
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概述
本指南深入探讨 TensorFlow 和 Keras 的内部机制,展示 TensorFlow 的工作原理。如果您想立即开始使用 Keras,请查看 Keras 指南集合。
在本指南中,您将学习 TensorFlow 如何让您对代码进行简单的更改以获得图,以及图如何存储和表示,以及如何使用它们来加速模型。
这是一个宏观概述,涵盖了如何使用 tf.function 从急切执行切换到图执行。 有关 tf.function 的更完整规范,请参阅 使用 tf.function 提高性能 指南。
什么是图?
在之前的三个指南中,您以急切方式运行 TensorFlow。这意味着 TensorFlow 操作由 Python 一步一步地执行,并将结果返回给 Python。
虽然急切执行有几个独特的优势,但图执行可以实现 Python 之外的可移植性,并且往往能提供更好的性能。**图执行**意味着张量计算被执行为一个TensorFlow 图,有时被称为一个tf.Graph,或者简称为“图”。
**图是包含一组tf.Operation对象的数据结构,这些对象代表计算单元;以及tf.Tensor对象,这些对象代表在操作之间流动的數據单元。**它们是在tf.Graph上下文中定义的。由于这些图是数据结构,因此可以在没有原始 Python 代码的情况下保存、运行和恢复它们。
这是一个在 TensorBoard 中可视化的表示两层神经网络的 TensorFlow 图。
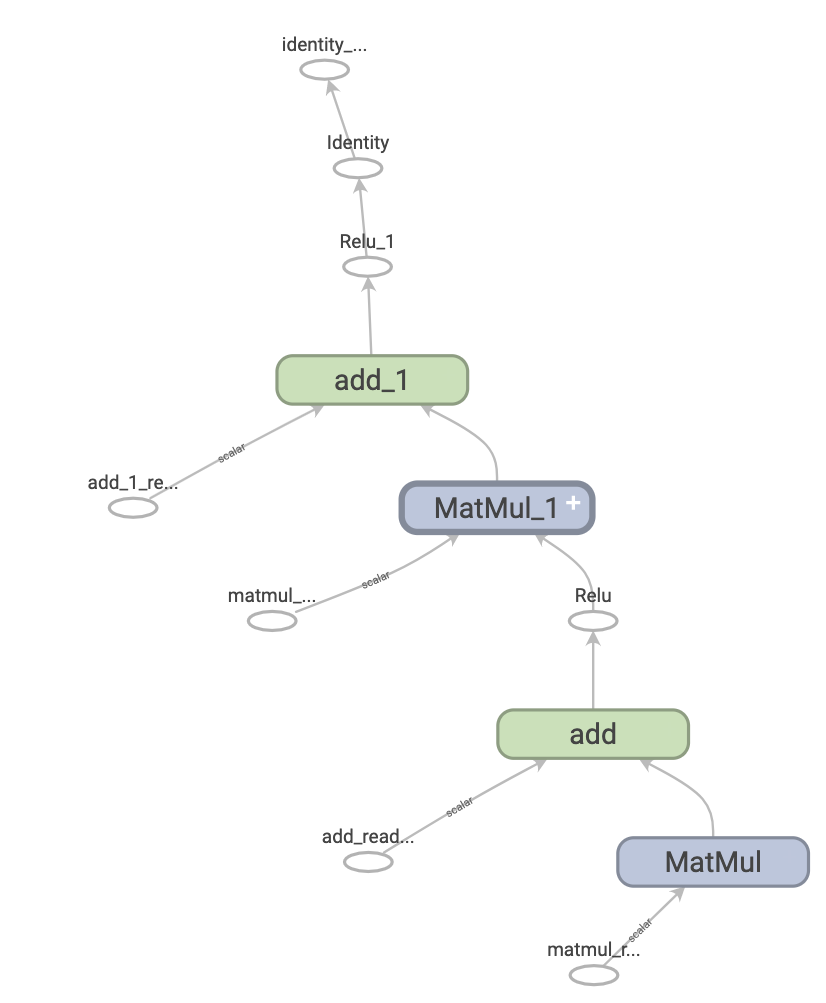
图的优势
使用图,您拥有极大的灵活性。您可以在没有 Python 解释器的环境中使用 TensorFlow 图,例如移动应用程序、嵌入式设备和后端服务器。TensorFlow 使用图作为保存的模型的格式,当它从 Python 导出它们时。
图也很容易优化,允许编译器执行以下转换:
- 通过在您的计算中折叠常量节点来静态推断张量的值(“常量折叠”)。
- 将计算的独立子部分分离,并在线程或设备之间进行拆分。
- 通过消除公共子表达式来简化算术运算。
有一个完整的优化系统,Grappler,用于执行此操作和其他加速操作。
简而言之,图非常有用,可以让您的 TensorFlow **快速**运行、**并行**运行,并在**多个设备**上高效运行。
但是,您仍然希望出于方便起见在 Python 中定义您的机器学习模型(或其他计算),然后在需要时自动构建图。
设置
导入一些必要的库
import tensorflow as tf
import timeit
from datetime import datetime
2023-11-28 02:20:45.671036: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-11-28 02:20:45.671078: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-11-28 02:20:45.672497: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
利用图
您通过使用tf.function在 TensorFlow 中创建和运行图,无论是直接调用还是作为装饰器。 tf.function将一个常规函数作为输入,并返回一个tf.types.experimental.PolymorphicFunction。**一个PolymorphicFunction是一个 Python 可调用对象,它从 Python 函数构建 TensorFlow 图。您使用tf.function的方式与它的 Python 等价物相同。**
# Define a Python function.
def a_regular_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# The Python type of `a_function_that_uses_a_graph` will now be a
# `PolymorphicFunction`.
a_function_that_uses_a_graph = tf.function(a_regular_function)
# Make some tensors.
x1 = tf.constant([[1.0, 2.0]])
y1 = tf.constant([[2.0], [3.0]])
b1 = tf.constant(4.0)
orig_value = a_regular_function(x1, y1, b1).numpy()
# Call a `tf.function` like a Python function.
tf_function_value = a_function_that_uses_a_graph(x1, y1, b1).numpy()
assert(orig_value == tf_function_value)
从表面上看,tf.function看起来像您使用 TensorFlow 操作编写的常规函数。但是,在内部,它非常不同。底层的PolymorphicFunction**在一个 API 中封装了多个tf.Graph(在多态性部分了解更多信息)。这就是tf.function能够为您提供图执行优势的方式,例如速度和可部署性(请参阅上面的图的优势)。
tf.function适用于一个函数及其调用的所有其他函数
def inner_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# Using the `tf.function` decorator makes `outer_function` into a
# `PolymorphicFunction`.
@tf.function
def outer_function(x):
y = tf.constant([[2.0], [3.0]])
b = tf.constant(4.0)
return inner_function(x, y, b)
# Note that the callable will create a graph that
# includes `inner_function` as well as `outer_function`.
outer_function(tf.constant([[1.0, 2.0]])).numpy()
array([[12.]], dtype=float32)
如果您使用过 TensorFlow 1.x,您会注意到,您无需定义Placeholder或tf.Session。
将 Python 函数转换为图
您使用 TensorFlow 编写的任何函数都将包含内置的 TF 操作和 Python 逻辑的混合,例如if-then子句、循环、break、return、continue等等。虽然 TensorFlow 操作很容易被tf.Graph捕获,但 Python 特定的逻辑需要经过额外的步骤才能成为图的一部分。 tf.function使用一个名为 AutoGraph 的库(tf.autograph)将 Python 代码转换为生成图的代码。
def simple_relu(x):
if tf.greater(x, 0):
return x
else:
return 0
# Using `tf.function` makes `tf_simple_relu` a `PolymorphicFunction` that wraps
# `simple_relu`.
tf_simple_relu = tf.function(simple_relu)
print("First branch, with graph:", tf_simple_relu(tf.constant(1)).numpy())
print("Second branch, with graph:", tf_simple_relu(tf.constant(-1)).numpy())
First branch, with graph: 1 Second branch, with graph: 0
虽然您不太可能需要直接查看图,但您可以检查输出以查看确切的结果。这些不容易阅读,所以不需要仔细查看!
# This is the graph-generating output of AutoGraph.
print(tf.autograph.to_code(simple_relu))
def tf__simple_relu(x):
with ag__.FunctionScope('simple_relu', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:
do_return = False
retval_ = ag__.UndefinedReturnValue()
def get_state():
return (do_return, retval_)
def set_state(vars_):
nonlocal retval_, do_return
(do_return, retval_) = vars_
def if_body():
nonlocal retval_, do_return
try:
do_return = True
retval_ = ag__.ld(x)
except:
do_return = False
raise
def else_body():
nonlocal retval_, do_return
try:
do_return = True
retval_ = 0
except:
do_return = False
raise
ag__.if_stmt(ag__.converted_call(ag__.ld(tf).greater, (ag__.ld(x), 0), None, fscope), if_body, else_body, get_state, set_state, ('do_return', 'retval_'), 2)
return fscope.ret(retval_, do_return)
# This is the graph itself.
print(tf_simple_relu.get_concrete_function(tf.constant(1)).graph.as_graph_def())
node {
name: "x"
op: "Placeholder"
attr {
key: "_user_specified_name"
value {
s: "x"
}
}
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "shape"
value {
shape {
}
}
}
}
node {
name: "Greater/y"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node {
name: "Greater"
op: "Greater"
input: "x"
input: "Greater/y"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
node {
name: "cond"
op: "StatelessIf"
input: "Greater"
input: "x"
attr {
key: "Tcond"
value {
type: DT_BOOL
}
}
attr {
key: "Tin"
value {
list {
type: DT_INT32
}
}
}
attr {
key: "Tout"
value {
list {
type: DT_BOOL
type: DT_INT32
}
}
}
attr {
key: "_lower_using_switch_merge"
value {
b: true
}
}
attr {
key: "_read_only_resource_inputs"
value {
list {
}
}
}
attr {
key: "else_branch"
value {
func {
name: "cond_false_31"
}
}
}
attr {
key: "output_shapes"
value {
list {
shape {
}
shape {
}
}
}
}
attr {
key: "then_branch"
value {
func {
name: "cond_true_30"
}
}
}
}
node {
name: "cond/Identity"
op: "Identity"
input: "cond"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node {
name: "cond/Identity_1"
op: "Identity"
input: "cond:1"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
node {
name: "Identity"
op: "Identity"
input: "cond/Identity_1"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
library {
function {
signature {
name: "cond_false_31"
input_arg {
name: "cond_placeholder"
type: DT_INT32
}
output_arg {
name: "cond_identity"
type: DT_BOOL
}
output_arg {
name: "cond_identity_1"
type: DT_INT32
}
}
node_def {
name: "cond/Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Const_1"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Const_2"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node_def {
name: "cond/Const_3"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Identity"
op: "Identity"
input: "cond/Const_3:output:0"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node_def {
name: "cond/Const_4"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node_def {
name: "cond/Identity_1"
op: "Identity"
input: "cond/Const_4:output:0"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
ret {
key: "cond_identity"
value: "cond/Identity:output:0"
}
ret {
key: "cond_identity_1"
value: "cond/Identity_1:output:0"
}
attr {
key: "_construction_context"
value {
s: "kEagerRuntime"
}
}
arg_attr {
key: 0
value {
attr {
key: "_output_shapes"
value {
list {
shape {
}
}
}
}
}
}
}
function {
signature {
name: "cond_true_30"
input_arg {
name: "cond_identity_1_x"
type: DT_INT32
}
output_arg {
name: "cond_identity"
type: DT_BOOL
}
output_arg {
name: "cond_identity_1"
type: DT_INT32
}
}
node_def {
name: "cond/Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Identity"
op: "Identity"
input: "cond/Const:output:0"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node_def {
name: "cond/Identity_1"
op: "Identity"
input: "cond_identity_1_x"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
ret {
key: "cond_identity"
value: "cond/Identity:output:0"
}
ret {
key: "cond_identity_1"
value: "cond/Identity_1:output:0"
}
attr {
key: "_construction_context"
value {
s: "kEagerRuntime"
}
}
arg_attr {
key: 0
value {
attr {
key: "_output_shapes"
value {
list {
shape {
}
}
}
}
attr {
key: "_user_specified_name"
value {
s: "x"
}
}
}
}
}
}
versions {
producer: 1645
min_consumer: 12
}
大多数情况下,tf.function将在没有特殊考虑的情况下工作。但是,有一些注意事项,tf.function指南可以在这里提供帮助,以及完整的 AutoGraph 参考。
多态性:一个tf.function,多个图
一个tf.Graph专门用于特定类型的输入(例如,具有特定dtype的张量或具有相同id()的对象)。
每次您使用一组无法由其任何现有图处理的参数(例如,具有新dtypes或不兼容形状的参数)调用tf.function时,它都会创建一个专门用于这些新参数的新tf.Graph。 tf.Graph输入的类型规范由tf.types.experimental.FunctionType表示,也称为**签名**。有关何时生成新tf.Graph、如何控制以及FunctionType如何有用的更多信息,请参阅使用tf.function获得更好的性能指南的跟踪规则部分。
tf.function将与该签名相对应的tf.Graph存储在ConcreteFunction中。**一个ConcreteFunction可以被认为是tf.Graph的包装器。**
@tf.function
def my_relu(x):
return tf.maximum(0., x)
# `my_relu` creates new graphs as it observes different input types.
print(my_relu(tf.constant(5.5)))
print(my_relu([1, -1]))
print(my_relu(tf.constant([3., -3.])))
tf.Tensor(5.5, shape=(), dtype=float32) tf.Tensor([1. 0.], shape=(2,), dtype=float32) tf.Tensor([3. 0.], shape=(2,), dtype=float32)
如果tf.function已经使用相同的输入类型被调用,它不会创建新的tf.Graph。
# These two calls do *not* create new graphs.
print(my_relu(tf.constant(-2.5))) # Input type matches `tf.constant(5.5)`.
print(my_relu(tf.constant([-1., 1.]))) # Input type matches `tf.constant([3., -3.])`.
tf.Tensor(0.0, shape=(), dtype=float32) tf.Tensor([0. 1.], shape=(2,), dtype=float32)
由于它由多个图支持,因此tf.function是(正如“PolymorphicFunction”这个名字所暗示的)**多态的**。这使得它能够支持比单个tf.Graph所能表示的更多输入类型,并优化每个tf.Graph以获得更好的性能。
# There are three `ConcreteFunction`s (one for each graph) in `my_relu`.
# The `ConcreteFunction` also knows the return type and shape!
print(my_relu.pretty_printed_concrete_signatures())
Input Parameters: x (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(), dtype=tf.float32, name=None) Output Type: TensorSpec(shape=(), dtype=tf.float32, name=None) Captures: None Input Parameters: x (POSITIONAL_OR_KEYWORD): List[Literal[1], Literal[-1]] Output Type: TensorSpec(shape=(2,), dtype=tf.float32, name=None) Captures: None Input Parameters: x (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(2,), dtype=tf.float32, name=None) Output Type: TensorSpec(shape=(2,), dtype=tf.float32, name=None) Captures: None
使用tf.function
到目前为止,您已经了解了如何简单地使用tf.function作为装饰器或包装器将 Python 函数转换为图。但在实践中,让tf.function正常工作可能很棘手!在接下来的部分中,您将了解如何使您的代码按预期与tf.function一起工作。
图执行与急切执行
tf.function中的代码可以急切地执行,也可以作为图执行。默认情况下,tf.function将其代码作为图执行
@tf.function
def get_MSE(y_true, y_pred):
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
y_true = tf.random.uniform([5], maxval=10, dtype=tf.int32)
y_pred = tf.random.uniform([5], maxval=10, dtype=tf.int32)
print(y_true)
print(y_pred)
tf.Tensor([3 5 2 7 7], shape=(5,), dtype=int32) tf.Tensor([1 1 7 6 0], shape=(5,), dtype=int32)
get_MSE(y_true, y_pred)
<tf.Tensor: shape=(), dtype=int32, numpy=19>
为了验证您的tf.function的图是否与它的等效 Python 函数执行相同的计算,您可以使用tf.config.run_functions_eagerly(True)使其急切地执行。这是一个开关,它**关闭了tf.function创建和运行图的能力**,而不是正常执行代码。
tf.config.run_functions_eagerly(True)
get_MSE(y_true, y_pred)
<tf.Tensor: shape=(), dtype=int32, numpy=19>
# Don't forget to set it back when you are done.
tf.config.run_functions_eagerly(False)
但是,tf.function在图执行和急切执行下可能表现不同。Python print函数是这两种模式差异的一个例子。让我们看看当您在函数中插入一个print语句并多次调用它时会发生什么。
@tf.function
def get_MSE(y_true, y_pred):
print("Calculating MSE!")
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
观察打印的内容
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
Calculating MSE!
输出令人惊讶吗?**get_MSE只打印了一次,即使它被调用了三次。**
为了解释,print语句是在tf.function运行原始代码以在称为“跟踪”的过程中创建图时执行的(请参阅tf.function指南的跟踪部分)。**跟踪将 TensorFlow 操作捕获到图中,而print不会被捕获到图中。**然后,该图将被执行三次,**而无需再次运行 Python 代码**。
作为健全性检查,让我们关闭图执行以进行比较
# Now, globally set everything to run eagerly to force eager execution.
tf.config.run_functions_eagerly(True)
# Observe what is printed below.
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
Calculating MSE! Calculating MSE! Calculating MSE!
tf.config.run_functions_eagerly(False)
print是一个Python 副作用,在将函数转换为tf.function时,您应该注意其他一些差异。在使用tf.function获得更好的性能指南的限制部分了解更多信息。
非严格执行
图执行只执行产生可观察效果的必要操作,这些操作包括
- 函数的返回值
- 记录在案的众所周知的副作用,例如
- 输入/输出操作,例如
tf.print - 调试操作,例如
tf.debugging中的断言函数 tf.Variable的变异
- 输入/输出操作,例如
这种行为通常被称为“非严格执行”,它与急切执行不同,急切执行会逐步执行程序中的所有操作,无论是否需要。
特别是,运行时错误检查不计入可观察到的效果。如果一个操作被跳过,因为它是不必要的,它不会引发任何运行时错误。
在下面的示例中,"不必要的"操作 tf.gather 在图执行期间被跳过,因此运行时错误 InvalidArgumentError 不会像在急切执行中那样被引发。不要依赖在执行图时会引发错误。
def unused_return_eager(x):
# Get index 1 will fail when `len(x) == 1`
tf.gather(x, [1]) # unused
return x
try:
print(unused_return_eager(tf.constant([0.0])))
except tf.errors.InvalidArgumentError as e:
# All operations are run during eager execution so an error is raised.
print(f'{type(e).__name__}: {e}')
tf.Tensor([0.], shape=(1,), dtype=float32)
@tf.function
def unused_return_graph(x):
tf.gather(x, [1]) # unused
return x
# Only needed operations are run during graph execution. The error is not raised.
print(unused_return_graph(tf.constant([0.0])))
tf.Tensor([0.], shape=(1,), dtype=float32)
tf.function 最佳实践
可能需要一些时间才能习惯 tf.function 的行为。为了快速入门,初次使用该函数的用户应该尝试用 @tf.function 装饰一些玩具函数,以获得从急切执行到图执行的经验。
为 tf.function 设计可能是编写与图兼容的 TensorFlow 程序的最佳选择。以下是一些提示
- 使用
tf.config.run_functions_eagerly频繁地在急切执行和图执行之间切换,以确定两种模式何时/何处出现分歧。 - 在 Python 函数之外创建
tf.Variable,并在函数内部修改它们。对于使用tf.Variable的对象,例如tf.keras.layers、tf.keras.Model和tf.keras.optimizers,也是如此。 - 避免编写依赖于外部 Python 变量的函数,不包括
tf.Variable和 Keras 对象。在tf.function指南 的依赖于 Python 全局变量和自由变量部分了解更多信息。 - 最好编写以张量和其他 TensorFlow 类型作为输入的函数。你可以传入其他类型的对象,但要小心!在
tf.function指南 的依赖于 Python 对象部分了解更多信息。 - 尽可能将计算包含在
tf.function中,以最大限度地提高性能增益。例如,装饰整个训练步骤或整个训练循环。
查看加速效果
tf.function 通常会提高代码的性能,但加速程度取决于你运行的计算类型。小型计算可能会被调用图的开销所支配。你可以像这样衡量性能差异
x = tf.random.uniform(shape=[10, 10], minval=-1, maxval=2, dtype=tf.dtypes.int32)
def power(x, y):
result = tf.eye(10, dtype=tf.dtypes.int32)
for _ in range(y):
result = tf.matmul(x, result)
return result
print("Eager execution:", timeit.timeit(lambda: power(x, 100), number=1000), "seconds")
Eager execution: 4.297045933999925 seconds
power_as_graph = tf.function(power)
print("Graph execution:", timeit.timeit(lambda: power_as_graph(x, 100), number=1000), "seconds")
Graph execution: 0.823222464999958 seconds
tf.function 通常用于加速训练循环,你可以在 Keras 指南的使用 tf.function 加速训练步骤部分了解更多信息。
性能和权衡
图可以加速你的代码,但创建图的过程会产生一些开销。对于某些函数,创建图所需的时间比执行图所需的时间更长。这种投入通常会通过后续执行的性能提升而迅速得到回报,但重要的是要注意,任何大型模型训练的前几个步骤可能会因为跟踪而变慢。
无论你的模型有多大,你都希望避免频繁跟踪。在控制重新跟踪部分,tf.function 指南 讨论了如何设置输入规范并使用张量参数来避免重新跟踪。如果你发现你的性能异常低下,最好检查一下你是否意外地进行了重新跟踪。
何时 tf.function 正在跟踪?
要确定你的 tf.function 何时正在跟踪,请在它的代码中添加一个 print 语句。作为经验法则,tf.function 每次跟踪时都会执行 print 语句。
@tf.function
def a_function_with_python_side_effect(x):
print("Tracing!") # An eager-only side effect.
return x * x + tf.constant(2)
# This is traced the first time.
print(a_function_with_python_side_effect(tf.constant(2)))
# The second time through, you won't see the side effect.
print(a_function_with_python_side_effect(tf.constant(3)))
Tracing! tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(11, shape=(), dtype=int32)
# This retraces each time the Python argument changes,
# as a Python argument could be an epoch count or other
# hyperparameter.
print(a_function_with_python_side_effect(2))
print(a_function_with_python_side_effect(3))
Tracing! tf.Tensor(6, shape=(), dtype=int32) Tracing! tf.Tensor(11, shape=(), dtype=int32)
新的 Python 参数总是会触发新图的创建,因此会进行额外的跟踪。
下一步
你可以在 API 参考页面上了解更多关于 tf.function 的信息,并按照 使用 tf.function 提高性能 指南进行操作。