
概述
TensorFlow 模型分析 (TFMA) 管道如下图所示
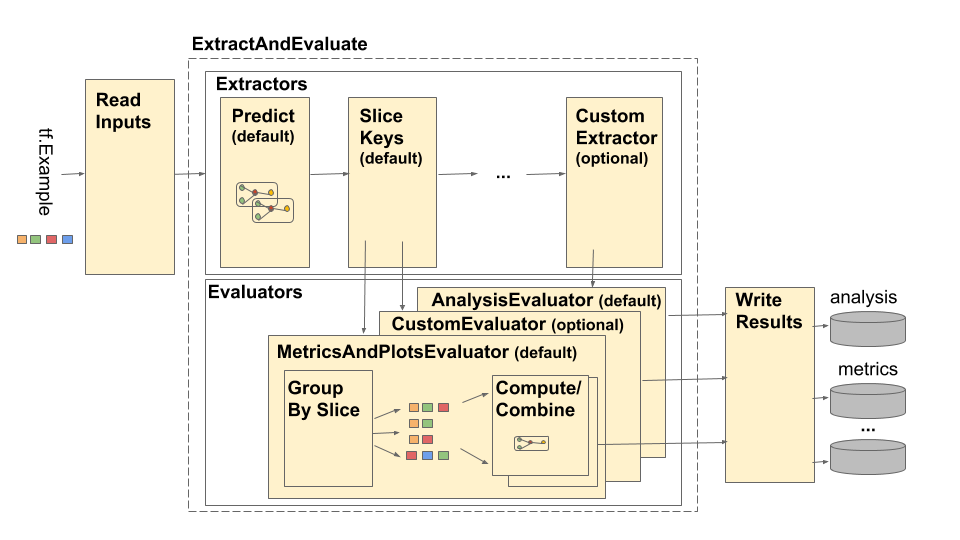
管道由四个主要组件组成
- 读取输入
- 提取
- 评估
- 写入结果
这些组件使用两种主要类型:tfma.Extracts 和 tfma.evaluators.Evaluation。类型 tfma.Extracts 代表在管道处理期间提取的数据,可能对应于模型的一个或多个示例。 tfma.evaluators.Evaluation 代表在提取过程中的各个点评估提取结果的输出。为了提供灵活的 API,这些类型只是字典,其中键由不同的实现定义(保留供使用)。类型定义如下
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
请注意,tfma.Extracts 永远不会直接写入,它们必须始终通过评估器来生成一个 tfma.evaluators.Evaluation,然后将其写入。还要注意,tfma.Extracts 是存储在 beam.pvalue.PCollection 中的字典(即 beam.PTransform 将 beam.pvalue.PCollection[tfma.Extracts] 作为输入),而 tfma.evaluators.Evaluation 是一个字典,其值是 beam.pvalue.PCollection(即 beam.PTransform 将字典本身作为 beam.value.PCollection 输入的参数)。换句话说,tfma.evaluators.Evaluation 用于管道构建时,而 tfma.Extracts 用于管道运行时。
读取输入
ReadInputs 阶段由一个转换组成,该转换接受原始输入(tf.train.Example、CSV 等)并将它们转换为提取结果。目前,提取结果表示为存储在 tfma.INPUT_KEY 下的原始输入字节,但是提取结果可以采用任何与提取管道兼容的形式——这意味着它创建 tfma.Extracts 作为输出,并且这些提取结果与下游提取器兼容。不同的提取器需要明确记录它们需要什么。
提取
提取过程是一系列按顺序运行的 beam.PTransform。提取器接受 tfma.Extracts 作为输入,并返回 tfma.Extracts 作为输出。典型的提取器是 tfma.extractors.PredictExtractor,它使用读取输入转换生成的输入提取结果,并将其通过模型运行以生成预测提取结果。可以将自定义提取器插入任何位置,前提是它们的转换符合 tfma.Extracts 输入和 tfma.Extracts 输出 API。提取器定义如下
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
InputExtractor
用于从 tf.train.Example 记录中提取原始特征、原始标签和原始示例权重,以便在指标切片和计算中使用。默认情况下,这些值分别存储在提取键 features、labels 和 example_weights 下。单输出模型标签和示例权重直接存储为 np.ndarray 值。多输出模型标签和示例权重存储为 np.ndarray 值的字典(以输出名称为键)。如果执行多模型评估,标签和示例权重将进一步嵌入另一个字典中(以模型名称为键)。
PredictExtractor
The tfma.extractors.PredictExtractor 运行模型预测并将它们存储在 tfma.Extracts 字典中的键 predictions 下。单输出模型预测直接存储为预测的输出值。多输出模型预测存储为输出值的字典(以输出名称为键)。如果执行多模型评估,预测将进一步嵌入另一个字典中(以模型名称为键)。使用的实际输出值取决于模型(例如,TF 估计器的返回输出以字典的形式,而 keras 返回 np.ndarray 值)。
SliceKeyExtractor
The tfma.extractors.SliceKeyExtractor 使用切片规范根据提取的特征确定哪些切片适用于每个示例输入,并将相应的切片值添加到提取中,以便评估器稍后使用。
评估
评估是获取提取并对其进行评估的过程。虽然通常在提取管道结束时执行评估,但有些用例需要在提取过程的早期执行评估。因此,评估器与它们应该对其输出进行评估的提取器相关联。评估器的定义如下:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
请注意,评估器是一个 beam.PTransform,它以 tfma.Extracts 作为输入。没有任何东西可以阻止实现作为评估过程的一部分对提取进行额外的转换。与必须返回 tfma.Extracts 字典的提取器不同,对评估器可以产生的输出类型没有限制,尽管大多数评估器也返回字典(例如,指标名称和值的字典)。
MetricsAndPlotsEvaluator
The tfma.evaluators.MetricsAndPlotsEvaluator 以 features、labels 和 predictions 作为输入,通过 tfma.slicer.FanoutSlices 运行它们以按切片对它们进行分组,然后执行指标和绘图计算。它以指标和绘图键和值的字典形式生成输出(这些输出稍后将转换为序列化协议缓冲区,以便由 tfma.writers.MetricsAndPlotsWriter 输出)。
写入结果
The WriteResults stage is where the evaluation output gets written out to disk. WriteResults uses writers to write out the data based on the output keys. For example, an tfma.evaluators.Evaluation may contain keys for metrics and plots. These would then be associated with the metrics and plots dictionaries called 'metrics' and 'plots'. The writers specify how to write out each file
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
We provide a tfma.writers.MetricsAndPlotsWriter that converts the metrics and plots dictionaries to serialized protos and writes them to disk.
If you wish to use a different serialization format, you can create a custom writer and use that instead. Since the tfma.evaluators.Evaluation passed to the writers contains the output for all of the evaluators combined, a tfma.writers.Write helper transform is provided that writers can use in their ptransform implementations to select the appropriate beam.PCollections based on an output key (see below for an example).
Customization
The tfma.run_model_analysis method takes extractors, evaluators, and writers arguments for customing the extractors, evaluators, and writers used by the pipeline. If no arguments are provided then tfma.default_extractors, tfma.default_evaluators, and tfma.default_writers are used by default.
Custom Extractors
To create a custom extractor, create a tfma.extractors.Extractor type that wraps a beam.PTransform taking tfma.Extracts as input and returning tfma.Extracts as output. Examples of extractors are available under tfma.extractors.
Custom Evaluators
To create a custom evaluator, create a tfma.evaluators.Evaluator type that wraps a beam.PTransform taking tfma.Extracts as input and returning tfma.evaluators.Evaluation as output. A very basic evaluator might just take the incoming tfma.Extracts and output them for storing in a table. This is exactly what the tfma.evaluators.AnalysisTableEvaluator does. A more complicated evaluator might perform additional processing and data aggregation. See the tfma.evaluators.MetricsAndPlotsEvaluator as an example.
Note that the tfma.evaluators.MetricsAndPlotsEvaluator itself can be customized to support custom metrics (see metrics for more details).
Custom Writers
To create a custom writer, create a tfma.writers.Writer type that wraps a beam.PTransform taking tfma.evaluators.Evaluation as input and returning beam.pvalue.PDone as output. The following is a basic example of a writer for writing out TFRecords containing metrics
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
A writer's inputs depend on the output of the associated evaluator. For the above example, the output is a serialized proto produced by the tfma.evaluators.MetricsAndPlotsEvaluator. A writer for the tfma.evaluators.AnalysisTableEvaluator would be responsible for writing out a beam.pvalue.PCollection of tfma.Extracts.
Note that a writer is associated with the output of an evaluator via the output key used (e.g. tfma.METRICS_KEY, tfma.ANALYSIS_KEY, etc).
Step by Step Example
The following is an example of the steps involved in the extraction and evaluation pipeline when both the tfma.evaluators.MetricsAndPlotsEvaluator and tfma.evaluators.AnalysisTableEvaluator are used
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files