
一般
EvalSavedModel 仍然需要吗?
以前 TFMA 要求所有指标都使用特殊的 EvalSavedModel 存储在 TensorFlow 图中。现在,指标可以使用 beam.CombineFn 实现计算在 TF 图之外。
一些主要区别是
EvalSavedModel需要来自训练器的特殊导出,而服务模型可以使用,无需对训练代码进行任何更改。- 当使用
EvalSavedModel时,在训练时添加的任何指标都会在评估时自动可用。如果没有EvalSavedModel,则必须重新添加这些指标。- 此规则的例外情况是,如果使用 keras 模型,则也可以自动添加指标,因为 keras 会将指标信息与保存的模型一起保存。
TFMA 可以同时使用图内指标和外部指标吗?
TFMA 允许使用混合方法,其中一些指标可以在图内计算,而另一些指标可以在图外计算。如果您当前有 EvalSavedModel,则可以继续使用它。
有两种情况
- 将 TFMA
EvalSavedModel用于特征提取和指标计算,但也添加额外的基于组合器的指标。在这种情况下,您将从EvalSavedModel获取所有图内指标,以及可能以前不支持的基于组合器的任何其他指标。 - 将 TFMA
EvalSavedModel用于特征/预测提取,但将基于组合器的指标用于所有指标计算。如果EvalSavedModel中存在要用于切片的特征转换,但您希望在图外执行所有指标计算,则此模式很有用。
设置
支持哪些模型类型?
TFMA 支持 keras 模型、基于通用 TF2 签名 API 的模型,以及基于 TF 估算器的模型(尽管根据用例,基于估算器的模型可能需要使用 EvalSavedModel)。
请参阅 入门 指南,了解支持的完整模型类型列表以及任何限制。
如何设置 TFMA 以与基于本机 keras 的模型一起使用?
以下是一个基于以下假设的 keras 模型的示例配置
- 保存的模型用于服务,并使用签名名称
serving_default(这可以使用model_specs[0].signature_name更改)。 - 应评估来自
model.compile(...)的内置指标(这可以通过 tfma.EvalConfig 中的options.include_default_metric禁用)。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
请参阅 指标,了解有关可以配置的其他指标类型的更多信息。
如何设置 TFMA 以与基于通用 TF2 签名的模型一起使用?
以下是通用 TF2 模型的示例配置。下面,signature_name 是用于评估的特定签名的名称。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
请参阅 指标,了解有关可以配置的其他指标类型的更多信息。
如何设置 TFMA 以与基于估算器的模型一起使用?
在这种情况下,有三种选择。
选项 1:使用服务模型
如果使用此选项,则在训练期间添加的任何指标都不会包含在评估中。
以下是一个示例配置,假设 serving_default 是使用的签名名称
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
请参阅 指标,了解有关可以配置的其他指标类型的更多信息。
选项 2:使用 EvalSavedModel 以及额外的基于组合器的指标
在这种情况下,使用 EvalSavedModel 进行特征/预测提取和评估,并添加额外的基于组合器的指标。
以下是一个示例配置
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
有关可以配置的其他类型指标的更多信息,请参阅 指标,有关设置 EvalSavedModel 的更多信息,请参阅 EvalSavedModel。
选项 3:仅将 EvalSavedModel 模型用于特征/预测提取
与选项 (2) 类似,但仅将 EvalSavedModel 用于特征/预测提取。如果只需要外部指标,但您希望对特征转换进行切片,则此选项很有用。与选项 (1) 类似,在训练期间添加的任何指标都不会包含在评估中。
在这种情况下,配置与上面相同,只是 include_default_metrics 被禁用。
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
有关可以配置的其他类型指标的更多信息,请参阅 指标,有关设置 EvalSavedModel 的更多信息,请参阅 EvalSavedModel。
如何设置 TFMA 以与基于 Keras 模型到估算器的模型一起使用?
Keras model_to_estimator 设置类似于估算器配置。但是,模型到估算器的工作方式有一些特定差异。特别是,模型到估算器以字典的形式返回其输出,其中字典键是关联 Keras 模型中最后一个输出层的名称(如果没有提供名称,Keras 将为您选择默认名称,例如 dense_1 或 output_1)。从 TFMA 的角度来看,这种行为类似于多输出模型的输出,即使模型到估算器可能只针对单个模型。为了解决这种差异,需要一个额外的步骤来设置输出名称。但是,与估算器一样,也适用三种选项。
以下是基于估算器的配置所需的更改示例
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
如何设置 TFMA 以与预先计算的(即与模型无关的)预测一起使用?(TFRecord 和 tf.Example)
为了将 TFMA 配置为与预先计算的预测一起使用,必须禁用默认的 tfma.PredictExtractor,并且必须配置 tfma.InputExtractor 以解析预测以及其他输入特征。这是通过配置一个 tfma.ModelSpec 来完成的,该配置包含用于预测的特征键的名称以及标签和权重。
以下是一个示例设置
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
有关可以配置的指标的更多信息,请参阅 指标。
请注意,虽然正在配置 tfma.ModelSpec,但实际上并没有使用模型(即没有 tfma.EvalSharedModel)。运行模型分析的调用可能如下所示
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
如何设置 TFMA 以与预先计算的(即与模型无关的)预测一起使用?(pd.DataFrame)
对于可以放入内存的小型数据集,TFRecord 的替代方法是 pandas.DataFrame。TFMA 可以使用 tfma.analyze_raw_data API 对 pandas.DataFrame 进行操作。有关 tfma.MetricsSpec 和 tfma.SlicingSpec 的解释,请参阅 设置 指南。有关可以配置的指标的更多信息,请参阅 指标。
以下是一个示例设置
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
指标
支持哪些类型的指标?
TFMA 支持多种指标,包括
是否支持多输出模型的指标?
是的。有关更多详细信息,请参阅 指标 指南。
是否支持来自多个模型的指标?
是的。有关更多详细信息,请参阅 指标 指南。
可以自定义指标设置(名称等)吗?
是的。可以通过在指标配置中添加 config 设置来自定义指标设置(例如,设置特定阈值等)。有关更多详细信息,请参阅 指标 指南。
是否支持自定义指标?
是的。可以通过编写自定义的 tf.keras.metrics.Metric 实现或编写自定义的 beam.CombineFn 实现来完成。有关更多详细信息,请参阅 指标 指南。
不支持哪些类型的指标?
只要您的指标可以使用 beam.CombineFn 计算,那么基于 tfma.metrics.Metric 可以计算的指标类型就没有限制。如果使用从 tf.keras.metrics.Metric 派生的指标,则必须满足以下条件
- 应该能够独立地为每个示例计算指标的充分统计量,然后通过将这些充分统计量加在一起跨所有示例进行组合,并仅从这些充分统计量确定指标值。
- 例如,对于准确率,充分统计量是“总正确”和“总示例”。可以为单个示例计算这两个数字,并将它们加起来以获得这些示例的正确值。可以使用“总正确 / 总示例”计算最终准确率。
附加组件
我可以使用 TFMA 来评估模型中的公平性或偏差吗?
TFMA 包含一个 FairnessIndicators 附加组件,它提供用于评估分类模型中意外偏差的影响的导出后指标。
自定义
如果我需要更多自定义怎么办?
TFMA 非常灵活,允许您使用自定义的 Extractors、Evaluators 和/或 Writers 来自定义管道的大部分内容。这些抽象在 架构 文档中进行了更详细的讨论。
故障排除、调试和获取帮助
为什么 MultiClassConfusionMatrix 指标与二值化 ConfusionMatrix 指标不匹配
这些实际上是不同的计算。二值化对每个类 ID 独立执行比较(即,每个类的预测分别与提供的阈值进行比较)。在这种情况下,两个或多个类都可能表明它们匹配了预测,因为它们的预测值大于阈值(这在较低的阈值下将更加明显)。在多类混淆矩阵的情况下,仍然只有一个真实的预测值,它要么与实际值匹配,要么不匹配。阈值仅用于强制预测在小于阈值时与任何类都不匹配。阈值越高,二值化类的预测越难匹配。同样,阈值越低,二值化类的预测越容易匹配。这意味着在阈值 > 0.5 时,二值化值和多类矩阵值将更接近,而在阈值 < 0.5 时,它们将相距更远。
例如,假设我们有 10 个类,其中类 2 的预测概率为 0.8,但实际类是类 1,其概率为 0.15。如果您对类 1 进行二值化并使用 0.1 的阈值,那么类 1 将被视为正确(0.15 > 0.1),因此它将被计为 TP。但是,对于多类情况,类 2 将被视为正确(0.8 > 0.1),并且由于类 1 是实际类,因此这将被计为 FN。由于在较低的阈值下,更多值将被视为正值,因此通常,二值化混淆矩阵的 TP 和 FP 计数将高于多类混淆矩阵,而 TN 和 FN 计数将更低。
以下是 MultiClassConfusionMatrixAtThresholds 与其中一个类的二值化结果的相应计数之间观察到的差异示例。
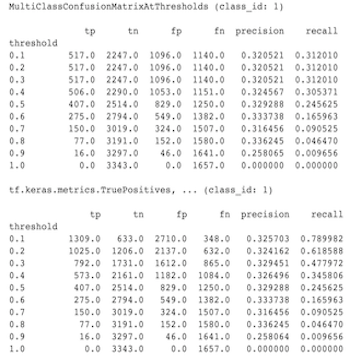
为什么我的 precision@1 和 recall@1 指标具有相同的值?
在 top k 值为 1 时,精确率和召回率是相同的。精确率等于 TP / (TP + FP),召回率等于 TP / (TP + FN)。最佳预测始终为正,并且要么与标签匹配,要么不匹配。换句话说,对于 N 个示例,TP + FP = N。但是,如果标签与最佳预测不匹配,那么这也意味着非最佳 k 预测匹配,并且当 top k 设置为 1 时,所有非最佳 1 预测将为 0。这意味着 FN 必须为 (N - TP) 或 N = TP + FN。最终结果是 precision@1 = TP / N = recall@1。请注意,这仅适用于每个示例只有一个标签的情况,不适用于多标签。
为什么我的 mean_label 和 mean_prediction 指标始终为 0.5?
这很可能是因为指标配置为二元分类问题,但模型输出的是两个类的概率,而不是只有一个。当使用 TensorFlow 的分类 API 时,这很常见。解决方案是选择您希望预测基于的类,然后对该类进行二值化。例如
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
如何解释 MultiLabelConfusionMatrixPlot?
给定一个特定的标签,MultiLabelConfusionMatrixPlot(以及相关的 MultiLabelConfusionMatrix)可用于比较其他标签的结果及其预测,前提是所选标签实际上为真。例如,假设我们有三个类别 bird、plane 和 superman,并且我们正在对图片进行分类以指示它们是否包含其中一个或多个类别。 MultiLabelConfusionMatrix 将计算每个实际类别与每个其他类别(称为预测类别)的笛卡尔积。请注意,虽然配对是 (actual, predicted),但 predicted 类别并不一定意味着正预测,它仅仅代表实际与预测矩阵中的预测列。例如,假设我们计算了以下矩阵
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot 有三种方式来显示这些数据。在所有情况下,阅读表格的方式都是从实际类别的角度逐行进行。
1) 总预测计数
在这种情况下,对于给定的行(即实际类别),其他类别的 TP + FP 计数是多少。对于上面的计数,我们的显示如下
| 预测鸟 | 预测飞机 | 预测超人 | |
|---|---|---|---|
| 实际鸟 | 6 | 4 | 2 |
| 实际飞机 | 4 | 4 | 4 |
| 实际超人 | 5 | 5 | 4 |
当图片实际上包含 bird 时,我们正确地预测了其中的 6 个。同时,我们还预测了 plane(正确或错误地)4 次,以及 superman(正确或错误地)2 次。
2) 错误预测计数
在这种情况下,对于给定的行(即实际类别),其他类别的 FP 计数是多少。对于上面的计数,我们的显示如下
| 预测鸟 | 预测飞机 | 预测超人 | |
|---|---|---|---|
| 实际鸟 | 0 | 2 | 1 |
| 实际飞机 | 1 | 0 | 3 |
| 实际超人 | 2 | 3 | 0 |
当图片实际上包含 bird 时,我们错误地预测了 plane 2 次,以及 superman 1 次。
3) 假阴性计数
在这种情况下,对于给定的行(即实际类别),其他类别的 FN 计数是多少。对于上面的计数,我们的显示如下
| 预测鸟 | 预测飞机 | 预测超人 | |
|---|---|---|---|
| 实际鸟 | 2 | 2 | 4 |
| 实际飞机 | 1 | 4 | 3 |
| 实际超人 | 2 | 2 | 5 |
当图片实际上包含 bird 时,我们未能预测它 2 次。同时,我们未能预测 plane 2 次,以及 superman 4 次。
为什么我收到关于预测键未找到的错误?
一些模型以字典的形式输出其预测。例如,用于二元分类问题的 TF 估计器输出包含 probabilities、class_ids 等的字典。在大多数情况下,TFMA 具有用于查找常用键名的默认值,例如 predictions、probabilities 等。但是,如果您的模型非常定制,它可能会在 TFMA 未知的名称下输出键。在这种情况下,必须在 tfma.ModelSpec 中添加 prediciton_key 设置以识别输出存储在其中的键的名称。