
|
|
|
 在 GitHub 上查看 在 GitHub 上查看
|
|
介绍
Leo Breiman 是 随机森林 学习算法的作者,他 提出 了一种使用预训练随机森林 (RF) 模型来衡量两个示例之间邻近度(也称为相似度)的方法。他将这种方法描述为“[...] 随机森林中最有用的工具之一。”。在本笔记本中,我们将实现这种方法,并展示如何使用它来解释模型。
本笔记本使用 TensorFlow 决策森林 库实现。如果您熟悉 初学者 colab 的内容,则更容易理解本文档。
邻近度
两个示例之间的邻近度(或相似度)是一个数字,表示这两个示例之间的“接近程度”。以下是 3 个示例 \(\{e_1, e_2, e_3\}\) 之间相似度的示例
\[ \mathrm{proxy}(e_1, e_2) = 0.1 \\ \mathrm{proxy}(e_2, e_3) = 9.6 \\ \mathrm{proxy}(e_3, e_1) = 4.1 \\ \]
为了方便起见,示例之间的邻近度以矩阵形式表示
| \(e_1\) | \(e_2\) | \(e_3\) | |
|---|---|---|---|
| \(e_1\) | \(\mathrm{proxy}(e_1, e_1)\) | \(\mathrm{proxy}(e_1, e_2)\) | \(\mathrm{proxy}(e_1, e_3)\) |
| \(e_2\) | \(\mathrm{proxy}(e_2, e_1)\) | \(\mathrm{proxy}(e_2, e_2)\) | \(\mathrm{proxy}(e_2, e_3)\) |
| \(e_3\) | \(\mathrm{proxy}(e_3, e_1)\) | \(\mathrm{proxy}(e_3, e_2)\) | \(\mathrm{proxy}(e_3, e_3)\) |
邻近度用于多种数据分析技术,包括聚类、降维或最近邻分析。因此,它是模型和预测解释的绝佳工具。
不幸的是,衡量两个表格示例之间的邻近度并不简单,因为不同的列可能描述不同的量。例如,尝试定义以下示例之间的邻近度。
| 物种 | 重量 | 腿数 | 年龄 | 性别 |
|---|---|---|---|---|
| 猫 | 2 公斤 | 4 | 2 年 | 雄性 |
| 狗 | 6 公斤 | 4 | 12 年 | 雌性 |
| 蜘蛛 | 5 克 | 8 | 3 周 | 雌性 |
要定义上表中两行之间的相似度,您需要指定重量差异与腿数差异或年龄差异相比如何。此外,关系可能是非线性的,或者取决于其他列。例如,狗的寿命比蜘蛛长,因此,蜘蛛的一年年龄差异可能不应该与狗的一年年龄差异相同。
Breiman 的邻近度方法不是手动定义这些关系,而是将随机森林模型(我们知道如何将其训练在表格数据集上)转换为邻近度度量。
随机森林的邻近度
随机森林是决策树的集合。随机森林的预测是单个树预测的聚合。决策树的预测是通过根据节点条件将示例从根路由到森林中的叶子来计算的。示例 \(i\) 在树 \(t\) 中到达的叶子称为其活动叶子,并记为 \(\mathrm{leaf}(i,t)\)
Breiman 将两个示例之间的邻近度定义为这两个示例之间共享的活动叶子的比率。形式上,示例 \(i\) 和示例 \(j\) 之间的邻近度为
\[ \mathrm{prox}(i,j) = \mathrm{prox}(j,i) = \frac{1}{|\mathrm{Trees}|} \sum_{t \in \mathrm{Trees} } \left[ \mathrm{leaf}(i,t) = \mathrm{leaf}(j,t) \right] \]
其中 \(\mathrm{leaf}(j,t)\) 是示例 \(j\) 在树 \(t\) 中的活动叶子的索引。
非正式地说,如果两个示例经常被路由到相同的叶子(即两个示例具有相同的活动叶子),那么这两个示例是相似的。
让我们实现这个邻近度函数,并在一些示例中使用它。
设置
# Install TensorFlow Dececision Forests and the dependencies used in this colab.pip install tensorflow_decision_forests plotly scikit-learn wurlitzer -U -qq
import tensorflow_decision_forests as tfdf
import matplotlib.colors as mcolors
import math
import os
import numpy as np
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from plotly.offline import iplot
import plotly.graph_objs as go
训练随机森林模型
该方法依赖于预训练的随机森林模型。首先,我们使用 TensorFlow 决策森林库 在 Adult 二元分类数据集上训练一个随机森林模型。Adult 数据集非常适合此示例,因为它包含没有自然比较方式的列。
# Download a copy of the adult dataset.wget -q https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset/adult_train.csv -O /tmp/adult_train.csvwget -q https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset/adult_test.csv -O /tmp/adult_test.csv
# Load the dataset in memory
train_df = pd.read_csv("/tmp/adult_train.csv")
test_df = pd.read_csv("/tmp/adult_test.csv")
# , and convert it into a TensorFlow dataset.
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="income")
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="income")
以下是训练数据集的前五个示例。请注意,不同的列代表不同的数量。例如,您将如何比较关系和年龄之间的距离?
# Print the first 5 examples.
train_df.head()
随机森林的训练方式如下
# Train a Random Forest
model = tfdf.keras.RandomForestModel(num_trees=1000)
model.fit(train_ds)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmpznja9qk8 as temporary training directory Reading training dataset... Training dataset read in 0:00:03.886835. Found 22792 examples. Training model... [INFO 24-04-20 11:30:19.2658 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpznja9qk8/model/ with prefix a872f3db44424bcd [INFO 24-04-20 11:30:23.3606 UTC decision_forest.cc:734] Model loaded with 1000 root(s), 1262362 node(s), and 14 input feature(s). [INFO 24-04-20 11:30:23.3607 UTC abstract_model.cc:1344] Engine "RandomForestGeneric" built [INFO 24-04-20 11:30:23.3607 UTC kernel.cc:1061] Use fast generic engine Model trained in 0:00:09.781512 Compiling model... Model compiled. <tf_keras.src.callbacks.History at 0x7f421086a9d0>
随机森林模型的性能为
model_inspector = model.make_inspector()
out_of_bag_accuracy = model_inspector.evaluation().accuracy
print(f"Out-of-bag accuracy: {out_of_bag_accuracy:.4f}")
Out-of-bag accuracy: 0.8653
这是随机森林模型在此数据集上的预期准确率值。这表明模型已正确训练。
我们还可以衡量模型在测试数据集上的准确率
# The test accuracy is measured on the test datasets.
model.compile(["accuracy"])
test_accuracy = model.evaluate(test_ds, return_dict=True, verbose=0)["accuracy"]
print(f"Test accuracy: {test_accuracy:.4f}")
Test accuracy: 0.8663
邻近度
首先,我们检查模型中的树木数量和测试数据集中的示例数量。
print("The model contains", model_inspector.num_trees(), "trees.")
print("The test dataset contains", test_df.shape[0], "examples.")
The model contains 1000 trees. The test dataset contains 9769 examples.
方法 predict_get_leaves() 返回每个示例和每棵树的活动叶子的索引。
leaves = model.predict_get_leaves(test_ds)
print("The leaf indices:\n", leaves)
[INFO 24-04-20 11:30:34.6052 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpznja9qk8/model/ with prefix a872f3db44424bcd [INFO 24-04-20 11:30:37.8796 UTC kernel.cc:1079] Use slow generic engine WARNING:tensorflow:AutoGraph could not transform <function simple_ml_inference_leaf_index_op_with_handle at 0x7f40ecacf550> and will run it as-is. Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: could not get source code To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert WARNING:tensorflow:AutoGraph could not transform <function simple_ml_inference_leaf_index_op_with_handle at 0x7f40ecacf550> and will run it as-is. Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: could not get source code To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert WARNING: AutoGraph could not transform <function simple_ml_inference_leaf_index_op_with_handle at 0x7f40ecacf550> and will run it as-is. Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: could not get source code To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert The leaf indices: [[498 193 142 ... 457 221 198] [399 466 423 ... 288 420 444] [639 651 562 ... 608 636 625] ... [149 296 258 ... 153 310 316] [481 186 131 ... 432 192 153] [ 9 0 28 ... 4 1 42]] 2024-04-20 11:30:49.070709: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
print("The predicted leaves have shape", leaves.shape,
"(we expect [num_examples, num_trees]")
The predicted leaves have shape (9769, 1000) (we expect [num_examples, num_trees]
这里,leaves[i,j] 是第 i 个示例在第 j 棵树中的活动叶子的索引。
接下来,我们实现前面定义的 \(\mathrm{prox}\) 方程。
def compute_proximity(leaves, step_size=100):
"""Computes the proximity between each pair of examples.
Args:
leaves: A matrix of shape [num_example, num_tree] where the value [i,j] is
the index of the leaf reached by example "i" in the tree "j".
step_size: Size of the block of examples for the computation of the
proximity. Does not impact the results.
Returns:
The example pair-wise proximity matrix of shape [n,n] with "n" the number of
examples.
"""
example_idx = 0
num_examples = leaves.shape[0]
t_leaves = np.transpose(leaves)
proximities = []
# Instead of computing the proximity in between all the examples at the same
# time, we compute the similarity in blocks of "step_size" examples. This
# makes the code more efficient with the the numpy broadcast.
while example_idx < num_examples:
end_idx = min(example_idx + step_size, num_examples)
proximities.append(
np.mean(
leaves[..., np.newaxis] == t_leaves[:,
example_idx:end_idx][np.newaxis,
...],
axis=1))
example_idx = end_idx
return np.concatenate(proximities, axis=1)
proximity = compute_proximity(leaves)
print("The shape of proximity is", proximity.shape)
The shape of proximity is (9769, 9769)
这里,proximity[i,j] 是示例 i 和 j 之间的邻近度。
邻近度矩阵
proximity
array([[1. , 0. , 0. , ..., 0. , 0.053, 0. ],
[0. , 1. , 0. , ..., 0.002, 0. , 0. ],
[0. , 0. , 1. , ..., 0. , 0. , 0. ],
...,
[0. , 0.002, 0. , ..., 1. , 0. , 0. ],
[0.053, 0. , 0. , ..., 0. , 1. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 1. ]])
邻近度矩阵具有几个有趣的属性,特别是它是对称的、正的,并且对角元素都为 1。
投影
我们对邻近度的第一个用途是在二维平面上投影示例。
如果 \(\mathrm{prox} \in [0,1]\) 是邻近度,则 \(1 - \mathrm{prox}\) 是示例之间的距离。Breiman 建议计算这些距离的内积,并绘制 特征值。查看详细信息 此处。
相反,我们将使用 t-SNE,这是一种更现代的可视化高维数据的方案。
distance = 1 - proximity
t_sne = TSNE(
# Number of dimensions to display. 3d is also possible.
n_components=2,
# Control the shape of the projection. Higher values create more
# distinct but also more collapsed clusters. Can be in 5-50.
perplexity=20,
metric="precomputed",
init="random",
verbose=1,
learning_rate="auto").fit_transform(distance)
[t-SNE] Computing 61 nearest neighbors... [t-SNE] Indexed 9769 samples in 0.186s... [t-SNE] Computed neighbors for 9769 samples in 1.295s... [t-SNE] Computed conditional probabilities for sample 1000 / 9769 [t-SNE] Computed conditional probabilities for sample 2000 / 9769 [t-SNE] Computed conditional probabilities for sample 3000 / 9769 [t-SNE] Computed conditional probabilities for sample 4000 / 9769 [t-SNE] Computed conditional probabilities for sample 5000 / 9769 [t-SNE] Computed conditional probabilities for sample 6000 / 9769 [t-SNE] Computed conditional probabilities for sample 7000 / 9769 [t-SNE] Computed conditional probabilities for sample 8000 / 9769 [t-SNE] Computed conditional probabilities for sample 9000 / 9769 [t-SNE] Computed conditional probabilities for sample 9769 / 9769 [t-SNE] Mean sigma: 0.188051 [t-SNE] KL divergence after 250 iterations with early exaggeration: 76.133606 [t-SNE] KL divergence after 1000 iterations: 1.109254
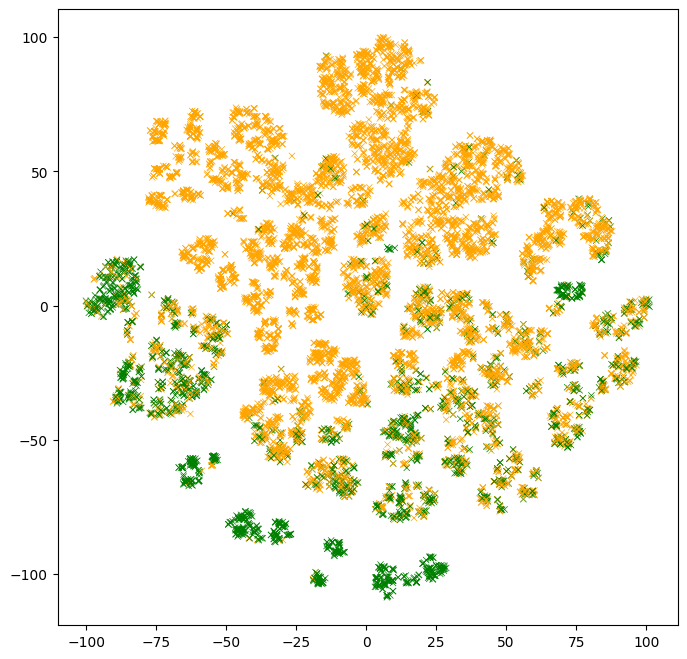
下一个图显示了测试示例特征的二维投影。点的颜色代表标签值。请注意,模型无法获得标签值。
fig, ax = plt.subplots(1, 1, figsize=(8, 8))
ax.grid(False)
# Color the points according to the label value.
colors = (test_df["income"] == ">50K").map(lambda x: ["orange", "green"][x])
ax.scatter(
t_sne[:, 0], t_sne[:, 1], c=colors, linewidths=0.5, marker="x", s=20)
<matplotlib.collections.PathCollection at 0x7f411be242e0>
观察结果
- 存在具有相似颜色的点簇。这些是模型易于分类的示例。
- 存在多个具有相同颜色的簇。这些多个簇显示了具有相同标签但根据模型“原因不同”的示例。
- 混合颜色的簇包含模型表现不佳的示例。在上面的部分中,我们评估了模型测试准确率约为 86%。这些可能是那些示例。
前面的图是静态图像。让我们将其转换为交互式图并检查各个示例。
# docs_infra: no_execute
# Note: Run the colab (click the "Run in Google Colab" link at the top) to see
# the interactive plot.
def interactive_plot(dataset, projections):
def label_fn(row):
"""HTML printer over each example."""
return "<br>".join([f"<b>{k}:</b> {v}" for k, v in row.items()])
labels = list(dataset.apply(label_fn, axis=1).values)
iplot({
"data": [
go.Scatter(
x=projections[:, 0],
y=projections[:, 1],
text=labels,
mode="markers",
marker={
"color": colors,
"size": 3,
})
],
"layout": go.Layout(width=600, height=600, template="simple_white")
})
interactive_plot(test_df, t_sne)
说明:将鼠标指针放在一些示例上,并尝试理解它们。将它们与它们的邻居进行比较。
未看到交互式图?使用 此链接 运行 colab 以查看交互式图。
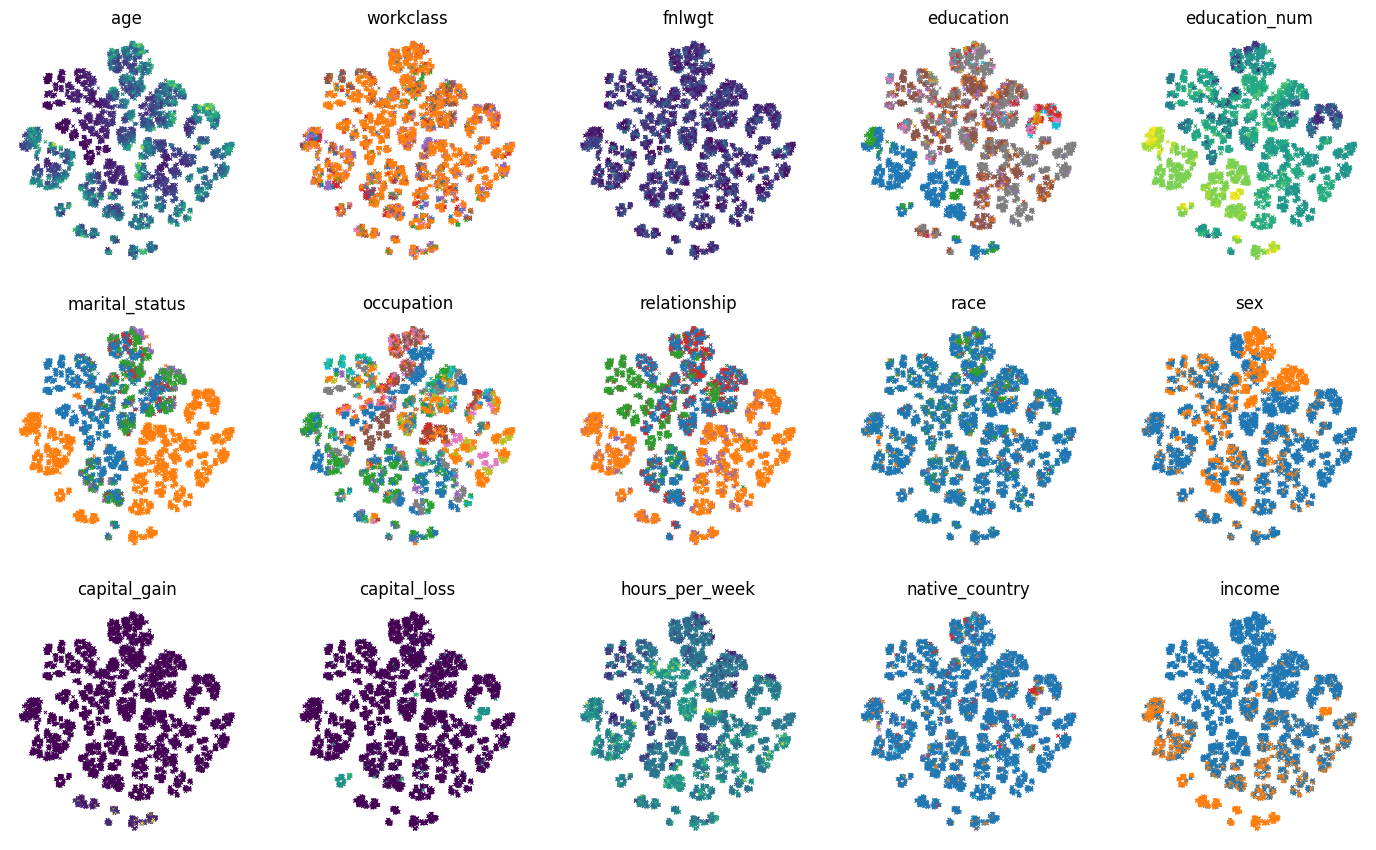
我们可以根据每个特征值对示例进行着色,而不是根据标签值对示例进行着色
# Number of columns and rows in the multi-plot.
num_plot_cols = 5
num_plot_rows = math.ceil(test_df.shape[1] / num_plot_cols)
# Color palette for the categorical features.
palette = list(mcolors.TABLEAU_COLORS.values())
# Create the plot
plot_size_in = 3.5
fig, axs = plt.subplots(
num_plot_rows,
num_plot_cols,
figsize=(num_plot_cols * plot_size_in, num_plot_rows * plot_size_in))
# Hide the borders.
for row in axs:
for ax in row:
ax.set_axis_off()
for col_idx, col_name in enumerate(test_df):
ax = axs[col_idx // num_plot_cols, col_idx % num_plot_cols]
colors = test_df[col_name]
if colors.dtypes in [str, object]:
# Use the color palette on categorical features.
unique_values = list(colors.unique())
colors = colors.map(
lambda x: palette[unique_values.index(x) % len(palette)])
ax.set_title(col_name)
ax.scatter(t_sne[:, 0], t_sne[:, 1], c=colors.values, linewidths=0.5,
marker="x", s=5)
原型
通过查看所有邻居来尝试理解一个示例并不总是有效。相反,我们可以将相似的示例“分组”以使此任务更容易。这是原型背后的基本思想。
原型是示例,不一定在原始数据集中,它们代表数据集中的大趋势。查看原型是理解数据集的解决方案。有关更多详细信息,请参阅 第 8.7 章 的 可解释机器学习(作者:Molnar)。
原型可以通过不同的方式计算,例如使用聚类算法。相反,Breiman 提出了一个基于简单迭代算法的特定解决方案。该算法如下
- 选择被其 k 个最近邻居中具有相同类别的邻居数量最多的示例包围的示例。
- 使用所选示例及其 k 个邻居的特征值的中间值创建一个原型示例。
- 删除这 k+1 个示例
- 重复
非正式地说,原型是我们上面创建的图中的簇的中心。
让我们实现此算法并查看一些原型。
首先是选择步骤 1 中示例的方法。
def select_example(labels, distance_matrix, k):
"""Selects the example with the highest number of neighbors with the same class.
Usage example:
n = 5
select_example(
np.random.randint(0,2, size=n),
np.random.uniform(size=(n,n)),
2)
Returns:
The list of neighbors for the selected example. Includes the selected
example.
"""
partition = np.argpartition(distance_matrix, k)[:,:k]
same_label = np.mean(np.equal(labels[partition], np.expand_dims(labels, axis=1)), axis=1)
selected_example = np.argmax(same_label)
return partition[selected_example, :]
def extract_prototype_examples(labels, distance_matrix, k, num_prototypes):
"""Extracts a list of examples in each prototype.
Usage example:
n = 50
print(extract_prototype_examples(
labels=np.random.randint(0, 2, size=n),
distance_matrix=np.random.uniform(size=(n, n)),
k=2,
num_prototypes=3))
Returns:
An array where E[i][j] is the index of the j-th examples of the i-th
prototype.
"""
example_idxs = np.arange(len(labels))
prototypes = []
examples_per_prototype = []
for iter in range(num_prototypes):
print(f"Iter #{iter}")
# Select the example
neighbors = select_example(labels, distance_matrix, k)
# Index of the examples in the prototype
examples_per_prototype.append(list(example_idxs[neighbors]))
# Remove the selected examples
example_idxs = np.delete(example_idxs, neighbors)
labels = np.delete(labels, neighbors)
distance_matrix = np.delete(distance_matrix, neighbors, axis=0)
distance_matrix = np.delete(distance_matrix, neighbors, axis=1)
return examples_per_prototype
使用以上方法,让我们提取 10 个原型的示例。
examples_per_prototype = extract_prototype_examples(test_df["income"].values, distance, k=20, num_prototypes=10)
print(f"Found examples for {len(examples_per_prototype)} prototypes.")
Iter #0 Iter #1 Iter #2 Iter #3 Iter #4 Iter #5 Iter #6 Iter #7 Iter #8 Iter #9 Found examples for 10 prototypes.
对于这些原型中的每一个,我们想要显示特征值的统计信息。在本例中,我们将查看数值特征的四分位数,以及分类特征的最频繁值。
def build_prototype(dataset):
"""Exacts the feature statistics of a prototype.
For numerical features, returns the quantiles.
For categorical features, returns the most frequent value.
Usage example:
n = 50
print(build_prototype(
pd.DataFrame({
"f1": np.random.uniform(size=n),
"f2": np.random.uniform(size=n),
"f3": [f"v_{x}" for x in np.random.randint(0, 2, size=n)],
"label": np.random.randint(0, 2, size=n)
})))
Return:
A prototype as a dictionary of strings.
"""
prototype = {}
for col in dataset.columns:
col_values = dataset[col]
if col_values.dtypes in [str, object]:
# A categorical feature.
# Remove the missing values
col_values = [x for x in col_values if isinstance(x,str) or not math.isnan(x)]
# Frequency of each possible value.
frequency_item, frequency_count = np.unique(col_values, return_counts=True)
top_item_idx = np.argmax(frequency_count)
top_item_probability = frequency_count[top_item_idx] / np.sum(frequency_count)
# Print the most common item.
prototype[col] = f"{frequency_item[top_item_idx]} ({100*top_item_probability:.0f}%)"
else:
# A numerical feature.
quartiles = np.nanquantile(col_values.values, [0.25, 0.5, 0.75])
# Print the 3 quantiles.
prototype[col] = f"{quartiles[0]} {quartiles[1]} {quartiles[2]}"
return prototype
现在,让我们看看我们的原型。
# Extract the statistics of each prototype.
prototypes = []
for examples in examples_per_prototype:
# Prorotype statistics.
prototypes.append(build_prototype(test_df.iloc[examples, :]))
prototypes = pd.DataFrame(prototypes)
prototypes
尝试理解原型。
让我们提取并绘制这些原型中元素的平均 2d t-SNE 投影。
# Extract the projection of each prototype.
prototypes_projection = []
for examples in examples_per_prototype:
# t-SNE for each prototype.
prototypes_projection.append(np.mean(t_sne[examples,:],axis=0))
prototypes_projection = np.stack(prototypes_projection)
# Plot the mean 2d t-SNE projection of the elements in the prototypes.
fig, ax = plt.subplots(1, 1, figsize=(8, 8))
ax.grid(False)
# Color the points according to the label value.
colors = (test_df["income"] == ">50K").map(lambda x: ["orange", "green"][x])
ax.scatter(
t_sne[:, 0], t_sne[:, 1], c=colors, linewidths=0.5, marker="x", s=20)
# Add the prototype indices.
for i in range(prototypes_projection.shape[0]):
ax.text(prototypes_projection[i, 0],
prototypes_projection[i, 1],
f"{i}",
fontdict={"size":18},
c="red")
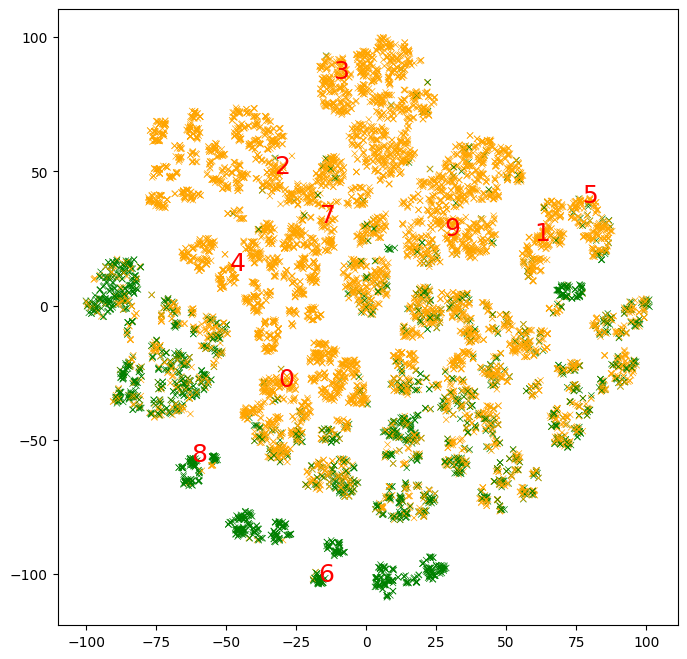
我们看到 10 个原型覆盖了大约一半的域。没有原型的示例簇最好用更多原型来解释。
在上面的示例中,我们自动提取了原型。但是,我们也可以围绕特定示例构建原型。
让我们围绕示例 #0 创建原型。
example_idx = 0
k = 20
neighbors = np.argpartition(distance[example_idx, :], k)[:k]
print(f"The example #{example_idx} is:")
print("===============================")
print(test_df.iloc[example_idx, :])
print("")
print(f"The prototype around the example #{example_idx} is:")
print("============================================")
print(pd.Series(build_prototype(test_df.iloc[neighbors, :])))
The example #0 is: =============================== age 39 workclass State-gov fnlwgt 77516 education Bachelors education_num 13 marital_status Never-married occupation Adm-clerical relationship Not-in-family race White sex Male capital_gain 2174 capital_loss 0 hours_per_week 40 native_country United-States income <=50K Name: 0, dtype: object The prototype around the example #0 is: ============================================ age 36.0 39.0 41.0 workclass Private (50%) fnlwgt 72314.0 115188.5 138797.0 education Bachelors (95%) education_num 13.0 13.0 13.0 marital_status Never-married (65%) occupation Adm-clerical (70%) relationship Not-in-family (75%) race White (95%) sex Male (65%) capital_gain 0.0 0.0 0.0 capital_loss 0.0 0.0 0.0 hours_per_week 38.75 40.0 40.0 native_country United-States (100%) income <=50K (100%) dtype: object