
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
import tensorflow as tf
import numpy as np
2023-10-28 01:21:58.219231: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-10-28 01:21:58.219277: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-10-28 01:21:58.220822: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
张量是具有统一类型(称为 dtype)的多维数组。您可以在 tf.dtypes 查看所有支持的 dtypes。
如果您熟悉 NumPy,张量(有点像) np.arrays。
所有张量都是不可变的,就像 Python 数字和字符串一样:您永远无法更新张量的内容,只能创建一个新的张量。
基础
首先,创建一些基本张量。
这是一个“标量”或“秩 0”张量。标量包含单个值,没有“轴”。
# This will be an int32 tensor by default; see "dtypes" below.
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)
tf.Tensor(4, shape=(), dtype=int32)
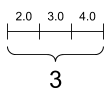
一个“向量”或“秩 1”张量就像一个值列表。向量有一个轴
# Let's make this a float tensor.
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)
tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)
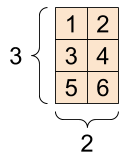
一个“矩阵”或“秩 2”张量有两个轴
# If you want to be specific, you can set the dtype (see below) at creation time
rank_2_tensor = tf.constant([[1, 2],
[3, 4],
[5, 6]], dtype=tf.float16)
print(rank_2_tensor)
tf.Tensor( [[1. 2.] [3. 4.] [5. 6.]], shape=(3, 2), dtype=float16)
一个标量,形状:[] |
一个向量,形状:[3] |
一个矩阵,形状:[3, 2] |
|---|---|---|

|
|
|
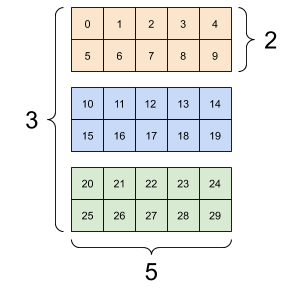
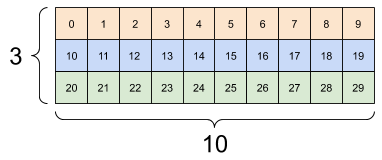
张量可能有多个轴;这是一个具有三个轴的张量
# There can be an arbitrary number of
# axes (sometimes called "dimensions")
rank_3_tensor = tf.constant([
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]],])
print(rank_3_tensor)
tf.Tensor( [[[ 0 1 2 3 4] [ 5 6 7 8 9]] [[10 11 12 13 14] [15 16 17 18 19]] [[20 21 22 23 24] [25 26 27 28 29]]], shape=(3, 2, 5), dtype=int32)
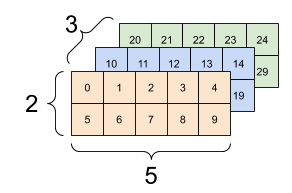
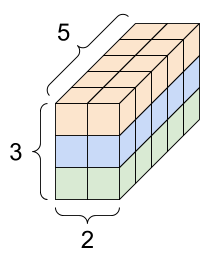
有很多方法可以可视化具有两个以上轴的张量。
一个 3 轴张量,形状:[3, 2, 5] |
||
|---|---|---|
|
|
|
您可以使用 np.array 或 tensor.numpy 方法将张量转换为 NumPy 数组
np.array(rank_2_tensor)
array([[1., 2.],
[3., 4.],
[5., 6.]], dtype=float16)
rank_2_tensor.numpy()
array([[1., 2.],
[3., 4.],
[5., 6.]], dtype=float16)
张量通常包含浮点数和整数,但还有许多其他类型,包括
- 复数
- 字符串
基本 tf.Tensor 类要求张量为“矩形”——也就是说,沿着每个轴,每个元素的大小都相同。但是,有一些专门类型的张量可以处理不同的形状
- 不规则张量(参见下面的 RaggedTensor)
- 稀疏张量(参见下面的 SparseTensor)
您可以对张量进行基本数学运算,包括加法、逐元素乘法和矩阵乘法。
a = tf.constant([[1, 2],
[3, 4]])
b = tf.constant([[1, 1],
[1, 1]]) # Could have also said `tf.ones([2,2], dtype=tf.int32)`
print(tf.add(a, b), "\n")
print(tf.multiply(a, b), "\n")
print(tf.matmul(a, b), "\n")
tf.Tensor( [[2 3] [4 5]], shape=(2, 2), dtype=int32) tf.Tensor( [[1 2] [3 4]], shape=(2, 2), dtype=int32) tf.Tensor( [[3 3] [7 7]], shape=(2, 2), dtype=int32)
print(a + b, "\n") # element-wise addition
print(a * b, "\n") # element-wise multiplication
print(a @ b, "\n") # matrix multiplication
tf.Tensor( [[2 3] [4 5]], shape=(2, 2), dtype=int32) tf.Tensor( [[1 2] [3 4]], shape=(2, 2), dtype=int32) tf.Tensor( [[3 3] [7 7]], shape=(2, 2), dtype=int32)
张量用于各种操作(或“操作”)。
c = tf.constant([[4.0, 5.0], [10.0, 1.0]])
# Find the largest value
print(tf.reduce_max(c))
# Find the index of the largest value
print(tf.math.argmax(c))
# Compute the softmax
print(tf.nn.softmax(c))
tf.Tensor(10.0, shape=(), dtype=float32) tf.Tensor([1 0], shape=(2,), dtype=int64) tf.Tensor( [[2.6894143e-01 7.3105854e-01] [9.9987662e-01 1.2339458e-04]], shape=(2, 2), dtype=float32)
tf.convert_to_tensor([1,2,3])
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 2, 3], dtype=int32)>
tf.reduce_max([1,2,3])
<tf.Tensor: shape=(), dtype=int32, numpy=3>
tf.reduce_max(np.array([1,2,3]))
<tf.Tensor: shape=(), dtype=int64, numpy=3>
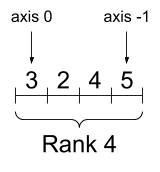
关于形状
张量有形状。一些词汇
- 形状:张量每个轴的长度(元素数量)。
- 秩:张量轴的数量。标量秩为 0,向量秩为 1,矩阵秩为 2。
- 轴或维度:张量的特定维度。
- 大小:张量中项目的总数,即形状向量元素的乘积。
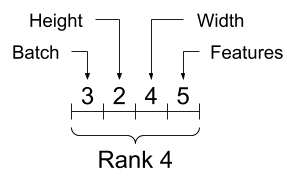
张量和 tf.TensorShape 对象具有方便的属性来访问这些
rank_4_tensor = tf.zeros([3, 2, 4, 5])
一个秩为 4 的张量,形状:[3, 2, 4, 5] |
|
|---|---|
|
|
print("Type of every element:", rank_4_tensor.dtype)
print("Number of axes:", rank_4_tensor.ndim)
print("Shape of tensor:", rank_4_tensor.shape)
print("Elements along axis 0 of tensor:", rank_4_tensor.shape[0])
print("Elements along the last axis of tensor:", rank_4_tensor.shape[-1])
print("Total number of elements (3*2*4*5): ", tf.size(rank_4_tensor).numpy())
Type of every element: <dtype: 'float32'> Number of axes: 4 Shape of tensor: (3, 2, 4, 5) Elements along axis 0 of tensor: 3 Elements along the last axis of tensor: 5 Total number of elements (3*2*4*5): 120
但请注意,Tensor.ndim 和 Tensor.shape 属性不会返回 Tensor 对象。如果您需要一个 Tensor,请使用 tf.rank 或 tf.shape 函数。这种差异很细微,但在构建图(稍后)时可能很重要。
tf.rank(rank_4_tensor)
<tf.Tensor: shape=(), dtype=int32, numpy=4>
tf.shape(rank_4_tensor)
<tf.Tensor: shape=(4,), dtype=int32, numpy=array([3, 2, 4, 5], dtype=int32)>
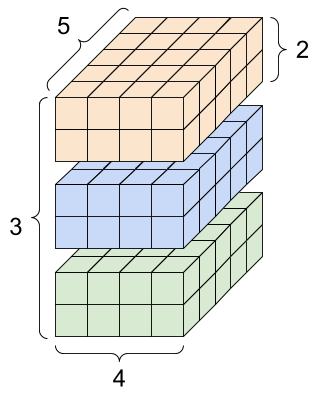
虽然轴通常通过它们的索引来引用,但您应该始终跟踪每个轴的含义。轴通常按从全局到局部的顺序排列:首先是批次轴,然后是空间维度,最后是每个位置的特征。这样,特征向量就是内存中连续的区域。
| 典型的轴顺序 |
|---|
|
索引
单轴索引
TensorFlow 遵循标准的 Python 索引规则,类似于 在 Python 中索引列表或字符串,以及 NumPy 索引的基本规则。
- 索引从
0开始 - 负索引从末尾开始反向计数
- 冒号,
:,用于切片:start:stop:step
rank_1_tensor = tf.constant([0, 1, 1, 2, 3, 5, 8, 13, 21, 34])
print(rank_1_tensor.numpy())
[ 0 1 1 2 3 5 8 13 21 34]
用标量索引会移除轴
print("First:", rank_1_tensor[0].numpy())
print("Second:", rank_1_tensor[1].numpy())
print("Last:", rank_1_tensor[-1].numpy())
First: 0 Second: 1 Last: 34
用 : 切片索引会保留轴
print("Everything:", rank_1_tensor[:].numpy())
print("Before 4:", rank_1_tensor[:4].numpy())
print("From 4 to the end:", rank_1_tensor[4:].numpy())
print("From 2, before 7:", rank_1_tensor[2:7].numpy())
print("Every other item:", rank_1_tensor[::2].numpy())
print("Reversed:", rank_1_tensor[::-1].numpy())
Everything: [ 0 1 1 2 3 5 8 13 21 34] Before 4: [0 1 1 2] From 4 to the end: [ 3 5 8 13 21 34] From 2, before 7: [1 2 3 5 8] Every other item: [ 0 1 3 8 21] Reversed: [34 21 13 8 5 3 2 1 1 0]
多轴索引
更高秩的张量通过传递多个索引来索引。
与单轴情况完全相同的规则独立地应用于每个轴。
print(rank_2_tensor.numpy())
[[1. 2.] [3. 4.] [5. 6.]]
为每个索引传递一个整数,结果是一个标量。
# Pull out a single value from a 2-rank tensor
print(rank_2_tensor[1, 1].numpy())
4.0
您可以使用整数和切片的任意组合进行索引
# Get row and column tensors
print("Second row:", rank_2_tensor[1, :].numpy())
print("Second column:", rank_2_tensor[:, 1].numpy())
print("Last row:", rank_2_tensor[-1, :].numpy())
print("First item in last column:", rank_2_tensor[0, -1].numpy())
print("Skip the first row:")
print(rank_2_tensor[1:, :].numpy(), "\n")
Second row: [3. 4.] Second column: [2. 4. 6.] Last row: [5. 6.] First item in last column: 2.0 Skip the first row: [[3. 4.] [5. 6.]]
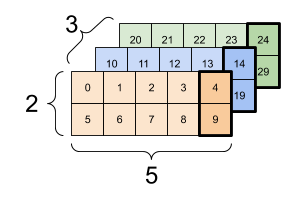
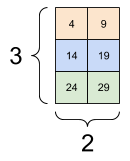
以下是一个使用 3 轴张量的示例
print(rank_3_tensor[:, :, 4])
tf.Tensor( [[ 4 9] [14 19] [24 29]], shape=(3, 2), dtype=int32)
| 选择批次中每个示例中所有位置的最后一个特征 | |
|---|---|
|
|
阅读 张量切片指南,了解如何应用索引来操作张量中的单个元素。
操作形状
重新整形张量非常有用。
# Shape returns a `TensorShape` object that shows the size along each axis
x = tf.constant([[1], [2], [3]])
print(x.shape)
(3, 1)
# You can convert this object into a Python list, too
print(x.shape.as_list())
[3, 1]
您可以将张量重新整形为新的形状。 tf.reshape 操作速度快且成本低,因为底层数据不需要复制。
# You can reshape a tensor to a new shape.
# Note that you're passing in a list
reshaped = tf.reshape(x, [1, 3])
print(x.shape)
print(reshaped.shape)
(3, 1) (1, 3)
数据在内存中保持其布局,并创建一个具有请求形状的新张量,指向相同的数据。TensorFlow 使用 C 样式的“行优先”内存排序,其中递增最右边的索引对应于内存中的单个步长。
print(rank_3_tensor)
tf.Tensor( [[[ 0 1 2 3 4] [ 5 6 7 8 9]] [[10 11 12 13 14] [15 16 17 18 19]] [[20 21 22 23 24] [25 26 27 28 29]]], shape=(3, 2, 5), dtype=int32)
如果您展平一个张量,您可以看到它在内存中的布局顺序。
# A `-1` passed in the `shape` argument says "Whatever fits".
print(tf.reshape(rank_3_tensor, [-1]))
tf.Tensor( [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29], shape=(30,), dtype=int32)
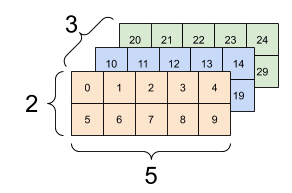
通常, tf.reshape 的唯一合理用途是合并或拆分相邻轴(或添加/删除 1)。
对于这个 3x2x5 张量,重新整形为 (3x2)x5 或 3x(2x5) 都是合理的做法,因为切片不会混合
print(tf.reshape(rank_3_tensor, [3*2, 5]), "\n")
print(tf.reshape(rank_3_tensor, [3, -1]))
tf.Tensor( [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14] [15 16 17 18 19] [20 21 22 23 24] [25 26 27 28 29]], shape=(6, 5), dtype=int32) tf.Tensor( [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29]], shape=(3, 10), dtype=int32)
| 一些好的重新整形。 | ||
|---|---|---|
|
|
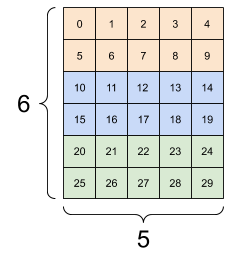
|
重新整形将“适用于”任何具有相同元素总数的新形状,但如果您不尊重轴的顺序,它将不会做任何有用的事情。
在 tf.reshape 中交换轴不起作用;您需要 tf.transpose 来实现这一点。
# Bad examples: don't do this
# You can't reorder axes with reshape.
print(tf.reshape(rank_3_tensor, [2, 3, 5]), "\n")
# This is a mess
print(tf.reshape(rank_3_tensor, [5, 6]), "\n")
# This doesn't work at all
try:
tf.reshape(rank_3_tensor, [7, -1])
except Exception as e:
print(f"{type(e).__name__}: {e}")
tf.Tensor(
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]]], shape=(2, 3, 5), dtype=int32)
tf.Tensor(
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]], shape=(5, 6), dtype=int32)
InvalidArgumentError: { {function_node __wrapped__Reshape_device_/job:localhost/replica:0/task:0/device:GPU:0} } Input to reshape is a tensor with 30 values, but the requested shape requires a multiple of 7 [Op:Reshape]
| 一些不好的重新整形。 | ||
|---|---|---|
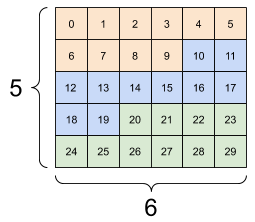
|
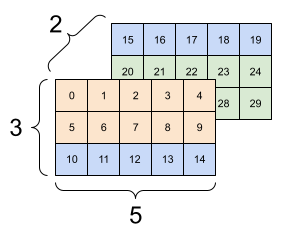
|

|
您可能会遇到未完全指定的形状。要么形状包含一个 None(轴长度未知),要么整个形状为 None(张量的秩未知)。
除了 tf.RaggedTensor 之外,此类形状只会出现在 TensorFlow 的符号式图构建 API 的上下文中
更多关于 DTypes 的内容
要检查 tf.Tensor 的数据类型,请使用 Tensor.dtype 属性。
从 Python 对象创建 tf.Tensor 时,您可以选择指定数据类型。
如果您不指定,TensorFlow 会选择一个可以表示您的数据的类型。TensorFlow 将 Python 整数转换为 tf.int32,将 Python 浮点数转换为 tf.float32。否则,TensorFlow 会使用 NumPy 在转换为数组时使用的相同规则。
您可以从一种类型转换为另一种类型。
the_f64_tensor = tf.constant([2.2, 3.3, 4.4], dtype=tf.float64)
the_f16_tensor = tf.cast(the_f64_tensor, dtype=tf.float16)
# Now, cast to an uint8 and lose the decimal precision
the_u8_tensor = tf.cast(the_f16_tensor, dtype=tf.uint8)
print(the_u8_tensor)
tf.Tensor([2 3 4], shape=(3,), dtype=uint8)
广播
广播是从 NumPy 中的等效功能 中借鉴的概念。简而言之,在某些条件下,当对较小的张量执行组合操作时,较小的张量会自动“拉伸”以适应较大的张量。
最简单也是最常见的情况是,当您尝试将张量乘以或加到标量时。在这种情况下,标量将广播为与另一个参数相同的形状。
x = tf.constant([1, 2, 3])
y = tf.constant(2)
z = tf.constant([2, 2, 2])
# All of these are the same computation
print(tf.multiply(x, 2))
print(x * y)
print(x * z)
tf.Tensor([2 4 6], shape=(3,), dtype=int32) tf.Tensor([2 4 6], shape=(3,), dtype=int32) tf.Tensor([2 4 6], shape=(3,), dtype=int32)
同样,长度为 1 的轴可以拉伸以匹配其他参数。两个参数都可以在同一个计算中拉伸。
在这种情况下,一个 3x1 矩阵与一个 1x4 矩阵逐元素相乘,生成一个 3x4 矩阵。请注意,前导 1 是可选的:y 的形状为 [4]。
# These are the same computations
x = tf.reshape(x,[3,1])
y = tf.range(1, 5)
print(x, "\n")
print(y, "\n")
print(tf.multiply(x, y))
tf.Tensor( [[1] [2] [3]], shape=(3, 1), dtype=int32) tf.Tensor([1 2 3 4], shape=(4,), dtype=int32) tf.Tensor( [[ 1 2 3 4] [ 2 4 6 8] [ 3 6 9 12]], shape=(3, 4), dtype=int32)
广播加法:一个 [3, 1] 乘以一个 [1, 4] 会得到一个 [3,4] |
|---|
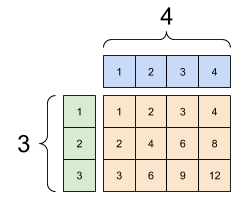
|
以下是相同操作,但没有广播
x_stretch = tf.constant([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]])
y_stretch = tf.constant([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])
print(x_stretch * y_stretch) # Again, operator overloading
tf.Tensor( [[ 1 2 3 4] [ 2 4 6 8] [ 3 6 9 12]], shape=(3, 4), dtype=int32)
大多数情况下,广播在时间和空间上都是高效的,因为广播操作永远不会在内存中实现扩展的张量。
您可以使用 tf.broadcast_to 查看广播的样子。
print(tf.broadcast_to(tf.constant([1, 2, 3]), [3, 3]))
tf.Tensor( [[1 2 3] [1 2 3] [1 2 3]], shape=(3, 3), dtype=int32)
与数学运算不同,例如, broadcast_to 不会做任何特殊的事情来节省内存。在这里,您正在实现张量。
它可以变得更加复杂。 Jake VanderPlas 的书《Python 数据科学手册》的这一部分 展示了更多广播技巧(同样在 NumPy 中)。
tf.convert_to_tensor
大多数运算,如 tf.matmul 和 tf.reshape 接受类 tf.Tensor 的参数。但是,您会注意到,在上面的情况下,接受了类似张量的 Python 对象。
大多数(但不是全部)运算会在非张量参数上调用 convert_to_tensor。有一个转换注册表,大多数对象类,如 NumPy 的 ndarray、TensorShape、Python 列表和 tf.Variable 都将自动转换。
有关更多详细信息,以及如果您有自己的类型想要自动转换为张量,请参阅 tf.register_tensor_conversion_function。
不规则张量
沿某个轴具有可变数量元素的张量称为“不规则”。对于不规则数据,请使用 tf.ragged.RaggedTensor。
例如,这不能表示为常规张量
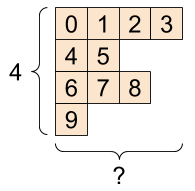
一个 tf.RaggedTensor,形状:[4, None] |
|---|
|
ragged_list = [
[0, 1, 2, 3],
[4, 5],
[6, 7, 8],
[9]]
try:
tensor = tf.constant(ragged_list)
except Exception as e:
print(f"{type(e).__name__}: {e}")
ValueError: Can't convert non-rectangular Python sequence to Tensor.
而是使用 tf.ragged.constant 创建一个 tf.RaggedTensor
ragged_tensor = tf.ragged.constant(ragged_list)
print(ragged_tensor)
<tf.RaggedTensor [[0, 1, 2, 3], [4, 5], [6, 7, 8], [9]]>
tf.RaggedTensor 的形状将包含一些长度未知的轴
print(ragged_tensor.shape)
(4, None)
字符串张量
tf.string 是一种 dtype,也就是说,您可以在张量中以字符串(可变长度字节数组)的形式表示数据。
字符串是原子的,不能像 Python 字符串那样被索引。字符串的长度不是张量轴之一。有关操作字符串的函数,请参阅 tf.strings。
这是一个标量字符串张量
# Tensors can be strings, too here is a scalar string.
scalar_string_tensor = tf.constant("Gray wolf")
print(scalar_string_tensor)
tf.Tensor(b'Gray wolf', shape=(), dtype=string)
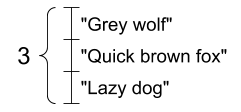
以及一个字符串向量
一个字符串向量,形状:[3,] |
|---|
|
# If you have three string tensors of different lengths, this is OK.
tensor_of_strings = tf.constant(["Gray wolf",
"Quick brown fox",
"Lazy dog"])
# Note that the shape is (3,). The string length is not included.
print(tensor_of_strings)
tf.Tensor([b'Gray wolf' b'Quick brown fox' b'Lazy dog'], shape=(3,), dtype=string)
在上面的打印输出中,b 前缀表示 tf.string dtype 不是 Unicode 字符串,而是字节字符串。有关在 TensorFlow 中使用 Unicode 文本的更多信息,请参阅 Unicode 教程。
如果您传递 Unicode 字符,它们将被 utf-8 编码。
tf.constant("🥳👍")
<tf.Tensor: shape=(), dtype=string, numpy=b'\xf0\x9f\xa5\xb3\xf0\x9f\x91\x8d'>
一些字符串的基本函数可以在 tf.strings 中找到,包括 tf.strings.split。
# You can use split to split a string into a set of tensors
print(tf.strings.split(scalar_string_tensor, sep=" "))
tf.Tensor([b'Gray' b'wolf'], shape=(2,), dtype=string)
# ...but it turns into a `RaggedTensor` if you split up a tensor of strings,
# as each string might be split into a different number of parts.
print(tf.strings.split(tensor_of_strings))
<tf.RaggedTensor [[b'Gray', b'wolf'], [b'Quick', b'brown', b'fox'], [b'Lazy', b'dog']]>
三个拆分的字符串,形状:[3, None] |
|---|

|
text = tf.constant("1 10 100")
print(tf.strings.to_number(tf.strings.split(text, " ")))
tf.Tensor([ 1. 10. 100.], shape=(3,), dtype=float32)
虽然您不能使用 tf.cast 将字符串张量转换为数字,但您可以将其转换为字节,然后转换为数字。
byte_strings = tf.strings.bytes_split(tf.constant("Duck"))
byte_ints = tf.io.decode_raw(tf.constant("Duck"), tf.uint8)
print("Byte strings:", byte_strings)
print("Bytes:", byte_ints)
Byte strings: tf.Tensor([b'D' b'u' b'c' b'k'], shape=(4,), dtype=string) Bytes: tf.Tensor([ 68 117 99 107], shape=(4,), dtype=uint8)
# Or split it up as unicode and then decode it
unicode_bytes = tf.constant("アヒル 🦆")
unicode_char_bytes = tf.strings.unicode_split(unicode_bytes, "UTF-8")
unicode_values = tf.strings.unicode_decode(unicode_bytes, "UTF-8")
print("\nUnicode bytes:", unicode_bytes)
print("\nUnicode chars:", unicode_char_bytes)
print("\nUnicode values:", unicode_values)
Unicode bytes: tf.Tensor(b'\xe3\x82\xa2\xe3\x83\x92\xe3\x83\xab \xf0\x9f\xa6\x86', shape=(), dtype=string) Unicode chars: tf.Tensor([b'\xe3\x82\xa2' b'\xe3\x83\x92' b'\xe3\x83\xab' b' ' b'\xf0\x9f\xa6\x86'], shape=(5,), dtype=string) Unicode values: tf.Tensor([ 12450 12498 12523 32 129414], shape=(5,), dtype=int32)
tf.string dtype 用于 TensorFlow 中的所有原始字节数据。 tf.io 模块包含用于将数据转换为字节和从字节转换数据的函数,包括解码图像和解析 csv。
稀疏张量
有时,您的数据是稀疏的,例如非常宽的嵌入空间。TensorFlow 支持 tf.sparse.SparseTensor 和相关操作来有效地存储稀疏数据。
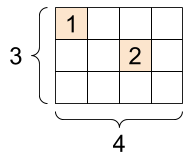
一个 tf.SparseTensor,形状:[3, 4] |
|---|
|
# Sparse tensors store values by index in a memory-efficient manner
sparse_tensor = tf.sparse.SparseTensor(indices=[[0, 0], [1, 2]],
values=[1, 2],
dense_shape=[3, 4])
print(sparse_tensor, "\n")
# You can convert sparse tensors to dense
print(tf.sparse.to_dense(sparse_tensor))
SparseTensor(indices=tf.Tensor( [[0 0] [1 2]], shape=(2, 2), dtype=int64), values=tf.Tensor([1 2], shape=(2,), dtype=int32), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64)) tf.Tensor( [[1 0 0 0] [0 0 2 0] [0 0 0 0]], shape=(3, 4), dtype=int32)