
|
|
|
 在 GitHub 上查看 在 GitHub 上查看
|
|
|
欢迎来到 TensorFlow 决策森林 (TF-DF) 的 中级 Colab。在这个 Colab 中,您将了解 TF-DF 的一些更高级的功能,包括如何处理自然语言特征。
此 Colab 假设您熟悉 初学者 Colab 中介绍的概念,特别是关于 TF-DF 的安装。
在这个 Colab 中,您将
训练一个随机森林,它以分类集的形式原生地使用文本特征。
训练一个随机森林,它使用 TensorFlow Hub 模块使用文本特征。在这种设置(迁移学习)中,该模块已在大型文本语料库上预训练。
一起训练一个梯度提升决策树 (GBDT) 和一个神经网络。GBDT 将使用神经网络的输出。
设置
# Install TensorFlow Dececision Forestspip install tensorflow_decision_forests
Wurlitzer 需要在 Colabs 中显示详细的训练日志(在模型构造函数中使用 verbose=2 时)。
pip install wurlitzer
导入必要的库。
import os
# Keep using Keras 2
os.environ['TF_USE_LEGACY_KERAS'] = '1'
import tensorflow_decision_forests as tfdf
import numpy as np
import pandas as pd
import tensorflow as tf
import tf_keras
import math
隐藏的代码单元格限制了 Colab 中的输出高度。
使用原始文本作为特征
TF-DF 可以原生地使用 分类集 特征。分类集将文本特征表示为词袋(或 n 元语法)。
例如:"The little blue dog" → {"the", "little", "blue", "dog"}
在本例中,您将使用 斯坦福情感树库 (SST) 数据集训练一个随机森林。此数据集的目标是将句子分类为带有正面或负面情感。您将使用 TensorFlow 数据集 中整理的该数据集的二元分类版本。
# Install the TensorFlow Datasets packagepip install tensorflow-datasets -U --quiet
# Load the dataset
import tensorflow_datasets as tfds
all_ds = tfds.load("glue/sst2")
# Display the first 3 examples of the test fold.
for example in all_ds["test"].take(3):
print({attr_name: attr_tensor.numpy() for attr_name, attr_tensor in example.items()})
{'idx': 163, 'label': -1, 'sentence': b'not even the hanson brothers can save it'}
{'idx': 131, 'label': -1, 'sentence': b'strong setup and ambitious goals fade as the film descends into unsophisticated scare tactics and b-film thuggery .'}
{'idx': 1579, 'label': -1, 'sentence': b'too timid to bring a sense of closure to an ugly chapter of the twentieth century .'}
2024-04-20 11:17:31.940774: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
2024-04-20 11:17:31.946131: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
数据集按如下方式修改
- 原始标签是
{-1, 1}中的整数,但学习算法期望正整数标签,例如{0, 1}。因此,标签按如下方式转换:new_labels = (original_labels + 1) / 2。 - 应用了 64 的批次大小,以使读取数据集更有效率。
sentence属性需要进行标记,即"hello world" -> ["hello", "world"]。
详细信息:一些决策森林学习算法不需要验证数据集(例如随机森林),而另一些则需要(例如,在某些情况下,梯度提升树)。由于 TF-DF 中的每个学习算法都可以以不同的方式使用验证数据,因此 TF-DF 在内部处理训练/验证拆分。因此,当您有训练集和验证集时,它们始终可以连接起来作为学习算法的输入。
def prepare_dataset(example):
label = (example["label"] + 1) // 2
return {"sentence" : tf.strings.split(example["sentence"])}, label
train_ds = all_ds["train"].batch(100).map(prepare_dataset)
test_ds = all_ds["validation"].batch(100).map(prepare_dataset)
最后,像往常一样训练和评估模型。TF-DF 会自动将多值分类特征检测为分类集。
%set_cell_height 300
# Specify the model.
model_1 = tfdf.keras.RandomForestModel(num_trees=30, verbose=2)
# Train the model.
model_1.fit(x=train_ds)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpx28adgyq as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'sentence': tf.RaggedTensor(values=Tensor("data:0", shape=(None,), dtype=string), row_splits=Tensor("data_1:0", shape=(None,), dtype=int64))}
Label: Tensor("data_2:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'sentence': SemanticTensor(semantic=<Semantic.CATEGORICAL_SET: 4>, tensor=tf.RaggedTensor(values=Tensor("data:0", shape=(None,), dtype=string), row_splits=Tensor("data_1:0", shape=(None,), dtype=int64)))}
Training dataset read in 0:00:04.709443. Found 67349 examples.
Training model...
Standard output detected as not visible to the user e.g. running in a notebook. Creating a training log redirection. If training gets stuck, try calling tfdf.keras.set_training_logs_redirection(False).
[INFO 24-04-20 11:17:36.8175 UTC kernel.cc:771] Start Yggdrasil model training
[INFO 24-04-20 11:17:36.8176 UTC kernel.cc:772] Collect training examples
[INFO 24-04-20 11:17:36.8176 UTC kernel.cc:785] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 24-04-20 11:17:36.8179 UTC kernel.cc:391] Number of batches: 674
[INFO 24-04-20 11:17:36.8180 UTC kernel.cc:392] Number of examples: 67349
[INFO 24-04-20 11:17:36.8602 UTC data_spec_inference.cc:305] 12816 item(s) have been pruned (i.e. they are considered out of dictionary) for the column sentence (2000 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 24-04-20 11:17:36.9136 UTC kernel.cc:792] Training dataset:
Number of records: 67349
Number of columns: 2
Number of columns by type:
CATEGORICAL_SET: 1 (50%)
CATEGORICAL: 1 (50%)
Columns:
CATEGORICAL_SET: 1 (50%)
1: "sentence" CATEGORICAL_SET has-dict vocab-size:2001 num-oods:10187 (15.1257%) most-frequent:"the" 27205 (40.3941%)
CATEGORICAL: 1 (50%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute whose type is manually defined by the user, i.e., the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 24-04-20 11:17:36.9137 UTC kernel.cc:808] Configure learner
[INFO 24-04-20 11:17:36.9139 UTC kernel.cc:822] Training config:
learner: "RANDOM_FOREST"
features: "^sentence$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 123456
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 30
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
[INFO 24-04-20 11:17:36.9143 UTC kernel.cc:825] Deployment config:
cache_path: "/tmpfs/tmp/tmpx28adgyq/working_cache"
num_threads: 32
try_resume_training: true
[INFO 24-04-20 11:17:36.9145 UTC kernel.cc:887] Train model
[INFO 24-04-20 11:17:36.9152 UTC random_forest.cc:416] Training random forest on 67349 example(s) and 1 feature(s).
[INFO 24-04-20 11:18:08.8767 UTC random_forest.cc:802] Training of tree 1/30 (tree index:1) done accuracy:0.7412 logloss:9.32811
[INFO 24-04-20 11:18:19.2026 UTC random_forest.cc:802] Training of tree 6/30 (tree index:27) done accuracy:0.775555 logloss:4.88012
[INFO 24-04-20 11:18:21.1285 UTC random_forest.cc:802] Training of tree 16/30 (tree index:25) done accuracy:0.808699 logloss:1.679
[INFO 24-04-20 11:18:22.6848 UTC random_forest.cc:802] Training of tree 26/30 (tree index:8) done accuracy:0.818557 logloss:0.904858
[INFO 24-04-20 11:18:24.0005 UTC random_forest.cc:802] Training of tree 30/30 (tree index:6) done accuracy:0.821274 logloss:0.854486
[INFO 24-04-20 11:18:24.0013 UTC random_forest.cc:882] Final OOB metrics: accuracy:0.821274 logloss:0.854486
[INFO 24-04-20 11:18:24.0104 UTC kernel.cc:919] Export model in log directory: /tmpfs/tmp/tmpx28adgyq with prefix da59c2f23fdb4012
[INFO 24-04-20 11:18:24.0388 UTC kernel.cc:937] Save model in resources
[INFO 24-04-20 11:18:24.0420 UTC abstract_model.cc:881] Model self evaluation:
Number of predictions (without weights): 67349
Number of predictions (with weights): 67349
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.821274 CI95[W][0.818828 0.8237]
LogLoss: : 0.854486
ErrorRate: : 0.178726
Default Accuracy: : 0.557826
Default LogLoss: : 0.686445
Default ErrorRate: : 0.442174
Confusion Table:
truth\prediction
1 2
1 19593 10187
2 1850 35719
Total: 67349
[INFO 24-04-20 11:18:24.0658 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpx28adgyq/model/ with prefix da59c2f23fdb4012
[INFO 24-04-20 11:18:24.3112 UTC decision_forest.cc:734] Model loaded with 30 root(s), 43180 node(s), and 1 input feature(s).
[INFO 24-04-20 11:18:24.3113 UTC abstract_model.cc:1344] Engine "RandomForestGeneric" built
[INFO 24-04-20 11:18:24.3113 UTC kernel.cc:1061] Use fast generic engine
Model trained in 0:00:47.515581
Compiling model...
Model compiled.
<tf_keras.src.callbacks.History at 0x7ff6107c01c0>
在之前的日志中,请注意 sentence 是一个 CATEGORICAL_SET 特征。
模型像往常一样进行评估
model_1.compile(metrics=["accuracy"])
evaluation = model_1.evaluate(test_ds)
print(f"BinaryCrossentropyloss: {evaluation[0]}")
print(f"Accuracy: {evaluation[1]}")
9/9 [==============================] - 4s 4ms/step - loss: 0.0000e+00 - accuracy: 0.7638 BinaryCrossentropyloss: 0.0 Accuracy: 0.7637614607810974
训练日志如下所示
import matplotlib.pyplot as plt
logs = model_1.make_inspector().training_logs()
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Out-of-bag accuracy")
pass
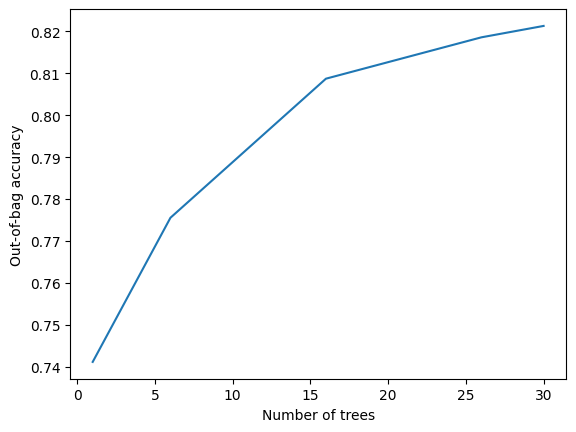
更多的树可能会有益(我确信这一点,因为我尝试过:p)。
使用预训练的文本嵌入
之前的示例使用原始文本特征训练了一个随机森林。本示例将使用预训练的 TF-Hub 嵌入将文本特征转换为密集嵌入,然后在其之上训练一个随机森林。在这种情况下,随机森林只会“看到”嵌入的数值输出(即它不会看到原始文本)。
在本实验中,将使用 通用句子编码器。不同的预训练嵌入可能适合不同类型的文本(例如不同的语言、不同的任务),也可能适合其他类型的结构化特征(例如图像)。
嵌入模块可以在以下两个地方之一应用
- 在数据集准备期间。
- 在模型的预处理阶段。
第二个选项通常更可取:将嵌入打包到模型中可以使模型更容易使用(并且更难误用)。
首先安装 TF-Hub
pip install --upgrade tensorflow-hub
与之前不同,您不需要对文本进行分词。
def prepare_dataset(example):
label = (example["label"] + 1) // 2
return {"sentence" : example["sentence"]}, label
train_ds = all_ds["train"].batch(100).map(prepare_dataset)
test_ds = all_ds["validation"].batch(100).map(prepare_dataset)
%set_cell_height 300
import tensorflow_hub as hub
# NNLM (https://tfhub.dev/google/nnlm-en-dim128/2) is also a good choice.
hub_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
embedding = hub.KerasLayer(hub_url)
sentence = tf_keras.layers.Input(shape=(), name="sentence", dtype=tf.string)
embedded_sentence = embedding(sentence)
raw_inputs = {"sentence": sentence}
processed_inputs = {"embedded_sentence": embedded_sentence}
preprocessor = tf_keras.Model(inputs=raw_inputs, outputs=processed_inputs)
model_2 = tfdf.keras.RandomForestModel(
preprocessing=preprocessor,
num_trees=100)
model_2.fit(x=train_ds)
<IPython.core.display.Javascript object> Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmpv_kuhy0b as temporary training directory Reading training dataset... Training dataset read in 0:00:24.071412. Found 67349 examples. Training model... [INFO 24-04-20 11:19:25.9064 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpv_kuhy0b/model/ with prefix 36a4a9d3f10743e4 Model trained in 0:00:13.926431 Compiling model... [INFO 24-04-20 11:19:27.6042 UTC decision_forest.cc:734] Model loaded with 100 root(s), 565608 node(s), and 512 input feature(s). [INFO 24-04-20 11:19:27.6044 UTC abstract_model.cc:1344] Engine "RandomForestOptPred" built [INFO 24-04-20 11:19:27.6045 UTC kernel.cc:1061] Use fast generic engine Model compiled. <tf_keras.src.callbacks.History at 0x7ff4202c16d0>
model_2.compile(metrics=["accuracy"])
evaluation = model_2.evaluate(test_ds)
print(f"BinaryCrossentropyloss: {evaluation[0]}")
print(f"Accuracy: {evaluation[1]}")
9/9 [==============================] - 2s 18ms/step - loss: 0.0000e+00 - accuracy: 0.7878 BinaryCrossentropyloss: 0.0 Accuracy: 0.7878440618515015
请注意,分类集以与密集嵌入不同的方式表示文本,因此联合使用这两种策略可能很有用。
一起训练决策树和神经网络
之前的示例使用预训练的神经网络 (NN) 来处理文本特征,然后将其传递给随机森林。本示例将从头开始训练神经网络和随机森林。
TF-DF 的决策森林不反向传播梯度 (尽管这是正在进行的研究主题)。因此,训练分为两个阶段
- 将神经网络训练为标准分类任务
example → [Normalize] → [Neural Network*] → [classification head] → prediction
*: Training.
- 用随机森林替换神经网络的头部(最后一层和 Softmax)。像往常一样训练随机森林
example → [Normalize] → [Neural Network] → [Random Forest*] → prediction
*: Training.
准备数据集
本示例使用 帕尔默企鹅 数据集。有关详细信息,请参阅 初学者协作。
首先,下载原始数据
wget -q https://storage.googleapis.com/download.tensorflow.org/data/palmer_penguins/penguins.csv -O /tmp/penguins.csv
将数据集加载到 Pandas 数据框中。
dataset_df = pd.read_csv("/tmp/penguins.csv")
# Display the first 3 examples.
dataset_df.head(3)
准备用于训练的数据集。
label = "species"
# Replaces numerical NaN (representing missing values in Pandas Dataframe) with 0s.
# ...Neural Nets don't work well with numerical NaNs.
for col in dataset_df.columns:
if dataset_df[col].dtype not in [str, object]:
dataset_df[col] = dataset_df[col].fillna(0)
# Split the dataset into a training and testing dataset.
def split_dataset(dataset, test_ratio=0.30):
"""Splits a panda dataframe in two."""
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples for testing.".format(
len(train_ds_pd), len(test_ds_pd)))
# Convert the datasets into tensorflow datasets
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_ds_pd, label=label)
248 examples in training, 96 examples for testing.
构建模型
接下来,使用 Keras 的函数式风格 创建神经网络模型。
为了使示例简单,此模型仅使用两个输入。
input_1 = tf_keras.Input(shape=(1,), name="bill_length_mm", dtype="float")
input_2 = tf_keras.Input(shape=(1,), name="island", dtype="string")
nn_raw_inputs = [input_1, input_2]
使用 预处理层 将原始输入转换为适合神经网络的输入。
# Normalization.
Normalization = tf_keras.layers.Normalization
CategoryEncoding = tf_keras.layers.CategoryEncoding
StringLookup = tf_keras.layers.StringLookup
values = train_ds_pd["bill_length_mm"].values[:, tf.newaxis]
input_1_normalizer = Normalization()
input_1_normalizer.adapt(values)
values = train_ds_pd["island"].values
input_2_indexer = StringLookup(max_tokens=32)
input_2_indexer.adapt(values)
input_2_onehot = CategoryEncoding(output_mode="binary", max_tokens=32)
normalized_input_1 = input_1_normalizer(input_1)
normalized_input_2 = input_2_onehot(input_2_indexer(input_2))
nn_processed_inputs = [normalized_input_1, normalized_input_2]
WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
构建神经网络的主体
y = tf_keras.layers.Concatenate()(nn_processed_inputs)
y = tf_keras.layers.Dense(16, activation=tf.nn.relu6)(y)
last_layer = tf_keras.layers.Dense(8, activation=tf.nn.relu, name="last")(y)
# "3" for the three label classes. If it were a binary classification, the
# output dim would be 1.
classification_output = tf_keras.layers.Dense(3)(y)
nn_model = tf_keras.models.Model(nn_raw_inputs, classification_output)
此 nn_model 直接生成分类 logits。
接下来,创建一个决策森林模型。它将对神经网络在最后一层提取的高级特征进行操作,然后再进行分类头部。
# To reduce the risk of mistakes, group both the decision forest and the
# neural network in a single keras model.
nn_without_head = tf_keras.models.Model(inputs=nn_model.inputs, outputs=last_layer)
df_and_nn_model = tfdf.keras.RandomForestModel(preprocessing=nn_without_head)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus. Use /tmpfs/tmp/tmpgsdeyzk5 as temporary training directory
训练和评估模型
模型将分两个阶段进行训练。首先训练神经网络及其自己的分类头部
%set_cell_height 300
nn_model.compile(
optimizer=tf_keras.optimizers.Adam(),
loss=tf_keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
nn_model.fit(x=train_ds, validation_data=test_ds, epochs=10)
nn_model.summary()
<IPython.core.display.Javascript object>
Epoch 1/10
/tmpfs/tmp/__autograph_generated_filetvdtpwer.py:63: UserWarning: Input dict contained keys ['bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex', 'year'] which did not match any model input. They will be ignored by the model.
ag__.converted_call(ag__.ld(warnings).warn, (ag__.converted_call('Input dict contained keys {} which did not match any model input. They will be ignored by the model.'.format, ([ag__.ld(n) for n in ag__.converted_call(ag__.ld(tensors).keys, (), None, fscope) if ag__.ld(n) not in ag__.ld(ref_input_names)],), None, fscope),), dict(stacklevel=2), fscope)
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1713611983.477059 22965 service.cc:145] XLA service 0x7ff3c4155d00 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1713611983.477103 22965 service.cc:153] StreamExecutor device (0): Tesla T4, Compute Capability 7.5
I0000 00:00:1713611983.477109 22965 service.cc:153] StreamExecutor device (1): Tesla T4, Compute Capability 7.5
I0000 00:00:1713611983.477112 22965 service.cc:153] StreamExecutor device (2): Tesla T4, Compute Capability 7.5
I0000 00:00:1713611983.477115 22965 service.cc:153] StreamExecutor device (3): Tesla T4, Compute Capability 7.5
I0000 00:00:1713611983.604064 22965 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1/1 [==============================] - 7s 7s/step - loss: 1.0737 - accuracy: 0.7137 - val_loss: 1.0569 - val_accuracy: 0.7500
Epoch 2/10
1/1 [==============================] - 0s 24ms/step - loss: 1.0696 - accuracy: 0.7177 - val_loss: 1.0529 - val_accuracy: 0.7500
Epoch 3/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0655 - accuracy: 0.7177 - val_loss: 1.0489 - val_accuracy: 0.7500
Epoch 4/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0614 - accuracy: 0.7218 - val_loss: 1.0450 - val_accuracy: 0.7500
Epoch 5/10
1/1 [==============================] - 0s 23ms/step - loss: 1.0574 - accuracy: 0.7258 - val_loss: 1.0410 - val_accuracy: 0.7500
Epoch 6/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0533 - accuracy: 0.7298 - val_loss: 1.0371 - val_accuracy: 0.7708
Epoch 7/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0494 - accuracy: 0.7339 - val_loss: 1.0332 - val_accuracy: 0.7708
Epoch 8/10
1/1 [==============================] - 0s 25ms/step - loss: 1.0454 - accuracy: 0.7379 - val_loss: 1.0293 - val_accuracy: 0.7708
Epoch 9/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0415 - accuracy: 0.7419 - val_loss: 1.0254 - val_accuracy: 0.7812
Epoch 10/10
1/1 [==============================] - 0s 22ms/step - loss: 1.0376 - accuracy: 0.7460 - val_loss: 1.0217 - val_accuracy: 0.7812
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
island (InputLayer) [(None, 1)] 0 []
bill_length_mm (InputLayer [(None, 1)] 0 []
)
string_lookup (StringLooku (None, 1) 0 ['island[0][0]']
p)
normalization (Normalizati (None, 1) 3 ['bill_length_mm[0][0]']
on)
category_encoding (Categor (None, 32) 0 ['string_lookup[0][0]']
yEncoding)
concatenate (Concatenate) (None, 33) 0 ['normalization[0][0]',
'category_encoding[0][0]']
dense (Dense) (None, 16) 544 ['concatenate[0][0]']
dense_1 (Dense) (None, 3) 51 ['dense[0][0]']
==================================================================================================
Total params: 598 (2.34 KB)
Trainable params: 595 (2.32 KB)
Non-trainable params: 3 (16.00 Byte)
__________________________________________________________________________________________________
神经网络层在两个模型之间共享。因此,现在神经网络已经过训练,决策森林模型将适合神经网络层的训练输出
%set_cell_height 300
df_and_nn_model.fit(x=train_ds)
<IPython.core.display.Javascript object> Reading training dataset... Training dataset read in 0:00:00.463558. Found 248 examples. Training model... Model trained in 0:00:00.043113 Compiling model... [INFO 24-04-20 11:19:45.0975 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpgsdeyzk5/model/ with prefix ac3d07af419249e2 [INFO 24-04-20 11:19:45.1138 UTC decision_forest.cc:734] Model loaded with 300 root(s), 5640 node(s), and 8 input feature(s). [INFO 24-04-20 11:19:45.1138 UTC abstract_model.cc:1344] Engine "RandomForestGeneric" built [INFO 24-04-20 11:19:45.1138 UTC kernel.cc:1061] Use fast generic engine Model compiled. <tf_keras.src.callbacks.History at 0x7ff3fc7e2ac0>
现在评估组合模型
df_and_nn_model.compile(metrics=["accuracy"])
print("Evaluation:", df_and_nn_model.evaluate(test_ds))
1/1 [==============================] - 0s 240ms/step - loss: 0.0000e+00 - accuracy: 0.9479 Evaluation: [0.0, 0.9479166865348816]
将其与单独的神经网络进行比较
print("Evaluation :", nn_model.evaluate(test_ds))
1/1 [==============================] - 0s 14ms/step - loss: 1.0217 - accuracy: 0.7812 Evaluation : [1.021651029586792, 0.78125]