
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概述
此笔记本展示了如何使用神经网络和 TensorFlow Compression 进行有损数据压缩。
有损压缩涉及在**速率**(编码样本所需的预期比特数)和**失真**(样本重建中的预期误差)之间进行权衡。
以下示例使用类似自动编码器的模型来压缩来自 MNIST 数据集的图像。该方法基于论文 端到端优化图像压缩。
有关学习数据压缩的更多背景信息,请参阅针对熟悉经典数据压缩的人员的 这篇论文,或针对机器学习受众的 这篇综述。
设置
通过 pip 安装 Tensorflow Compression。
# Installs the latest version of TFC compatible with the installed TF version.read MAJOR MINOR <<< "$(pip show tensorflow | perl -p -0777 -e 's/.*Version: (\d+)\.(\d+).*/\1 \2/sg')"pip install "tensorflow-compression<$MAJOR.$(($MINOR+1))"
导入库依赖项。
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_compression as tfc
import tensorflow_datasets as tfds
2024-02-02 02:21:52.947295: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-02-02 02:21:52.947345: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-02-02 02:21:52.947388: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
定义训练器模型。
由于模型类似于自动编码器,并且我们需要在训练和推理期间执行不同的函数集,因此设置与分类器略有不同。
训练模型由三个部分组成
- **分析**(或编码器)变换,将图像转换为潜在空间,
- **合成**(或解码器)变换,将潜在空间转换回图像空间,以及
- **先验**和熵模型,对潜在变量的边缘概率进行建模。
首先,定义变换
def make_analysis_transform(latent_dims):
"""Creates the analysis (encoder) transform."""
return tf.keras.Sequential([
tf.keras.layers.Conv2D(
20, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_1"),
tf.keras.layers.Conv2D(
50, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_2"),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(
500, use_bias=True, activation="leaky_relu", name="fc_1"),
tf.keras.layers.Dense(
latent_dims, use_bias=True, activation=None, name="fc_2"),
], name="analysis_transform")
def make_synthesis_transform():
"""Creates the synthesis (decoder) transform."""
return tf.keras.Sequential([
tf.keras.layers.Dense(
500, use_bias=True, activation="leaky_relu", name="fc_1"),
tf.keras.layers.Dense(
2450, use_bias=True, activation="leaky_relu", name="fc_2"),
tf.keras.layers.Reshape((7, 7, 50)),
tf.keras.layers.Conv2DTranspose(
20, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_1"),
tf.keras.layers.Conv2DTranspose(
1, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_2"),
], name="synthesis_transform")
训练器保存了两种变换的实例,以及先验参数。
它的 call 方法设置为计算
- **速率**,表示数字批次所需的比特数的估计值,以及
- **失真**,原始数字像素与其重建之间的平均绝对差。
class MNISTCompressionTrainer(tf.keras.Model):
"""Model that trains a compressor/decompressor for MNIST."""
def __init__(self, latent_dims):
super().__init__()
self.analysis_transform = make_analysis_transform(latent_dims)
self.synthesis_transform = make_synthesis_transform()
self.prior_log_scales = tf.Variable(tf.zeros((latent_dims,)))
@property
def prior(self):
return tfc.NoisyLogistic(loc=0., scale=tf.exp(self.prior_log_scales))
def call(self, x, training):
"""Computes rate and distortion losses."""
# Ensure inputs are floats in the range (0, 1).
x = tf.cast(x, self.compute_dtype) / 255.
x = tf.reshape(x, (-1, 28, 28, 1))
# Compute latent space representation y, perturb it and model its entropy,
# then compute the reconstructed pixel-level representation x_hat.
y = self.analysis_transform(x)
entropy_model = tfc.ContinuousBatchedEntropyModel(
self.prior, coding_rank=1, compression=False)
y_tilde, rate = entropy_model(y, training=training)
x_tilde = self.synthesis_transform(y_tilde)
# Average number of bits per MNIST digit.
rate = tf.reduce_mean(rate)
# Mean absolute difference across pixels.
distortion = tf.reduce_mean(abs(x - x_tilde))
return dict(rate=rate, distortion=distortion)
计算速率和失真。
让我们一步一步地完成此步骤,使用训练集中的一个图像。加载用于训练和验证的 MNIST 数据集
training_dataset, validation_dataset = tfds.load(
"mnist",
split=["train", "test"],
shuffle_files=True,
as_supervised=True,
with_info=False,
)
2024-02-02 02:21:57.270402: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://tensorflowcn.cn/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices...
并提取一个图像 \(x\)
(x, _), = validation_dataset.take(1)
plt.imshow(tf.squeeze(x))
print(f"Data type: {x.dtype}")
print(f"Shape: {x.shape}")
2024-02-02 02:21:57.719574: W tensorflow/core/kernels/data/cache_dataset_ops.cc:854] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. Data type: <dtype: 'uint8'> Shape: (28, 28, 1)
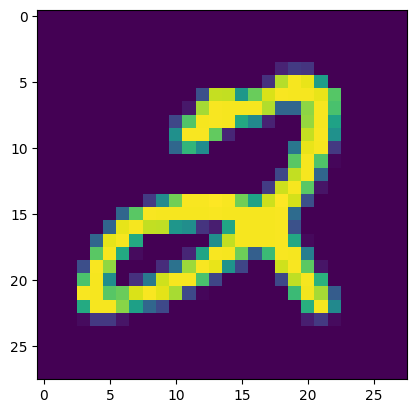
要获得潜在表示 \(y\),我们需要将其转换为 float32,添加批次维度,并将其传递给分析变换。
x = tf.cast(x, tf.float32) / 255.
x = tf.reshape(x, (-1, 28, 28, 1))
y = make_analysis_transform(10)(x)
print("y:", y)
y: tf.Tensor( [[ 0.02126924 -0.06894962 0.09302588 -0.03838679 -0.07932404 0.04434497 -0.01607926 0.03123217 -0.00262138 -0.10917155]], shape=(1, 10), dtype=float32)
潜在变量将在测试时进行量化。为了在训练期间以可微分的方式对这种情况进行建模,我们在区间 \((-.5, .5)\) 中添加均匀噪声,并将结果称为 \(\tilde y\)。这与论文 端到端优化图像压缩 中使用的术语相同。
y_tilde = y + tf.random.uniform(y.shape, -.5, .5)
print("y_tilde:", y_tilde)
y_tilde: tf.Tensor( [[ 0.3478785 0.08000787 -0.18317918 0.25482622 -0.31788376 -0.13823514 0.362665 -0.05973584 0.34111002 -0.1322978 ]], shape=(1, 10), dtype=float32)
“先验”是我们训练的概率密度,用于对噪声潜在变量的边缘分布进行建模。例如,它可以是一组独立的 逻辑分布,每个潜在维度具有不同的尺度。 tfc.NoisyLogistic 考虑了潜在变量具有加性噪声的事实。当尺度接近零时,逻辑分布接近狄拉克 delta(尖峰),但添加的噪声会导致“噪声”分布反而接近均匀分布。
prior = tfc.NoisyLogistic(loc=0., scale=tf.linspace(.01, 2., 10))
_ = tf.linspace(-6., 6., 501)[:, None]
plt.plot(_, prior.prob(_));
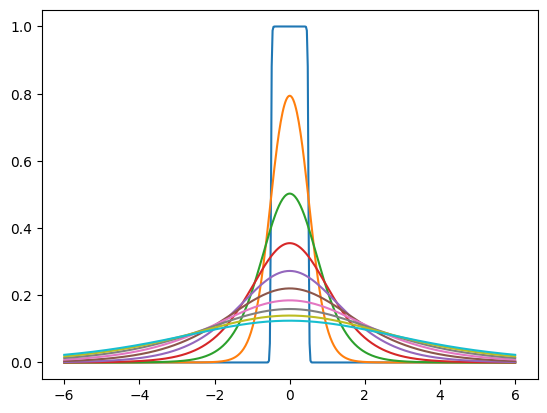
在训练期间, tfc.ContinuousBatchedEntropyModel 添加均匀噪声,并使用噪声和先验来计算速率(编码潜在表示所需的平均比特数)的可微分上限。该上限可以作为损失最小化。
entropy_model = tfc.ContinuousBatchedEntropyModel(
prior, coding_rank=1, compression=False)
y_tilde, rate = entropy_model(y, training=True)
print("rate:", rate)
print("y_tilde:", y_tilde)
rate: tf.Tensor([18.012472], shape=(1,), dtype=float32) y_tilde: tf.Tensor( [[-0.09349963 -0.02974442 -0.1147738 0.39858678 0.33601853 -0.13327162 -0.10957606 0.2511304 -0.15129623 0.25686544]], shape=(1, 10), dtype=float32)
最后,噪声潜在变量通过合成变换传递回,以生成图像重建 \(\tilde x\)。失真是在原始图像和重建之间的误差。显然,在变换未经训练的情况下,重建不是很有用。
x_tilde = make_synthesis_transform()(y_tilde)
# Mean absolute difference across pixels.
distortion = tf.reduce_mean(abs(x - x_tilde))
print("distortion:", distortion)
x_tilde = tf.saturate_cast(x_tilde[0] * 255, tf.uint8)
plt.imshow(tf.squeeze(x_tilde))
print(f"Data type: {x_tilde.dtype}")
print(f"Shape: {x_tilde.shape}")
distortion: tf.Tensor(0.17072156, shape=(), dtype=float32) Data type: <dtype: 'uint8'> Shape: (28, 28, 1)
对于每批数字,调用 MNISTCompressionTrainer 会生成速率和失真,作为该批次的平均值
(example_batch, _), = validation_dataset.batch(32).take(1)
trainer = MNISTCompressionTrainer(10)
example_output = trainer(example_batch)
print("rate: ", example_output["rate"])
print("distortion: ", example_output["distortion"])
rate: tf.Tensor(20.296253, shape=(), dtype=float32) distortion: tf.Tensor(0.14659302, shape=(), dtype=float32) 2024-02-02 02:21:58.788887: W tensorflow/core/kernels/data/cache_dataset_ops.cc:854] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
在下一节中,我们将设置模型以对这两个损失进行梯度下降。
训练模型。
我们以一种优化速率-失真拉格朗日的方式编译训练器,即速率和失真的总和,其中一项由拉格朗日参数 \(\lambda\) 加权。
此损失函数对模型的不同部分的影响不同
- 分析变换经过训练,以生成能够实现速率和失真之间所需权衡的潜在表示。
- 合成变换经过训练,以最小化给定潜在表示的失真。
- 先验参数经过训练,以最小化给定潜在表示的速率。这与以最大似然意义拟合潜在变量的边缘分布相同。
def pass_through_loss(_, x):
# Since rate and distortion are unsupervised, the loss doesn't need a target.
return x
def make_mnist_compression_trainer(lmbda, latent_dims=50):
trainer = MNISTCompressionTrainer(latent_dims)
trainer.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
# Just pass through rate and distortion as losses/metrics.
loss=dict(rate=pass_through_loss, distortion=pass_through_loss),
metrics=dict(rate=pass_through_loss, distortion=pass_through_loss),
loss_weights=dict(rate=1., distortion=lmbda),
)
return trainer
接下来,训练模型。这里不需要人工标注,因为我们只想压缩图像,所以我们使用 map 丢弃它们,而是为速率和失真添加“虚拟”目标。
def add_rd_targets(image, label):
# Training is unsupervised, so labels aren't necessary here. However, we
# need to add "dummy" targets for rate and distortion.
return image, dict(rate=0., distortion=0.)
def train_mnist_model(lmbda):
trainer = make_mnist_compression_trainer(lmbda)
trainer.fit(
training_dataset.map(add_rd_targets).batch(128).prefetch(8),
epochs=15,
validation_data=validation_dataset.map(add_rd_targets).batch(128).cache(),
validation_freq=1,
verbose=1,
)
return trainer
trainer = train_mnist_model(lmbda=2000)
Epoch 1/15 467/469 [============================>.] - ETA: 0s - loss: 219.4970 - distortion_loss: 0.0598 - rate_loss: 99.8539 - distortion_pass_through_loss: 0.0598 - rate_pass_through_loss: 99.8539 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 14s 23ms/step - loss: 219.3287 - distortion_loss: 0.0598 - rate_loss: 99.8235 - distortion_pass_through_loss: 0.0597 - rate_pass_through_loss: 99.8190 - val_loss: 176.6952 - val_distortion_loss: 0.0424 - val_rate_loss: 91.9455 - val_distortion_pass_through_loss: 0.0424 - val_rate_pass_through_loss: 91.9553 Epoch 2/15 469/469 [==============================] - 10s 21ms/step - loss: 166.0387 - distortion_loss: 0.0410 - rate_loss: 83.9876 - distortion_pass_through_loss: 0.0410 - rate_pass_through_loss: 83.9833 - val_loss: 156.0399 - val_distortion_loss: 0.0397 - val_rate_loss: 76.5447 - val_distortion_pass_through_loss: 0.0397 - val_rate_pass_through_loss: 76.5545 Epoch 3/15 469/469 [==============================] - 10s 21ms/step - loss: 150.7590 - distortion_loss: 0.0397 - rate_loss: 71.2698 - distortion_pass_through_loss: 0.0397 - rate_pass_through_loss: 71.2663 - val_loss: 143.7437 - val_distortion_loss: 0.0399 - val_rate_loss: 64.0326 - val_distortion_pass_through_loss: 0.0399 - val_rate_pass_through_loss: 64.0276 Epoch 4/15 469/469 [==============================] - 10s 21ms/step - loss: 142.2607 - distortion_loss: 0.0395 - rate_loss: 63.2149 - distortion_pass_through_loss: 0.0395 - rate_pass_through_loss: 63.2126 - val_loss: 136.2439 - val_distortion_loss: 0.0406 - val_rate_loss: 55.1126 - val_distortion_pass_through_loss: 0.0406 - val_rate_pass_through_loss: 55.0992 Epoch 5/15 469/469 [==============================] - 10s 21ms/step - loss: 136.6350 - distortion_loss: 0.0392 - rate_loss: 58.2967 - distortion_pass_through_loss: 0.0392 - rate_pass_through_loss: 58.2950 - val_loss: 131.8454 - val_distortion_loss: 0.0418 - val_rate_loss: 48.2437 - val_distortion_pass_through_loss: 0.0418 - val_rate_pass_through_loss: 48.2309 Epoch 6/15 469/469 [==============================] - 10s 21ms/step - loss: 132.8357 - distortion_loss: 0.0388 - rate_loss: 55.1559 - distortion_pass_through_loss: 0.0388 - rate_pass_through_loss: 55.1541 - val_loss: 126.8537 - val_distortion_loss: 0.0413 - val_rate_loss: 44.1647 - val_distortion_pass_through_loss: 0.0413 - val_rate_pass_through_loss: 44.1611 Epoch 7/15 469/469 [==============================] - 10s 21ms/step - loss: 129.6230 - distortion_loss: 0.0383 - rate_loss: 52.9344 - distortion_pass_through_loss: 0.0383 - rate_pass_through_loss: 52.9332 - val_loss: 123.1619 - val_distortion_loss: 0.0406 - val_rate_loss: 41.8766 - val_distortion_pass_through_loss: 0.0406 - val_rate_pass_through_loss: 41.8841 Epoch 8/15 469/469 [==============================] - 10s 21ms/step - loss: 127.0022 - distortion_loss: 0.0379 - rate_loss: 51.1485 - distortion_pass_through_loss: 0.0379 - rate_pass_through_loss: 51.1476 - val_loss: 119.7338 - val_distortion_loss: 0.0393 - val_rate_loss: 41.0842 - val_distortion_pass_through_loss: 0.0393 - val_rate_pass_through_loss: 41.0881 Epoch 9/15 469/469 [==============================] - 10s 21ms/step - loss: 124.5822 - distortion_loss: 0.0375 - rate_loss: 49.6230 - distortion_pass_through_loss: 0.0375 - rate_pass_through_loss: 49.6216 - val_loss: 118.7188 - val_distortion_loss: 0.0396 - val_rate_loss: 39.5464 - val_distortion_pass_through_loss: 0.0396 - val_rate_pass_through_loss: 39.5388 Epoch 10/15 469/469 [==============================] - 10s 20ms/step - loss: 122.2946 - distortion_loss: 0.0370 - rate_loss: 48.2343 - distortion_pass_through_loss: 0.0370 - rate_pass_through_loss: 48.2335 - val_loss: 116.0431 - val_distortion_loss: 0.0378 - val_rate_loss: 40.5313 - val_distortion_pass_through_loss: 0.0378 - val_rate_pass_through_loss: 40.5214 Epoch 11/15 469/469 [==============================] - 10s 20ms/step - loss: 120.2840 - distortion_loss: 0.0366 - rate_loss: 47.0336 - distortion_pass_through_loss: 0.0366 - rate_pass_through_loss: 47.0329 - val_loss: 115.0391 - val_distortion_loss: 0.0374 - val_rate_loss: 40.2651 - val_distortion_pass_through_loss: 0.0374 - val_rate_pass_through_loss: 40.2673 Epoch 12/15 469/469 [==============================] - 9s 20ms/step - loss: 118.5191 - distortion_loss: 0.0363 - rate_loss: 45.9115 - distortion_pass_through_loss: 0.0363 - rate_pass_through_loss: 45.9113 - val_loss: 113.4488 - val_distortion_loss: 0.0362 - val_rate_loss: 41.1207 - val_distortion_pass_through_loss: 0.0362 - val_rate_pass_through_loss: 41.1314 Epoch 13/15 469/469 [==============================] - 10s 20ms/step - loss: 116.7709 - distortion_loss: 0.0358 - rate_loss: 45.1241 - distortion_pass_through_loss: 0.0358 - rate_pass_through_loss: 45.1242 - val_loss: 112.9705 - val_distortion_loss: 0.0358 - val_rate_loss: 41.3719 - val_distortion_pass_through_loss: 0.0358 - val_rate_pass_through_loss: 41.3784 Epoch 14/15 469/469 [==============================] - 10s 20ms/step - loss: 115.5197 - distortion_loss: 0.0355 - rate_loss: 44.5284 - distortion_pass_through_loss: 0.0355 - rate_pass_through_loss: 44.5273 - val_loss: 111.5821 - val_distortion_loss: 0.0356 - val_rate_loss: 40.3043 - val_distortion_pass_through_loss: 0.0356 - val_rate_pass_through_loss: 40.3116 Epoch 15/15 469/469 [==============================] - 10s 21ms/step - loss: 114.3993 - distortion_loss: 0.0352 - rate_loss: 44.0437 - distortion_pass_through_loss: 0.0352 - rate_pass_through_loss: 44.0429 - val_loss: 110.9734 - val_distortion_loss: 0.0350 - val_rate_loss: 40.9841 - val_distortion_pass_through_loss: 0.0350 - val_rate_pass_through_loss: 40.9915
压缩一些 MNIST 图像。
为了在测试时进行压缩和解压缩,我们将训练后的模型分成两部分
- 编码器端包含分析变换和熵模型。
- 解码器端包含合成变换和相同的熵模型。
在测试时,潜在变量将不会有加性噪声,但它们将被量化,然后进行无损压缩,因此我们为它们赋予新的名称。我们分别将它们和图像重建称为 \(\hat x\) 和 \(\hat y\)(遵循 端到端优化图像压缩)。
class MNISTCompressor(tf.keras.Model):
"""Compresses MNIST images to strings."""
def __init__(self, analysis_transform, entropy_model):
super().__init__()
self.analysis_transform = analysis_transform
self.entropy_model = entropy_model
def call(self, x):
# Ensure inputs are floats in the range (0, 1).
x = tf.cast(x, self.compute_dtype) / 255.
y = self.analysis_transform(x)
# Also return the exact information content of each digit.
_, bits = self.entropy_model(y, training=False)
return self.entropy_model.compress(y), bits
class MNISTDecompressor(tf.keras.Model):
"""Decompresses MNIST images from strings."""
def __init__(self, entropy_model, synthesis_transform):
super().__init__()
self.entropy_model = entropy_model
self.synthesis_transform = synthesis_transform
def call(self, string):
y_hat = self.entropy_model.decompress(string, ())
x_hat = self.synthesis_transform(y_hat)
# Scale and cast back to 8-bit integer.
return tf.saturate_cast(tf.round(x_hat * 255.), tf.uint8)
当使用 compression=True 实例化时,熵模型将学习的先验转换为用于范围编码算法的表格。当调用 compress() 时,将调用此算法将潜在空间向量转换为比特序列。每个二进制字符串的长度近似于潜在变量的信息内容(潜在变量在先验下的负对数似然)。
用于压缩和解压缩的熵模型必须是同一个实例,因为范围编码表格在两侧必须完全相同。否则,可能会出现解码错误。
def make_mnist_codec(trainer, **kwargs):
# The entropy model must be created with `compression=True` and the same
# instance must be shared between compressor and decompressor.
entropy_model = tfc.ContinuousBatchedEntropyModel(
trainer.prior, coding_rank=1, compression=True, **kwargs)
compressor = MNISTCompressor(trainer.analysis_transform, entropy_model)
decompressor = MNISTDecompressor(entropy_model, trainer.synthesis_transform)
return compressor, decompressor
compressor, decompressor = make_mnist_codec(trainer)
从验证数据集中获取 16 张图像。您可以通过更改 skip 的参数来选择不同的子集。
(originals, _), = validation_dataset.batch(16).skip(3).take(1)
将它们压缩为字符串,并跟踪每个字符串的信息内容(以比特为单位)。
strings, entropies = compressor(originals)
print(f"String representation of first digit in hexadecimal: 0x{strings[0].numpy().hex()}")
print(f"Number of bits actually needed to represent it: {entropies[0]:0.2f}")
String representation of first digit in hexadecimal: 0x4d63d90ed1 Number of bits actually needed to represent it: 37.99
从字符串中解压缩图像。
reconstructions = decompressor(strings)
显示每个 16 个原始数字及其压缩的二进制表示,以及重建的数字。
display_digits(originals, strings, entropies, reconstructions)

请注意,编码字符串的长度与每个数字的信息内容不同。
这是因为范围编码过程使用离散概率,并且有一点开销。因此,特别是对于短字符串,对应关系只是近似的。但是,范围编码是**渐近最优的**:在极限情况下,预期比特数将接近交叉熵(预期信息内容),训练模型中的速率项是其上限。
速率-失真权衡
在上面,模型经过训练以实现特定的权衡(由 lmbda=2000 给出),在用于表示每个数字的平均比特数和重建中产生的误差之间。
当我们使用不同的值重复实验时会发生什么?
让我们首先将 \(\lambda\) 减少到 500。
def train_and_visualize_model(lmbda):
trainer = train_mnist_model(lmbda=lmbda)
compressor, decompressor = make_mnist_codec(trainer)
strings, entropies = compressor(originals)
reconstructions = decompressor(strings)
display_digits(originals, strings, entropies, reconstructions)
train_and_visualize_model(lmbda=500)
Epoch 1/15 469/469 [==============================] - ETA: 0s - loss: 127.5305 - distortion_loss: 0.0700 - rate_loss: 92.5392 - distortion_pass_through_loss: 0.0700 - rate_pass_through_loss: 92.5329 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 12s 21ms/step - loss: 127.5305 - distortion_loss: 0.0700 - rate_loss: 92.5392 - distortion_pass_through_loss: 0.0700 - rate_pass_through_loss: 92.5329 - val_loss: 107.4705 - val_distortion_loss: 0.0548 - val_rate_loss: 80.0521 - val_distortion_pass_through_loss: 0.0549 - val_rate_pass_through_loss: 80.0560 Epoch 2/15 469/469 [==============================] - 10s 20ms/step - loss: 97.2982 - distortion_loss: 0.0541 - rate_loss: 70.2615 - distortion_pass_through_loss: 0.0541 - rate_pass_through_loss: 70.2563 - val_loss: 86.4681 - val_distortion_loss: 0.0599 - val_rate_loss: 56.5326 - val_distortion_pass_through_loss: 0.0599 - val_rate_pass_through_loss: 56.5317 Epoch 3/15 469/469 [==============================] - 10s 20ms/step - loss: 81.2346 - distortion_loss: 0.0562 - rate_loss: 53.1251 - distortion_pass_through_loss: 0.0562 - rate_pass_through_loss: 53.1215 - val_loss: 71.9185 - val_distortion_loss: 0.0682 - val_rate_loss: 37.8106 - val_distortion_pass_through_loss: 0.0683 - val_rate_pass_through_loss: 37.8011 Epoch 4/15 469/469 [==============================] - 10s 20ms/step - loss: 71.5505 - distortion_loss: 0.0593 - rate_loss: 41.8880 - distortion_pass_through_loss: 0.0593 - rate_pass_through_loss: 41.8856 - val_loss: 63.3954 - val_distortion_loss: 0.0762 - val_rate_loss: 25.3134 - val_distortion_pass_through_loss: 0.0762 - val_rate_pass_through_loss: 25.3113 Epoch 5/15 469/469 [==============================] - 10s 20ms/step - loss: 65.9471 - distortion_loss: 0.0622 - rate_loss: 34.8656 - distortion_pass_through_loss: 0.0622 - rate_pass_through_loss: 34.8637 - val_loss: 57.6301 - val_distortion_loss: 0.0786 - val_rate_loss: 18.3391 - val_distortion_pass_through_loss: 0.0786 - val_rate_pass_through_loss: 18.3298 Epoch 6/15 469/469 [==============================] - 9s 20ms/step - loss: 62.4032 - distortion_loss: 0.0642 - rate_loss: 30.3145 - distortion_pass_through_loss: 0.0642 - rate_pass_through_loss: 30.3131 - val_loss: 55.5859 - val_distortion_loss: 0.0848 - val_rate_loss: 13.1697 - val_distortion_pass_through_loss: 0.0848 - val_rate_pass_through_loss: 13.1684 Epoch 7/15 469/469 [==============================] - 9s 20ms/step - loss: 59.9169 - distortion_loss: 0.0656 - rate_loss: 27.1412 - distortion_pass_through_loss: 0.0655 - rate_pass_through_loss: 27.1403 - val_loss: 51.1707 - val_distortion_loss: 0.0758 - val_rate_loss: 13.2823 - val_distortion_pass_through_loss: 0.0758 - val_rate_pass_through_loss: 13.2810 Epoch 8/15 469/469 [==============================] - 9s 20ms/step - loss: 57.7210 - distortion_loss: 0.0660 - rate_loss: 24.7239 - distortion_pass_through_loss: 0.0660 - rate_pass_through_loss: 24.7234 - val_loss: 49.3867 - val_distortion_loss: 0.0736 - val_rate_loss: 12.5935 - val_distortion_pass_through_loss: 0.0736 - val_rate_pass_through_loss: 12.5888 Epoch 9/15 469/469 [==============================] - 10s 20ms/step - loss: 55.7091 - distortion_loss: 0.0658 - rate_loss: 22.7991 - distortion_pass_through_loss: 0.0658 - rate_pass_through_loss: 22.7988 - val_loss: 48.4335 - val_distortion_loss: 0.0695 - val_rate_loss: 13.6779 - val_distortion_pass_through_loss: 0.0695 - val_rate_pass_through_loss: 13.6865 Epoch 10/15 469/469 [==============================] - 10s 20ms/step - loss: 53.9030 - distortion_loss: 0.0651 - rate_loss: 21.3707 - distortion_pass_through_loss: 0.0651 - rate_pass_through_loss: 21.3701 - val_loss: 47.2973 - val_distortion_loss: 0.0689 - val_rate_loss: 12.8318 - val_distortion_pass_through_loss: 0.0690 - val_rate_pass_through_loss: 12.8296 Epoch 11/15 469/469 [==============================] - 9s 20ms/step - loss: 52.3183 - distortion_loss: 0.0641 - rate_loss: 20.2617 - distortion_pass_through_loss: 0.0641 - rate_pass_through_loss: 20.2610 - val_loss: 46.6293 - val_distortion_loss: 0.0671 - val_rate_loss: 13.0571 - val_distortion_pass_through_loss: 0.0672 - val_rate_pass_through_loss: 13.0598 Epoch 12/15 469/469 [==============================] - 10s 20ms/step - loss: 51.0015 - distortion_loss: 0.0633 - rate_loss: 19.3680 - distortion_pass_through_loss: 0.0633 - rate_pass_through_loss: 19.3676 - val_loss: 46.1679 - val_distortion_loss: 0.0642 - val_rate_loss: 14.0836 - val_distortion_pass_through_loss: 0.0642 - val_rate_pass_through_loss: 14.0873 Epoch 13/15 469/469 [==============================] - 9s 20ms/step - loss: 49.9189 - distortion_loss: 0.0627 - rate_loss: 18.5747 - distortion_pass_through_loss: 0.0627 - rate_pass_through_loss: 18.5742 - val_loss: 45.6781 - val_distortion_loss: 0.0640 - val_rate_loss: 13.6870 - val_distortion_pass_through_loss: 0.0640 - val_rate_pass_through_loss: 13.6915 Epoch 14/15 469/469 [==============================] - 9s 20ms/step - loss: 48.9510 - distortion_loss: 0.0621 - rate_loss: 17.9217 - distortion_pass_through_loss: 0.0621 - rate_pass_through_loss: 17.9215 - val_loss: 45.1058 - val_distortion_loss: 0.0614 - val_rate_loss: 14.4060 - val_distortion_pass_through_loss: 0.0614 - val_rate_pass_through_loss: 14.4218 Epoch 15/15 469/469 [==============================] - 9s 20ms/step - loss: 48.1553 - distortion_loss: 0.0615 - rate_loss: 17.4100 - distortion_pass_through_loss: 0.0615 - rate_pass_through_loss: 17.4101 - val_loss: 44.9707 - val_distortion_loss: 0.0609 - val_rate_loss: 14.5456 - val_distortion_pass_through_loss: 0.0609 - val_rate_pass_through_loss: 14.5536

我们代码的比特率下降了,数字的保真度也下降了。但是,大多数数字仍然可以识别。
让我们进一步减少 \(\lambda\)。
train_and_visualize_model(lmbda=300)
Epoch 1/15 469/469 [==============================] - ETA: 0s - loss: 114.0398 - distortion_loss: 0.0768 - rate_loss: 90.9927 - distortion_pass_through_loss: 0.0768 - rate_pass_through_loss: 90.9862 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 12s 21ms/step - loss: 114.0398 - distortion_loss: 0.0768 - rate_loss: 90.9927 - distortion_pass_through_loss: 0.0768 - rate_pass_through_loss: 90.9862 - val_loss: 96.7790 - val_distortion_loss: 0.0688 - val_rate_loss: 76.1469 - val_distortion_pass_through_loss: 0.0688 - val_rate_pass_through_loss: 76.1451 Epoch 2/15 469/469 [==============================] - 10s 20ms/step - loss: 85.8627 - distortion_loss: 0.0613 - rate_loss: 67.4866 - distortion_pass_through_loss: 0.0613 - rate_pass_through_loss: 67.4809 - val_loss: 74.3796 - val_distortion_loss: 0.0796 - val_rate_loss: 50.5063 - val_distortion_pass_through_loss: 0.0797 - val_rate_pass_through_loss: 50.5014 Epoch 3/15 469/469 [==============================] - 10s 21ms/step - loss: 68.7960 - distortion_loss: 0.0645 - rate_loss: 49.4494 - distortion_pass_through_loss: 0.0645 - rate_pass_through_loss: 49.4456 - val_loss: 58.5856 - val_distortion_loss: 0.0911 - val_rate_loss: 31.2701 - val_distortion_pass_through_loss: 0.0912 - val_rate_pass_through_loss: 31.2587 Epoch 4/15 469/469 [==============================] - 10s 21ms/step - loss: 58.2693 - distortion_loss: 0.0693 - rate_loss: 37.4914 - distortion_pass_through_loss: 0.0693 - rate_pass_through_loss: 37.4892 - val_loss: 48.5439 - val_distortion_loss: 0.0983 - val_rate_loss: 19.0433 - val_distortion_pass_through_loss: 0.0984 - val_rate_pass_through_loss: 19.0396 Epoch 5/15 469/469 [==============================] - 10s 21ms/step - loss: 51.9585 - distortion_loss: 0.0734 - rate_loss: 29.9320 - distortion_pass_through_loss: 0.0734 - rate_pass_through_loss: 29.9306 - val_loss: 42.2598 - val_distortion_loss: 0.0994 - val_rate_loss: 12.4350 - val_distortion_pass_through_loss: 0.0995 - val_rate_pass_through_loss: 12.4339 Epoch 6/15 469/469 [==============================] - 10s 20ms/step - loss: 48.0547 - distortion_loss: 0.0769 - rate_loss: 24.9776 - distortion_pass_through_loss: 0.0769 - rate_pass_through_loss: 24.9766 - val_loss: 38.5121 - val_distortion_loss: 0.1000 - val_rate_loss: 8.4996 - val_distortion_pass_through_loss: 0.1000 - val_rate_pass_through_loss: 8.5025 Epoch 7/15 469/469 [==============================] - 9s 20ms/step - loss: 45.3418 - distortion_loss: 0.0798 - rate_loss: 21.4144 - distortion_pass_through_loss: 0.0798 - rate_pass_through_loss: 21.4135 - val_loss: 36.2517 - val_distortion_loss: 0.0992 - val_rate_loss: 6.4969 - val_distortion_pass_through_loss: 0.0991 - val_rate_pass_through_loss: 6.5043 Epoch 8/15 469/469 [==============================] - 9s 20ms/step - loss: 43.1311 - distortion_loss: 0.0812 - rate_loss: 18.7581 - distortion_pass_through_loss: 0.0812 - rate_pass_through_loss: 18.7577 - val_loss: 34.4578 - val_distortion_loss: 0.0923 - val_rate_loss: 6.7545 - val_distortion_pass_through_loss: 0.0923 - val_rate_pass_through_loss: 6.7532 Epoch 9/15 469/469 [==============================] - 10s 20ms/step - loss: 41.1835 - distortion_loss: 0.0815 - rate_loss: 16.7441 - distortion_pass_through_loss: 0.0815 - rate_pass_through_loss: 16.7435 - val_loss: 33.3371 - val_distortion_loss: 0.0870 - val_rate_loss: 7.2369 - val_distortion_pass_through_loss: 0.0870 - val_rate_pass_through_loss: 7.2306 Epoch 10/15 469/469 [==============================] - 10s 20ms/step - loss: 39.4039 - distortion_loss: 0.0806 - rate_loss: 15.2191 - distortion_pass_through_loss: 0.0806 - rate_pass_through_loss: 15.2184 - val_loss: 32.8390 - val_distortion_loss: 0.0840 - val_rate_loss: 7.6290 - val_distortion_pass_through_loss: 0.0840 - val_rate_pass_through_loss: 7.6263 Epoch 11/15 469/469 [==============================] - 9s 20ms/step - loss: 37.9107 - distortion_loss: 0.0793 - rate_loss: 14.1125 - distortion_pass_through_loss: 0.0793 - rate_pass_through_loss: 14.1124 - val_loss: 32.6137 - val_distortion_loss: 0.0816 - val_rate_loss: 8.1349 - val_distortion_pass_through_loss: 0.0816 - val_rate_pass_through_loss: 8.1267 Epoch 12/15 469/469 [==============================] - 10s 20ms/step - loss: 36.6647 - distortion_loss: 0.0780 - rate_loss: 13.2545 - distortion_pass_through_loss: 0.0780 - rate_pass_through_loss: 13.2540 - val_loss: 32.2822 - val_distortion_loss: 0.0814 - val_rate_loss: 7.8685 - val_distortion_pass_through_loss: 0.0814 - val_rate_pass_through_loss: 7.8598 Epoch 13/15 469/469 [==============================] - 10s 20ms/step - loss: 35.6982 - distortion_loss: 0.0771 - rate_loss: 12.5623 - distortion_pass_through_loss: 0.0771 - rate_pass_through_loss: 12.5622 - val_loss: 31.9754 - val_distortion_loss: 0.0791 - val_rate_loss: 8.2589 - val_distortion_pass_through_loss: 0.0791 - val_rate_pass_through_loss: 8.2520 Epoch 14/15 469/469 [==============================] - 9s 20ms/step - loss: 34.9956 - distortion_loss: 0.0765 - rate_loss: 12.0543 - distortion_pass_through_loss: 0.0765 - rate_pass_through_loss: 12.0540 - val_loss: 31.8855 - val_distortion_loss: 0.0786 - val_rate_loss: 8.3127 - val_distortion_pass_through_loss: 0.0786 - val_rate_pass_through_loss: 8.2984 Epoch 15/15 469/469 [==============================] - 9s 20ms/step - loss: 34.4267 - distortion_loss: 0.0759 - rate_loss: 11.6673 - distortion_pass_through_loss: 0.0759 - rate_pass_through_loss: 11.6670 - val_loss: 31.7163 - val_distortion_loss: 0.0777 - val_rate_loss: 8.3933 - val_distortion_pass_through_loss: 0.0778 - val_rate_pass_through_loss: 8.3861

字符串现在开始变得更短,每个数字大约一个字节。但是,这是有代价的。更多数字变得无法识别。
这表明该模型对人类对误差的感知是不可知的,它只是根据像素值的绝对偏差进行测量。为了获得更好的感知图像质量,我们需要用感知损失替换像素损失。
将解码器用作生成模型。
如果我们向解码器提供随机比特,这将有效地从模型学习到的表示数字的分布中进行采样。
首先,重新实例化压缩器/解压缩器,但不要进行健全性检查,该检查会检测输入字符串是否未完全解码。
compressor, decompressor = make_mnist_codec(trainer, decode_sanity_check=False)
现在,向解压缩器提供足够长的随机字符串,以便它可以从这些字符串中解码/采样数字。
import os
strings = tf.constant([os.urandom(8) for _ in range(16)])
samples = decompressor(strings)
fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(5, 5))
axes = axes.ravel()
for i in range(len(axes)):
axes[i].imshow(tf.squeeze(samples[i]))
axes[i].axis("off")
plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)
