
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
学习目标
在本 Colab 笔记本中,您将学习如何使用来自 NLP 建模库 的构建块,构建用于常见 NLP 任务(包括预训练、跨度标记和分类)的基于 Transformer 的模型。
安装和导入
安装 TensorFlow Model Garden pip 包
tf-models-official是稳定的 Model Garden 包。请注意,它可能不包含tensorflow_modelsgithub 存储库中的最新更改。要包含最新更改,您可以安装tf-models-nightly,它是每天自动创建的 Model Garden 夜间包。pip将自动安装所有模型和依赖项。
pip install tf-models-official
导入 Tensorflow 和其他库
import numpy as np
import tensorflow as tf
from tensorflow_models import nlp
2023-10-17 12:23:04.557393: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-10-17 12:23:04.557445: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-10-17 12:23:04.557482: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
BERT 预训练模型
BERT (用于语言理解的深度双向 Transformer 的预训练) 引入了在大型文本语料库上预训练语言表示的方法,然后将该模型用于下游 NLP 任务。
在本节中,我们将学习如何构建一个模型来在掩码语言建模任务和下一句预测任务上预训练 BERT。为简单起见,我们只展示最小示例并使用虚拟数据。
构建一个 BertPretrainer 模型,它包装了 BertEncoder
nlp.networks.BertEncoder 类实现了 BERT 论文中描述的基于 Transformer 的编码器。它包括嵌入查找和 Transformer 层 (nlp.layers.TransformerEncoderBlock),但不包括掩码语言模型或分类任务网络。
nlp.models.BertPretrainer 类允许用户传入一个 Transformer 堆栈,并实例化用于创建训练目标的掩码语言模型和分类网络。
# Build a small transformer network.
vocab_size = 100
network = nlp.networks.BertEncoder(
vocab_size=vocab_size,
# The number of TransformerEncoderBlock layers
num_layers=3)
2023-10-17 12:23:09.241708: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://tensorflowcn.cn/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices...
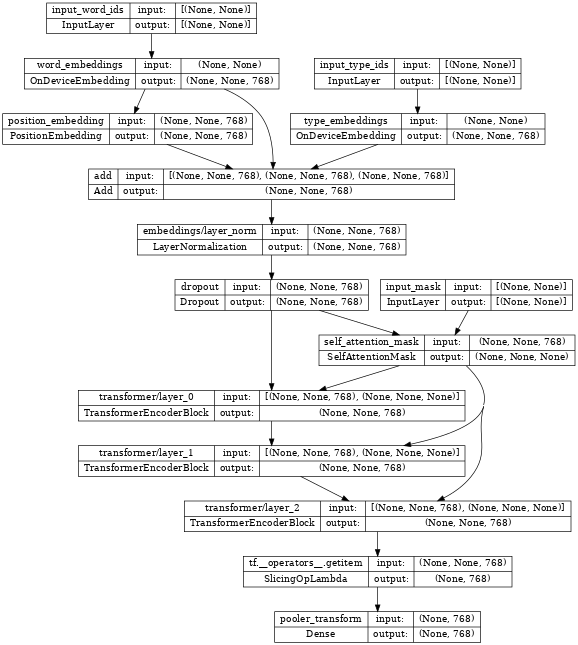
检查编码器,我们看到它包含几个嵌入层,堆叠的 nlp.layers.TransformerEncoderBlock 层,并连接到三个输入层
input_word_ids、input_type_ids 和 input_mask。
tf.keras.utils.plot_model(network, show_shapes=True, expand_nested=True, dpi=48)
# Create a BERT pretrainer with the created network.
num_token_predictions = 8
bert_pretrainer = nlp.models.BertPretrainer(
network, num_classes=2, num_token_predictions=num_token_predictions, output='predictions')
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/official/nlp/modeling/models/bert_pretrainer.py:112: Classification.__init__ (from official.nlp.modeling.networks.classification) is deprecated and will be removed in a future version. Instructions for updating: Classification as a network is deprecated. Please use the layers.ClassificationHead instead.
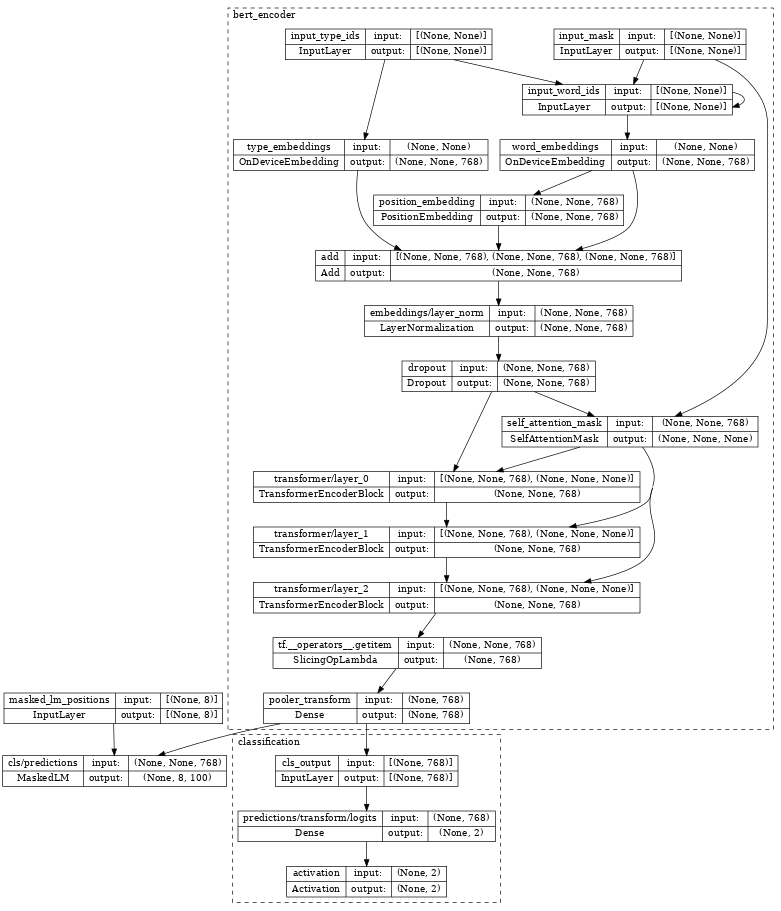
检查 bert_pretrainer,我们看到它使用额外的 MaskedLM 和 nlp.layers.ClassificationHead 头部包装了 encoder。
tf.keras.utils.plot_model(bert_pretrainer, show_shapes=True, expand_nested=True, dpi=48)
# We can feed some dummy data to get masked language model and sentence output.
sequence_length = 16
batch_size = 2
word_id_data = np.random.randint(vocab_size, size=(batch_size, sequence_length))
mask_data = np.random.randint(2, size=(batch_size, sequence_length))
type_id_data = np.random.randint(2, size=(batch_size, sequence_length))
masked_lm_positions_data = np.random.randint(2, size=(batch_size, num_token_predictions))
outputs = bert_pretrainer(
[word_id_data, mask_data, type_id_data, masked_lm_positions_data])
lm_output = outputs["masked_lm"]
sentence_output = outputs["classification"]
print(f'lm_output: shape={lm_output.shape}, dtype={lm_output.dtype!r}')
print(f'sentence_output: shape={sentence_output.shape}, dtype={sentence_output.dtype!r}')
lm_output: shape=(2, 8, 100), dtype=tf.float32 sentence_output: shape=(2, 2), dtype=tf.float32
计算损失
接下来,我们可以使用 lm_output 和 sentence_output 来计算 loss。
masked_lm_ids_data = np.random.randint(vocab_size, size=(batch_size, num_token_predictions))
masked_lm_weights_data = np.random.randint(2, size=(batch_size, num_token_predictions))
next_sentence_labels_data = np.random.randint(2, size=(batch_size))
mlm_loss = nlp.losses.weighted_sparse_categorical_crossentropy_loss(
labels=masked_lm_ids_data,
predictions=lm_output,
weights=masked_lm_weights_data)
sentence_loss = nlp.losses.weighted_sparse_categorical_crossentropy_loss(
labels=next_sentence_labels_data,
predictions=sentence_output)
loss = mlm_loss + sentence_loss
print(loss)
tf.Tensor(5.2983174, shape=(), dtype=float32)
有了损失,您可以优化模型。训练后,我们可以保存 TransformerEncoder 的权重,用于下游微调任务。有关完整示例,请参阅 run_pretraining.py。
跨度标记模型
跨度标记是将标签分配给文本跨度的任务,例如,将文本跨度标记为给定问题的答案。
在本节中,我们将学习如何构建一个跨度标记模型。同样,为简单起见,我们使用虚拟数据。
构建一个包装了 BertEncoder 的 BertSpanLabeler
nlp.models.BertSpanLabeler 类实现了一个简单的单跨度起始-结束预测器(即,一个预测两个值的模型:起始标记索引和结束标记索引),适用于 SQuAD 风格的任务。
请注意,nlp.models.BertSpanLabeler 包装了一个 nlp.networks.BertEncoder,其权重可以从上面的预训练模型中恢复。
network = nlp.networks.BertEncoder(
vocab_size=vocab_size, num_layers=2)
# Create a BERT trainer with the created network.
bert_span_labeler = nlp.models.BertSpanLabeler(network)
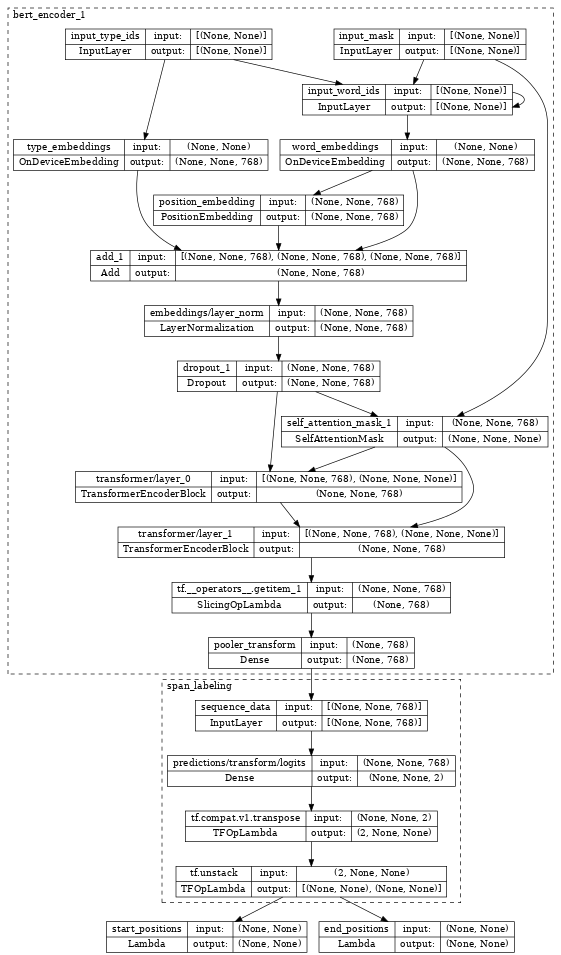
检查 bert_span_labeler,我们看到它使用额外的 SpanLabeling 包装了编码器,该编码器输出 start_position 和 end_position。
tf.keras.utils.plot_model(bert_span_labeler, show_shapes=True, expand_nested=True, dpi=48)
# Create a set of 2-dimensional data tensors to feed into the model.
word_id_data = np.random.randint(vocab_size, size=(batch_size, sequence_length))
mask_data = np.random.randint(2, size=(batch_size, sequence_length))
type_id_data = np.random.randint(2, size=(batch_size, sequence_length))
# Feed the data to the model.
start_logits, end_logits = bert_span_labeler([word_id_data, mask_data, type_id_data])
print(f'start_logits: shape={start_logits.shape}, dtype={start_logits.dtype!r}')
print(f'end_logits: shape={end_logits.shape}, dtype={end_logits.dtype!r}')
start_logits: shape=(2, 16), dtype=tf.float32 end_logits: shape=(2, 16), dtype=tf.float32
计算损失
有了 start_logits 和 end_logits,我们可以计算损失
start_positions = np.random.randint(sequence_length, size=(batch_size))
end_positions = np.random.randint(sequence_length, size=(batch_size))
start_loss = tf.keras.losses.sparse_categorical_crossentropy(
start_positions, start_logits, from_logits=True)
end_loss = tf.keras.losses.sparse_categorical_crossentropy(
end_positions, end_logits, from_logits=True)
total_loss = (tf.reduce_mean(start_loss) + tf.reduce_mean(end_loss)) / 2
print(total_loss)
tf.Tensor(5.3621416, shape=(), dtype=float32)
有了 loss,您可以优化模型。有关完整示例,请参阅 run_squad.py。
分类模型
在最后一节中,我们将展示如何构建一个文本分类模型。
构建一个包装了 BertEncoder 的 BertClassifier 模型
nlp.models.BertClassifier 实现了一个包含单个分类头的 [CLS] 令牌分类模型。
network = nlp.networks.BertEncoder(
vocab_size=vocab_size, num_layers=2)
# Create a BERT trainer with the created network.
num_classes = 2
bert_classifier = nlp.models.BertClassifier(
network, num_classes=num_classes)
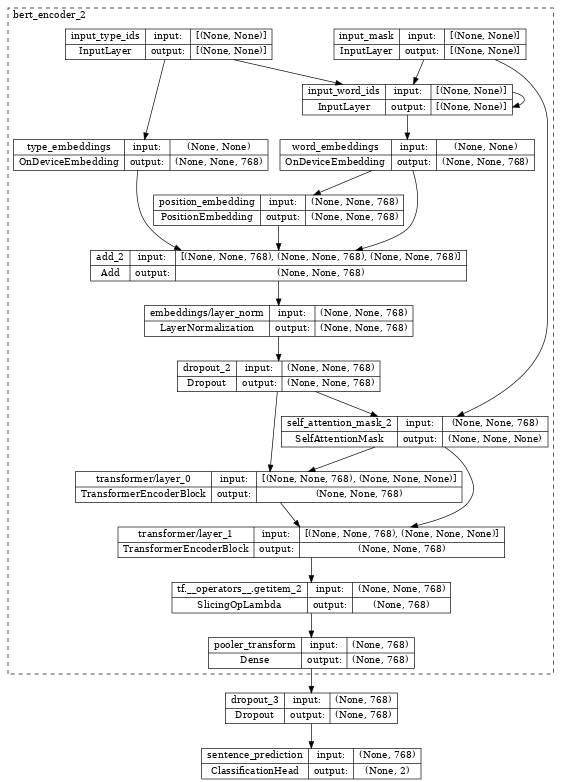
检查 bert_classifier,我们看到它将 encoder 与额外的 Classification 头部包装在一起。
tf.keras.utils.plot_model(bert_classifier, show_shapes=True, expand_nested=True, dpi=48)
# Create a set of 2-dimensional data tensors to feed into the model.
word_id_data = np.random.randint(vocab_size, size=(batch_size, sequence_length))
mask_data = np.random.randint(2, size=(batch_size, sequence_length))
type_id_data = np.random.randint(2, size=(batch_size, sequence_length))
# Feed the data to the model.
logits = bert_classifier([word_id_data, mask_data, type_id_data])
print(f'logits: shape={logits.shape}, dtype={logits.dtype!r}')
logits: shape=(2, 2), dtype=tf.float32
计算损失
使用 logits,我们可以计算 loss。
labels = np.random.randint(num_classes, size=(batch_size))
loss = tf.keras.losses.sparse_categorical_crossentropy(
labels, logits, from_logits=True)
print(loss)
tf.Tensor([0.7332015 1.3447659], shape=(2,), dtype=float32)
使用 loss,您可以优化模型。请参阅 Fine tune_bert 笔记本或 模型训练文档 获取完整示例。