
公平性指标旨在与更广泛的 Tensorflow 工具包合作,支持团队评估和改进模型以解决公平性问题。该工具目前在内部被我们许多产品积极使用,现在以 BETA 版本提供,供您尝试用于自己的用例。
什么是公平性指标?
公平性指标是一个库,它可以轻松计算二元和多类分类器的常见公平性指标。许多现有的评估公平性问题的工具在大型数据集和模型上效果不佳。在 Google,拥有可以在数十亿用户系统上运行的工具对我们来说至关重要。公平性指标将使您能够评估任何规模的用例。
特别是,公平性指标包括以下功能:
- 评估数据集的分布
- 评估模型性能,在定义的用户组中进行切片
- 使用置信区间和在多个阈值上的评估,对结果充满信心
- 深入研究各个切片,探索根本原因和改进机会
这个 案例研究,包含 视频 和编程练习,演示了如何在您自己的产品上使用公平性指标来评估一段时间内的公平性问题。

pip 包下载包括:
在 Tensorflow 模型中使用公平性指标
数据
要使用 TFMA 运行公平性指标,请确保评估数据集已针对您要按其进行切片的特征进行标记。如果您没有用于公平性问题的确切切片特征,您可以尝试找到包含这些特征的评估集,或者考虑特征集中可能突出显示结果差异的代理特征。有关更多指导,请参阅 此处。
模型
您可以使用 Tensorflow Estimator 类构建模型。对 Keras 模型的支持即将添加到 TFMA。如果您想在 Keras 模型上运行 TFMA,请参阅下面的“与模型无关的 TFMA”部分。
训练完 Estimator 后,您需要导出一个保存的模型以供评估。要了解更多信息,请参阅 TFMA 指南。
配置切片
接下来,定义您要评估的切片
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
如果您想评估交叉切片(例如,毛色和身高),您可以设置以下内容
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
计算公平性指标
将公平性指标回调添加到 metrics_callback 列表中。在回调中,您可以定义模型将在其上进行评估的阈值列表。
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
在运行配置之前,确定是否要启用置信区间的计算。置信区间使用泊松自举法计算,需要重新计算 20 个样本。
compute_confidence_intervals = True
运行 TFMA 评估管道
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
呈现公平性指标
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
使用公平性指标的提示
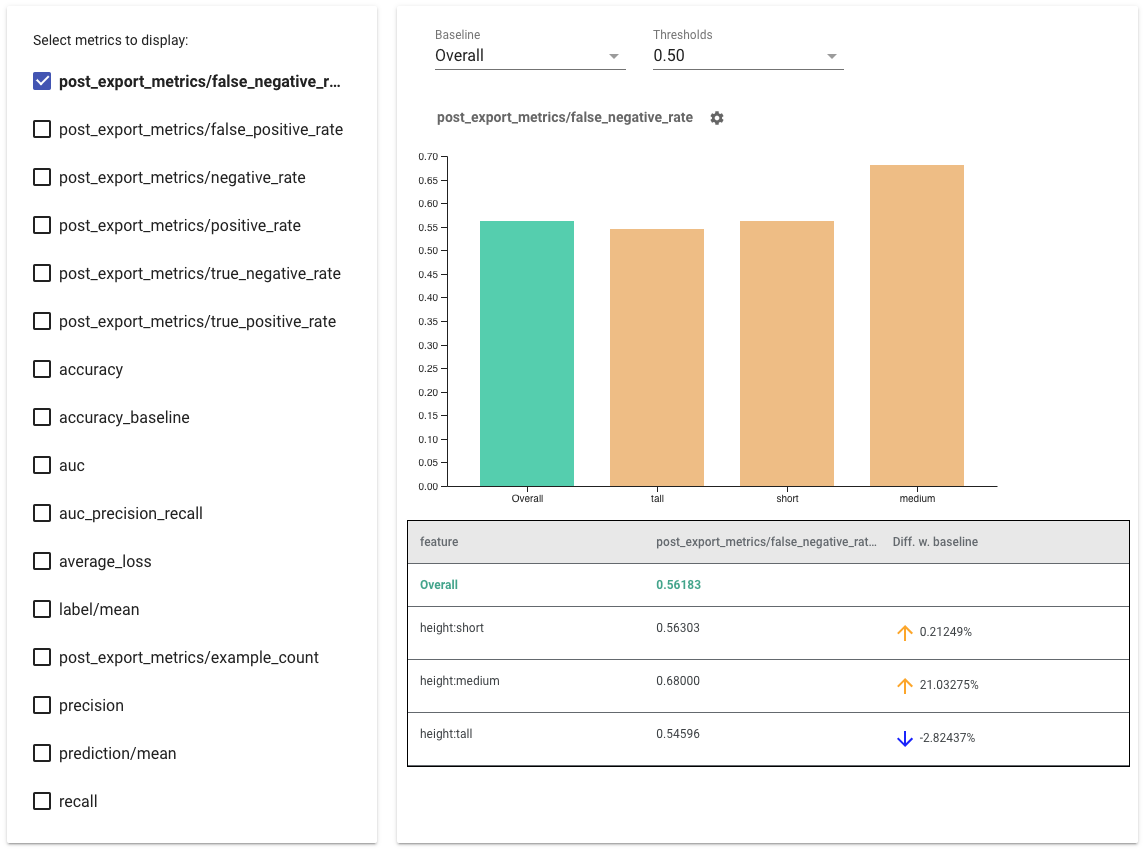
- 通过选中左侧的复选框来选择要显示的指标。每个指标的单独图表将按顺序出现在小部件中。
- 更改基线切片,即图表上的第一个条形,使用下拉选择器。增量将使用此基线值计算。
- 选择阈值,使用下拉选择器。您可以在同一个图表上查看多个阈值。选定的阈值将以粗体显示,您可以单击粗体阈值以取消选择它。
- 将鼠标悬停在条形上以查看该切片的指标。
- 使用“与基线的差异”列识别与基线的差异,该列标识当前切片与基线之间的百分比差异。
- 使用What-If 工具深入探索切片的 数据点。请参阅此处以获取示例。
渲染多个模型的公平性指标
公平性指标也可以用于比较模型。而不是传入单个 eval_result,而是传入一个 multi_eval_results 对象,它是一个字典,将两个模型名称映射到 eval_result 对象。
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
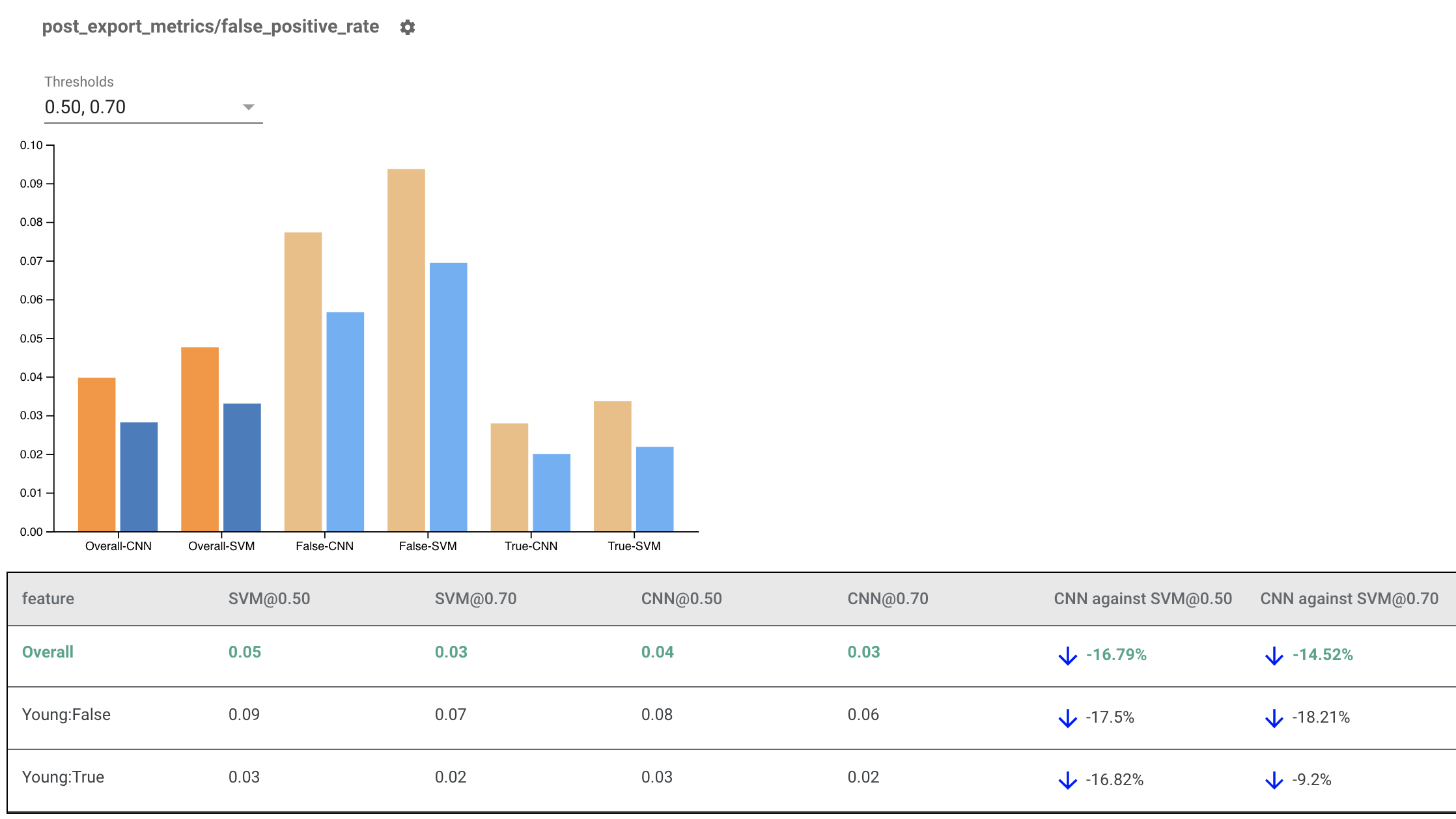
模型比较可以与阈值比较一起使用。例如,您可以比较两个模型在两组阈值下的表现,以找到最适合您的公平性指标的组合。
将公平性指标与非 TensorFlow 模型一起使用
为了更好地支持使用不同模型和工作流程的客户,我们开发了一个与被评估模型无关的评估库。
任何想要评估其机器学习系统的人都可以使用它,尤其是在您拥有非 TensorFlow 模型的情况下。使用 Apache Beam Python SDK,您可以创建一个独立的 TFMA 评估二进制文件,然后运行它来分析您的模型。
数据
此步骤是为了提供您希望评估运行的数据集。它应该采用tf.Example 协议缓冲区格式,其中包含标签、预测以及您可能想要切片的其他特征。
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
模型
您可以创建一个与模型无关的评估配置和提取器来解析和提供 TFMA 需要计算指标的数据,而不是指定模型。 ModelAgnosticConfig 规范定义了要从输入示例中使用的特征、预测和标签。
为此,请创建一个特征映射,其键表示所有特征(包括标签和预测键),值表示特征的数据类型。
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
使用标签键、预测键和特征映射创建一个与模型无关的配置。
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
设置与模型无关的提取器
Extractor 用于使用与模型无关的配置从输入中提取特征、标签和预测。如果您想对数据进行切片,您还需要定义切片键规范,其中包含有关您想要切片的列的信息。
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
计算公平性指标
作为EvalSharedModel的一部分,您可以提供您希望评估模型的所有指标。指标以指标回调的形式提供,例如在post_export_metrics或fairness_indicators中定义的指标回调。
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
它还接收一个construct_fn,用于创建执行评估的 TensorFlow 图。
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
一切设置好后,使用model_eval_lib提供的ExtractEvaluate 或 ExtractEvaluateAndWriteResults 函数之一来评估模型。
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
最后,使用上面“渲染公平性指标”部分中的说明渲染公平性指标。
更多示例
公平性指标示例目录包含多个示例
- Fairness_Indicators_Example_Colab.ipynb概述了TensorFlow 模型分析中的公平性指标以及如何在真实数据集上使用它。此笔记本还介绍了TensorFlow 数据验证和What-If 工具,这两个工具用于分析与公平性指标捆绑在一起的 TensorFlow 模型。
- Fairness_Indicators_on_TF_Hub.ipynb演示了如何使用公平性指标来比较在不同文本嵌入上训练的模型。此笔记本使用来自TensorFlow Hub(TensorFlow 的用于发布、发现和重用模型组件的库)的文本嵌入。
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb演示了如何在 TensorBoard 中可视化公平性指标。