
ExampleGen TFX 管道组件将数据导入 TFX 管道。它使用外部文件/服务生成其他 TFX 组件将读取的示例。它还提供一致且可配置的分区,并为机器学习最佳实践对数据集进行混洗。
- 使用:来自外部数据源(如 CSV、
TFRecord、Avro、Parquet 和 BigQuery)的数据。 - 发出:
tf.Example记录、tf.SequenceExample记录或协议缓冲区格式,具体取决于有效负载格式。
ExampleGen 和其他组件
ExampleGen 为使用 TensorFlow 数据验证 库的组件提供数据,例如 SchemaGen、StatisticsGen 和 示例验证器。它还为 Transform 提供数据,Transform 使用 TensorFlow Transform 库,并最终在推理期间提供数据给部署目标。
数据源和格式
目前,TFX 的标准安装包含针对以下数据源和格式的完整 ExampleGen 组件
还提供自定义执行器,这些执行器支持为以下数据源和格式开发 ExampleGen 组件
有关如何使用和开发自定义执行器的更多信息,请参阅源代码中的使用示例和 此讨论。
此外,以下数据源和格式可作为 自定义组件 示例使用
导入 Apache Beam 支持的数据格式
Apache Beam 支持从 各种数据源和格式 导入数据(见下文)。这些功能可用于为 TFX 创建自定义 ExampleGen 组件,一些现有的 ExampleGen 组件已证明了这一点(见下文)。
如何使用 ExampleGen 组件
对于支持的数据源(目前包括 CSV 文件、包含 tf.Example 和 tf.SequenceExample 的 TFRecord 文件以及 proto 格式和 BigQuery 查询结果),ExampleGen 管道组件可以直接在部署中使用,并且需要很少的自定义。例如
example_gen = CsvExampleGen(input_base='data_root')
或者像下面这样直接导入包含 tf.Example 的外部 TFRecord
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
跨度、版本和拆分
跨度是训练示例的组合。如果您的数据保存在文件系统上,每个跨度可能存储在单独的目录中。跨度的语义没有硬编码到 TFX 中;跨度可能对应于一天的数据、一小时的数据或与您的任务相关的任何其他分组。
每个跨度可以包含多个数据版本。举个例子,如果您从跨度中删除一些示例以清理低质量数据,这可能会导致该跨度的新的版本。默认情况下,TFX 组件在跨度内的最新版本上运行。
跨度内的每个版本可以进一步细分为多个拆分。拆分跨度的最常见用例是将其拆分为训练数据和评估数据。
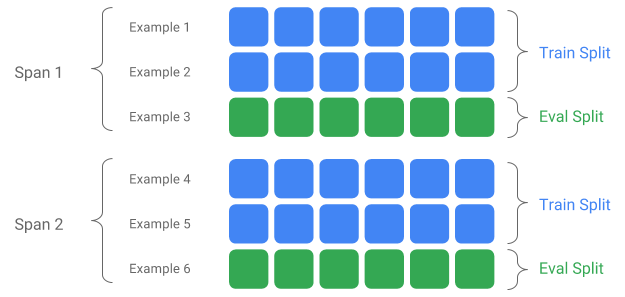
自定义输入/输出拆分
要自定义 ExampleGen 将输出的训练/评估拆分比率,请设置 ExampleGen 组件的 output_config。例如
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
注意在这个例子中如何设置 hash_buckets。
对于已经拆分的输入源,请设置 ExampleGen 组件的 input_config
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
对于基于文件的示例生成(例如 CsvExampleGen 和 ImportExampleGen),pattern 是一个相对于输入基路径的全局文件模式,它映射到具有输入基路径的输入文件。对于基于查询的示例生成(例如 BigQueryExampleGen、PrestoExampleGen),pattern 是一个 SQL 查询。
默认情况下,整个输入基目录被视为单个输入拆分,并且训练和评估输出拆分以 2:1 的比率生成。
请参考 proto/example_gen.proto 获取 ExampleGen 的输入和输出拆分配置。并参考 下游组件指南 以了解如何在下游使用自定义拆分。
拆分方法
当使用 hash_buckets 拆分方法时,可以使用特征而不是整个记录来对示例进行分区。如果存在特征,ExampleGen 将使用该特征的指纹作为分区键。
此功能可用于维护相对于示例某些属性的稳定拆分:例如,如果选择“user_id”作为分区特征名称,则用户将始终被放入相同的拆分中。
对“特征”的解释以及如何将“特征”与指定名称匹配取决于 ExampleGen 实现和示例的类型。
对于现成的 ExampleGen 实现
- 如果它生成 tf.Example,则“特征”表示 tf.Example.features.feature 中的条目。
- 如果它生成 tf.SequenceExample,则“特征”表示 tf.SequenceExample.context.feature 中的条目。
- 仅支持 int64 和 bytes 特征。
在以下情况下,ExampleGen 会抛出运行时错误
- 指定的特征名称在示例中不存在。
- 空特征:
tf.train.Feature(). - 不支持的特征类型,例如 float 特征。
要根据示例中的特征输出训练/评估拆分,请设置 ExampleGen 组件的 output_config。例如
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
注意在这个例子中如何设置 partition_feature_name。
跨度
跨度可以通过在 输入全局模式 中使用“{SPAN}”规范来检索
- 此规范匹配数字并将数据映射到相关的 SPAN 编号。例如,“data_{SPAN}-*.tfrecord”将收集像“data_12-a.tfrecord”、“data_12-b.tfrecord”这样的文件。
- 可选地,此规范可以在映射时指定整数的宽度。例如,“data_{SPAN:2}.file”映射到像“data_02.file”和“data_27.file”这样的文件(分别作为 Span-2 和 Span-27 的输入),但不映射到“data_1.file”或“data_123.file”。
- 当 SPAN 规范缺失时,它被假定为始终是 Span '0'。
- 如果指定了 SPAN,管道将处理最新的跨度,并将跨度编号存储在元数据中。
例如,假设存在输入数据
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
并且输入配置如下所示
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
当触发管道时,它将处理
- '/tmp/span-2/train/data' 作为训练拆分
- '/tmp/span-2/eval/data' 作为评估拆分
跨度编号为“2”。如果稍后 '/tmp/span-3/...' 准备就绪,只需再次触发管道,它将选择跨度“3”进行处理。以下是使用跨度规范的代码示例
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
可以使用 RangeConfig 检索特定跨度,该配置将在下面详细介绍。
日期
如果您的数据源按日期在文件系统上组织,TFX 支持将日期直接映射到跨度编号。有三个规范来表示从日期到跨度的映射:{YYYY}、{MM} 和 {DD}
- 如果指定了任何规范,则这三个规范应该全部出现在 输入全局模式 中
- 只能指定 {SPAN} 规范或这组日期规范。
- 计算一个日历日期,其中年份来自 YYYY,月份来自 MM,月份中的日期来自 DD,然后将跨度编号计算为自 Unix 纪元(即 1970-01-01)以来的天数。例如,“log-{YYYY}{MM}{DD}.data”匹配文件“log-19700101.data”并将其作为 Span-0 的输入使用,并将“log-20170101.data”作为 Span-17167 的输入使用。
- 如果指定了这组日期规范,管道将处理最新的日期,并将相应的跨度编号存储在元数据中。
例如,假设存在按日历日期组织的输入数据
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
并且输入配置如下所示
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
当触发管道时,它将处理
- '/tmp/1970-01-03/train/data' 作为训练拆分
- '/tmp/1970-01-03/eval/data' 作为评估拆分
跨度编号为“2”。如果稍后 '/tmp/1970-01-04/...' 准备就绪,只需再次触发管道,它将选择跨度“3”进行处理。以下是使用日期规范的代码示例
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
版本
版本可以通过在 输入全局模式 中使用“{VERSION}”规范来检索
- 此规范匹配数字并将数据映射到 SPAN 下的相关 VERSION 编号。请注意,VERSION 规范可以与 Span 或 Date 规范组合使用。
- 此规范也可以可选地以与 SPAN 规范相同的方式指定宽度。例如,“span-{SPAN}/version-{VERSION:4}/data-*”。
- 当 VERSION 规范缺失时,版本被设置为 None。
- 如果同时指定了 SPAN 和 VERSION,管道将处理最新跨度的最新版本,并将版本编号存储在元数据中。
- 如果指定了 VERSION,但没有指定 SPAN(或日期规范),则会抛出错误。
例如,假设存在输入数据
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
并且输入配置如下所示
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
当触发管道时,它将处理
- '/tmp/span-2/ver-2/train/data' 作为训练拆分
- '/tmp/span-2/ver-2/eval/data' 作为评估拆分
跨度编号为“2”,版本编号为“2”。如果稍后 '/tmp/span-2/ver-3/...' 准备就绪,只需再次触发管道,它将选择跨度“2”和版本“3”进行处理。以下是使用版本规范的代码示例
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
范围配置
TFX 支持使用范围配置检索和处理基于文件的 ExampleGen 中的特定跨度,范围配置是用于描述不同 TFX 实体范围的抽象配置。要检索特定跨度,请设置基于文件的 ExampleGen 组件的 range_config。例如,假设存在输入数据
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
要专门检索和处理跨度“1”的数据,我们在输入配置之外指定一个范围配置。请注意,ExampleGen 仅支持单跨度静态范围(以指定对特定单个跨度的处理)。因此,对于 StaticRange,start_span_number 必须等于 end_span_number。使用提供的跨度和跨度宽度信息(如果提供)进行零填充,ExampleGen 将使用所需的跨度编号替换提供的拆分模式中的 SPAN 规范。以下是使用示例
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
如果使用日期规范而不是 SPAN 规范,范围配置也可以用于处理特定日期。例如,假设存在按日历日期组织的输入数据
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
要专门检索和处理 1970 年 1 月 2 日的数据,我们执行以下操作
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
自定义 ExampleGen
如果当前可用的 ExampleGen 组件不符合您的需求,您可以创建自定义 ExampleGen,这将使您能够从不同的数据源或不同的数据格式中读取数据。
基于文件的 ExampleGen 自定义(实验性)
首先,使用自定义 Beam PTransform 扩展 BaseExampleGenExecutor,该 PTransform 提供从您的训练/评估输入拆分到 TF 示例的转换。例如,CsvExampleGen 执行器 提供从输入 CSV 拆分到 TF 示例的转换。
然后,使用上面的执行器创建一个组件,就像在 CsvExampleGen 组件 中所做的那样。或者,将自定义执行器传递到标准 ExampleGen 组件中,如下所示。
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
现在,我们还支持使用此 方法 读取 Avro 和 Parquet 文件。
其他数据格式
Apache Beam 支持通过 Beam I/O 转换读取许多 其他数据格式。您可以通过利用 Beam I/O 转换并使用类似于 Avro 示例 的模式来创建自定义 ExampleGen 组件
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
截至撰写本文时,Beam Python SDK 当前支持的格式和数据源包括
- Amazon S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Apache Parquet
- Google Cloud BigQuery
- Google Cloud BigTable
- Google Cloud Datastore
- Google Cloud Pub/Sub
- Google Cloud Storage (GCS)
- MongoDB
查看 Beam 文档 获取最新列表。
基于查询的 ExampleGen 自定义(实验性)
首先,使用自定义 Beam PTransform 扩展 BaseExampleGenExecutor,该 PTransform 从外部数据源读取数据。然后,通过扩展 QueryBasedExampleGen 创建一个简单组件。
这可能需要或不需要额外的连接配置。例如,BigQuery 执行器 使用默认的 beam.io 连接器读取数据,该连接器抽象了连接配置细节。而 Presto 执行器 需要一个自定义 Beam PTransform 和一个 自定义连接配置 protobuf 作为输入。
如果自定义 ExampleGen 组件需要连接配置,请创建一个新的 protobuf 并通过 custom_config 传入,custom_config 现在是一个可选的执行参数。以下是如何使用已配置组件的示例。
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ExampleGen 下游组件
下游组件支持自定义拆分配置。
StatisticsGen
默认行为是对所有拆分执行统计信息生成。
要排除任何拆分,请为 StatisticsGen 组件设置 exclude_splits。例如
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
默认行为是根据所有拆分生成模式。
要排除任何拆分,请为 SchemaGen 组件设置 exclude_splits。例如
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ExampleValidator
默认行为是根据模式验证输入示例中所有拆分的统计信息。
要排除任何拆分,请为 ExampleValidator 组件设置 exclude_splits。例如
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Transform
默认行为是分析并从“train”拆分中生成元数据,并转换所有拆分。
要指定分析拆分和转换拆分,请为 Transform 组件设置 splits_config。例如
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
训练器和调优器
默认行为是在“train”拆分上训练,并在“eval”拆分上评估。
要指定训练拆分和评估拆分,请为 Trainer 组件设置 train_args 和 eval_args。例如
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Evaluator
默认行为是提供在“eval”拆分上计算的指标。
要在自定义拆分上计算评估统计信息,请为 Evaluator 组件设置 example_splits。例如
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
更多详细信息请参见 CsvExampleGen API 参考、FileBasedExampleGen API 实现 和 ImportExampleGen API 参考。