
作者: fchollet
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
 在 keras.io 上查看 在 keras.io 上查看
|
设置
import tensorflow as tf
import keras
from keras import layers
介绍
本指南介绍了使用内置 API 进行训练和验证(例如 Model.fit()、Model.evaluate() 和 Model.predict())时训练、评估和预测(推理)模型。
如果您有兴趣在指定自己的训练步骤函数的同时利用 fit(),请参阅 自定义 fit() 中的操作指南。
如果您有兴趣从头开始编写自己的训练和评估循环,请参阅指南 "从头开始编写训练循环"。
总的来说,无论您是使用内置循环还是编写自己的循环,模型训练和评估在所有类型的 Keras 模型中都以完全相同的方式工作——顺序模型、使用函数式 API 构建的模型以及通过模型子类化从头开始编写的模型。
本指南不涵盖分布式训练,这将在我们的 多 GPU 和分布式训练指南 中介绍。
API 概述:第一个端到端示例
将数据传递给模型的内置训练循环时,您应该使用 **NumPy 数组**(如果您的数据很小并且适合内存)或 **tf.data.Dataset 对象**。在接下来的几段中,我们将使用 MNIST 数据集作为 NumPy 数组,以演示如何使用优化器、损失和指标。
让我们考虑以下模型(这里,我们使用函数式 API 构建,但它也可以是顺序模型或子类模型)。
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
以下是典型的端到端工作流程,包括:
- 训练
- 在从原始训练数据生成的保留集上进行验证
- 在测试数据上进行评估
我们将使用 MNIST 数据作为示例。
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Preprocess the data (these are NumPy arrays)
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# Reserve 10,000 samples for validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
我们指定训练配置(优化器、损失、指标)
model.compile(
optimizer=keras.optimizers.RMSprop(), # Optimizer
# Loss function to minimize
loss=keras.losses.SparseCategoricalCrossentropy(),
# List of metrics to monitor
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
我们调用 fit(),它将通过将数据切片成大小为 batch_size 的“批次”来训练模型,并针对给定数量的 epochs 重复遍历整个数据集。
print("Fit model on training data")
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=2,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(x_val, y_val),
)
Fit model on training data Epoch 1/2 782/782 [==============================] - 4s 3ms/step - loss: 0.3414 - sparse_categorical_accuracy: 0.9024 - val_loss: 0.1810 - val_sparse_categorical_accuracy: 0.9466 Epoch 2/2 782/782 [==============================] - 2s 2ms/step - loss: 0.1594 - sparse_categorical_accuracy: 0.9523 - val_loss: 0.1376 - val_sparse_categorical_accuracy: 0.9598
返回的 history 对象保存了训练期间损失值和指标值的记录
history.history
{'loss': [0.341447114944458, 0.15940724313259125],
'sparse_categorical_accuracy': [0.9024400115013123, 0.9523400068283081],
'val_loss': [0.18102389574050903, 0.13764098286628723],
'val_sparse_categorical_accuracy': [0.9466000199317932, 0.9598000049591064]}
我们通过 evaluate() 在测试数据上评估模型
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(x_test, y_test, batch_size=128)
print("test loss, test acc:", results)
# Generate predictions (probabilities -- the output of the last layer)
# on new data using `predict`
print("Generate predictions for 3 samples")
predictions = model.predict(x_test[:3])
print("predictions shape:", predictions.shape)
79/79 [==============================] - 0s 2ms/step - loss: 0.1448 - sparse_categorical_accuracy: 0.9537 1/1 [==============================] - 0s 73ms/step predictions shape: (3, 10)
现在,让我们详细回顾一下此工作流程的每个部分。
The compile() 方法:指定损失、指标和优化器
要使用 fit() 训练模型,您需要指定损失函数、优化器,以及可选的某些指标来监控。
您将这些作为参数传递给模型的 compile() 方法
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
The metrics 参数应为列表 - 您的模型可以具有任意数量的指标。
如果您的模型具有多个输出,您可以为每个输出指定不同的损失和指标,并且可以调节每个输出对模型总损失的贡献。您将在 **将数据传递给多输入、多输出模型** 部分中找到有关此的更多详细信息。
请注意,如果您对默认设置感到满意,在许多情况下,优化器、损失和指标可以通过字符串标识符作为快捷方式指定
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
为了以后重用,让我们将模型定义和编译步骤放在函数中;我们将在本指南的不同示例中多次调用它们。
def get_uncompiled_model():
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
def get_compiled_model():
model = get_uncompiled_model()
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
return model
许多内置优化器、损失和指标可用
一般来说,您不必从头开始创建自己的损失、指标或优化器,因为您需要的很可能已经是 Keras API 的一部分
优化器
SGD()(带或不带动量)RMSprop()Adam()- 等等。
损失
MeanSquaredError()KLDivergence()CosineSimilarity()- 等等。
指标
AUC()Precision()Recall()- 等等。
自定义损失
如果您需要创建一个自定义损失,Keras 提供三种方法。
第一种方法涉及创建一个接受输入 y_true 和 y_pred 的函数。以下示例显示了一个计算真实数据和预测之间的均方误差的损失函数
def custom_mean_squared_error(y_true, y_pred):
return tf.math.reduce_mean(tf.square(y_true - y_pred), axis=-1)
model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=custom_mean_squared_error)
# We need to one-hot encode the labels to use MSE
y_train_one_hot = tf.one_hot(y_train, depth=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)
782/782 [==============================] - 3s 2ms/step - loss: 0.0158 <keras.src.callbacks.History at 0x7fd65c343310>
如果您需要一个除了 y_true 和 y_pred 之外还接受参数的损失函数,您可以对 keras.losses.Loss 类进行子类化并实现以下两种方法
__init__(self):接受在调用您的损失函数期间传递的参数call(self, y_true, y_pred):使用目标 (y_true) 和模型预测 (y_pred) 来计算模型的损失
假设您想使用均方误差,但添加了一个额外的项,该项将阻止预测值远离 0.5(我们假设分类目标是独热编码的,并且取值在 0 和 1 之间)。这为模型创造了一种不那么自信的激励,这可能有助于减少过度拟合(我们只有尝试后才知道它是否有效!)。
以下是如何操作
@keras.saving.register_keras_serializable()
class CustomMSE(keras.losses.Loss):
def __init__(self, regularization_factor=0.1, name="custom_mse"):
super().__init__(name=name)
self.regularization_factor = regularization_factor
def call(self, y_true, y_pred):
mse = tf.math.reduce_mean(tf.square(y_true - y_pred), axis=-1)
reg = tf.math.reduce_mean(tf.square(0.5 - y_pred), axis=-1)
return mse + reg * self.regularization_factor
def get_config(self):
return {
"regularization_factor": self.regularization_factor,
"name": self.name,
}
model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=CustomMSE())
y_train_one_hot = tf.one_hot(y_train, depth=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)
782/782 [==============================] - 3s 2ms/step - loss: 0.0385 <keras.src.callbacks.History at 0x7fd65c197c10>
自定义指标
如果您需要一个不在 API 中的指标,您可以通过对 keras.metrics.Metric 类进行子类化来轻松创建自定义指标。您需要实现 4 种方法
__init__(self),您将在其中为您的指标创建状态变量。update_state(self, y_true, y_pred, sample_weight=None),它使用目标 y_true 和模型预测 y_pred 来更新状态变量。result(self),它使用状态变量来计算最终结果。reset_state(self),它重新初始化指标的状态。
状态更新和结果计算是分开的(分别在 update_state() 和 result() 中),因为在某些情况下,结果计算可能非常昂贵,并且只会定期执行。
以下是一个简单的示例,展示了如何实现一个 CategoricalTruePositives 指标,该指标计算有多少样本被正确分类为属于给定类别
@keras.saving.register_keras_serializable()
class CategoricalTruePositives(keras.metrics.Metric):
def __init__(self, name="categorical_true_positives", **kwargs):
super().__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name="ctp", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
y_pred = tf.reshape(tf.argmax(y_pred, axis=1), shape=(-1, 1))
values = tf.cast(y_true, "int32") == tf.cast(y_pred, "int32")
values = tf.cast(values, "float32")
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, "float32")
values = tf.multiply(values, sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values))
def result(self):
return self.true_positives
def reset_state(self):
# The state of the metric will be reset at the start of each epoch.
self.true_positives.assign(0.0)
model = get_uncompiled_model()
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[CategoricalTruePositives()],
)
model.fit(x_train, y_train, batch_size=64, epochs=3)
Epoch 1/3 782/782 [==============================] - 2s 2ms/step - loss: 0.3449 - categorical_true_positives: 45089.0000 Epoch 2/3 782/782 [==============================] - 2s 2ms/step - loss: 0.1618 - categorical_true_positives: 47589.0000 Epoch 3/3 782/782 [==============================] - 2s 2ms/step - loss: 0.1192 - categorical_true_positives: 48198.0000 <keras.src.callbacks.History at 0x7fd64c415be0>
处理不符合标准签名的损失和指标
绝大多数损失和指标可以从 y_true 和 y_pred 计算得出,其中 y_pred 是您模型的输出 - 但并非所有指标都可以。例如,正则化损失可能只需要一层激活(在这种情况下没有目标),并且此激活可能不是模型输出。
在这种情况下,您可以从自定义层的 call 方法内部调用 self.add_loss(loss_value)。以这种方式添加的损失在训练期间会添加到“主”损失中(传递给 compile() 的损失)。以下是一个简单的示例,它添加了活动正则化(请注意,活动正则化在所有 Keras 层中都是内置的 - 此层只是为了提供一个具体的示例)
@keras.saving.register_keras_serializable()
class ActivityRegularizationLayer(layers.Layer):
def call(self, inputs):
self.add_loss(tf.reduce_sum(inputs) * 0.1)
return inputs # Pass-through layer.
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
# Insert activity regularization as a layer
x = ActivityRegularizationLayer()(x)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
# The displayed loss will be much higher than before
# due to the regularization component.
model.fit(x_train, y_train, batch_size=64, epochs=1)
782/782 [==============================] - 2s 2ms/step - loss: 2.4921 <keras.src.callbacks.History at 0x7fd64c257340>
请注意,当您通过 add_loss() 传递损失时,可以调用 compile() 而无需损失函数,因为模型已经有一个要最小化的损失。
考虑以下 LogisticEndpoint 层:它将目标和 logits 作为输入,并通过 add_loss() 跟踪交叉熵损失。
@keras.saving.register_keras_serializable()
class LogisticEndpoint(keras.layers.Layer):
def __init__(self, name=None):
super().__init__(name=name)
self.loss_fn = keras.losses.BinaryCrossentropy(from_logits=True)
def call(self, targets, logits, sample_weights=None):
# Compute the training-time loss value and add it
# to the layer using `self.add_loss()`.
loss = self.loss_fn(targets, logits, sample_weights)
self.add_loss(loss)
# Return the inference-time prediction tensor (for `.predict()`).
return tf.nn.softmax(logits)
您可以在具有两个输入(输入数据和目标)的模型中使用它,并使用 loss 参数进行编译,如下所示
import numpy as np
inputs = keras.Input(shape=(3,), name="inputs")
targets = keras.Input(shape=(10,), name="targets")
logits = keras.layers.Dense(10)(inputs)
predictions = LogisticEndpoint(name="predictions")(targets, logits)
model = keras.Model(inputs=[inputs, targets], outputs=predictions)
model.compile(optimizer="adam") # No loss argument!
data = {
"inputs": np.random.random((3, 3)),
"targets": np.random.random((3, 10)),
}
model.fit(data)
1/1 [==============================] - 1s 522ms/step - loss: 0.7258 <keras.src.callbacks.History at 0x7fd64c188400>
有关训练多输入模型的更多信息,请参阅 **将数据传递给多输入、多输出模型** 部分。
自动将验证保留集分开
在您看到的第一个端到端示例中,我们使用了 validation_data 参数将 NumPy 数组的元组 (x_val, y_val) 传递给模型,以便在每个 epoch 结束时评估验证损失和验证指标。
以下还有另一种选择:参数 validation_split 允许您自动保留一部分训练数据用于验证。参数值表示要保留用于验证的数据的比例,因此应将其设置为大于 0 小于 1 的数字。例如,validation_split=0.2 表示“使用 20% 的数据进行验证”,而 validation_split=0.6 表示“使用 60% 的数据进行验证”。
验证的计算方式是,在任何混洗之前,从 fit() 调用接收的数组中获取最后 x% 的样本。
请注意,您只能在使用 NumPy 数据进行训练时使用 validation_split。
model = get_compiled_model()
model.fit(x_train, y_train, batch_size=64, validation_split=0.2, epochs=1)
625/625 [==============================] - 2s 3ms/step - loss: 0.3743 - sparse_categorical_accuracy: 0.8947 - val_loss: 0.2315 - val_sparse_categorical_accuracy: 0.9293 <keras.src.callbacks.History at 0x7fd64c050e20>
从 tf.data 数据集进行训练和评估
在过去几段中,您已经了解了如何处理损失、指标和优化器,并且您已经了解了如何在 fit() 中使用 validation_data 和 validation_split 参数,当您的数据以 NumPy 数组的形式传递时。
现在让我们看一下您的数据以 tf.data.Dataset 对象的形式出现的情况。
The tf.data API 是 TensorFlow 2.0 中的一组实用程序,用于以快速且可扩展的方式加载和预处理数据。
有关创建 Datasets 的完整指南,请参阅 tf.data 文档。
您可以将 Dataset 实例直接传递给方法 fit()、evaluate() 和 predict()
model = get_compiled_model()
# First, let's create a training Dataset instance.
# For the sake of our example, we'll use the same MNIST data as before.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Now we get a test dataset.
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(64)
# Since the dataset already takes care of batching,
# we don't pass a `batch_size` argument.
model.fit(train_dataset, epochs=3)
# You can also evaluate or predict on a dataset.
print("Evaluate")
result = model.evaluate(test_dataset)
dict(zip(model.metrics_names, result))
Epoch 1/3
782/782 [==============================] - 2s 2ms/step - loss: 0.3365 - sparse_categorical_accuracy: 0.9042
Epoch 2/3
782/782 [==============================] - 2s 2ms/step - loss: 0.1628 - sparse_categorical_accuracy: 0.9523
Epoch 3/3
782/782 [==============================] - 2s 2ms/step - loss: 0.1185 - sparse_categorical_accuracy: 0.9648
Evaluate
157/157 [==============================] - 0s 2ms/step - loss: 0.1247 - sparse_categorical_accuracy: 0.9627
{'loss': 0.12467469274997711,
'sparse_categorical_accuracy': 0.9627000093460083}
请注意,数据集在每个 epoch 结束时都会重置,因此它可以在下一个 epoch 中重复使用。
如果您只想在此数据集的特定数量的批次上运行训练,您可以传递 steps_per_epoch 参数,该参数指定模型应使用此数据集运行多少个训练步骤,然后才能进入下一个 epoch。
如果您这样做,数据集在每个 epoch 结束时不会重置,而是我们只是继续提取下一个批次。数据集最终会耗尽数据(除非它是一个无限循环的数据集)。
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Only use the 100 batches per epoch (that's 64 * 100 samples)
model.fit(train_dataset, epochs=3, steps_per_epoch=100)
Epoch 1/3 100/100 [==============================] - 1s 2ms/step - loss: 0.7870 - sparse_categorical_accuracy: 0.7933 Epoch 2/3 100/100 [==============================] - 0s 2ms/step - loss: 0.3748 - sparse_categorical_accuracy: 0.8969 Epoch 3/3 100/100 [==============================] - 0s 2ms/step - loss: 0.3169 - sparse_categorical_accuracy: 0.9070 <keras.src.callbacks.History at 0x7fd6242a8790>
使用验证数据集
您可以将 Dataset 实例作为 validation_data 参数传递给 fit()
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(train_dataset, epochs=1, validation_data=val_dataset)
782/782 [==============================] - 3s 2ms/step - loss: 0.3470 - sparse_categorical_accuracy: 0.9005 - val_loss: 0.1883 - val_sparse_categorical_accuracy: 0.9491 <keras.src.callbacks.History at 0x7fd65c343580>
在每个 epoch 结束时,模型将遍历验证数据集并计算验证损失和验证指标。
如果您只想在此数据集的特定数量的批次上运行验证,您可以传递 validation_steps 参数,该参数指定模型应使用验证数据集运行多少个验证步骤,然后才能中断验证并进入下一个 epoch
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(
train_dataset,
epochs=1,
# Only run validation using the first 10 batches of the dataset
# using the `validation_steps` argument
validation_data=val_dataset,
validation_steps=10,
)
782/782 [==============================] - 2s 2ms/step - loss: 0.3375 - sparse_categorical_accuracy: 0.9046 - val_loss: 0.3063 - val_sparse_categorical_accuracy: 0.9234 <keras.src.callbacks.History at 0x7fd64c2b4280>
请注意,验证数据集将在每次使用后重置(这样您将始终在每个 epoch 中评估相同的样本)。
参数 validation_split(从训练数据生成保留集)在从 Dataset 对象进行训练时不受支持,因为此功能需要能够索引数据集的样本,而这在 Dataset API 中通常是不可能的。
支持的其他输入格式
除了 NumPy 数组、急切张量和 TensorFlow Datasets,还可以使用 Pandas 数据框或从生成批次数据和标签的 Python 生成器中训练 Keras 模型。
特别是,keras.utils.Sequence 类提供了一个简单的接口来构建支持多处理并且可以进行洗牌的 Python 数据生成器。
一般来说,我们建议您使用
- 如果您的数据量很小并且可以放入内存,则使用 NumPy 输入数据
Dataset对象,如果您有大型数据集并且需要进行分布式训练Sequence对象,如果您有大型数据集并且需要进行大量无法在 TensorFlow 中完成的自定义 Python 端处理(例如,如果您依赖外部库进行数据加载或预处理)。
使用 keras.utils.Sequence 对象作为输入
keras.utils.Sequence 是一个实用程序,您可以对其进行子类化以获得具有两个重要属性的 Python 生成器
- 它与多处理配合良好。
- 它可以进行洗牌(例如,在
fit()中传递shuffle=True时)。
一个 Sequence 必须实现两个方法
__getitem____len__
方法 __getitem__ 应该返回一个完整的批次。如果您想在 epoch 之间修改数据集,您可以实现 on_epoch_end。
这是一个快速示例
from skimage.io import imread
from skimage.transform import resize
import numpy as np
# Here, `filenames` is list of path to the images
# and `labels` are the associated labels.
class CIFAR10Sequence(Sequence):
def __init__(self, filenames, labels, batch_size):
self.filenames, self.labels = filenames, labels
self.batch_size = batch_size
def __len__(self):
return int(np.ceil(len(self.filenames) / float(self.batch_size)))
def __getitem__(self, idx):
batch_x = self.filenames[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_y = self.labels[idx * self.batch_size:(idx + 1) * self.batch_size]
return np.array([
resize(imread(filename), (200, 200))
for filename in batch_x]), np.array(batch_y)
sequence = CIFAR10Sequence(filenames, labels, batch_size)
model.fit(sequence, epochs=10)
使用样本权重和类别权重
使用默认设置,样本的权重由其在数据集中的频率决定。有两种方法可以对数据进行加权,与样本频率无关
- 类别权重
- 样本权重
类别权重
这可以通过将字典传递给 class_weight 参数来设置,该参数传递给 Model.fit()。此字典将类别索引映射到应用于属于此类别的样本的权重。
这可以用来平衡类别而无需重新采样,或者训练一个模型,该模型更重视特定类别。
例如,如果类别“0”在您的数据中所占比例是类别“1”的一半,您可以使用 Model.fit(..., class_weight={0: 1., 1: 0.5})。
这是一个 NumPy 示例,我们使用类别权重或样本权重来更重视对类别 #5(在 MNIST 数据集中是数字“5”)的正确分类。
import numpy as np
class_weight = {
0: 1.0,
1: 1.0,
2: 1.0,
3: 1.0,
4: 1.0,
# Set weight "2" for class "5",
# making this class 2x more important
5: 2.0,
6: 1.0,
7: 1.0,
8: 1.0,
9: 1.0,
}
print("Fit with class weight")
model = get_compiled_model()
model.fit(x_train, y_train, class_weight=class_weight, batch_size=64, epochs=1)
Fit with class weight 782/782 [==============================] - 3s 2ms/step - loss: 0.3721 - sparse_categorical_accuracy: 0.9007 <keras.src.callbacks.History at 0x7fd5a032de80>
样本权重
为了进行更细粒度的控制,或者如果您没有构建分类器,您可以使用“样本权重”。
- 从 NumPy 数据训练时:将
sample_weight参数传递给Model.fit()。 - 从
tf.data或任何其他类型的迭代器训练时:生成(input_batch, label_batch, sample_weight_batch)元组。
“样本权重”数组是一个数字数组,指定批次中每个样本在计算总损失时应具有的权重。它通常用于不平衡分类问题(想法是给很少见到的类别赋予更大的权重)。
当使用的权重为 1 和 0 时,该数组可以用作损失函数的掩码(完全丢弃某些样本对总损失的贡献)。
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.0
print("Fit with sample weight")
model = get_compiled_model()
model.fit(x_train, y_train, sample_weight=sample_weight, batch_size=64, epochs=1)
Fit with sample weight 782/782 [==============================] - 2s 2ms/step - loss: 0.3753 - sparse_categorical_accuracy: 0.9019 <keras.src.callbacks.History at 0x7fd5a01eafa0>
这是一个匹配的 Dataset 示例
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.0
# Create a Dataset that includes sample weights
# (3rd element in the return tuple).
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train, sample_weight))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model = get_compiled_model()
model.fit(train_dataset, epochs=1)
782/782 [==============================] - 2s 2ms/step - loss: 0.3794 - sparse_categorical_accuracy: 0.9023 <keras.src.callbacks.History at 0x7fd5a00a0f40>
将数据传递给多输入、多输出模型
在前面的示例中,我们考虑的是一个具有单个输入(形状为 (764,) 的张量)和单个输出(形状为 (10,) 的预测张量)的模型。但是对于具有多个输入或输出的模型呢?
考虑以下模型,它具有形状为 (32, 32, 3) 的图像输入(即 (高度, 宽度, 通道))和形状为 (None, 10) 的时间序列输入(即 (时间步长, 特征))。我们的模型将有两个输出,它们是根据这些输入的组合计算出来的:一个“分数”(形状为 (1,))和一个五个类别的概率分布(形状为 (5,))。
image_input = keras.Input(shape=(32, 32, 3), name="img_input")
timeseries_input = keras.Input(shape=(None, 10), name="ts_input")
x1 = layers.Conv2D(3, 3)(image_input)
x1 = layers.GlobalMaxPooling2D()(x1)
x2 = layers.Conv1D(3, 3)(timeseries_input)
x2 = layers.GlobalMaxPooling1D()(x2)
x = layers.concatenate([x1, x2])
score_output = layers.Dense(1, name="score_output")(x)
class_output = layers.Dense(5, name="class_output")(x)
model = keras.Model(
inputs=[image_input, timeseries_input], outputs=[score_output, class_output]
)
让我们绘制这个模型,这样您就可以清楚地看到我们在这里做了什么(请注意,图中显示的形状是批次形状,而不是每个样本的形状)。
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
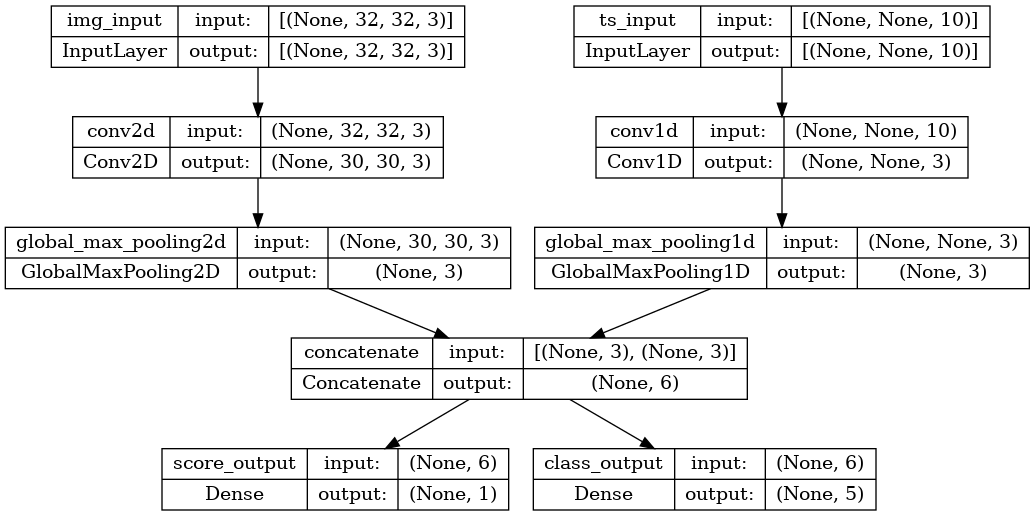
在编译时,我们可以通过将损失函数作为列表传递来指定不同的损失函数到不同的输出
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
)
如果我们只将一个损失函数传递给模型,则相同的损失函数将应用于每个输出(这在这里不合适)。
指标也是如此
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
metrics=[
[
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
[keras.metrics.CategoricalAccuracy()],
],
)
由于我们为输出层命名,我们还可以通过字典指定每个输出的损失和指标
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"score_output": keras.losses.MeanSquaredError(),
"class_output": keras.losses.CategoricalCrossentropy(),
},
metrics={
"score_output": [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
"class_output": [keras.metrics.CategoricalAccuracy()],
},
)
如果您有多于 2 个输出,我们建议使用显式名称和字典。
可以使用 loss_weights 参数为不同的输出特定损失赋予不同的权重(例如,有人可能希望优先考虑我们示例中的“分数”损失,通过赋予其 2 倍于类别损失的重要性),
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"score_output": keras.losses.MeanSquaredError(),
"class_output": keras.losses.CategoricalCrossentropy(),
},
metrics={
"score_output": [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
"class_output": [keras.metrics.CategoricalAccuracy()],
},
loss_weights={"score_output": 2.0, "class_output": 1.0},
)
您也可以选择不为某些输出计算损失,如果这些输出用于预测但不用于训练
# List loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[None, keras.losses.CategoricalCrossentropy()],
)
# Or dict loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={"class_output": keras.losses.CategoricalCrossentropy()},
)
在 fit() 中将数据传递给多输入或多输出模型的方式与在编译中指定损失函数的方式类似:您可以传递NumPy 数组列表(与接收损失函数的输出一一对应)或将输出名称映射到 NumPy 数组的字典。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
)
# Generate dummy NumPy data
img_data = np.random.random_sample(size=(100, 32, 32, 3))
ts_data = np.random.random_sample(size=(100, 20, 10))
score_targets = np.random.random_sample(size=(100, 1))
class_targets = np.random.random_sample(size=(100, 5))
# Fit on lists
model.fit([img_data, ts_data], [score_targets, class_targets], batch_size=32, epochs=1)
# Alternatively, fit on dicts
model.fit(
{"img_input": img_data, "ts_input": ts_data},
{"score_output": score_targets, "class_output": class_targets},
batch_size=32,
epochs=1,
)
4/4 [==============================] - 2s 16ms/step - loss: 10.9556 - score_output_loss: 0.3131 - class_output_loss: 10.6425 4/4 [==============================] - 0s 5ms/step - loss: 14.1855 - score_output_loss: 0.2088 - class_output_loss: 13.9767 <keras.src.callbacks.History at 0x7fd7f0d47040>
这是 Dataset 使用案例:与我们对 NumPy 数组所做的一样,Dataset 应该返回一个字典元组。
train_dataset = tf.data.Dataset.from_tensor_slices(
(
{"img_input": img_data, "ts_input": ts_data},
{"score_output": score_targets, "class_output": class_targets},
)
)
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model.fit(train_dataset, epochs=1)
2/2 [==============================] - 0s 40ms/step - loss: 21.0572 - score_output_loss: 0.2223 - class_output_loss: 20.8349 <keras.src.callbacks.History at 0x7fd64c2b4b20>
使用回调
Keras 中的回调是在训练的不同阶段(在 epoch 开始时、在批次结束时、在 epoch 结束时等)被调用的对象。它们可以用来实现某些行为,例如
- 在训练的不同阶段进行验证(超出内置的每个 epoch 验证)
- 定期检查模型,或者当模型超过某个准确率阈值时检查模型
- 当训练似乎陷入停滞时,更改模型的学习率
- 当训练似乎陷入停滞时,对顶层进行微调
- 当训练结束或达到某个性能阈值时,发送电子邮件或即时消息通知
- 等等。
回调可以作为列表传递给您对 fit() 的调用
model = get_compiled_model()
callbacks = [
keras.callbacks.EarlyStopping(
# Stop training when `val_loss` is no longer improving
monitor="val_loss",
# "no longer improving" being defined as "no better than 1e-2 less"
min_delta=1e-2,
# "no longer improving" being further defined as "for at least 2 epochs"
patience=2,
verbose=1,
)
]
model.fit(
x_train,
y_train,
epochs=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2,
)
Epoch 1/20 625/625 [==============================] - 2s 3ms/step - loss: 0.3630 - sparse_categorical_accuracy: 0.8962 - val_loss: 0.2388 - val_sparse_categorical_accuracy: 0.9296 Epoch 2/20 625/625 [==============================] - 1s 2ms/step - loss: 0.1720 - sparse_categorical_accuracy: 0.9490 - val_loss: 0.1713 - val_sparse_categorical_accuracy: 0.9485 Epoch 3/20 625/625 [==============================] - 1s 2ms/step - loss: 0.1246 - sparse_categorical_accuracy: 0.9624 - val_loss: 0.1597 - val_sparse_categorical_accuracy: 0.9525 Epoch 4/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0977 - sparse_categorical_accuracy: 0.9704 - val_loss: 0.1550 - val_sparse_categorical_accuracy: 0.9538 Epoch 5/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0795 - sparse_categorical_accuracy: 0.9770 - val_loss: 0.1438 - val_sparse_categorical_accuracy: 0.9596 Epoch 6/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0664 - sparse_categorical_accuracy: 0.9804 - val_loss: 0.1394 - val_sparse_categorical_accuracy: 0.9589 Epoch 7/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0567 - sparse_categorical_accuracy: 0.9835 - val_loss: 0.1235 - val_sparse_categorical_accuracy: 0.9660 Epoch 8/20 625/625 [==============================] - 1s 2ms/step - loss: 0.0483 - sparse_categorical_accuracy: 0.9847 - val_loss: 0.1396 - val_sparse_categorical_accuracy: 0.9615 Epoch 9/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0422 - sparse_categorical_accuracy: 0.9872 - val_loss: 0.1406 - val_sparse_categorical_accuracy: 0.9627 Epoch 9: early stopping <keras.src.callbacks.History at 0x7fd7f1ec0c10>
许多内置回调可用
Keras 中已经提供了许多内置回调,例如
ModelCheckpoint:定期保存模型。EarlyStopping:当训练不再改善验证指标时停止训练。TensorBoard:定期写入模型日志,这些日志可以在 TensorBoard 中可视化(有关详细信息,请参阅“可视化”部分)。CSVLogger:将损失和指标数据流式传输到 CSV 文件。- 等等。
有关完整列表,请参阅 回调文档。
编写您自己的回调
您可以通过扩展基类 keras.callbacks.Callback 来创建自定义回调。回调可以通过类属性 self.model 访问其关联的模型。
请务必阅读 编写自定义回调的完整指南。
这是一个简单的示例,它在训练期间保存一个每个批次损失值的列表
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs):
self.per_batch_losses = []
def on_batch_end(self, batch, logs):
self.per_batch_losses.append(logs.get("loss"))
检查模型
当您在相对较大的数据集上训练模型时,至关重要的是要定期保存模型的检查点。
实现此目的最简单的方法是使用 ModelCheckpoint 回调
model = get_compiled_model()
callbacks = [
keras.callbacks.ModelCheckpoint(
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
# The saved model name will include the current epoch.
filepath="mymodel_{epoch}",
save_best_only=True, # Only save a model if `val_loss` has improved.
monitor="val_loss",
verbose=1,
)
]
model.fit(
x_train, y_train, epochs=2, batch_size=64, callbacks=callbacks, validation_split=0.2
)
Epoch 1/2 608/625 [============================>.] - ETA: 0s - loss: 0.3786 - sparse_categorical_accuracy: 0.8939 Epoch 1: val_loss improved from inf to 0.24249, saving model to mymodel_1 INFO:tensorflow:Assets written to: mymodel_1/assets INFO:tensorflow:Assets written to: mymodel_1/assets 625/625 [==============================] - 3s 4ms/step - loss: 0.3756 - sparse_categorical_accuracy: 0.8946 - val_loss: 0.2425 - val_sparse_categorical_accuracy: 0.9307 Epoch 2/2 619/625 [============================>.] - ETA: 0s - loss: 0.1808 - sparse_categorical_accuracy: 0.9458 Epoch 2: val_loss improved from 0.24249 to 0.18221, saving model to mymodel_2 INFO:tensorflow:Assets written to: mymodel_2/assets INFO:tensorflow:Assets written to: mymodel_2/assets 625/625 [==============================] - 2s 3ms/step - loss: 0.1809 - sparse_categorical_accuracy: 0.9458 - val_loss: 0.1822 - val_sparse_categorical_accuracy: 0.9430 <keras.src.callbacks.History at 0x7fd7f1e11be0>
ModelCheckpoint 回调可用于实现容错:如果训练随机中断,则能够从模型的上次保存状态重新开始训练。这是一个基本示例
import os
# Prepare a directory to store all the checkpoints.
checkpoint_dir = "./ckpt"
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
def make_or_restore_model():
# Either restore the latest model, or create a fresh one
# if there is no checkpoint available.
checkpoints = [checkpoint_dir + "/" + name for name in os.listdir(checkpoint_dir)]
if checkpoints:
latest_checkpoint = max(checkpoints, key=os.path.getctime)
print("Restoring from", latest_checkpoint)
return keras.models.load_model(latest_checkpoint)
print("Creating a new model")
return get_compiled_model()
model = make_or_restore_model()
callbacks = [
# This callback saves the model every 100 batches.
# We include the training loss in the saved model name.
keras.callbacks.ModelCheckpoint(
filepath=checkpoint_dir + "/model-loss={loss:.2f}", save_freq=100
)
]
model.fit(x_train, y_train, epochs=1, callbacks=callbacks)
Creating a new model 96/1563 [>.............................] - ETA: 3s - loss: 0.9908 - sparse_categorical_accuracy: 0.7197INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.98/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.98/assets 193/1563 [==>...........................] - ETA: 5s - loss: 0.7186 - sparse_categorical_accuracy: 0.7970INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.71/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.71/assets 295/1563 [====>.........................] - ETA: 5s - loss: 0.5922 - sparse_categorical_accuracy: 0.8303INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.59/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.59/assets 396/1563 [======>.......................] - ETA: 5s - loss: 0.5166 - sparse_categorical_accuracy: 0.8506INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.51/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.51/assets 495/1563 [========>.....................] - ETA: 5s - loss: 0.4744 - sparse_categorical_accuracy: 0.8625INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.47/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.47/assets 589/1563 [==========>...................] - ETA: 5s - loss: 0.4410 - sparse_categorical_accuracy: 0.8725INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.44/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.44/assets 692/1563 [============>.................] - ETA: 4s - loss: 0.4102 - sparse_categorical_accuracy: 0.8805INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.41/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.41/assets 788/1563 [==============>...............] - ETA: 4s - loss: 0.3882 - sparse_categorical_accuracy: 0.8867INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.39/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.39/assets 888/1563 [================>.............] - ETA: 3s - loss: 0.3695 - sparse_categorical_accuracy: 0.8923INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.37/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.37/assets 993/1563 [==================>...........] - ETA: 3s - loss: 0.3538 - sparse_categorical_accuracy: 0.8965INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.35/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.35/assets 1093/1563 [===================>..........] - ETA: 2s - loss: 0.3387 - sparse_categorical_accuracy: 0.9007INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.34/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.34/assets 1195/1563 [=====================>........] - ETA: 1s - loss: 0.3260 - sparse_categorical_accuracy: 0.9041INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.33/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.33/assets 1292/1563 [=======================>......] - ETA: 1s - loss: 0.3158 - sparse_categorical_accuracy: 0.9072INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.31/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.31/assets 1389/1563 [=========================>....] - ETA: 0s - loss: 0.3068 - sparse_categorical_accuracy: 0.9097INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.31/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.31/assets 1493/1563 [===========================>..] - ETA: 0s - loss: 0.2979 - sparse_categorical_accuracy: 0.9124INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.30/assets INFO:tensorflow:Assets written to: ./ckpt/model-loss=0.30/assets 1563/1563 [==============================] - 10s 6ms/step - loss: 0.2930 - sparse_categorical_accuracy: 0.9137 <keras.src.callbacks.History at 0x7fd7f1f22ee0>
您也可以编写自己的回调来保存和恢复模型。
有关序列化和保存的完整指南,请参阅 保存和序列化模型的指南。
使用学习率计划
训练深度学习模型时,一个常见的模式是随着训练的进行逐渐降低学习率。这通常被称为“学习率衰减”。
学习衰减计划可以是静态的(预先固定,作为当前 epoch 或当前批次索引的函数),也可以是动态的(响应模型的当前行为,特别是验证损失)。
将计划传递给优化器
您可以通过将计划对象作为 learning_rate 参数传递给优化器来轻松使用静态学习率衰减计划
initial_learning_rate = 0.1
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate, decay_steps=100000, decay_rate=0.96, staircase=True
)
optimizer = keras.optimizers.RMSprop(learning_rate=lr_schedule)
提供了一些内置计划:ExponentialDecay、PiecewiseConstantDecay、PolynomialDecay 和 InverseTimeDecay。
使用回调来实现动态学习率计划
动态学习率计划(例如,当验证损失不再改善时降低学习率)无法使用这些计划对象实现,因为优化器无法访问验证指标。
但是,回调可以访问所有指标,包括验证指标!因此,您可以通过使用修改优化器当前学习率的回调来实现这种模式。实际上,这甚至作为 ReduceLROnPlateau 回调内置。
可视化训练期间的损失和指标
在训练期间密切关注模型的最佳方法是使用 TensorBoard - 一个可以在本地运行的基于浏览器的应用程序,它为您提供
- 训练和评估的损失和指标的实时图
- (可选)层激活直方图的可视化
- (可选)由
Embedding层学习的嵌入空间的 3D 可视化
如果您使用 pip 安装了 TensorFlow,您应该能够从命令行启动 TensorBoard
tensorboard --logdir=/full_path_to_your_logs
使用 TensorBoard 回调
在 Keras 模型和 fit() 方法中使用 TensorBoard 的最简单方法是 TensorBoard 回调。
在最简单的情况下,只需指定您希望回调写入日志的位置,就可以了
keras.callbacks.TensorBoard(
log_dir="/full_path_to_your_logs",
histogram_freq=0, # How often to log histogram visualizations
embeddings_freq=0, # How often to log embedding visualizations
update_freq="epoch",
) # How often to write logs (default: once per epoch)
<keras.src.callbacks.TensorBoard at 0x7fd64c425310>
有关更多信息,请参阅 TensorBoard 回调的文档。