
| weights to apply to the model's loss for each sample. In the case
| of temporal data, you can pass a 2D array with shape (samples,
| sequence_length), to apply a different weight to every timestep of
| every sample.
| reset_metrics: If `True`, the metrics returned will be only for this
| batch. If `False`, the metrics will be statefully accumulated
| across batches.
| return_dict: If `True`, loss and metric results are returned as a
| dict, with each key being the name of the metric. If `False`, they
| are returned as a list.
|
| Returns:
| Scalar test loss (if the model has a single output and no metrics)
| or list of scalars (if the model has multiple outputs
| and/or metrics). The attribute `model.metrics_names` will give you
| the display labels for the scalar outputs.
|
| Raises:
| RuntimeError: If `model.test_on_batch` is wrapped in a
| `tf.function`.
|
| test_step(self, data)
| The logic for one evaluation step.
|
| This method can be overridden to support custom evaluation logic.
| This method is called by `Model.make_test_function`.
|
| This function should contain the mathematical logic for one step of
| evaluation.
| This typically includes the forward pass, loss calculation, and metrics
| updates.
|
| Configuration details for *how* this logic is run (e.g. `tf.function`
| and `tf.distribute.Strategy` settings), should be left to
| `Model.make_test_function`, which can also be overridden.
|
| Args:
| data: A nested structure of `Tensor`s.
|
| Returns:
| A `dict` containing values that will be passed to
| `tf.keras.callbacks.CallbackList.on_train_batch_end`. Typically, the
| values of the `Model`'s metrics are returned.
|
| to_json(self, **kwargs)
| Returns a JSON string containing the network configuration.
|
| To load a network from a JSON save file, use
| `keras.models.model_from_json(json_string, custom_objects={})`.
|
| Args:
| **kwargs: Additional keyword arguments to be passed to
| *`json.dumps()`.
|
| Returns:
| A JSON string.
|
| to_yaml(self, **kwargs)
| Returns a yaml string containing the network configuration.
|
| Note: Since TF 2.6, this method is no longer supported and will raise a
| RuntimeError.
|
| To load a network from a yaml save file, use
| `keras.models.model_from_yaml(yaml_string, custom_objects={})`.
|
| `custom_objects` should be a dictionary mapping
| the names of custom losses / layers / etc to the corresponding
| functions / classes.
|
| Args:
| **kwargs: Additional keyword arguments
| to be passed to `yaml.dump()`.
|
| Returns:
| A YAML string.
|
| Raises:
| RuntimeError: announces that the method poses a security risk
|
| ----------------------------------------------------------------------
| Class methods inherited from tf_keras.src.engine.training.Model:
|
| from_config(config, custom_objects=None) from builtins.type
| Creates a layer from its config.
|
| This method is the reverse of `get_config`,
| capable of instantiating the same layer from the config
| dictionary. It does not handle layer connectivity
| (handled by Network), nor weights (handled by `set_weights`).
|
| Args:
| config: A Python dictionary, typically the
| output of get_config.
|
| Returns:
| A layer instance.
|
| ----------------------------------------------------------------------
| Static methods inherited from tf_keras.src.engine.training.Model:
|
| __new__(cls, *args, **kwargs)
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Readonly properties inherited from tf_keras.src.engine.training.Model:
|
| distribute_strategy
| The `tf.distribute.Strategy` this model was created under.
|
| metrics
| Return metrics added using `compile()` or `add_metric()`.
|
| Note: Metrics passed to `compile()` are available only after a
| `keras.Model` has been trained/evaluated on actual data.
|
| Examples:
|
| >>> inputs = tf.keras.layers.Input(shape=(3,))
| >>> outputs = tf.keras.layers.Dense(2)(inputs)
| >>> model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
| >>> model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
| >>> [m.name for m in model.metrics]
| []
|
| >>> x = np.random.random((2, 3))
| >>> y = np.random.randint(0, 2, (2, 2))
| >>> model.fit(x, y)
| >>> [m.name for m in model.metrics]
| ['loss', 'mae']
|
| >>> inputs = tf.keras.layers.Input(shape=(3,))
| >>> d = tf.keras.layers.Dense(2, name='out')
| >>> output_1 = d(inputs)
| >>> output_2 = d(inputs)
| >>> model = tf.keras.models.Model(
| ... inputs=inputs, outputs=[output_1, output_2])
| >>> model.add_metric(
| ... tf.reduce_sum(output_2), name='mean', aggregation='mean')
| >>> model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
| >>> model.fit(x, (y, y))
| >>> [m.name for m in model.metrics]
| ['loss', 'out_loss', 'out_1_loss', 'out_mae', 'out_acc', 'out_1_mae',
| 'out_1_acc', 'mean']
|
| metrics_names
| Returns the model's display labels for all outputs.
|
| Note: `metrics_names` are available only after a `keras.Model` has been
| trained/evaluated on actual data.
|
| Examples:
|
| >>> inputs = tf.keras.layers.Input(shape=(3,))
| >>> outputs = tf.keras.layers.Dense(2)(inputs)
| >>> model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
| >>> model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
| >>> model.metrics_names
| []
|
| >>> x = np.random.random((2, 3))
| >>> y = np.random.randint(0, 2, (2, 2))
| >>> model.fit(x, y)
| >>> model.metrics_names
| ['loss', 'mae']
|
| >>> inputs = tf.keras.layers.Input(shape=(3,))
| >>> d = tf.keras.layers.Dense(2, name='out')
| >>> output_1 = d(inputs)
| >>> output_2 = d(inputs)
| >>> model = tf.keras.models.Model(
| ... inputs=inputs, outputs=[output_1, output_2])
| >>> model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
| >>> model.fit(x, (y, y))
| >>> model.metrics_names
| ['loss', 'out_loss', 'out_1_loss', 'out_mae', 'out_acc', 'out_1_mae',
| 'out_1_acc']
|
| non_trainable_weights
| List of all non-trainable weights tracked by this layer.
|
| Non-trainable weights are *not* updated during training. They are
| expected to be updated manually in `call()`.
|
| Returns:
| A list of non-trainable variables.
|
| state_updates
| Deprecated, do NOT use!
|
| Returns the `updates` from all layers that are stateful.
|
| This is useful for separating training updates and
| state updates, e.g. when we need to update a layer's internal state
| during prediction.
|
| Returns:
| A list of update ops.
|
| trainable_weights
| List of all trainable weights tracked by this layer.
|
| Trainable weights are updated via gradient descent during training.
|
| Returns:
| A list of trainable variables.
|
| weights
| Returns the list of all layer variables/weights.
|
| Note: This will not track the weights of nested `tf.Modules` that are
| not themselves TF-Keras layers.
|
| Returns:
| A list of variables.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from tf_keras.src.engine.training.Model:
|
| autotune_steps_per_execution
| Settable property to enable tuning for steps_per_execution
|
| distribute_reduction_method
| The method employed to reduce per-replica values during training.
|
| Unless specified, the value "auto" will be assumed, indicating that
| the reduction strategy should be chosen based on the current
| running environment.
| See `reduce_per_replica` function for more details.
|
| jit_compile
| Specify whether to compile the model with XLA.
|
| [XLA](https://tensorflowcn.cn/xla) is an optimizing compiler
| for machine learning. `jit_compile` is not enabled by default.
| Note that `jit_compile=True` may not necessarily work for all models.
|
| For more information on supported operations please refer to the
| [XLA documentation](https://tensorflowcn.cn/xla). Also refer to
| [known XLA issues](https://tensorflowcn.cn/xla/known_issues)
| for more details.
|
| layers
|
| run_eagerly
| Settable attribute indicating whether the model should run eagerly.
|
| Running eagerly means that your model will be run step by step,
| like Python code. Your model might run slower, but it should become
| easier for you to debug it by stepping into individual layer calls.
|
| By default, we will attempt to compile your model to a static graph to
| deliver the best execution performance.
|
| Returns:
| Boolean, whether the model should run eagerly.
|
| steps_per_execution
| Settable `steps_per_execution variable. Requires a compiled model.
|
| ----------------------------------------------------------------------
| Methods inherited from tf_keras.src.engine.base_layer.Layer:
|
| __delattr__(self, name)
| Implement delattr(self, name).
|
| __getstate__(self)
|
| __setstate__(self, state)
|
| add_loss(self, losses, **kwargs)
| Add loss tensor(s), potentially dependent on layer inputs.
|
| Some losses (for instance, activity regularization losses) may be
| dependent on the inputs passed when calling a layer. Hence, when reusing
| the same layer on different inputs `a` and `b`, some entries in
| `layer.losses` may be dependent on `a` and some on `b`. This method
| automatically keeps track of dependencies.
|
| This method can be used inside a subclassed layer or model's `call`
| function, in which case `losses` should be a Tensor or list of Tensors.
|
| Example:
|
| ```python
| class MyLayer(tf.keras.layers.Layer):
| def call(self, inputs):
| self.add_loss(tf.abs(tf.reduce_mean(inputs)))
| return inputs
| ```
|
| The same code works in distributed training: the input to `add_loss()`
| is treated like a regularization loss and averaged across replicas
| by the training loop (both built-in `Model.fit()` and compliant custom
| training loops).
|
| The `add_loss` method can also be called directly on a Functional Model
| during construction. In this case, any loss Tensors passed to this Model
| must be symbolic and be able to be traced back to the model's `Input`s.
| These losses become part of the model's topology and are tracked in
| `get_config`.
|
| Example:
|
| ```python
| inputs = tf.keras.Input(shape=(10,))
| x = tf.keras.layers.Dense(10)(inputs)
| outputs = tf.keras.layers.Dense(1)(x)
| model = tf.keras.Model(inputs, outputs)
| # Activity regularization.
| model.add_loss(tf.abs(tf.reduce_mean(x)))
| ```
|
| If this is not the case for your loss (if, for example, your loss
| references a `Variable` of one of the model's layers), you can wrap your
| loss in a zero-argument lambda. These losses are not tracked as part of
| the model's topology since they can't be serialized.
|
| Example:
|
| ```python
| inputs = tf.keras.Input(shape=(10,))
| d = tf.keras.layers.Dense(10)
| x = d(inputs)
| outputs = tf.keras.layers.Dense(1)(x)
| model = tf.keras.Model(inputs, outputs)
| # Weight regularization.
| model.add_loss(lambda: tf.reduce_mean(d.kernel))
| ```
|
| Args:
| losses: Loss tensor, or list/tuple of tensors. Rather than tensors,
| losses may also be zero-argument callables which create a loss
| tensor.
| **kwargs: Used for backwards compatibility only.
|
| add_metric(self, value, name=None, **kwargs)
| Adds metric tensor to the layer.
|
| This method can be used inside the `call()` method of a subclassed layer
| or model.
|
| ```python
| class MyMetricLayer(tf.keras.layers.Layer):
| def __init__(self):
| super(MyMetricLayer, self).__init__(name='my_metric_layer')
| self.mean = tf.keras.metrics.Mean(name='metric_1')
|
| def call(self, inputs):
| self.add_metric(self.mean(inputs))
| self.add_metric(tf.reduce_sum(inputs), name='metric_2')
| return inputs
| ```
|
| This method can also be called directly on a Functional Model during
| construction. In this case, any tensor passed to this Model must
| be symbolic and be able to be traced back to the model's `Input`s. These
| metrics become part of the model's topology and are tracked when you
| save the model via `save()`.
|
| ```python
| inputs = tf.keras.Input(shape=(10,))
| x = tf.keras.layers.Dense(10)(inputs)
| outputs = tf.keras.layers.Dense(1)(x)
| model = tf.keras.Model(inputs, outputs)
| model.add_metric(math_ops.reduce_sum(x), name='metric_1')
| ```
|
| Note: Calling `add_metric()` with the result of a metric object on a
| Functional Model, as shown in the example below, is not supported. This
| is because we cannot trace the metric result tensor back to the model's
| inputs.
|
| ```python
| inputs = tf.keras.Input(shape=(10,))
| x = tf.keras.layers.Dense(10)(inputs)
| outputs = tf.keras.layers.Dense(1)(x)
| model = tf.keras.Model(inputs, outputs)
| model.add_metric(tf.keras.metrics.Mean()(x), name='metric_1')
| ```
|
| Args:
| value: Metric tensor.
| name: String metric name.
| **kwargs: Additional keyword arguments for backward compatibility.
| Accepted values:
| `aggregation` - When the `value` tensor provided is not the result
| of calling a `keras.Metric` instance, it will be aggregated by
| default using a `keras.Metric.Mean`.
|
| add_update(self, updates)
| Add update op(s), potentially dependent on layer inputs.
|
| Weight updates (for instance, the updates of the moving mean and
| variance in a BatchNormalization layer) may be dependent on the inputs
| passed when calling a layer. Hence, when reusing the same layer on
| different inputs `a` and `b`, some entries in `layer.updates` may be
| dependent on `a` and some on `b`. This method automatically keeps track
| of dependencies.
|
| This call is ignored when eager execution is enabled (in that case,
| variable updates are run on the fly and thus do not need to be tracked
| for later execution).
|
| Args:
| updates: Update op, or list/tuple of update ops, or zero-arg callable
| that returns an update op. A zero-arg callable should be passed in
| order to disable running the updates by setting `trainable=False`
| on this Layer, when executing in Eager mode.
|
| add_variable(self, *args, **kwargs)
| Deprecated, do NOT use! Alias for `add_weight`.
|
| add_weight(self, name=None, shape=None, dtype=None, initializer=None, regularizer=None, trainable=None, constraint=None, use_resource=None, synchronization=<VariableSynchronization.AUTO: 0>, aggregation=<VariableAggregationV2.NONE: 0>, **kwargs)
| Adds a new variable to the layer.
|
| Args:
| name: Variable name.
| shape: Variable shape. Defaults to scalar if unspecified.
| dtype: The type of the variable. Defaults to `self.dtype`.
| initializer: Initializer instance (callable).
| regularizer: Regularizer instance (callable).
| trainable: Boolean, whether the variable should be part of the layer's
| "trainable_variables" (e.g. variables, biases)
| or "non_trainable_variables" (e.g. BatchNorm mean and variance).
| Note that `trainable` cannot be `True` if `synchronization`
| is set to `ON_READ`.
| constraint: Constraint instance (callable).
| use_resource: Whether to use a `ResourceVariable` or not.
| See [this guide](
| https://tensorflowcn.cn/guide/migrate/tf1_vs_tf2#resourcevariables_instead_of_referencevariables)
| for more information.
| synchronization: Indicates when a distributed a variable will be
| aggregated. Accepted values are constants defined in the class
| `tf.VariableSynchronization`. By default the synchronization is set
| to `AUTO` and the current `DistributionStrategy` chooses when to
| synchronize. If `synchronization` is set to `ON_READ`, `trainable`
| must not be set to `True`.
| aggregation: Indicates how a distributed variable will be aggregated.
| Accepted values are constants defined in the class
| `tf.VariableAggregation`.
| **kwargs: Additional keyword arguments. Accepted values are `getter`,
| `collections`, `experimental_autocast` and `caching_device`.
|
| Returns:
| The variable created.
|
| Raises:
| ValueError: When giving unsupported dtype and no initializer or when
| trainable has been set to True with synchronization set as
| `ON_READ`.
|
| build_from_config(self, config)
| Builds the layer's states with the supplied config dict.
|
| By default, this method calls the `build(config["input_shape"])` method,
| which creates weights based on the layer's input shape in the supplied
| config. If your config contains other information needed to load the
| layer's state, you should override this method.
|
| Args:
| config: Dict containing the input shape associated with this layer.
|
| compute_mask(self, inputs, mask=None)
| Computes an output mask tensor.
|
| Args:
| inputs: Tensor or list of tensors.
| mask: Tensor or list of tensors.
|
| Returns:
| None or a tensor (or list of tensors,
| one per output tensor of the layer).
|
| compute_output_shape(self, input_shape)
| Computes the output shape of the layer.
|
| This method will cause the layer's state to be built, if that has not
| happened before. This requires that the layer will later be used with
| inputs that match the input shape provided here.
|
| Args:
| input_shape: Shape tuple (tuple of integers) or `tf.TensorShape`,
| or structure of shape tuples / `tf.TensorShape` instances
| (one per output tensor of the layer).
| Shape tuples can include None for free dimensions,
| instead of an integer.
|
| Returns:
| A `tf.TensorShape` instance
| or structure of `tf.TensorShape` instances.
|
| compute_output_signature(self, input_signature)
| Compute the output tensor signature of the layer based on the inputs.
|
| Unlike a TensorShape object, a TensorSpec object contains both shape
| and dtype information for a tensor. This method allows layers to provide
| output dtype information if it is different from the input dtype.
| For any layer that doesn't implement this function,
| the framework will fall back to use `compute_output_shape`, and will
| assume that the output dtype matches the input dtype.
|
| Args:
| input_signature: Single TensorSpec or nested structure of TensorSpec
| objects, describing a candidate input for the layer.
|
| Returns:
| Single TensorSpec or nested structure of TensorSpec objects,
| describing how the layer would transform the provided input.
|
| Raises:
| TypeError: If input_signature contains a non-TensorSpec object.
|
| count_params(self)
| Count the total number of scalars composing the weights.
|
| Returns:
| An integer count.
|
| Raises:
| ValueError: if the layer isn't yet built
| (in which case its weights aren't yet defined).
|
| finalize_state(self)
| Finalizes the layers state after updating layer weights.
|
| This function can be subclassed in a layer and will be called after
| updating a layer weights. It can be overridden to finalize any
| additional layer state after a weight update.
|
| This function will be called after weights of a layer have been restored
| from a loaded model.
|
| get_build_config(self)
| Returns a dictionary with the layer's input shape.
|
| This method returns a config dict that can be used by
| `build_from_config(config)` to create all states (e.g. Variables and
| Lookup tables) needed by the layer.
|
| By default, the config only contains the input shape that the layer
| was built with. If you're writing a custom layer that creates state in
| an unusual way, you should override this method to make sure this state
| is already created when TF-Keras attempts to load its value upon model
| loading.
|
| Returns:
| A dict containing the input shape associated with the layer.
|
| get_input_at(self, node_index)
| Retrieves the input tensor(s) of a layer at a given node.
|
| Args:
| node_index: Integer, index of the node
| from which to retrieve the attribute.
| E.g. `node_index=0` will correspond to the
| first input node of the layer.
|
| Returns:
| A tensor (or list of tensors if the layer has multiple inputs).
|
| Raises:
| RuntimeError: If called in Eager mode.
|
| get_input_mask_at(self, node_index)
| Retrieves the input mask tensor(s) of a layer at a given node.
|
| Args:
| node_index: Integer, index of the node
| from which to retrieve the attribute.
| E.g. `node_index=0` will correspond to the
| first time the layer was called.
|
| Returns:
| A mask tensor
| (or list of tensors if the layer has multiple inputs).
|
| get_input_shape_at(self, node_index)
| Retrieves the input shape(s) of a layer at a given node.
|
| Args:
| node_index: Integer, index of the node
| from which to retrieve the attribute.
| E.g. `node_index=0` will correspond to the
| first time the layer was called.
|
| Returns:
| A shape tuple
| (or list of shape tuples if the layer has multiple inputs).
|
| Raises:
| RuntimeError: If called in Eager mode.
|
| get_output_at(self, node_index)
| Retrieves the output tensor(s) of a layer at a given node.
|
| Args:
| node_index: Integer, index of the node
| from which to retrieve the attribute.
| E.g. `node_index=0` will correspond to the
| first output node of the layer.
|
| Returns:
| A tensor (or list of tensors if the layer has multiple outputs).
|
| Raises:
| RuntimeError: If called in Eager mode.
|
| get_output_mask_at(self, node_index)
| Retrieves the output mask tensor(s) of a layer at a given node.
|
| Args:
| node_index: Integer, index of the node
| from which to retrieve the attribute.
| E.g. `node_index=0` will correspond to the
| first time the layer was called.
|
| Returns:
| A mask tensor
| (or list of tensors if the layer has multiple outputs).
|
| get_output_shape_at(self, node_index)
| Retrieves the output shape(s) of a layer at a given node.
|
| Args:
| node_index: Integer, index of the node
| from which to retrieve the attribute.
| E.g. `node_index=0` will correspond to the
| first time the layer was called.
|
| Returns:
| A shape tuple
| (or list of shape tuples if the layer has multiple outputs).
|
| Raises:
| RuntimeError: If called in Eager mode.
|
| load_own_variables(self, store)
| Loads the state of the layer.
|
| You can override this method to take full control of how the state of
| the layer is loaded upon calling `keras.models.load_model()`.
|
| Args:
| store: Dict from which the state of the model will be loaded.
|
| save_own_variables(self, store)
| Saves the state of the layer.
|
| You can override this method to take full control of how the state of
| the layer is saved upon calling `model.save()`.
|
| Args:
| store: Dict where the state of the model will be saved.
|
| set_weights(self, weights)
| Sets the weights of the layer, from NumPy arrays.
|
| The weights of a layer represent the state of the layer. This function
| sets the weight values from numpy arrays. The weight values should be
| passed in the order they are created by the layer. Note that the layer's
| weights must be instantiated before calling this function, by calling
| the layer.
|
| For example, a `Dense` layer returns a list of two values: the kernel
| matrix and the bias vector. These can be used to set the weights of
| another `Dense` layer:
|
| >>> layer_a = tf.keras.layers.Dense(1,
| ... kernel_initializer=tf.constant_initializer(1.))
| >>> a_out = layer_a(tf.convert_to_tensor([[1., 2., 3.]]))
| >>> layer_a.get_weights()
| [array([[1.],
| [1.],
| [1.]], dtype=float32), array([0.], dtype=float32)]
| >>> layer_b = tf.keras.layers.Dense(1,
| ... kernel_initializer=tf.constant_initializer(2.))
| >>> b_out = layer_b(tf.convert_to_tensor([[10., 20., 30.]]))
| >>> layer_b.get_weights()
| [array([[2.],
| [2.],
| [2.]], dtype=float32), array([0.], dtype=float32)]
| >>> layer_b.set_weights(layer_a.get_weights())
| >>> layer_b.get_weights()
| [array([[1.],
| [1.],
| [1.]], dtype=float32), array([0.], dtype=float32)]
|
| Args:
| weights: a list of NumPy arrays. The number
| of arrays and their shape must match
| number of the dimensions of the weights
| of the layer (i.e. it should match the
| output of `get_weights`).
|
| Raises:
| ValueError: If the provided weights list does not match the
| layer's specifications.
|
| ----------------------------------------------------------------------
| Readonly properties inherited from tf_keras.src.engine.base_layer.Layer:
|
| compute_dtype
| The dtype of the layer's computations.
|
| This is equivalent to `Layer.dtype_policy.compute_dtype`. Unless
| mixed precision is used, this is the same as `Layer.dtype`, the dtype of
| the weights.
|
| Layers automatically cast their inputs to the compute dtype, which
| causes computations and the output to be in the compute dtype as well.
| This is done by the base Layer class in `Layer.__call__`, so you do not
| have to insert these casts if implementing your own layer.
|
| Layers often perform certain internal computations in higher precision
| when `compute_dtype` is float16 or bfloat16 for numeric stability. The
| output will still typically be float16 or bfloat16 in such cases.
|
| Returns:
| The layer's compute dtype.
|
| dtype
| The dtype of the layer weights.
|
| This is equivalent to `Layer.dtype_policy.variable_dtype`. Unless
| mixed precision is used, this is the same as `Layer.compute_dtype`, the
| dtype of the layer's computations.
|
| dtype_policy
| The dtype policy associated with this layer.
|
| This is an instance of a `tf.keras.mixed_precision.Policy`.
|
| dynamic
| Whether the layer is dynamic (eager-only); set in the constructor.
|
| inbound_nodes
| Return Functional API nodes upstream of this layer.
|
| input
| Retrieves the input tensor(s) of a layer.
|
| Only applicable if the layer has exactly one input,
| i.e. if it is connected to one incoming layer.
|
| Returns:
| Input tensor or list of input tensors.
|
| Raises:
| RuntimeError: If called in Eager mode.
| AttributeError: If no inbound nodes are found.
|
| input_mask
| Retrieves the input mask tensor(s) of a layer.
|
| Only applicable if the layer has exactly one inbound node,
| i.e. if it is connected to one incoming layer.
|
| Returns:
| Input mask tensor (potentially None) or list of input
| mask tensors.
|
| Raises:
| AttributeError: if the layer is connected to
| more than one incoming layers.
|
| input_shape
| Retrieves the input shape(s) of a layer.
|
| Only applicable if the layer has exactly one input,
| i.e. if it is connected to one incoming layer, or if all inputs
| have the same shape.
|
| Returns:
| Input shape, as an integer shape tuple
| (or list of shape tuples, one tuple per input tensor).
|
| Raises:
| AttributeError: if the layer has no defined input_shape.
| RuntimeError: if called in Eager mode.
|
| losses
| List of losses added using the `add_loss()` API.
|
| Variable regularization tensors are created when this property is
| accessed, so it is eager safe: accessing `losses` under a
| `tf.GradientTape` will propagate gradients back to the corresponding
| variables.
|
| Examples:
|
| >>> class MyLayer(tf.keras.layers.Layer):
| ... def call(self, inputs):
| ... self.add_loss(tf.abs(tf.reduce_mean(inputs)))
| ... return inputs
| >>> l = MyLayer()
| >>> l(np.ones((10, 1)))
| >>> l.losses
| [1.0]
|
| >>> inputs = tf.keras.Input(shape=(10,))
| >>> x = tf.keras.layers.Dense(10)(inputs)
| >>> outputs = tf.keras.layers.Dense(1)(x)
| >>> model = tf.keras.Model(inputs, outputs)
| >>> # Activity regularization.
| >>> len(model.losses)
| 0
| >>> model.add_loss(tf.abs(tf.reduce_mean(x)))
| >>> len(model.losses)
| 1
|
| >>> inputs = tf.keras.Input(shape=(10,))
| >>> d = tf.keras.layers.Dense(10, kernel_initializer='ones')
| >>> x = d(inputs)
| >>> outputs = tf.keras.layers.Dense(1)(x)
| >>> model = tf.keras.Model(inputs, outputs)
| >>> # Weight regularization.
| >>> model.add_loss(lambda: tf.reduce_mean(d.kernel))
| >>> model.losses
| [<tf.Tensor: shape=(), dtype=float32, numpy=1.0>]
|
| Returns:
| A list of tensors.
|
| name
| Name of the layer (string), set in the constructor.
|
| non_trainable_variables
| Sequence of non-trainable variables owned by this module and its submodules.
|
| Note: this method uses reflection to find variables on the current instance
| and submodules. For performance reasons you may wish to cache the result
| of calling this method if you don't expect the return value to change.
|
| Returns:
| A sequence of variables for the current module (sorted by attribute
| name) followed by variables from all submodules recursively (breadth
| first).
|
| outbound_nodes
| Return Functional API nodes downstream of this layer.
|
| output
| Retrieves the output tensor(s) of a layer.
|
| Only applicable if the layer has exactly one output,
| i.e. if it is connected to one incoming layer.
|
| Returns:
| Output tensor or list of output tensors.
|
| Raises:
| AttributeError: if the layer is connected to more than one incoming
| layers.
| RuntimeError: if called in Eager mode.
|
| output_mask
| Retrieves the output mask tensor(s) of a layer.
|
| Only applicable if the layer has exactly one inbound node,
| i.e. if it is connected to one incoming layer.
|
| Returns:
| Output mask tensor (potentially None) or list of output
| mask tensors.
|
| Raises:
| AttributeError: if the layer is connected to
| more than one incoming layers.
|
| output_shape
| Retrieves the output shape(s) of a layer.
|
| Only applicable if the layer has one output,
| or if all outputs have the same shape.
|
| Returns:
| Output shape, as an integer shape tuple
| (or list of shape tuples, one tuple per output tensor).
|
| Raises:
| AttributeError: if the layer has no defined output shape.
| RuntimeError: if called in Eager mode.
|
| trainable_variables
| Sequence of trainable variables owned by this module and its submodules.
|
| Note: this method uses reflection to find variables on the current instance
| and submodules. For performance reasons you may wish to cache the result
| of calling this method if you don't expect the return value to change.
|
| Returns:
| A sequence of variables for the current module (sorted by attribute
| name) followed by variables from all submodules recursively (breadth
| first).
|
| updates
|
| variable_dtype
| Alias of `Layer.dtype`, the dtype of the weights.
|
| variables
| Returns the list of all layer variables/weights.
|
| Alias of `self.weights`.
|
| Note: This will not track the weights of nested `tf.Modules` that are
| not themselves TF-Keras layers.
|
| Returns:
| A list of variables.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from tf_keras.src.engine.base_layer.Layer:
|
| activity_regularizer
| Optional regularizer function for the output of this layer.
|
| input_spec
| `InputSpec` instance(s) describing the input format for this layer.
|
| When you create a layer subclass, you can set `self.input_spec` to
| enable the layer to run input compatibility checks when it is called.
| Consider a `Conv2D` layer: it can only be called on a single input
| tensor of rank 4. As such, you can set, in `__init__()`:
|
| ```python
| self.input_spec = tf.keras.layers.InputSpec(ndim=4)
| ```
|
| Now, if you try to call the layer on an input that isn't rank 4
| (for instance, an input of shape `(2,)`, it will raise a
| nicely-formatted error:
|
| ```
| ValueError: Input 0 of layer conv2d is incompatible with the layer:
| expected ndim=4, found ndim=1. Full shape received: [2]
| ```
|
| Input checks that can be specified via `input_spec` include:
| - Structure (e.g. a single input, a list of 2 inputs, etc)
| - Shape
| - Rank (ndim)
| - Dtype
|
| For more information, see `tf.keras.layers.InputSpec`.
|
| Returns:
| A `tf.keras.layers.InputSpec` instance, or nested structure thereof.
|
| stateful
|
| supports_masking
| Whether this layer supports computing a mask using `compute_mask`.
|
| trainable
|
| ----------------------------------------------------------------------
| Class methods inherited from tensorflow.python.module.module.Module:
|
| with_name_scope(method) from builtins.type
| Decorator to automatically enter the module name scope.
|
| >>> class MyModule(tf.Module):
| ... @tf.Module.with_name_scope
| ... def __call__(self, x):
| ... if not hasattr(self, 'w'):
| ... self.w = tf.Variable(tf.random.normal([x.shape[1], 3]))
| ... return tf.matmul(x, self.w)
|
| Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
| names included the module name:
|
| >>> mod = MyModule()
| >>> mod(tf.ones([1, 2]))
| <tf.Tensor: shape=(1, 3), dtype=float32, numpy=..., dtype=float32)>
| >>> mod.w
| <tf.Variable 'my_module/Variable:0' shape=(2, 3) dtype=float32,
| numpy=..., dtype=float32)>
|
| Args:
| method: The method to wrap.
|
| Returns:
| The original method wrapped such that it enters the module's name scope.
|
| ----------------------------------------------------------------------
| Readonly properties inherited from tensorflow.python.module.module.Module:
|
| name_scope
| Returns a `tf.name_scope` instance for this class.
|
| submodules
| Sequence of all sub-modules.
|
| Submodules are modules which are properties of this module, or found as
| properties of modules which are properties of this module (and so on).
|
| >>> a = tf.Module()
| >>> b = tf.Module()
| >>> c = tf.Module()
| >>> a.b = b
| >>> b.c = c
| >>> list(a.submodules) == [b, c]
| True
| >>> list(b.submodules) == [c]
| True
| >>> list(c.submodules) == []
| True
|
| Returns:
| A sequence of all submodules.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from tensorflow.python.trackable.base.Trackable:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
使用特征子集
前面的示例没有指定特征,因此所有列都用作输入特征(标签除外)。以下示例显示了如何指定输入特征。
feature_1 = tfdf.keras.FeatureUsage(name="bill_length_mm")
feature_2 = tfdf.keras.FeatureUsage(name="island")
all_features = [feature_1, feature_2]
# Note: This model is only trained with two features. It will not be as good as
# the one trained on all features.
model_2 = tfdf.keras.GradientBoostedTreesModel(
features=all_features, exclude_non_specified_features=True)
model_2.compile(metrics=["accuracy"])
model_2.fit(train_ds, validation_data=test_ds)
print(model_2.evaluate(test_ds, return_dict=True))
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpxy6e_tv7 as temporary training directory
Reading training dataset...
Training dataset read in 0:00:00.143923. Found 234 examples.
Reading validation dataset...
[WARNING 24-04-20 11:27:30.1247 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 24-04-20 11:27:30.1247 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 24-04-20 11:27:30.1247 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
Num validation examples: tf.Tensor(110, shape=(), dtype=int32)
Validation dataset read in 0:00:00.211031. Found 110 examples.
Training model...
Model trained in 0:00:00.340464
Compiling model...
Model compiled.
[INFO 24-04-20 11:27:30.8221 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpxy6e_tv7/model/ with prefix da2733be40aa4faa
[INFO 24-04-20 11:27:30.8295 UTC decision_forest.cc:734] Model loaded with 84 root(s), 2502 node(s), and 2 input feature(s).
[INFO 24-04-20 11:27:30.8295 UTC abstract_model.cc:1344] Engine "GradientBoostedTreesGeneric" built
[INFO 24-04-20 11:27:30.8295 UTC kernel.cc:1061] Use fast generic engine
1/1 [==============================] - 0s 126ms/step - loss: 0.0000e+00 - accuracy: 0.9636
{'loss': 0.0, 'accuracy': 0.9636363387107849}
TF-DF 为每个特征附加一个语义。此语义控制模型如何使用特征。当前支持以下语义
- 数值:通常用于具有完整排序的量或计数。例如,一个人的年龄或一个包中的物品数量。可以是浮点数或整数。缺失值用 float(Nan) 或空稀疏张量表示。
- 分类:通常用于有限可能值集中的类型/类别,没有排序。例如,集合 {RED, BLUE, GREEN} 中的颜色 RED。可以是字符串或整数。缺失值用 ""(空字符串)、值 -2 或空稀疏张量表示。
- 分类集:一组分类值。非常适合表示标记化的文本。可以是稀疏张量或不规则张量(推荐)中的字符串或整数。每个项目的顺序/索引无关紧要。
如果未指定,则语义将从表示类型推断,并在训练日志中显示
- int、float(密集或稀疏)→ 数值语义。
- str(密集或稀疏)→ 分类语义
- int、str(不规则)→ 分类集语义
在某些情况下,推断的语义不正确。例如:存储为整数的枚举在语义上是分类的,但它将被检测为数值。在这种情况下,您应该在输入中指定语义参数。Adult 数据集的 education_num 字段就是一个典型的例子。
此数据集不包含此类特征。但是,为了演示,我们将使模型将 year 视为分类特征
%set_cell_height 300
feature_1 = tfdf.keras.FeatureUsage(name="year", semantic=tfdf.keras.FeatureSemantic.CATEGORICAL)
feature_2 = tfdf.keras.FeatureUsage(name="bill_length_mm")
feature_3 = tfdf.keras.FeatureUsage(name="sex")
all_features = [feature_1, feature_2, feature_3]
model_3 = tfdf.keras.GradientBoostedTreesModel(features=all_features, exclude_non_specified_features=True)
model_3.compile( metrics=["accuracy"])
model_3.fit(train_ds, validation_data=test_ds)
<IPython.core.display.Javascript object> Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmp0zhsozon as temporary training directory Reading training dataset... Training dataset read in 0:00:00.148776. Found 234 examples. Reading validation dataset... [WARNING 24-04-20 11:27:31.3125 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS". [WARNING 24-04-20 11:27:31.3125 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS". [WARNING 24-04-20 11:27:31.3125 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB". Num validation examples: tf.Tensor(110, shape=(), dtype=int32) Validation dataset read in 0:00:00.157524. Found 110 examples. Training model... Model trained in 0:00:00.287483 Compiling model... Model compiled. [INFO 24-04-20 11:27:31.9092 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmp0zhsozon/model/ with prefix bce0cec3f97a4755 [INFO 24-04-20 11:27:31.9153 UTC decision_forest.cc:734] Model loaded with 54 root(s), 1854 node(s), and 3 input feature(s). [INFO 24-04-20 11:27:31.9154 UTC kernel.cc:1061] Use fast generic engine <tf_keras.src.callbacks.History at 0x7f55402df880>
请注意,year 在 CATEGORICAL 特征列表中(与第一次运行不同)。
超参数
超参数是训练算法的参数,会影响最终模型的质量。它们在模型类构造函数中指定。超参数列表可以使用问号 Colab 命令查看(例如,?tfdf.keras.GradientBoostedTreesModel)。
或者,您可以在 TensorFlow Decision Forest Github 或 Yggdrasil Decision Forest 文档 上找到它们。
每个算法的默认超参数大致匹配最初的出版物论文。为了确保一致性,新功能及其匹配的超参数默认情况下始终处于禁用状态。这就是为什么调整超参数是一个好主意。
# A classical but slighly more complex model.
model_6 = tfdf.keras.GradientBoostedTreesModel(
num_trees=500, growing_strategy="BEST_FIRST_GLOBAL", max_depth=8)
model_6.fit(train_ds)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmp00vc5pht as temporary training directory Reading training dataset... Training dataset read in 0:00:00.176264. Found 234 examples. Training model... [WARNING 24-04-20 11:27:32.2670 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS". [WARNING 24-04-20 11:27:32.2671 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS". [WARNING 24-04-20 11:27:32.2671 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB". Model trained in 0:00:00.375518 Compiling model... Model compiled. [INFO 24-04-20 11:27:32.8167 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmp00vc5pht/model/ with prefix 59ace60cbb934c36 [INFO 24-04-20 11:27:32.8255 UTC decision_forest.cc:734] Model loaded with 63 root(s), 3015 node(s), and 7 input feature(s). [INFO 24-04-20 11:27:32.8255 UTC kernel.cc:1061] Use fast generic engine <tf_keras.src.callbacks.History at 0x7f54105eb460>
# A more complex, but possibly, more accurate model.
model_7 = tfdf.keras.GradientBoostedTreesModel(
num_trees=500,
growing_strategy="BEST_FIRST_GLOBAL",
max_depth=8,
split_axis="SPARSE_OBLIQUE",
categorical_algorithm="RANDOM",
)
model_7.fit(train_ds)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmptd58uwue as temporary training directory Reading training dataset... [WARNING 24-04-20 11:27:32.9947 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS". [WARNING 24-04-20 11:27:32.9948 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS". [WARNING 24-04-20 11:27:32.9948 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB". WARNING:tensorflow:5 out of the last 5 calls to <function CoreModel._consumes_training_examples_until_eof at 0x7f54243c8f70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details. WARNING:tensorflow:5 out of the last 5 calls to <function CoreModel._consumes_training_examples_until_eof at 0x7f54243c8f70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details. Training dataset read in 0:00:00.180064. Found 234 examples. Training model... Model trained in 0:00:01.086266 Compiling model... WARNING:tensorflow:5 out of the last 5 calls to <function InferenceCoreModel.make_predict_function.<locals>.predict_function_trained at 0x7f54105329d0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details. [INFO 24-04-20 11:27:34.2368 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmptd58uwue/model/ with prefix 48e525341fe24b68 [INFO 24-04-20 11:27:34.2668 UTC decision_forest.cc:734] Model loaded with 177 root(s), 8965 node(s), and 7 input feature(s). [INFO 24-04-20 11:27:34.2668 UTC kernel.cc:1061] Use fast generic engine WARNING:tensorflow:5 out of the last 5 calls to <function InferenceCoreModel.make_predict_function.<locals>.predict_function_trained at 0x7f54105329d0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details. Model compiled. <tf_keras.src.callbacks.History at 0x7f5410593100>
随着新训练方法的发布和实施,超参数组合可能会出现,这些组合比默认参数更好或几乎总是更好。为了避免更改默认超参数值,这些良好组合被索引并作为超参数模板提供。
例如,benchmark_rank1 模板是我们内部基准测试中最好的组合。这些模板是版本化的,以允许训练配置稳定性,例如 benchmark_rank1@v1。
# A good template of hyper-parameters.
model_8 = tfdf.keras.GradientBoostedTreesModel(hyperparameter_template="benchmark_rank1")
model_8.fit(train_ds)
Resolve hyper-parameter template "benchmark_rank1" to "benchmark_rank1@v1" -> {'growing_strategy': 'BEST_FIRST_GLOBAL', 'categorical_algorithm': 'RANDOM', 'split_axis': 'SPARSE_OBLIQUE', 'sparse_oblique_normalization': 'MIN_MAX', 'sparse_oblique_num_projections_exponent': 1.0}.
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpgora_6xj as temporary training directory
Reading training dataset...
WARNING:tensorflow:6 out of the last 6 calls to <function CoreModel._consumes_training_examples_until_eof at 0x7f54243c8f70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
[WARNING 24-04-20 11:27:34.4381 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 24-04-20 11:27:34.4381 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 24-04-20 11:27:34.4382 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
WARNING:tensorflow:6 out of the last 6 calls to <function CoreModel._consumes_training_examples_until_eof at 0x7f54243c8f70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
Training dataset read in 0:00:00.178767. Found 234 examples.
Training model...
Model trained in 0:00:00.623958
Compiling model...
WARNING:tensorflow:6 out of the last 6 calls to <function InferenceCoreModel.make_predict_function.<locals>.predict_function_trained at 0x7f54200e8790> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
[INFO 24-04-20 11:27:35.2353 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpgora_6xj/model/ with prefix 1639f12e3b334a22
[INFO 24-04-20 11:27:35.2516 UTC decision_forest.cc:734] Model loaded with 144 root(s), 5380 node(s), and 7 input feature(s).
[INFO 24-04-20 11:27:35.2516 UTC kernel.cc:1061] Use fast generic engine
WARNING:tensorflow:6 out of the last 6 calls to <function InferenceCoreModel.make_predict_function.<locals>.predict_function_trained at 0x7f54200e8790> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
Model compiled.
<tf_keras.src.callbacks.History at 0x7f54104d9a60>
可以使用 predefined_hyperparameters 获取可用的模板。请注意,不同的学习算法具有不同的模板,即使名称相似。
# The hyper-parameter templates of the Gradient Boosted Tree model.
print(tfdf.keras.GradientBoostedTreesModel.predefined_hyperparameters())
[HyperParameterTemplate(name='better_default', version=1, parameters={'growing_strategy': 'BEST_FIRST_GLOBAL'}, description='A configuration that is generally better than the default parameters without being more expensive.'), HyperParameterTemplate(name='benchmark_rank1', version=1, parameters={'growing_strategy': 'BEST_FIRST_GLOBAL', 'categorical_algorithm': 'RANDOM', 'split_axis': 'SPARSE_OBLIQUE', 'sparse_oblique_normalization': 'MIN_MAX', 'sparse_oblique_num_projections_exponent': 1.0}, description='Top ranking hyper-parameters on our benchmark slightly modified to run in reasonable time.')]
特征预处理
有时需要对特征进行预处理,以使用具有复杂结构的信号,规范化模型或应用迁移学习。预处理可以通过以下三种方式之一完成
在 Pandas 数据框上进行预处理。此解决方案易于实施,通常适合实验。但是,预处理逻辑不会通过
model.save()导出到模型中。Keras 预处理:虽然比前面的解决方案更复杂,但 Keras 预处理已打包到模型中。
TensorFlow 特征列: 此 API 是 TF Estimator 库的一部分(与 Keras 不相同),计划弃用。当使用现有预处理代码时,此解决方案很有趣。
在下一个示例中,将 body_mass_g 特征预处理为 body_mass_kg = body_mass_g / 1000。 bill_length_mm 在没有预处理的情况下被使用。请注意,此类单调变换通常不会影响决策森林模型。
%set_cell_height 300
body_mass_g = tf_keras.layers.Input(shape=(1,), name="body_mass_g")
body_mass_kg = body_mass_g / 1000.0
bill_length_mm = tf_keras.layers.Input(shape=(1,), name="bill_length_mm")
raw_inputs = {"body_mass_g": body_mass_g, "bill_length_mm": bill_length_mm}
processed_inputs = {"body_mass_kg": body_mass_kg, "bill_length_mm": bill_length_mm}
# "preprocessor" contains the preprocessing logic.
preprocessor = tf_keras.Model(inputs=raw_inputs, outputs=processed_inputs)
# "model_4" contains both the pre-processing logic and the decision forest.
model_4 = tfdf.keras.RandomForestModel(preprocessing=preprocessor)
model_4.fit(train_ds)
model_4.summary()
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmp0cckk9wo as temporary training directory
Reading training dataset...
/tmpfs/tmp/__autograph_generated_filec59wzauh.py:63: UserWarning: Input dict contained keys ['island', 'bill_depth_mm', 'flipper_length_mm', 'sex', 'year'] which did not match any model input. They will be ignored by the model.
ag__.converted_call(ag__.ld(warnings).warn, (ag__.converted_call('Input dict contained keys {} which did not match any model input. They will be ignored by the model.'.format, ([ag__.ld(n) for n in ag__.converted_call(ag__.ld(tensors).keys, (), None, fscope) if ag__.ld(n) not in ag__.ld(ref_input_names)],), None, fscope),), dict(stacklevel=2), fscope)
Training dataset read in 0:00:01.279616. Found 234 examples.
Training model...
Model trained in 0:00:00.044363
Compiling model...
Model compiled.
WARNING:tensorflow:5 out of the last 12 calls to <function InferenceCoreModel.yggdrasil_model_path_tensor at 0x7f5410325dc0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
[INFO 24-04-20 11:27:36.7569 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmp0cckk9wo/model/ with prefix 3f81564b030c4d16
[INFO 24-04-20 11:27:36.7753 UTC decision_forest.cc:734] Model loaded with 300 root(s), 6444 node(s), and 2 input feature(s).
[INFO 24-04-20 11:27:36.7753 UTC kernel.cc:1061] Use fast generic engine
WARNING:tensorflow:5 out of the last 12 calls to <function InferenceCoreModel.yggdrasil_model_path_tensor at 0x7f5410325dc0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
Model: "random_forest_model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model (Functional) {'body_mass_kg': (None, 0
1),
'bill_length_mm': (Non
e, 1)}
=================================================================
Total params: 1 (1.00 Byte)
Trainable params: 0 (0.00 Byte)
Non-trainable params: 1 (1.00 Byte)
_________________________________________________________________
Type: "RANDOM_FOREST"
Task: CLASSIFICATION
Label: "__LABEL"
Input Features (2):
bill_length_mm
body_mass_kg
No weights
Variable Importance: INV_MEAN_MIN_DEPTH:
1. "bill_length_mm" 1.000000 ################
2. "body_mass_kg" 0.423552
Variable Importance: NUM_AS_ROOT:
1. "bill_length_mm" 300.000000
Variable Importance: NUM_NODES:
1. "bill_length_mm" 1652.000000 ################
2. "body_mass_kg" 1420.000000
Variable Importance: SUM_SCORE:
1. "bill_length_mm" 43353.054934 ################
2. "body_mass_kg" 23204.257581
Winner takes all: true
Out-of-bag evaluation: accuracy:0.905983 logloss:0.676408
Number of trees: 300
Total number of nodes: 6444
Number of nodes by tree:
Count: 300 Average: 21.48 StdDev: 3.15113
Min: 11 Max: 31 Ignored: 0
----------------------------------------------
[ 11, 12) 1 0.33% 0.33%
[ 12, 13) 0 0.00% 0.33%
[ 13, 14) 1 0.33% 0.67%
[ 14, 15) 0 0.00% 0.67%
[ 15, 16) 13 4.33% 5.00% ##
[ 16, 17) 0 0.00% 5.00%
[ 17, 18) 22 7.33% 12.33% ###
[ 18, 19) 0 0.00% 12.33%
[ 19, 20) 55 18.33% 30.67% #######
[ 20, 21) 0 0.00% 30.67%
[ 21, 22) 75 25.00% 55.67% ##########
[ 22, 23) 0 0.00% 55.67%
[ 23, 24) 76 25.33% 81.00% ##########
[ 24, 25) 0 0.00% 81.00%
[ 25, 26) 33 11.00% 92.00% ####
[ 26, 27) 0 0.00% 92.00%
[ 27, 28) 20 6.67% 98.67% ###
[ 28, 29) 0 0.00% 98.67%
[ 29, 30) 3 1.00% 99.67%
[ 30, 31] 1 0.33% 100.00%
Depth by leafs:
Count: 3372 Average: 4.00593 StdDev: 1.31059
Min: 1 Max: 8 Ignored: 0
----------------------------------------------
[ 1, 2) 21 0.62% 0.62%
[ 2, 3) 336 9.96% 10.59% ###
[ 3, 4) 941 27.91% 38.49% #########
[ 4, 5) 1016 30.13% 68.62% ##########
[ 5, 6) 575 17.05% 85.68% ######
[ 6, 7) 346 10.26% 95.94% ###
[ 7, 8) 119 3.53% 99.47% #
[ 8, 8] 18 0.53% 100.00%
Number of training obs by leaf:
Count: 3372 Average: 20.8185 StdDev: 25.5501
Min: 5 Max: 114 Ignored: 0
----------------------------------------------
[ 5, 10) 2147 63.67% 63.67% ##########
[ 10, 16) 269 7.98% 71.65% #
[ 16, 21) 48 1.42% 73.07%
[ 21, 27) 27 0.80% 73.87%
[ 27, 32) 53 1.57% 75.44%
[ 32, 38) 118 3.50% 78.94% #
[ 38, 43) 86 2.55% 81.49%
[ 43, 49) 115 3.41% 84.91% #
[ 49, 54) 76 2.25% 87.16%
[ 54, 60) 72 2.14% 89.29%
[ 60, 65) 45 1.33% 90.63%
[ 65, 71) 22 0.65% 91.28%
[ 71, 76) 29 0.86% 92.14%
[ 76, 82) 61 1.81% 93.95%
[ 82, 87) 58 1.72% 95.67%
[ 87, 93) 74 2.19% 97.86%
[ 93, 98) 33 0.98% 98.84%
[ 98, 104) 26 0.77% 99.61%
[ 104, 109) 9 0.27% 99.88%
[ 109, 114] 4 0.12% 100.00%
Attribute in nodes:
1652 : bill_length_mm [NUMERICAL]
1420 : body_mass_kg [NUMERICAL]
Attribute in nodes with depth <= 0:
300 : bill_length_mm [NUMERICAL]
Attribute in nodes with depth <= 1:
523 : bill_length_mm [NUMERICAL]
356 : body_mass_kg [NUMERICAL]
Attribute in nodes with depth <= 2:
854 : bill_length_mm [NUMERICAL]
847 : body_mass_kg [NUMERICAL]
Attribute in nodes with depth <= 3:
1248 : bill_length_mm [NUMERICAL]
1156 : body_mass_kg [NUMERICAL]
Attribute in nodes with depth <= 5:
1603 : bill_length_mm [NUMERICAL]
1396 : body_mass_kg [NUMERICAL]
Condition type in nodes:
3072 : HigherCondition
Condition type in nodes with depth <= 0:
300 : HigherCondition
Condition type in nodes with depth <= 1:
879 : HigherCondition
Condition type in nodes with depth <= 2:
1701 : HigherCondition
Condition type in nodes with depth <= 3:
2404 : HigherCondition
Condition type in nodes with depth <= 5:
2999 : HigherCondition
Node format: NOT_SET
Training OOB:
trees: 1, Out-of-bag evaluation: accuracy:0.885057 logloss:4.14295
trees: 11, Out-of-bag evaluation: accuracy:0.901288 logloss:2.3862
trees: 22, Out-of-bag evaluation: accuracy:0.905983 logloss:1.92983
trees: 32, Out-of-bag evaluation: accuracy:0.905983 logloss:1.79654
trees: 42, Out-of-bag evaluation: accuracy:0.905983 logloss:1.50883
trees: 52, Out-of-bag evaluation: accuracy:0.901709 logloss:1.36258
trees: 62, Out-of-bag evaluation: accuracy:0.905983 logloss:1.21612
trees: 72, Out-of-bag evaluation: accuracy:0.901709 logloss:1.21228
trees: 82, Out-of-bag evaluation: accuracy:0.91453 logloss:1.21659
trees: 92, Out-of-bag evaluation: accuracy:0.905983 logloss:1.21039
trees: 102, Out-of-bag evaluation: accuracy:0.91453 logloss:1.20993
trees: 112, Out-of-bag evaluation: accuracy:0.910256 logloss:1.07063
trees: 122, Out-of-bag evaluation: accuracy:0.910256 logloss:1.07392
trees: 132, Out-of-bag evaluation: accuracy:0.905983 logloss:1.07417
trees: 143, Out-of-bag evaluation: accuracy:0.901709 logloss:1.07334
trees: 153, Out-of-bag evaluation: accuracy:0.901709 logloss:1.07422
trees: 164, Out-of-bag evaluation: accuracy:0.901709 logloss:1.0733
trees: 174, Out-of-bag evaluation: accuracy:0.901709 logloss:0.938447
trees: 185, Out-of-bag evaluation: accuracy:0.901709 logloss:0.939815
trees: 195, Out-of-bag evaluation: accuracy:0.901709 logloss:0.941003
trees: 205, Out-of-bag evaluation: accuracy:0.901709 logloss:0.943527
trees: 215, Out-of-bag evaluation: accuracy:0.901709 logloss:0.808602
trees: 225, Out-of-bag evaluation: accuracy:0.901709 logloss:0.809466
trees: 236, Out-of-bag evaluation: accuracy:0.905983 logloss:0.810385
trees: 246, Out-of-bag evaluation: accuracy:0.905983 logloss:0.8095
trees: 256, Out-of-bag evaluation: accuracy:0.905983 logloss:0.67594
trees: 266, Out-of-bag evaluation: accuracy:0.905983 logloss:0.674199
trees: 276, Out-of-bag evaluation: accuracy:0.905983 logloss:0.67384
trees: 286, Out-of-bag evaluation: accuracy:0.905983 logloss:0.676288
trees: 296, Out-of-bag evaluation: accuracy:0.905983 logloss:0.674894
trees: 300, Out-of-bag evaluation: accuracy:0.905983 logloss:0.676408
以下示例使用 TensorFlow 特征列重新实现相同的逻辑。
def g_to_kg(x):
return x / 1000
feature_columns = [
tf.feature_column.numeric_column("body_mass_g", normalizer_fn=g_to_kg),
tf.feature_column.numeric_column("bill_length_mm"),
]
preprocessing = tf_keras.layers.DenseFeatures(feature_columns)
model_5 = tfdf.keras.RandomForestModel(preprocessing=preprocessing)
model_5.fit(train_ds)
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_33473/496948527.py:5: numeric_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model. WARNING:tensorflow:From /tmpfs/tmp/ipykernel_33473/496948527.py:5: numeric_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model. Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmpmn9yyl50 as temporary training directory Reading training dataset... Training dataset read in 0:00:00.764201. Found 234 examples. Training model... Model trained in 0:00:00.045311 Compiling model... Model compiled. WARNING:tensorflow:6 out of the last 13 calls to <function InferenceCoreModel.yggdrasil_model_path_tensor at 0x7f5410243670> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details. [INFO 24-04-20 11:27:37.7897 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpmn9yyl50/model/ with prefix 5378896ee3e444f1 [INFO 24-04-20 11:27:37.8090 UTC decision_forest.cc:734] Model loaded with 300 root(s), 6444 node(s), and 2 input feature(s). [INFO 24-04-20 11:27:37.8091 UTC kernel.cc:1061] Use fast generic engine WARNING:tensorflow:6 out of the last 13 calls to <function InferenceCoreModel.yggdrasil_model_path_tensor at 0x7f5410243670> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details. <tf_keras.src.callbacks.History at 0x7f54103f0040>
训练回归模型
前面的示例训练了一个分类模型(TF-DF 不区分二元分类和多类分类)。在下一个示例中,在 鲍鱼数据集 上训练一个回归模型。此数据集的目标是预测鲍鱼贝壳的环数。

# Download the dataset.
!wget -q https://storage.googleapis.com/download.tensorflow.org/data/abalone_raw.csv -O /tmp/abalone.csv
dataset_df = pd.read_csv("/tmp/abalone.csv")
print(dataset_df.head(3))
Type LongestShell Diameter Height WholeWeight ShuckedWeight \ 0 M 0.455 0.365 0.095 0.5140 0.2245 1 M 0.350 0.265 0.090 0.2255 0.0995 2 F 0.530 0.420 0.135 0.6770 0.2565 VisceraWeight ShellWeight Rings 0 0.1010 0.15 15 1 0.0485 0.07 7 2 0.1415 0.21 9
# Split the dataset into a training and testing dataset.
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples for testing.".format(
len(train_ds_pd), len(test_ds_pd)))
# Name of the label column.
label = "Rings"
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label, task=tfdf.keras.Task.REGRESSION)
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_ds_pd, label=label, task=tfdf.keras.Task.REGRESSION)
2945 examples in training, 1232 examples for testing.
%set_cell_height 300
# Configure the model.
model_7 = tfdf.keras.RandomForestModel(task = tfdf.keras.Task.REGRESSION)
# Train the model.
model_7.fit(train_ds)
<IPython.core.display.Javascript object> Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmp98v5wan5 as temporary training directory Reading training dataset... Training dataset read in 0:00:00.209393. Found 2945 examples. Training model... [INFO 24-04-20 11:27:39.3005 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmp98v5wan5/model/ with prefix 45e6275ae91f42f8 Model trained in 0:00:01.387455 Compiling model... [INFO 24-04-20 11:27:40.0857 UTC decision_forest.cc:734] Model loaded with 300 root(s), 264030 node(s), and 8 input feature(s). [INFO 24-04-20 11:27:40.0857 UTC kernel.cc:1061] Use fast generic engine Model compiled. <tf_keras.src.callbacks.History at 0x7f54101fd250>
# Evaluate the model on the test dataset.
model_7.compile(metrics=["mse"])
evaluation = model_7.evaluate(test_ds, return_dict=True)
print(evaluation)
print()
print(f"MSE: {evaluation['mse']}")
print(f"RMSE: {math.sqrt(evaluation['mse'])}")
WARNING:tensorflow:5 out of the last 5 calls to <function InferenceCoreModel.make_test_function.<locals>.test_function at 0x7f54102e9820> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:5 out of the last 5 calls to <function InferenceCoreModel.make_test_function.<locals>.test_function at 0x7f54102e9820> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
2/2 [==============================] - 1s 14ms/step - loss: 0.0000e+00 - mse: 4.3557
{'loss': 0.0, 'mse': 4.355661392211914}
MSE: 4.355661392211914
RMSE: 2.087022135055571