
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
本教程演示如何加载 BERT、ALBERT 和 ELECTRA 预训练检查点,并将其用于下游任务。
模型花园 包含一系列最先进的模型,这些模型使用 TensorFlow 的高级 API 实现。这些实现展示了建模的最佳实践,使用户能够充分利用 TensorFlow 进行研究和产品开发。
安装 TF 模型花园包
pip install -U -q "tf-models-official"
导入必要的库
import os
import yaml
import json
import tensorflow as tf
2023-10-17 12:27:09.738068: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-10-17 12:27:09.738115: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-10-17 12:27:09.738155: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
import tensorflow_models as tfm
from official.core import exp_factory
加载 BERT 模型预训练检查点
选择所需的 BERT 模型
# @title Download Checkpoint of the Selected Model { display-mode: "form", run: "auto" }
model_display_name = 'BERT-base cased English' # @param ['BERT-base uncased English','BERT-base cased English','BERT-large uncased English', 'BERT-large cased English', 'BERT-large, Uncased (Whole Word Masking)', 'BERT-large, Cased (Whole Word Masking)', 'BERT-base MultiLingual','BERT-base Chinese']
if model_display_name == 'BERT-base uncased English':
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/uncased_L-12_H-768_A-12.tar.gz"
!tar -xvf "uncased_L-12_H-768_A-12.tar.gz"
elif model_display_name == 'BERT-base cased English':
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/cased_L-12_H-768_A-12.tar.gz"
!tar -xvf "cased_L-12_H-768_A-12.tar.gz"
elif model_display_name == "BERT-large uncased English":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/uncased_L-24_H-1024_A-16.tar.gz"
!tar -xvf "uncased_L-24_H-1024_A-16.tar.gz"
elif model_display_name == "BERT-large cased English":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/cased_L-24_H-1024_A-16.tar.gz"
!tar -xvf "cased_L-24_H-1024_A-16.tar.gz"
elif model_display_name == "BERT-large, Uncased (Whole Word Masking)":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/wwm_uncased_L-24_H-1024_A-16.tar.gz"
!tar -xvf "wwm_uncased_L-24_H-1024_A-16.tar.gz"
elif model_display_name == "BERT-large, Cased (Whole Word Masking)":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/wwm_cased_L-24_H-1024_A-16.tar.gz"
!tar -xvf "wwm_cased_L-24_H-1024_A-16.tar.gz"
elif model_display_name == "BERT-base MultiLingual":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/multi_cased_L-12_H-768_A-12.tar.gz"
!tar -xvf "multi_cased_L-12_H-768_A-12.tar.gz"
elif model_display_name == "BERT-base Chinese":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/chinese_L-12_H-768_A-12.tar.gz"
!tar -xvf "chinese_L-12_H-768_A-12.tar.gz"
--2023-10-17 12:27:14-- https://storage.googleapis.com/tf_model_garden/nlp/bert/v3/cased_L-12_H-768_A-12.tar.gz Resolving storage.googleapis.com (storage.googleapis.com)... 172.217.219.207, 209.85.146.207, 209.85.147.207, ... Connecting to storage.googleapis.com (storage.googleapis.com)|172.217.219.207|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 401886728 (383M) [application/octet-stream] Saving to: ‘cased_L-12_H-768_A-12.tar.gz’ cased_L-12_H-768_A- 100%[===================>] 383.27M 79.4MB/s in 5.3s 2023-10-17 12:27:19 (72.9 MB/s) - ‘cased_L-12_H-768_A-12.tar.gz’ saved [401886728/401886728] cased_L-12_H-768_A-12/ cased_L-12_H-768_A-12/vocab.txt cased_L-12_H-768_A-12/bert_model.ckpt.index cased_L-12_H-768_A-12/bert_model.ckpt.data-00000-of-00001 cased_L-12_H-768_A-12/params.yaml cased_L-12_H-768_A-12/bert_config.json
# Lookup table of the directory name corresponding to each model checkpoint
folder_bert_dict = {
'BERT-base uncased English': 'uncased_L-12_H-768_A-12',
'BERT-base cased English': 'cased_L-12_H-768_A-12',
'BERT-large uncased English': 'uncased_L-24_H-1024_A-16',
'BERT-large cased English': 'cased_L-24_H-1024_A-16',
'BERT-large, Uncased (Whole Word Masking)': 'wwm_uncased_L-24_H-1024_A-16',
'BERT-large, Cased (Whole Word Masking)': 'wwm_cased_L-24_H-1024_A-16',
'BERT-base MultiLingual': 'multi_cased_L-12_H-768_A-1',
'BERT-base Chinese': 'chinese_L-12_H-768_A-12'
}
folder_bert = folder_bert_dict.get(model_display_name)
folder_bert
'cased_L-12_H-768_A-12'
使用新的 params.yaml 构建 BERT 模型
除了在此构建 BERT 编码器之外,params.yaml 还可用于使用捆绑的训练器进行训练。
config_file = os.path.join(folder_bert, "params.yaml")
config_dict = yaml.safe_load(tf.io.gfile.GFile(config_file).read())
config_dict
{'task': {'model': {'encoder': {'bert': {'attention_dropout_rate': 0.1,
'dropout_rate': 0.1,
'hidden_activation': 'gelu',
'hidden_size': 768,
'initializer_range': 0.02,
'intermediate_size': 3072,
'max_position_embeddings': 512,
'num_attention_heads': 12,
'num_layers': 12,
'type_vocab_size': 2,
'vocab_size': 28996},
'type': 'bert'} } } }
# Method 1: pass encoder config dict into EncoderConfig
encoder_config = tfm.nlp.encoders.EncoderConfig(config_dict["task"]["model"]["encoder"])
encoder_config.get().as_dict()
{'vocab_size': 28996,
'hidden_size': 768,
'num_layers': 12,
'num_attention_heads': 12,
'hidden_activation': 'gelu',
'intermediate_size': 3072,
'dropout_rate': 0.1,
'attention_dropout_rate': 0.1,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02,
'embedding_size': None,
'output_range': None,
'return_all_encoder_outputs': False,
'return_attention_scores': False,
'norm_first': False}
# Method 2: use override_params_dict function to override default Encoder params
encoder_config = tfm.nlp.encoders.EncoderConfig()
tfm.hyperparams.override_params_dict(encoder_config, config_dict["task"]["model"]["encoder"], is_strict=True)
encoder_config.get().as_dict()
{'vocab_size': 28996,
'hidden_size': 768,
'num_layers': 12,
'num_attention_heads': 12,
'hidden_activation': 'gelu',
'intermediate_size': 3072,
'dropout_rate': 0.1,
'attention_dropout_rate': 0.1,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02,
'embedding_size': None,
'output_range': None,
'return_all_encoder_outputs': False,
'return_attention_scores': False,
'norm_first': False}
使用旧的 bert_config.json 构建 BERT 模型
bert_config_file = os.path.join(folder_bert, "bert_config.json")
config_dict = json.loads(tf.io.gfile.GFile(bert_config_file).read())
config_dict
{'hidden_size': 768,
'initializer_range': 0.02,
'intermediate_size': 3072,
'max_position_embeddings': 512,
'num_attention_heads': 12,
'num_layers': 12,
'type_vocab_size': 2,
'vocab_size': 28996,
'hidden_activation': 'gelu',
'dropout_rate': 0.1,
'attention_dropout_rate': 0.1}
encoder_config = tfm.nlp.encoders.EncoderConfig({
'type':'bert',
'bert': config_dict
})
encoder_config.get().as_dict()
{'vocab_size': 28996,
'hidden_size': 768,
'num_layers': 12,
'num_attention_heads': 12,
'hidden_activation': 'gelu',
'intermediate_size': 3072,
'dropout_rate': 0.1,
'attention_dropout_rate': 0.1,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02,
'embedding_size': None,
'output_range': None,
'return_all_encoder_outputs': False,
'return_attention_scores': False,
'norm_first': False}
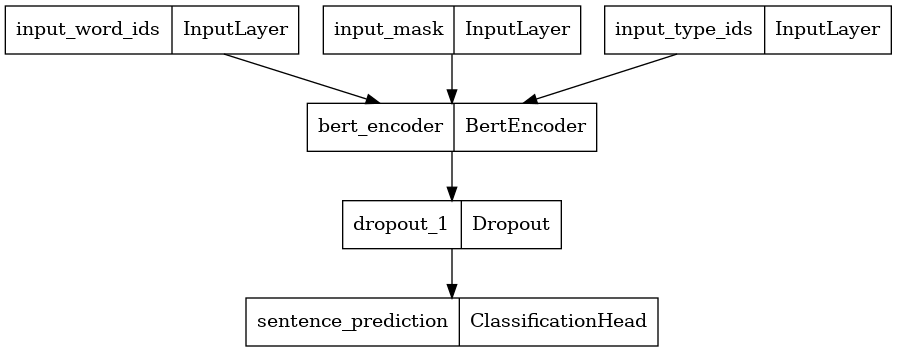
使用 encoder_config 构建分类器
在这里,我们使用选定的编码器配置构建了一个具有 2 个类的新 BERT 分类器,并绘制了其模型架构。BERT 分类器包含一个使用选定编码器配置的 BERT 编码器、一个 Dropout 层和一个 MLP 分类头。
bert_encoder = tfm.nlp.encoders.build_encoder(encoder_config)
bert_classifier = tfm.nlp.models.BertClassifier(network=bert_encoder, num_classes=2)
tf.keras.utils.plot_model(bert_classifier)
2023-10-17 12:27:24.243086: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://tensorflowcn.cn/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices...
将预训练权重加载到 BERT 分类器中
提供的预训练检查点仅包含 BERT 分类器中 BERT 编码器的权重。分类头的权重仍然是随机初始化的。
checkpoint = tf.train.Checkpoint(encoder=bert_encoder)
checkpoint.read(
os.path.join(folder_bert, 'bert_model.ckpt')).expect_partial().assert_existing_objects_matched()
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f73f8418fd0>
加载 ALBERT 模型预训练检查点
# @title Download Checkpoint of the Selected Model { display-mode: "form", run: "auto" }
albert_model_display_name = 'ALBERT-xxlarge English' # @param ['ALBERT-base English', 'ALBERT-large English', 'ALBERT-xlarge English', 'ALBERT-xxlarge English']
if albert_model_display_name == 'ALBERT-base English':
!wget "https://storage.googleapis.com/tf_model_garden/nlp/albert/albert_base.tar.gz"
!tar -xvf "albert_base.tar.gz"
elif albert_model_display_name == 'ALBERT-large English':
!wget "https://storage.googleapis.com/tf_model_garden/nlp/albert/albert_large.tar.gz"
!tar -xvf "albert_large.tar.gz"
elif albert_model_display_name == "ALBERT-xlarge English":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/albert/albert_xlarge.tar.gz"
!tar -xvf "albert_xlarge.tar.gz"
elif albert_model_display_name == "ALBERT-xxlarge English":
!wget "https://storage.googleapis.com/tf_model_garden/nlp/albert/albert_xxlarge.tar.gz"
!tar -xvf "albert_xxlarge.tar.gz"
--2023-10-17 12:27:27-- https://storage.googleapis.com/tf_model_garden/nlp/albert/albert_xxlarge.tar.gz Resolving storage.googleapis.com (storage.googleapis.com)... 172.253.114.207, 172.217.214.207, 142.251.6.207, ... Connecting to storage.googleapis.com (storage.googleapis.com)|172.253.114.207|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 826059238 (788M) [application/octet-stream] Saving to: ‘albert_xxlarge.tar.gz’ albert_xxlarge.tar. 100%[===================>] 787.79M 117MB/s in 6.5s 2023-10-17 12:27:34 (122 MB/s) - ‘albert_xxlarge.tar.gz’ saved [826059238/826059238] albert_xxlarge/ albert_xxlarge/bert_model.ckpt.index albert_xxlarge/30k-clean.model albert_xxlarge/30k-clean.vocab albert_xxlarge/bert_model.ckpt.data-00000-of-00001 albert_xxlarge/params.yaml albert_xxlarge/albert_config.json
# Lookup table of the directory name corresponding to each model checkpoint
folder_albert_dict = {
'ALBERT-base English': 'albert_base',
'ALBERT-large English': 'albert_large',
'ALBERT-xlarge English': 'albert_xlarge',
'ALBERT-xxlarge English': 'albert_xxlarge'
}
folder_albert = folder_albert_dict.get(albert_model_display_name)
folder_albert
'albert_xxlarge'
使用新的 params.yaml 构建 ALBERT 模型
除了在此构建 BERT 编码器之外,params.yaml 还可用于使用捆绑的训练器进行训练。
config_file = os.path.join(folder_albert, "params.yaml")
config_dict = yaml.safe_load(tf.io.gfile.GFile(config_file).read())
config_dict
{'task': {'model': {'encoder': {'albert': {'attention_dropout_rate': 0.0,
'dropout_rate': 0.0,
'embedding_width': 128,
'hidden_activation': 'gelu',
'hidden_size': 4096,
'initializer_range': 0.02,
'intermediate_size': 16384,
'max_position_embeddings': 512,
'num_attention_heads': 64,
'num_layers': 12,
'type_vocab_size': 2,
'vocab_size': 30000},
'type': 'albert'} } } }
# Method 1: pass encoder config dict into EncoderConfig
encoder_config = tfm.nlp.encoders.EncoderConfig(config_dict["task"]["model"]["encoder"])
encoder_config.get().as_dict()
{'vocab_size': 30000,
'embedding_width': 128,
'hidden_size': 4096,
'num_layers': 12,
'num_attention_heads': 64,
'hidden_activation': 'gelu',
'intermediate_size': 16384,
'dropout_rate': 0.0,
'attention_dropout_rate': 0.0,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02}
# Method 2: use override_params_dict function to override default Encoder params
encoder_config = tfm.nlp.encoders.EncoderConfig()
tfm.hyperparams.override_params_dict(encoder_config, config_dict["task"]["model"]["encoder"], is_strict=True)
encoder_config.get().as_dict()
{'vocab_size': 30000,
'embedding_width': 128,
'hidden_size': 4096,
'num_layers': 12,
'num_attention_heads': 64,
'hidden_activation': 'gelu',
'intermediate_size': 16384,
'dropout_rate': 0.0,
'attention_dropout_rate': 0.0,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02}
使用旧的 albert_config.json 构建 ALBERT 模型
albert_config_file = os.path.join(folder_albert, "albert_config.json")
config_dict = json.loads(tf.io.gfile.GFile(albert_config_file).read())
config_dict
{'hidden_size': 4096,
'initializer_range': 0.02,
'intermediate_size': 16384,
'max_position_embeddings': 512,
'num_attention_heads': 64,
'type_vocab_size': 2,
'vocab_size': 30000,
'embedding_width': 128,
'attention_dropout_rate': 0.0,
'dropout_rate': 0.0,
'num_layers': 12,
'hidden_activation': 'gelu'}
encoder_config = tfm.nlp.encoders.EncoderConfig({
'type':'albert',
'albert': config_dict
})
encoder_config.get().as_dict()
{'vocab_size': 30000,
'embedding_width': 128,
'hidden_size': 4096,
'num_layers': 12,
'num_attention_heads': 64,
'hidden_activation': 'gelu',
'intermediate_size': 16384,
'dropout_rate': 0.0,
'attention_dropout_rate': 0.0,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02}
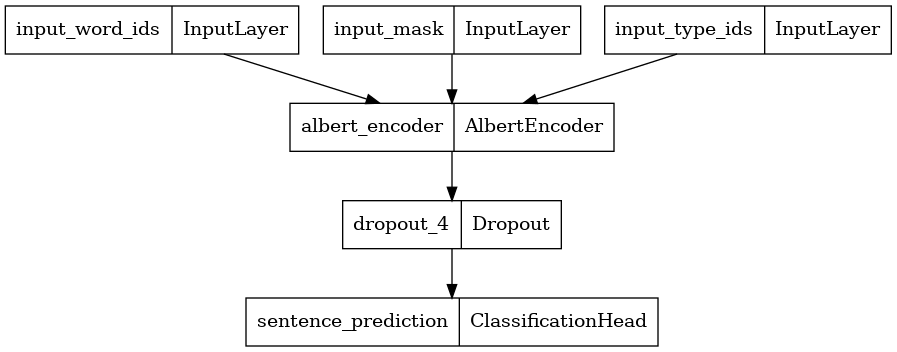
使用 encoder_config 构建分类器
在这里,我们使用选定的编码器配置构建了一个具有 2 个类的新 BERT 分类器,并绘制了其模型架构。BERT 分类器包含一个使用选定编码器配置的 BERT 编码器、一个 Dropout 层和一个 MLP 分类头。
albert_encoder = tfm.nlp.encoders.build_encoder(encoder_config)
albert_classifier = tfm.nlp.models.BertClassifier(network=albert_encoder, num_classes=2)
tf.keras.utils.plot_model(albert_classifier)
将预训练权重加载到分类器中
提供的预训练检查点仅包含 ALBERT 分类器中 ALBERT 编码器的权重。分类头的权重仍然是随机初始化的。
checkpoint = tf.train.Checkpoint(encoder=albert_encoder)
checkpoint.read(
os.path.join(folder_albert, 'bert_model.ckpt')).expect_partial().assert_existing_objects_matched()
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f73f8185fa0>
加载 ELECTRA 模型预训练检查点
# @title Download Checkpoint of the Selected Model { display-mode: "form", run: "auto" }
electra_model_display_name = 'ELECTRA-small English' # @param ['ELECTRA-small English', 'ELECTRA-base English']
if electra_model_display_name == 'ELECTRA-small English':
!wget "https://storage.googleapis.com/tf_model_garden/nlp/electra/small.tar.gz"
!tar -xvf "small.tar.gz"
elif electra_model_display_name == 'ELECTRA-base English':
!wget "https://storage.googleapis.com/tf_model_garden/nlp/electra/base.tar.gz"
!tar -xvf "base.tar.gz"
--2023-10-17 12:27:45-- https://storage.googleapis.com/tf_model_garden/nlp/electra/small.tar.gz Resolving storage.googleapis.com (storage.googleapis.com)... 172.253.114.207, 172.217.214.207, 142.251.6.207, ... Connecting to storage.googleapis.com (storage.googleapis.com)|172.253.114.207|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 157951922 (151M) [application/octet-stream] Saving to: ‘small.tar.gz’ small.tar.gz 100%[===================>] 150.63M 173MB/s in 0.9s 2023-10-17 12:27:46 (173 MB/s) - ‘small.tar.gz’ saved [157951922/157951922] small/ small/ckpt-1000000.data-00000-of-00001 small/params.yaml small/checkpoint small/ckpt-1000000.index
# Lookup table of the directory name corresponding to each model checkpoint
folder_electra_dict = {
'ELECTRA-small English': 'small',
'ELECTRA-base English': 'base'
}
folder_electra = folder_electra_dict.get(electra_model_display_name)
folder_electra
'small'
使用 params.yaml 构建 BERT 模型
除了在此构建 BERT 编码器之外,params.yaml 还可用于使用捆绑的训练器进行训练。
config_file = os.path.join(folder_electra, "params.yaml")
config_dict = yaml.safe_load(tf.io.gfile.GFile(config_file).read())
config_dict
{'model': {'cls_heads': [{'activation': 'tanh',
'cls_token_idx': 0,
'dropout_rate': 0.1,
'inner_dim': 64,
'name': 'next_sentence',
'num_classes': 2}],
'disallow_correct': False,
'discriminator_encoder': {'type': 'bert',
'bert': {'attention_dropout_rate': 0.1,
'dropout_rate': 0.1,
'embedding_size': 128,
'hidden_activation': 'gelu',
'hidden_size': 256,
'initializer_range': 0.02,
'intermediate_size': 1024,
'max_position_embeddings': 512,
'num_attention_heads': 4,
'num_layers': 12,
'type_vocab_size': 2,
'vocab_size': 30522} },
'discriminator_loss_weight': 50.0,
'generator_encoder': {'type': 'bert',
'bert': {'attention_dropout_rate': 0.1,
'dropout_rate': 0.1,
'embedding_size': 128,
'hidden_activation': 'gelu',
'hidden_size': 64,
'initializer_range': 0.02,
'intermediate_size': 256,
'max_position_embeddings': 512,
'num_attention_heads': 1,
'num_layers': 12,
'type_vocab_size': 2,
'vocab_size': 30522} },
'num_classes': 2,
'num_masked_tokens': 76,
'sequence_length': 512,
'tie_embeddings': True} }
disc_encoder_config = tfm.nlp.encoders.EncoderConfig(
config_dict['model']['discriminator_encoder']
)
disc_encoder_config.get().as_dict()
{'vocab_size': 30522,
'hidden_size': 256,
'num_layers': 12,
'num_attention_heads': 4,
'hidden_activation': 'gelu',
'intermediate_size': 1024,
'dropout_rate': 0.1,
'attention_dropout_rate': 0.1,
'max_position_embeddings': 512,
'type_vocab_size': 2,
'initializer_range': 0.02,
'embedding_size': 128,
'output_range': None,
'return_all_encoder_outputs': False,
'return_attention_scores': False,
'norm_first': False}
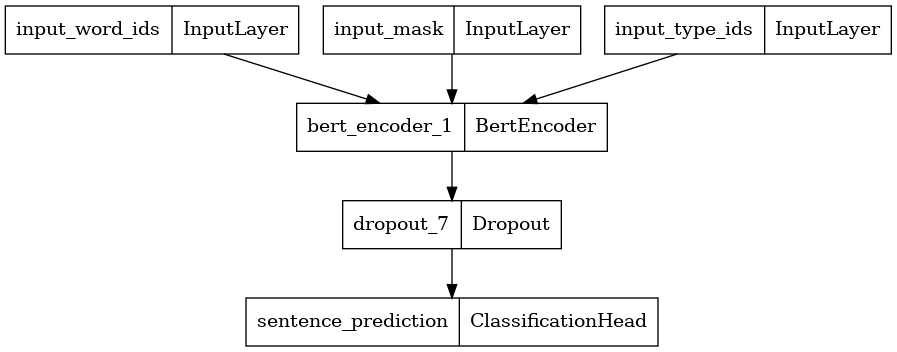
使用 encoder_config 构建分类器
在这里,我们构建了一个具有 2 个类别的分类器,并绘制了其模型架构。分类器包含一个使用选定编码器配置的 ELECTRA 判别器编码器、一个 Dropout 层和一个 MLP 分类头。
disc_encoder = tfm.nlp.encoders.build_encoder(disc_encoder_config)
elctra_dic_classifier = tfm.nlp.models.BertClassifier(network=disc_encoder, num_classes=2)
tf.keras.utils.plot_model(elctra_dic_classifier)
将预训练权重加载到分类器中
提供的预训练检查点包含整个 ELECTRA 模型的权重。我们只在分类器中加载其判别器(方便地命名为 encoder)的权重。分类头的权重仍然是随机初始化的。
checkpoint = tf.train.Checkpoint(encoder=disc_encoder)
checkpoint.read(
tf.train.latest_checkpoint(os.path.join(folder_electra))
).expect_partial().assert_existing_objects_matched()
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f74dbe84f40>