
TensorFlow 数据验证 (TFDV) 可以分析训练和提供数据,以
核心 API 支持每个功能部分,并提供构建在其上且可以在笔记本上下文中调用的便捷方法。
计算描述性数据统计
TFDV 可以计算描述性 统计数据,这些统计数据可以快速概览数据,包括存在的特征及其值分布的形状。诸如 Facets Overview 等工具可以直观地显示这些统计数据,以便于浏览。
例如,假设 path 指向 TFRecord 格式的文件(其中包含 tensorflow.Example 类型的记录)。以下代码段说明了如何使用 TFDV 计算统计数据
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
返回的值是 DatasetFeatureStatisticsList 协议缓冲区。 示例笔记本 包含使用 Facets 概览 对统计数据进行可视化的内容
tfdv.visualize_statistics(stats)
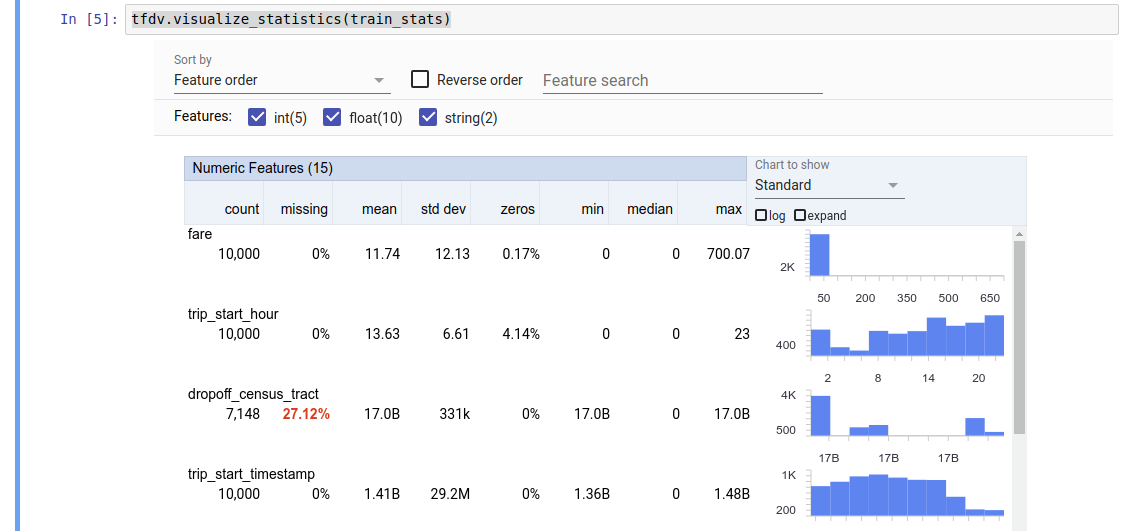
前面的示例假定数据存储在 TFRecord 文件中。TFDV 还支持 CSV 输入格式,并可扩展到其他常见格式。您可以在 此处 找到可用的数据解码器。此外,TFDV 为用户提供 tfdv.generate_statistics_from_dataframe 实用程序函数,用于将内存中的数据表示为 pandas DataFrame。
除了计算一组默认数据统计信息外,TFDV 还可以计算语义域(例如图像、文本)的统计信息。要启用语义域统计信息的计算,请将 tfdv.StatsOptions 对象与 enable_semantic_domain_stats 设置为 True 传递给 tfdv.generate_statistics_from_tfrecord。
在 Google Cloud 上运行
在内部,TFDV 使用 Apache Beam 的数据并行处理框架来扩展对大型数据集的统计信息计算。对于希望与 TFDV 更深入集成的应用程序(例如在数据生成管道末尾附加统计信息生成,生成自定义格式数据的统计信息),API 还公开了用于统计信息生成的 Beam PTransform。
要在 Google Cloud 上运行 TFDV,必须下载 TFDV 轮子文件并将其提供给 Dataflow 工作进程。按如下方式将轮子文件下载到当前目录
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
以下代码段显示了在 Google Cloud 上使用 TFDV 的示例用法
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
在这种情况下,生成的统计信息协议缓冲区存储在写入 GCS_STATS_OUTPUT_PATH 的 TFRecord 文件中。
注意在 Google Cloud 上调用任何 tfdv.generate_statistics_... 函数(例如 tfdv.generate_statistics_from_tfrecord)时,您必须提供 output_path。指定 None 可能导致错误。
推断数据上的架构
架构 描述了数据的预期属性。其中一些属性是
- 预期存在哪些特征
- 它们的类型
- 每个示例中某个特征的值的数量
- 所有示例中每个特征的存在性
- 特征的预期域。
简而言之,架构描述了对“正确”数据的期望,因此可用于检测数据中的错误(如下所述)。此外,可以使用同一架构来设置 TensorFlow Transform 以进行数据转换。请注意,架构应相当静态,例如,多个数据集可以符合同一架构,而统计信息(如上所述)因数据集而异。
由于编写架构可能是一项繁琐的任务,特别是对于具有大量特征的数据集,因此 TFDV 提供了一种基于描述性统计信息生成架构初始版本的方法
schema = tfdv.infer_schema(stats)
通常,TFDV 使用保守启发法从统计信息中推断稳定的数据属性,以避免架构对特定数据集过度拟合。强烈建议查看推断出的架构并根据需要对其进行细化,以捕获 TFDV 的启发法可能遗漏的有关数据的任何领域知识。
默认情况下,tfdv.infer_schema 推断每个必需特征的形状,如果 value_count.min 等于该特征的 value_count.max。将 infer_feature_shape 参数设置为 False 以禁用形状推断。
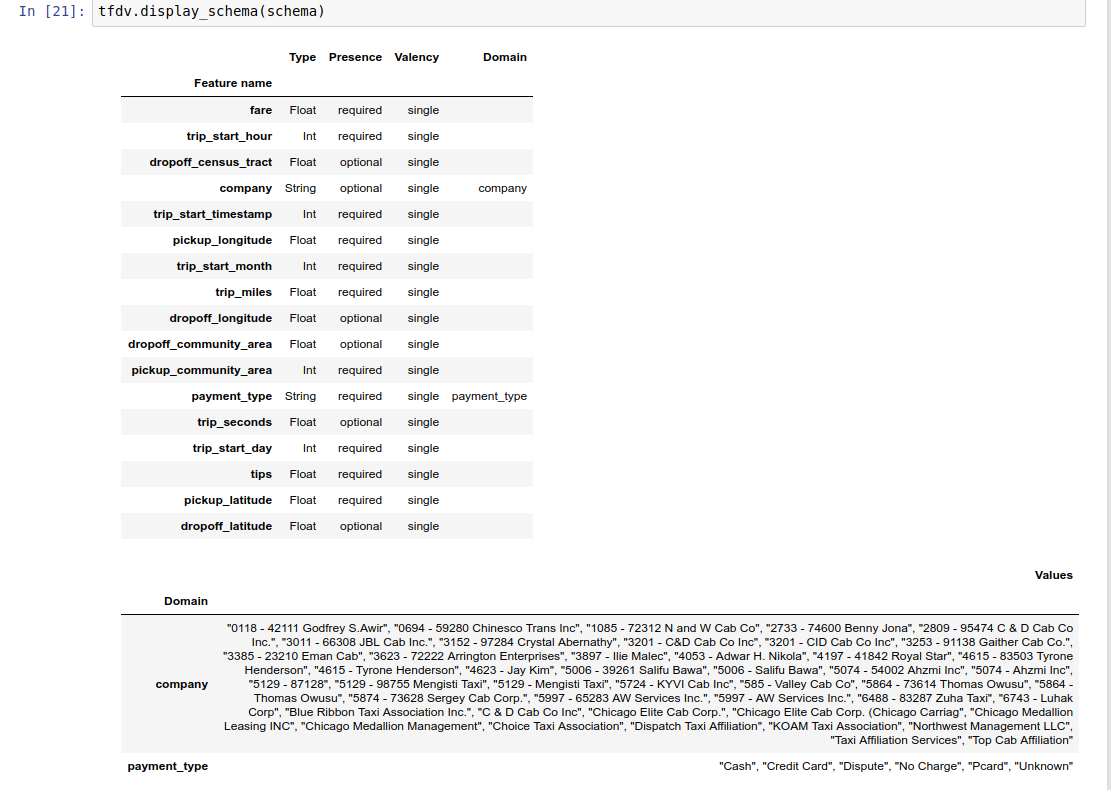
架构本身存储为 架构协议缓冲区,因此可以使用标准协议缓冲区 API 进行更新/编辑。TFDV 还提供了一些 实用程序方法 以简化这些更新。例如,假设架构包含以下内容来描述一个必需的字符串特征 payment_type,它采用一个值
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
要标记该特征应至少填充在 50% 的示例中
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
示例笔记本 包含架构的简单表格可视化,其中列出了每个特征及其在架构中编码的主要特征。
检查数据错误
给定一个架构,可以检查数据集是否符合架构中设定的预期,或是否存在任何 数据异常。您可以通过将数据集的统计信息与架构进行匹配,检查整个数据集中的错误 (a),或按示例检查错误 (b)。
将数据集的统计信息与架构进行匹配
要检查聚合中的错误,TFDV 会将数据集的统计信息与架构进行匹配,并标记任何差异。例如
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
结果是 Anomalies 协议缓冲区的实例,并描述统计信息与架构不一致的任何错误。例如,假设 other_path 中的数据包含特征 payment_type 的示例,其值超出架构中指定的域。
这会产生异常
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
表示在 < 1% 的特征值中找到了域外值。
如果这是预期的,则可以按如下方式更新架构
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
如果异常确实表示数据错误,则应在使用数据进行训练之前修复基础数据。
此模块可以检测到的各种异常类型在此处列出 here。
示例笔记本 包含异常的简单表格可视化,列出检测到错误的特征以及每个错误的简短描述。

按示例检查错误
TFDV 还提供按示例验证数据的选项,而不是将数据集范围的统计信息与架构进行比较。TFDV 提供按示例验证数据并生成找到的异常示例的汇总统计信息的函数。例如
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats 即 validate_examples_in_tfrecord 返回的 DatasetFeatureStatisticsList 协议缓冲区,其中每个数据集都包含表现出特定异常的示例集。您可以使用它来确定数据集中表现出给定异常的示例数以及这些示例的特征。
架构环境
默认情况下,验证假设管道中的所有数据集都遵循一个架构。在某些情况下,引入轻微的架构变化是必要的,例如在训练期间需要用作标签的特征(并且应该进行验证),但在提供服务期间却缺失。
环境可用于表达此类要求。特别是,架构中的特征可以使用 default_environment、in_environment 和 not_in_environment 与一组环境相关联。
例如,如果 tips 特征在训练中用作标签,但在提供服务的数据中缺失。如果没有指定环境,它将显示为异常。
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

要解决此问题,我们需要将所有特征的默认环境同时设置为“TRAINING”和“SERVING”,并将“tips”特征从 SERVING 环境中排除。
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
检查数据倾斜和漂移
除了检查数据集是否符合架构中设置的预期之外,TFDV 还提供检测以下内容的功能
- 训练数据和提供服务数据之间的倾斜
- 不同天训练数据之间的漂移
TFDV 通过根据架构中指定的漂移/倾斜比较器比较不同数据集的统计信息来执行此检查。例如,要检查训练数据集和提供服务的数据集中“payment_type”特征之间是否存在任何倾斜
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
注意 L-infinity 范数只会检测分类特征的倾斜。指定 infinity_norm 阈值,而不是在 skew_comparator 中指定 jensen_shannon_divergence 阈值,将检测数字特征和分类特征的倾斜。
与检查数据集是否符合架构中设置的预期相同,结果也是 Anomalies 协议缓冲区的一个实例,并描述了训练数据集和提供服务的数据集之间的任何倾斜。例如,假设提供服务的数据包含明显更多的示例,其中特征 payement_type 的值为 Cash,这会产生一个倾斜异常
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
如果异常确实表示训练数据和提供服务数据之间的倾斜,则需要进一步调查,因为这可能对模型性能产生直接影响。
示例笔记本包含检查基于倾斜的异常的简单示例。
可以类似地检测不同天训练数据之间的漂移
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
注意 L-infinity 范数只会检测分类特征的倾斜。指定 infinity_norm 阈值,而不是在 skew_comparator 中指定 jensen_shannon_divergence 阈值,将检测数字特征和分类特征的倾斜。
编写自定义数据连接器
为了计算数据统计信息,TFDV 提供了多种 便捷方法,用于处理各种格式的输入数据(例如 TFRecord 的 tf.train.Example、CSV 等)。如果您的数据格式不在此列表中,则需要编写一个自定义数据连接器来读取输入数据,并将其与 TFDV 核心 API 连接起来以计算数据统计信息。
用于计算数据统计信息的 TFDV 核心 API 是一个 Beam PTransform,它采用一个批次输入示例的 PCollection(一个批次的输入示例表示为一个 Arrow RecordBatch),并输出一个包含单个 DatasetFeatureStatisticsList 协议缓冲区的 PCollection。
在您实现将输入示例批处理到 Arrow RecordBatch 中的自定义数据连接器后,您需要将其与 tfdv.GenerateStatistics API 连接起来以计算数据统计信息。以 tf.train.Example 的 TFRecord 为例。 tfx_bsl 提供了 TFExampleRecord 数据连接器,下面是将其与 tfdv.GenerateStatistics API 连接起来的示例。
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
计算数据切片上的统计信息
可以将 TFDV 配置为计算数据切片上的统计信息。可以通过提供切片函数来启用切片,该函数采用一个 Arrow RecordBatch 并输出一系列形式为 (切片键,记录批次) 的元组。TFDV 提供了一种简单的方法来 生成基于特征值的切片函数,可以在计算统计信息时将其作为 tfdv.StatsOptions 的一部分提供。
启用切片后,输出 DatasetFeatureStatisticsList 协议包含多个 DatasetFeatureStatistics 协议,每个切片一个。每个切片都通过唯一名称进行标识,该名称设置为 DatasetFeatureStatistics 协议中的数据集名称。默认情况下,TFDV 会计算整个数据集的统计信息,以及配置的切片。
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])