
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
在本教程中,您将学习如何通过使用来自预训练网络的迁移学习来对猫和狗的图像进行分类。
预训练模型是保存的网络,之前已在大型数据集上进行过训练,通常是在大型图像分类任务上。您可以直接使用预训练模型,也可以使用迁移学习来根据特定任务对其进行自定义。
图像分类中迁移学习的直觉是,如果一个模型在足够大且通用的数据集上进行训练,那么这个模型将有效地充当视觉世界的通用模型。然后,您可以利用这些学习到的特征图,而无需从头开始训练大型模型,从而在大型数据集上进行训练。
在本笔记本中,您将尝试两种自定义预训练模型的方法
特征提取:使用先前网络学习到的表示从新样本中提取有意义的特征。您只需在预训练模型之上添加一个新的分类器,该分类器将从头开始训练,以便您可以将之前为数据集学习到的特征图重新用于其他目的。
您不需要(重新)训练整个模型。基本卷积网络已经包含对分类图片普遍有用的特征。但是,预训练模型的最终分类部分是特定于原始分类任务的,因此特定于模型训练所基于的类别集。
微调:解冻冻结模型基础的几个顶层,并联合训练新添加的分类层和基础模型的最后一层。这使我们能够“微调”基础模型中更高阶的特征表示,以使其更适合特定任务。
您将遵循一般的机器学习工作流程。
- 检查并了解数据
- 构建输入管道,在本例中使用 Keras ImageDataGenerator
- 组合模型
- 加载预训练的基础模型(和预训练权重)
- 在顶部堆叠分类层
- 训练模型
- 评估模型
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
数据预处理
数据下载
在本教程中,您将使用一个包含数千张猫和狗图像的数据集。下载并解压缩包含图像的 zip 文件,然后使用 tf.data.Dataset 为训练和验证创建一个 tf.keras.utils.image_dataset_from_directory 实用程序。您可以在此 教程 中了解更多关于加载图像的信息。
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68606236/68606236 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
显示训练集中前九张图像和标签
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
2024-06-27 01:22:05.112570: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

由于原始数据集不包含测试集,您将创建一个测试集。为此,请使用 tf.data.experimental.cardinality 确定验证集中有多少批数据可用,然后将其中 20% 移动到测试集中。
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
配置数据集以提高性能
使用缓冲预取从磁盘加载图像,而不会让 I/O 成为阻塞。要了解有关此方法的更多信息,请参阅 数据性能 指南。
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
使用数据增强
当您没有大型图像数据集时,最好通过对训练图像应用随机但现实的变换(例如旋转和水平翻转)来人为地引入样本多样性。这有助于将模型暴露于训练数据的不同方面,并减少 过度拟合。您可以在此 教程 中了解更多关于数据增强的信息。
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
让我们对同一图像重复应用这些层,并查看结果。
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')
2024-06-27 01:22:06.987241: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence

重新缩放像素值
过一会儿,您将下载 tf.keras.applications.MobileNetV2 用作您的基础模型。此模型期望像素值在 [-1, 1] 中,但在此时,图像中的像素值在 [0, 255] 中。要重新缩放它们,请使用模型中包含的预处理方法。
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
从预训练的卷积网络创建基础模型
您将从 Google 开发的 MobileNet V2 模型创建基础模型。它是在 ImageNet 数据集上预训练的,ImageNet 数据集是一个大型数据集,包含 140 万张图像和 1000 个类别。ImageNet 是一个研究训练数据集,包含各种各样的类别,例如 jackfruit 和 syringe。这些知识基础将帮助我们从特定数据集对猫和狗进行分类。
首先,您需要选择 MobileNet V2 的哪个层将用于特征提取。最后一个分类层(在“顶部”,因为大多数机器学习模型图从底部到顶部)不是很有用。相反,您将遵循常见的做法,依赖于扁平化操作之前的最后一层。此层称为“瓶颈层”。与最终/顶层相比,瓶颈层特征保留了更多通用性。
首先,实例化一个 MobileNet V2 模型,该模型预先加载了在 ImageNet 上训练的权重。通过指定 include_top=False 参数,您将加载一个不包含顶部分类层的网络,这非常适合特征提取。
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9406464/9406464 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
此特征提取器将每个 160x160x3 图像转换为 5x5x1280 特征块。让我们看看它对一批示例图像做了什么
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
特征提取
在此步骤中,您将冻结从上一步创建的卷积基础,并将其用作特征提取器。此外,您将在其顶部添加一个分类器,并训练顶层分类器。
冻结卷积基础
在编译和训练模型之前,冻结卷积基础非常重要。冻结(通过设置 layer.trainable = False)会阻止给定层中的权重在训练期间更新。MobileNet V2 有很多层,因此将整个模型的 trainable 标志设置为 False 将冻结所有层。
base_model.trainable = False
关于 BatchNormalization 层的重要说明
许多模型包含 tf.keras.layers.BatchNormalization 层。此层是一个特殊情况,在微调的上下文中应采取预防措施,如本教程后面的内容所示。
当您设置 layer.trainable = False 时,BatchNormalization 层将以推理模式运行,并且不会更新其均值和方差统计信息。
当您解冻包含 BatchNormalization 层的模型以进行微调时,您应该通过在调用基础模型时传递 training = False 来使 BatchNormalization 层保持推理模式。否则,应用于不可训练权重的更新将破坏模型所学到的内容。
有关更多详细信息,请参阅 迁移学习指南。
# Let's take a look at the base model architecture
base_model.summary()
添加分类头
要从特征块生成预测,请使用 tf.keras.layers.GlobalAveragePooling2D 层对空间 5x5 空间位置进行平均,以将特征转换为每个图像的单个 1280 元素向量。
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
应用 tf.keras.layers.Dense 层将这些特征转换为每个图像的单个预测。您不需要在此处使用激活函数,因为此预测将被视为 logit 或原始预测值。正数预测类别 1,负数预测类别 0。
prediction_layer = tf.keras.layers.Dense(1, activation='sigmoid')
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
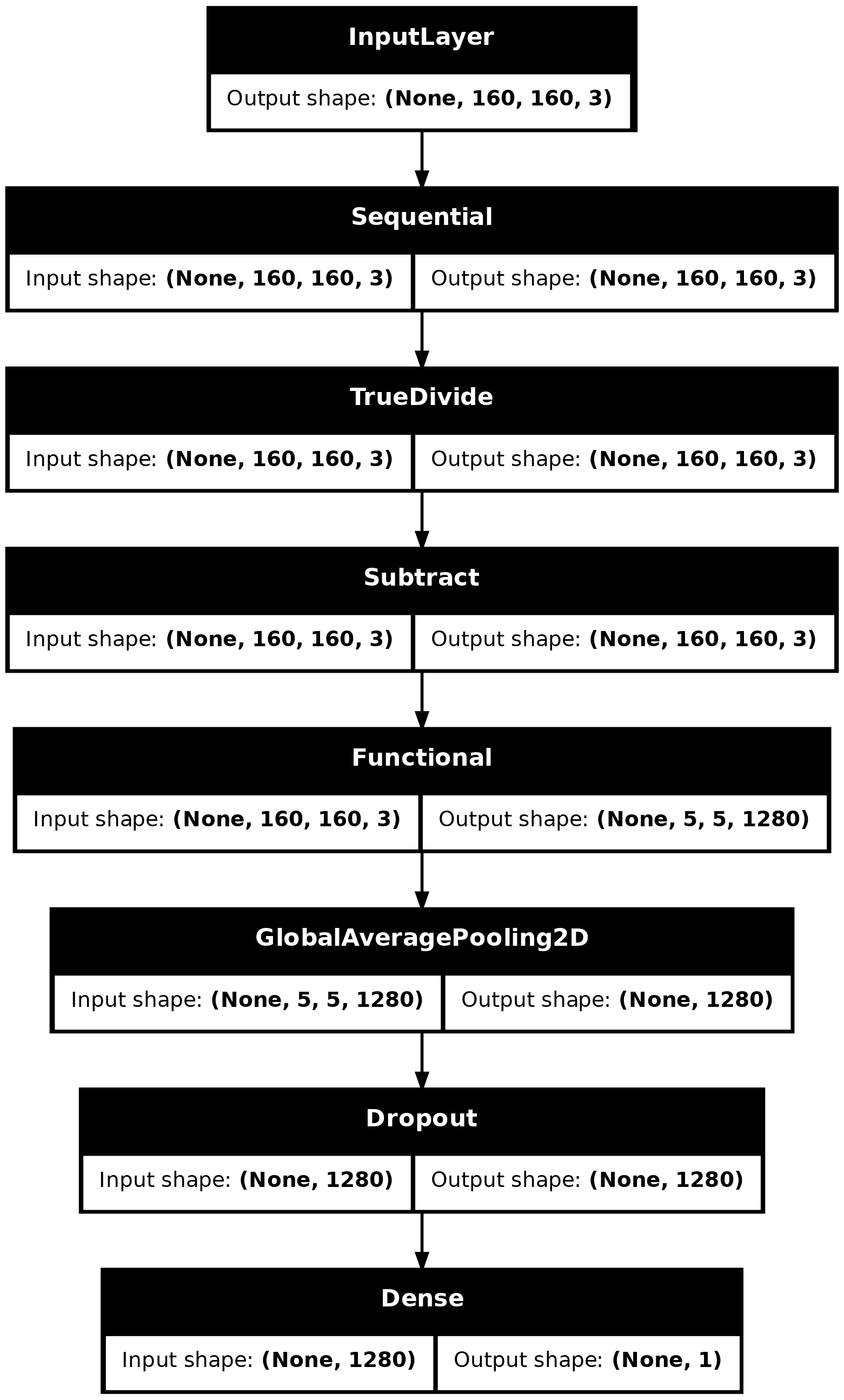
使用 Keras 函数式 API 将数据增强、重新缩放、base_model 和特征提取器层链接在一起,构建一个模型。如前所述,使用 training=False,因为我们的模型包含 BatchNormalization 层。
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
MobileNet 中的 800 多万个参数被冻结,但 Dense 层中有 1.2 千个可训练参数。这些参数分为两个 tf.Variable 对象,即权重和偏差。
len(model.trainable_variables)
2
tf.keras.utils.plot_model(model, show_shapes=True)
编译模型
在训练模型之前编译它。由于有两个类别和 sigmoid 输出,因此使用 BinaryAccuracy。
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])
训练模型
在训练 10 个 epoch 后,您应该在验证集上看到约 96% 的准确率。
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 ━━━━━━━━━━━━━━━━━━━━ 3s 50ms/step - accuracy: 0.5516 - loss: 0.7358
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.72 initial accuracy: 0.57
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 51ms/step - accuracy: 0.6088 - loss: 0.6782 - val_accuracy: 0.7908 - val_loss: 0.4953 Epoch 2/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.7647 - loss: 0.5053 - val_accuracy: 0.8812 - val_loss: 0.3665 Epoch 3/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8187 - loss: 0.4228 - val_accuracy: 0.9109 - val_loss: 0.2960 Epoch 4/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8556 - loss: 0.3566 - val_accuracy: 0.9344 - val_loss: 0.2435 Epoch 5/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8878 - loss: 0.3080 - val_accuracy: 0.9455 - val_loss: 0.2101 Epoch 6/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8879 - loss: 0.2790 - val_accuracy: 0.9480 - val_loss: 0.1879 Epoch 7/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.8970 - loss: 0.2621 - val_accuracy: 0.9554 - val_loss: 0.1616 Epoch 8/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.9082 - loss: 0.2352 - val_accuracy: 0.9641 - val_loss: 0.1485 Epoch 9/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.9162 - loss: 0.2239 - val_accuracy: 0.9678 - val_loss: 0.1360 Epoch 10/10 63/63 ━━━━━━━━━━━━━━━━━━━━ 3s 41ms/step - accuracy: 0.9204 - loss: 0.2183 - val_accuracy: 0.9728 - val_loss: 0.1245
学习曲线
让我们看一下使用 MobileNetV2 基础模型作为固定特征提取器时的训练和验证准确率/损失的学习曲线。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
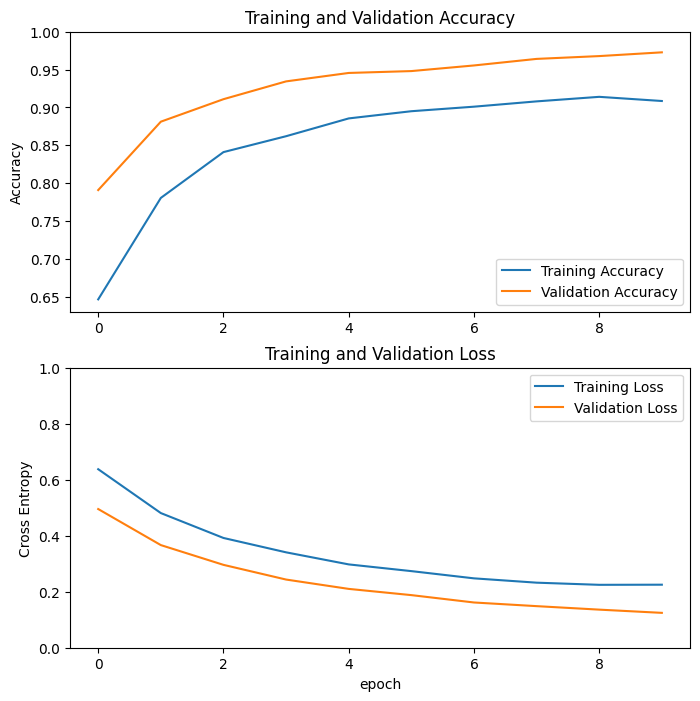
在较小程度上,这也是因为训练指标报告了 epoch 的平均值,而验证指标是在 epoch 之后评估的,因此验证指标看到了训练时间稍长的模型。
微调
在特征提取实验中,您只在 MobileNetV2 基础模型之上训练了几个层。预训练网络的权重在训练期间没有更新。
进一步提高性能的一种方法是训练(或“微调”)预训练模型顶层的权重,同时训练您添加的分类器。训练过程将迫使权重从通用特征图调整为与数据集相关的特征。
此外,您应该尝试微调少量顶层,而不是整个 MobileNet 模型。在大多数卷积网络中,层级越高,其专业性就越强。前几层学习非常简单和通用的特征,这些特征几乎可以推广到所有类型的图像。随着您层级上升,特征越来越特定于模型训练所用的数据集。微调的目标是使这些专门的特征适应新数据集,而不是覆盖通用学习。
解冻模型的顶层
您需要做的就是解冻 base_model 并将底层设置为不可训练。然后,您应该重新编译模型(对于这些更改生效是必要的),并恢复训练。
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
编译模型
由于您正在训练一个更大的模型,并且想要重新适应预训练权重,因此在此阶段使用较低的学习率非常重要。否则,您的模型可能会很快过拟合。
model.compile(loss=tf.keras.losses.BinaryCrossentropy(),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5, name='accuracy')])
model.summary()
len(model.trainable_variables)
56
继续训练模型
如果您之前训练到收敛,此步骤将使您的准确率提高几个百分点。
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=len(history.epoch),
validation_data=validation_dataset)
Epoch 11/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 14s 82ms/step - accuracy: 0.7710 - loss: 0.4544 - val_accuracy: 0.9740 - val_loss: 0.0892 Epoch 12/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.8829 - loss: 0.2787 - val_accuracy: 0.9752 - val_loss: 0.0771 Epoch 13/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9097 - loss: 0.2267 - val_accuracy: 0.9802 - val_loss: 0.0603 Epoch 14/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9186 - loss: 0.2091 - val_accuracy: 0.9827 - val_loss: 0.0577 Epoch 15/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9118 - loss: 0.1978 - val_accuracy: 0.9814 - val_loss: 0.0553 Epoch 16/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9382 - loss: 0.1637 - val_accuracy: 0.9839 - val_loss: 0.0507 Epoch 17/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9325 - loss: 0.1515 - val_accuracy: 0.9827 - val_loss: 0.0502 Epoch 18/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9448 - loss: 0.1339 - val_accuracy: 0.9827 - val_loss: 0.0511 Epoch 19/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9534 - loss: 0.1213 - val_accuracy: 0.9827 - val_loss: 0.0470 Epoch 20/20 63/63 ━━━━━━━━━━━━━━━━━━━━ 4s 60ms/step - accuracy: 0.9465 - loss: 0.1408 - val_accuracy: 0.9827 - val_loss: 0.0466
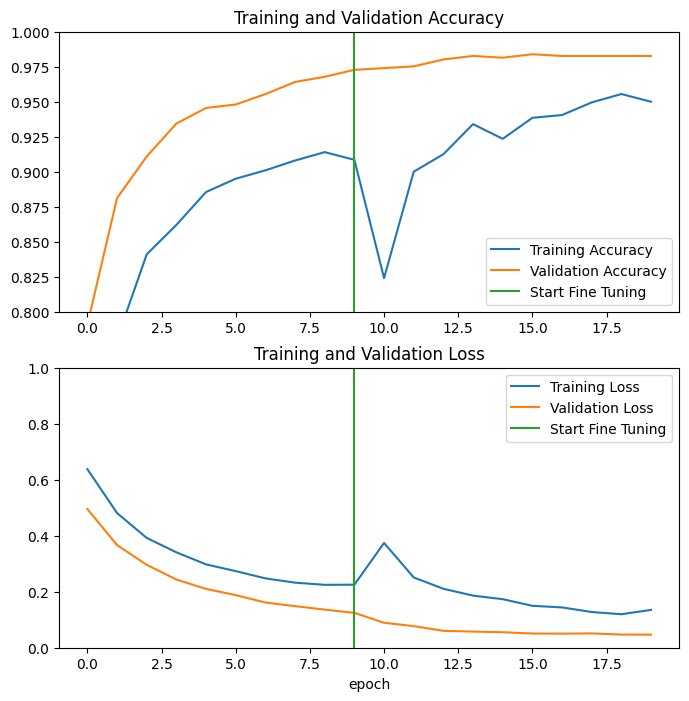
让我们看一下微调 MobileNetV2 基础模型的最后几层并在其之上训练分类器时的训练和验证准确率/损失的学习曲线。验证损失远高于训练损失,因此您可能会得到一些过拟合。
由于新的训练集相对较小并且类似于原始 MobileNetV2 数据集,您也可能会得到一些过拟合。
微调后,模型在验证集上的准确率接近 98%。
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
评估和预测
最后,您可以使用测试集验证模型在新数据上的性能。
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step - accuracy: 0.9893 - loss: 0.0340 Test accuracy : 0.9895833134651184
现在,您已准备好使用此模型来预测您的宠物是猫还是狗。
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [1 1 1 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 1 1 0 1 1 0 0 1 0 0 0 0] Labels: [1 1 1 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 1 1 0 1 1 0 0 1 0 0 0 0]

总结
使用预训练模型进行特征提取:在处理小型数据集时,通常的做法是利用在同一领域中训练的模型学习的特征。这是通过实例化预训练模型并在其之上添加一个全连接分类器来完成的。预训练模型被“冻结”,只有分类器的权重在训练期间得到更新。在这种情况下,卷积基提取了与每个图像相关联的所有特征,您只需训练一个分类器,根据提取的特征集确定图像类别。
微调预训练模型:为了进一步提高性能,您可能希望通过微调将预训练模型的顶层重新用于新数据集。在这种情况下,您调整了权重,以便您的模型学习特定于数据集的高级特征。当训练数据集很大并且与预训练模型训练所用的原始数据集非常相似时,通常建议使用此技术。
要了解更多信息,请访问 迁移学习指南。
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.