
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概述
The tf.distribute.Strategy API 提供了一种抽象,用于将您的训练分布到多个处理单元。它允许您使用现有的模型和训练代码进行分布式训练,只需进行最小的更改。
本教程演示了如何使用 tf.distribute.MirroredStrategy 在一台机器上的多个 GPU 上进行同步训练,执行图内复制。该策略实际上将所有模型变量复制到每个处理器。然后,它使用 全约简 来组合来自所有处理器的梯度,并将组合后的值应用于模型的所有副本。
您将使用 tf.keras API 来构建模型,并使用 Model.fit 来训练它。(要了解使用自定义训练循环和 MirroredStrategy 进行分布式训练,请查看 本教程。)
MirroredStrategy 在一台机器上的多个 GPU 上训练您的模型。对于多台机器上的多个 GPU 上进行同步训练,请使用 tf.distribute.MultiWorkerMirroredStrategy 以及 Keras Model.fit 或 自定义训练循环。有关其他选项,请参阅 分布式训练指南。
要了解各种其他策略,请参阅 使用 TensorFlow 进行分布式训练 指南。
设置
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
下载数据集
从 TensorFlow 数据集 加载 MNIST 数据集。这将返回 tf.data 格式的数据集。
将 with_info 参数设置为 True 将包含整个数据集的元数据,这些元数据将保存在此处到 info 中。除其他事项外,此元数据对象还包含训练和测试示例的数量。
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
定义分布策略
创建一个 MirroredStrategy 对象。这将处理分布并提供一个上下文管理器(MirroredStrategy.scope)在其中构建您的模型。
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
设置输入管道
在使用多个 GPU 训练模型时,您可以通过增加批次大小来有效地利用额外的计算能力。一般来说,使用适合 GPU 内存的最大批次大小,并相应地调整学习率。
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
定义一个函数,将图像像素值从 [0, 255] 范围归一化为 [0, 1] 范围(特征缩放)
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
将此 scale 函数应用于训练和测试数据,然后使用 tf.data.Dataset API 对训练数据进行洗牌(Dataset.shuffle)并将其批处理(Dataset.batch)。请注意,您还保留了训练数据的内存缓存,以提高性能(Dataset.cache)。
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
创建模型并实例化优化器
在 Strategy.scope 的上下文中,使用 Keras API 创建和编译模型
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
metrics=['accuracy'])
对于使用 MNIST 数据集的这个玩具示例,您将使用 Adam 优化器的默认学习率 0.001。
对于更大的数据集,分布式训练的主要好处是在每个训练步骤中学习更多,因为每个步骤并行处理更多训练数据,这允许使用更大的学习率(在模型和数据集的限制范围内)。
定义回调
定义以下 Keras 回调
tf.keras.callbacks.TensorBoard:为 TensorBoard 写入日志,这使您可以可视化图表。tf.keras.callbacks.ModelCheckpoint:定期保存模型,例如在每个 epoch 之后。tf.keras.callbacks.BackupAndRestore:通过备份模型和当前 epoch 编号来提供容错功能。在 使用 Keras 进行多工作器训练 教程的“容错”部分中了解更多信息。tf.keras.callbacks.LearningRateScheduler:安排学习率在例如每个 epoch/批次之后发生变化。
为了说明目的,添加一个名为 PrintLR 的 自定义回调,以在笔记本中显示学习率。
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format( epoch + 1, model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
训练和评估
现在,通过在模型上调用 Keras Model.fit 并传入本教程开头创建的数据集,以通常的方式训练模型。无论您是否正在分布训练,此步骤都是相同的。
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
检查保存的检查点
# Check the checkpoint directory.ls {checkpoint_dir}
要检查模型的性能,请加载最新的检查点并调用 Model.evaluate 来测试数据
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
要可视化输出,请启动 TensorBoard 并查看日志
%tensorboard --logdir=logs
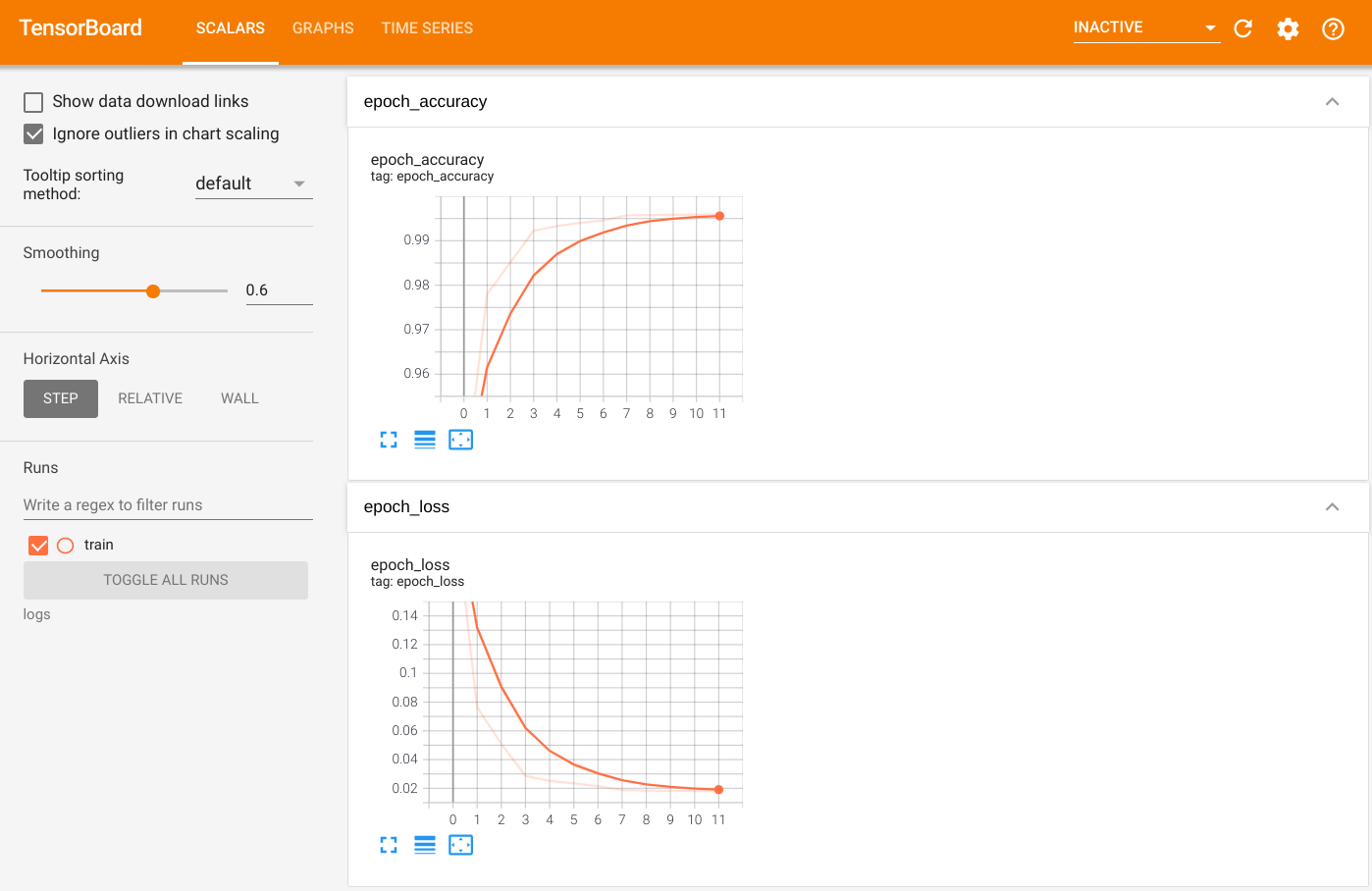
ls -sh ./logs
保存模型
使用 Model.save 将模型保存到 .keras zip 存档中。保存模型后,您可以使用或不使用 Strategy.scope 加载它。
path = 'my_model.keras'
model.save(path)
现在,在没有 Strategy.scope 的情况下加载模型
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
使用 Strategy.scope 加载模型
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
其他资源
使用 Keras Model.fit API 的更多示例,这些示例使用不同的分布策略
- 使用 BERT 在 TPU 上解决 GLUE 任务 教程使用
tf.distribute.MirroredStrategy在 GPU 上进行训练,以及tf.distribute.TPUStrategy在 TPU 上进行训练。 - 使用分布策略保存和加载模型 教程演示了如何将 SavedModel API 与
tf.distribute.Strategy一起使用。 - 官方 TensorFlow 模型 可以配置为运行多个分布策略。
要了解有关 TensorFlow 分布策略的更多信息
- 使用 tf.distribute.Strategy 进行自定义训练 教程展示了如何使用
tf.distribute.MirroredStrategy进行单工作器训练,并使用自定义训练循环。 - 使用 Keras 进行多工作器训练 教程展示了如何将
MultiWorkerMirroredStrategy与Model.fit一起使用。 - 使用 Keras 和 MultiWorkerMirroredStrategy 进行自定义训练循环 教程展示了如何将
MultiWorkerMirroredStrategy与 Keras 和自定义训练循环一起使用。 - TensorFlow 中的分布式训练 指南概述了可用的分布策略。
- 使用 tf.function 提高性能 指南提供有关其他策略和工具的信息,例如 TensorFlow 分析器,您可以使用它来优化 TensorFlow 模型的性能。