
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概述
此 Colab 介绍了 DTensor,它是 TensorFlow 的扩展,用于同步分布式计算。
DTensor 提供了一个全局编程模型,允许开发人员编写在全局范围内对张量进行操作的应用程序,同时在内部管理跨设备的分布。DTensor 根据分片指令通过称为单程序多数据 (SPMD) 扩展的过程来分布程序和张量。
通过将应用程序与分片指令分离,DTensor 能够在单个设备、多个设备甚至多个客户端上运行相同的应用程序,同时保留其全局语义。
本指南介绍了用于分布式计算的 DTensor 概念,以及 DTensor 如何与 TensorFlow 集成。有关在模型训练中使用 DTensor 的演示,请参阅使用 DTensor 进行分布式训练教程。
设置
DTensor (tf.experimental.dtensor) 已成为 TensorFlow 2.9.0 版本的一部分。
首先导入 TensorFlow、dtensor,并将 TensorFlow 配置为使用 6 个虚拟 CPU。即使本示例使用虚拟 CPU,DTensor 在 CPU、GPU 或 TPU 设备上的工作方式也是相同的。
import tensorflow as tf
from tensorflow.experimental import dtensor
print('TensorFlow version:', tf.__version__)
def configure_virtual_cpus(ncpu):
phy_devices = tf.config.list_physical_devices('CPU')
tf.config.set_logical_device_configuration(phy_devices[0], [
tf.config.LogicalDeviceConfiguration(),
] * ncpu)
configure_virtual_cpus(6)
DEVICES = [f'CPU:{i}' for i in range(6)]
tf.config.list_logical_devices('CPU')
2024-01-17 02:31:17.231274: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-17 02:31:17.231320: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-17 02:31:17.232805: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered TensorFlow version: 2.15.0 [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:CPU:1', device_type='CPU'), LogicalDevice(name='/device:CPU:2', device_type='CPU'), LogicalDevice(name='/device:CPU:3', device_type='CPU'), LogicalDevice(name='/device:CPU:4', device_type='CPU'), LogicalDevice(name='/device:CPU:5', device_type='CPU')]
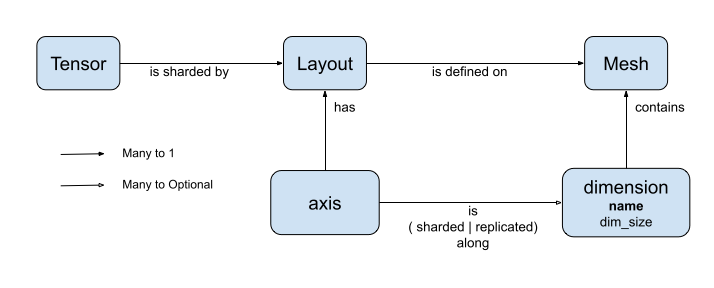
DTensor 的分布式张量模型
DTensor 引入了两个概念:dtensor.Mesh 和 dtensor.Layout。它们是用于对跨拓扑相关设备的张量分片进行建模的抽象。
Mesh定义了用于计算的设备列表。Layout定义了如何在Mesh上对张量维度进行分片。
网格
Mesh 代表一组设备的逻辑笛卡尔拓扑结构。笛卡尔网格的每个维度称为 **网格维度**,并用名称引用。同一 Mesh 内的网格维度名称必须唯一。
网格维度的名称由 Layout 引用,以描述 tf.Tensor 沿其每个轴的切片行为。这将在后面关于 Layout 的部分中详细介绍。
Mesh 可以看作是设备的多维数组。
在 1 维 Mesh 中,所有设备在单个网格维度中形成一个列表。以下示例使用 dtensor.create_mesh 从 6 个 CPU 设备创建一个网格,沿着网格维度 'x',大小为 6 个设备
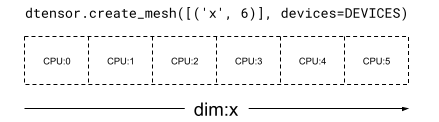
mesh_1d = dtensor.create_mesh([('x', 6)], devices=DEVICES)
print(mesh_1d)
Mesh.from_string(|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5)
Mesh 也可以是多维的。在以下示例中,6 个 CPU 设备形成了一个 3x2 网格,其中 'x' 网格维度的大小为 3 个设备,'y' 网格维度的大小为 2 个设备
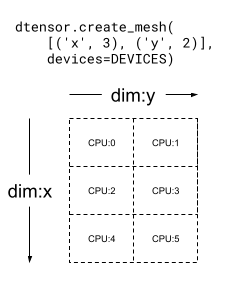
mesh_2d = dtensor.create_mesh([('x', 3), ('y', 2)], devices=DEVICES)
print(mesh_2d)
Mesh.from_string(|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5)
Layout
Layout 指定张量如何在 Mesh 上分布或切片。
Layout 的秩应与应用 Layout 的 Tensor 的秩相同。对于 Tensor 的每个轴,Layout 可以指定一个网格维度来对张量进行切片,或者将轴指定为“未切片”。张量在它未切片的任何网格维度上进行复制。
Layout 的秩和 Mesh 的维度数不需要匹配。 Layout 的 unsharded 轴不需要与网格维度相关联,并且 unsharded 网格维度不需要与 layout 轴相关联。
让我们分析几个 Layout 的示例,用于上一节中创建的 Mesh。
在 1 维网格上,例如 [("x", 6)](上一节中的 mesh_1d),Layout(["unsharded", "unsharded"], mesh_1d) 是一个秩为 2 的张量的布局,在 6 个设备上复制。 
layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh_1d)
使用相同的张量和网格,布局 Layout(['unsharded', 'x']) 将在 6 个设备上对张量的第二个轴进行切片。
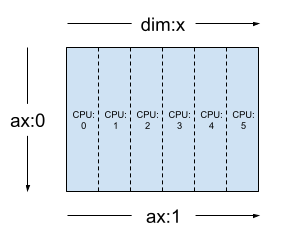
layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh_1d)
给定一个 2 维 3x2 网格,例如 [("x", 3), ("y", 2)](上一节中的 mesh_2d),Layout(["y", "x"], mesh_2d) 是一个秩为 2 的 Tensor 的布局,其第一个轴在网格维度 "y" 上进行切片,其第二个轴在网格维度 "x" 上进行切片。
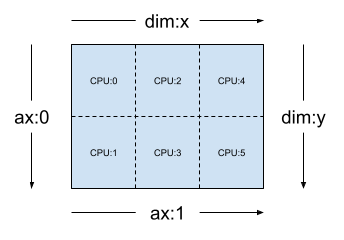
layout = dtensor.Layout(['y', 'x'], mesh_2d)
对于相同的 mesh_2d,布局 Layout(["x", dtensor.UNSHARDED], mesh_2d) 是一个秩为 2 的 Tensor 的布局,它在 "y" 上复制,其第一个轴在网格维度 x 上进行切片。
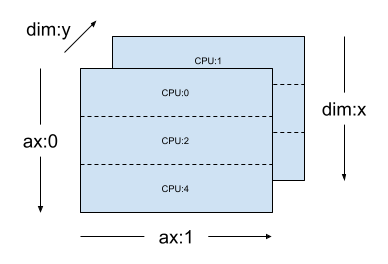
layout = dtensor.Layout(["x", dtensor.UNSHARDED], mesh_2d)
单客户端和多客户端应用程序
DTensor 支持单客户端和多客户端应用程序。colab Python 内核是单客户端 DTensor 应用程序的一个示例,其中只有一个 Python 进程。
在多客户端 DTensor 应用程序中,多个 Python 进程共同作为一个连贯的应用程序。多客户端 DTensor 应用程序中 Mesh 的笛卡尔网格可以跨越设备,无论它们是本地连接到当前客户端还是远程连接到另一个客户端。 Mesh 使用的所有设备的集合称为 *全局设备列表*。
在多客户端 DTensor 应用程序中创建 Mesh 是一个集体操作,其中 *全局设备列表* 对所有参与的客户端都是相同的,并且创建 Mesh 充当全局屏障。
在创建 Mesh 期间,每个客户端都会提供其 *本地设备列表* 以及预期的 *全局设备列表*。DTensor 会验证这两个列表是否一致。有关多客户端网格创建和 *全局设备列表* 的更多信息,请参阅 dtensor.create_mesh 和 dtensor.create_distributed_mesh 的 API 文档。
单客户端可以看作是多客户端的一个特例,只有一个客户端。在单客户端应用程序中,*全局设备列表* 与 *本地设备列表* 相同。
DTensor 作为切片张量
现在,开始使用 DTensor 编码。辅助函数 dtensor_from_array 演示了如何从类似于 tf.Tensor 的内容创建 DTensor。该函数执行两个步骤
- 将张量复制到网格上的每个设备。
- 根据其参数中请求的布局对副本进行切片。
def dtensor_from_array(arr, layout, shape=None, dtype=None):
"""Convert a DTensor from something that looks like an array or Tensor.
This function is convenient for quick doodling DTensors from a known,
unsharded data object in a single-client environment. This is not the
most efficient way of creating a DTensor, but it will do for this
tutorial.
"""
if shape is not None or dtype is not None:
arr = tf.constant(arr, shape=shape, dtype=dtype)
# replicate the input to the mesh
a = dtensor.copy_to_mesh(arr,
layout=dtensor.Layout.replicated(layout.mesh, rank=layout.rank))
# shard the copy to the desirable layout
return dtensor.relayout(a, layout=layout)
DTensor 的结构
DTensor 是一个 tf.Tensor 对象,但增加了 Layout 注释,该注释定义了其切片行为。DTensor 包含以下内容
- 全局张量元数据,包括张量的全局形状和数据类型。
- 一个
Layout,它定义了Tensor所属的Mesh,以及Tensor如何在Mesh上进行切片。 - 一个 **组件张量** 列表,每个
Mesh中的本地设备一个项目。
使用 dtensor_from_array,您可以创建第一个 DTensor,my_first_dtensor,并检查其内容
mesh = dtensor.create_mesh([("x", 6)], devices=DEVICES)
layout = dtensor.Layout([dtensor.UNSHARDED], mesh)
my_first_dtensor = dtensor_from_array([0, 1], layout)
# Examine the DTensor content
print(my_first_dtensor)
print("global shape:", my_first_dtensor.shape)
print("dtype:", my_first_dtensor.dtype)
tf.Tensor([0 1], layout="sharding_specs:unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(2,), dtype=int32) global shape: (2,) dtype: <dtype: 'int32'>
Layout 和 fetch_layout
DTensor 的布局不是 tf.Tensor 的常规属性。相反,DTensor 提供了一个函数 dtensor.fetch_layout 来访问 DTensor 的布局
print(dtensor.fetch_layout(my_first_dtensor))
assert layout == dtensor.fetch_layout(my_first_dtensor)
Layout.from_string(sharding_specs:unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5)
组件张量、pack 和 unpack
DTensor 由一个 **组件张量** 列表组成。 Mesh 中设备的组件张量是表示存储在此设备上的全局 DTensor 部分的 Tensor 对象。
DTensor 可以通过 dtensor.unpack 解包成组件张量。您可以使用 dtensor.unpack 检查 DTensor 的组件,并确认它们位于 Mesh 的所有设备上。
请注意,全局视图中组件张量的位置可能会相互重叠。例如,在完全复制布局的情况下,所有组件都是全局张量的相同副本。
for component_tensor in dtensor.unpack(my_first_dtensor):
print("Device:", component_tensor.device, ",", component_tensor)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor([0 1], shape=(2,), dtype=int32)
如所示,my_first_dtensor 是一个 [0, 1] 张量,复制到所有 6 个设备。
dtensor.unpack 的逆运算为 dtensor.pack。组件张量可以打包回 DTensor。
组件必须具有相同的秩和数据类型,这将是返回的 DTensor 的秩和数据类型。但是,对作为 dtensor.unpack 输入的组件张量的设备放置没有严格的要求:该函数将自动将组件张量复制到它们各自的对应设备。
packed_dtensor = dtensor.pack(
[[0, 1], [0, 1], [0, 1],
[0, 1], [0, 1], [0, 1]],
layout=layout
)
print(packed_dtensor)
tf.Tensor([0 1], layout="sharding_specs:unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(2,), dtype=int32)
将 DTensor 切片到 Mesh
到目前为止,您一直在使用 my_first_dtensor,它是一个在 dim-1 Mesh 上完全复制的秩为 1 的 DTensor。
接下来,创建和检查在 dim-2 Mesh 上切片的 DTensor。以下示例在 6 个 CPU 设备上的 3x2 Mesh 上执行此操作,其中网格维度 'x' 的大小为 3 个设备,网格维度 'y' 的大小为 2 个设备
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
在 dim-2 Mesh 上完全切片的秩为 2 的张量
创建一个 3x2 秩为 2 的 DTensor,将其第一个轴沿着 'x' 网格维度进行切片,将其第二个轴沿着 'y' 网格维度进行切片。
- 由于张量形状等于所有切片轴上的网格维度,因此每个设备都会收到 DTensor 的单个元素。
- 组件张量的秩始终与全局形状的秩相同。DTensor 采用此约定作为一种简单的方法来保留信息,以定位组件张量与全局 DTensor 之间的关系。
fully_sharded_dtensor = dtensor_from_array(
tf.reshape(tf.range(6), (3, 2)),
layout=dtensor.Layout(["x", "y"], mesh))
for raw_component in dtensor.unpack(fully_sharded_dtensor):
print("Device:", raw_component.device, ",", raw_component)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor([[0]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor([[1]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor([[2]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor([[3]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor([[4]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor([[5]], shape=(1, 1), dtype=int32)
在 dim-2 Mesh 上完全复制的秩为 2 的张量
为了比较,创建一个 3x2 秩为 2 的 DTensor,完全复制到相同的 dim-2 Mesh。
- 由于 DTensor 是完全复制的,因此每个设备都会收到 3x2 DTensor 的完整副本。
- 组件张量的秩与全局形状的秩相同——这一事实是微不足道的,因为在这种情况下,组件张量的形状与全局形状相同。
fully_replicated_dtensor = dtensor_from_array(
tf.reshape(tf.range(6), (3, 2)),
layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh))
# Or, layout=tensor.Layout.fully_replicated(mesh, rank=2)
for component_tensor in dtensor.unpack(fully_replicated_dtensor):
print("Device:", component_tensor.device, ",", component_tensor)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32)
在 dim-2 Mesh 上混合的秩为 2 的张量
完全切片和完全复制之间会怎么样?
DTensor 允许 Layout 是混合的,沿着某些轴进行切片,但在其他轴上进行复制。
例如,您可以以以下方式对相同的 3x2 秩为 2 的 DTensor 进行切片
- 第一个轴沿着
'x'网格维度进行切片。 - 第二个轴沿着
'y'网格维度进行复制。
要实现这种切片方案,您只需要将第二个轴的切片规范从 'y' 替换为 dtensor.UNSHARDED,以表明您要沿着第二个轴进行复制的意图。布局对象将类似于 Layout(['x', dtensor.UNSHARDED], mesh)
hybrid_sharded_dtensor = dtensor_from_array(
tf.reshape(tf.range(6), (3, 2)),
layout=dtensor.Layout(['x', dtensor.UNSHARDED], mesh))
for component_tensor in dtensor.unpack(hybrid_sharded_dtensor):
print("Device:", component_tensor.device, ",", component_tensor)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor([[0 1]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor([[0 1]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor([[2 3]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor([[2 3]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor([[4 5]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor([[4 5]], shape=(1, 2), dtype=int32)
您可以检查创建的 DTensor 的组件张量,并验证它们是否确实根据您的方案进行了切片。用图表说明情况可能会有所帮助
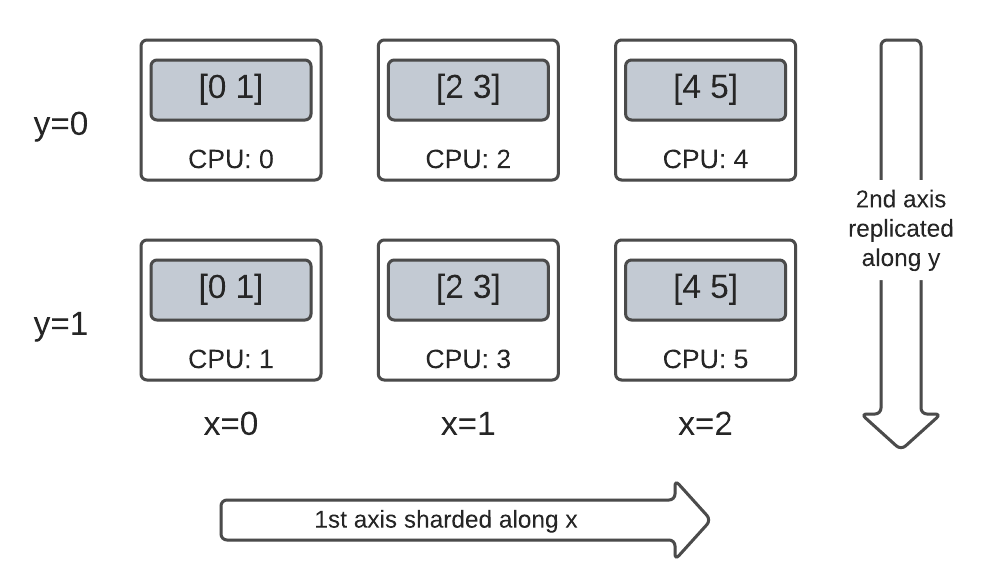
Tensor.numpy() 和切片 DTensor
请注意,在切片 DTensor 上调用 .numpy() 方法会引发错误。引发错误的原因是为了防止意外地从多个计算设备收集数据到支持返回的 NumPy 数组的主机 CPU 设备
print(fully_replicated_dtensor.numpy())
try:
fully_sharded_dtensor.numpy()
except tf.errors.UnimplementedError:
print("got an error as expected for fully_sharded_dtensor")
try:
hybrid_sharded_dtensor.numpy()
except tf.errors.UnimplementedError:
print("got an error as expected for hybrid_sharded_dtensor")
[[0 1] [2 3] [4 5]] got an error as expected for fully_sharded_dtensor got an error as expected for hybrid_sharded_dtensor
DTensor 上的 TensorFlow API
DTensor 旨在成为您程序中张量的直接替代品。 使用 tf.Tensor 的 TensorFlow Python API,例如 Ops 库函数、tf.function、tf.GradientTape,也可以与 DTensor 一起使用。
为了实现这一点,对于每个 TensorFlow 图,DTensor 在一个称为 *SPMD 扩展* 的过程中生成并执行一个等效的 SPMD 图。 DTensor SPMD 扩展中的几个关键步骤是
- 在 TensorFlow 图中传播 DTensor 的分片
Layout - 用全局 DTensor 上的等效 TensorFlow Ops 重写全局 DTensor 上的 TensorFlow Ops,并在必要时插入集体和通信 Ops
- 将后端中立的 TensorFlow Ops 降级为后端特定的 TensorFlow Ops。
最终结果是 **DTensor 是张量的直接替代品**。
有两种方法可以触发 DTensor 执行
- 作为 Python 函数的操作数的 DTensor,例如
tf.matmul(a, b),如果a、b或两者都是 DTensor,将通过 DTensor 运行。 - 请求 Python 函数的结果为 DTensor,例如
dtensor.call_with_layout(tf.ones, layout, shape=(3, 2)),将通过 DTensor 运行,因为我们请求tf.ones的输出根据layout进行分片。
DTensor 作为操作数
许多 TensorFlow API 函数以 tf.Tensor 作为其操作数,并返回 tf.Tensor 作为其结果。 对于这些函数,您可以通过传入 DTensor 作为操作数来表达通过 DTensor 运行函数的意图。 本节以 tf.matmul(a, b) 为例。
完全复制的输入和输出
在这种情况下,DTensor 是完全复制的。 在 Mesh 的每个设备上,
- 操作数
a的组件张量是[[1, 2, 3], [4, 5, 6]](2x3) - 操作数
b的组件张量是[[6, 5], [4, 3], [2, 1]](3x2) - 计算包括单个
MatMul的(2x3, 3x2) -> 2x2, - 结果
c的组件张量是[[20, 14], [56,41]](2x2)
浮点乘运算的总数是 6 device * 4 result * 3 mul = 72。
mesh = dtensor.create_mesh([("x", 6)], devices=DEVICES)
layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)
a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=layout)
b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=layout)
c = tf.matmul(a, b) # runs 6 identical matmuls in parallel on 6 devices
# `c` is a DTensor replicated on all devices (same as `a` and `b`)
print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)
print("components:")
for component_tensor in dtensor.unpack(c):
print(component_tensor.device, component_tensor.numpy())
Sharding spec: ['unsharded', 'unsharded'] components: /job:localhost/replica:0/task:0/device:CPU:0 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:1 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:2 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:3 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:4 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:5 [[20 14] [56 41]]
沿收缩轴分片操作数
您可以通过分片操作数 a 和 b 来减少每个设备的计算量。 tf.matmul 的一种流行的分片方案是沿收缩轴分片操作数,这意味着沿第二轴分片 a,沿第一轴分片 b。
根据此方案分片的全局矩阵乘积可以通过本地矩阵乘法有效地执行,本地矩阵乘法并发运行,然后进行集体约简以聚合本地结果。 这也是 实现分布式矩阵点积的规范方法。
浮点乘运算的总数是 6 devices * 4 result * 1 = 24,与上面的完全复制情况 (72) 相比,减少了 3 倍。 3 倍的减少是由于沿 x 网格维度分片,该维度的大小为 3 个设备。
顺序运行的运算数量的减少是同步模型并行加速训练的主要机制。
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
a_layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh)
a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)
b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)
b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)
c = tf.matmul(a, b)
# `c` is a DTensor replicated on all devices (same as `a` and `b`)
print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)
Sharding spec: ['unsharded', 'unsharded']
额外分片
您可以在输入上执行额外分片,它们会适当地传递到结果中。 例如,您可以将操作数 a 沿其第一轴应用到 'y' 网格维度上的额外分片。 额外分片将传递到结果 c 的第一轴。
浮点乘运算的总数是 6 devices * 2 result * 1 = 12,与上面的情况 (24) 相比,又减少了 2 倍。 2 倍的减少是由于沿 y 网格维度分片,该维度的大小为 2 个设备。
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
a_layout = dtensor.Layout(['y', 'x'], mesh)
a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)
b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)
b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)
c = tf.matmul(a, b)
# The sharding of `a` on the first axis is carried to `c'
print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)
print("components:")
for component_tensor in dtensor.unpack(c):
print(component_tensor.device, component_tensor.numpy())
Sharding spec: ['y', 'unsharded'] components: /job:localhost/replica:0/task:0/device:CPU:0 [[20 14]] /job:localhost/replica:0/task:0/device:CPU:1 [[56 41]] /job:localhost/replica:0/task:0/device:CPU:2 [[20 14]] /job:localhost/replica:0/task:0/device:CPU:3 [[56 41]] /job:localhost/replica:0/task:0/device:CPU:4 [[20 14]] /job:localhost/replica:0/task:0/device:CPU:5 [[56 41]]
DTensor 作为输出
对于不接受操作数但返回可以分片的张量结果的 Python 函数呢? 此类函数的示例包括
对于这些 Python 函数,DTensor 提供了 dtensor.call_with_layout,它热切地执行带有 DTensor 的 Python 函数,并确保返回的张量是具有请求的 Layout 的 DTensor。
help(dtensor.call_with_layout)
Help on function call_with_layout in module tensorflow.dtensor.python.api:
call_with_layout(fn: Callable[..., Any], layout: Optional[tensorflow.dtensor.python.layout.Layout], *args, **kwargs) -> Any
Calls a function in the DTensor device scope if `layout` is not None.
If `layout` is not None, `fn` consumes DTensor(s) as input and produces a
DTensor as output; a DTensor is a tf.Tensor with layout-related attributes.
If `layout` is None, `fn` consumes and produces regular tf.Tensors.
Args:
fn: A supported TF API function such as tf.zeros.
layout: Optional, the layout of the output DTensor.
*args: Arguments given to `fn`.
**kwargs: Keyword arguments given to `fn`.
Returns:
The return value of `fn` transformed to a DTensor if requested.
热切执行的 Python 函数通常只包含单个非平凡的 TensorFlow Op。
要使用使用 dtensor.call_with_layout 发射多个 TensorFlow Ops 的 Python 函数,该函数应转换为 tf.function。 调用 tf.function 是单个 TensorFlow Op。 当调用 tf.function 时,DTensor 在分析 tf.function 的计算图时,可以在任何中间张量被实例化之前执行布局传播。
发射单个 TensorFlow Op 的 API
如果函数发射单个 TensorFlow Op,您可以直接将 dtensor.call_with_layout 应用于该函数
help(tf.ones)
Help on function ones in module tensorflow.python.ops.array_ops:
ones(shape, dtype=tf.float32, name=None, layout=None)
Creates a tensor with all elements set to one (1).
See also `tf.ones_like`, `tf.zeros`, `tf.fill`, `tf.eye`.
This operation returns a tensor of type `dtype` with shape `shape` and
all elements set to one.
>>> tf.ones([3, 4], tf.int32)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]], dtype=int32)>
Args:
shape: A `list` of integers, a `tuple` of integers, or a 1-D `Tensor` of
type `int32`.
dtype: Optional DType of an element in the resulting `Tensor`. Default is
`tf.float32`.
name: Optional string. A name for the operation.
layout: Optional, `tf.experimental.dtensor.Layout`. If provided, the result
is a [DTensor](https://tensorflowcn.cn/guide/dtensor_overview) with the
provided layout.
Returns:
A `Tensor` with all elements set to one (1).
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
ones = dtensor.call_with_layout(tf.ones, dtensor.Layout(['x', 'y'], mesh), shape=(6, 4))
print(ones)
tf.Tensor({"CPU:0": [[1 1]
[1 1]], "CPU:1": [[1 1]
[1 1]], "CPU:2": [[1 1]
[1 1]], "CPU:3": [[1 1]
[1 1]], "CPU:4": [[1 1]
[1 1]], "CPU:5": [[1 1]
[1 1]]}, layout="sharding_specs:x,y, mesh:|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(6, 4), dtype=float32)
发射多个 TensorFlow Op 的 API
如果 API 发射多个 TensorFlow Op,请通过 tf.function 将函数转换为单个 Op。 例如,tf.random.stateleess_normal
help(tf.random.stateless_normal)
Help on function stateless_random_normal in module tensorflow.python.ops.stateless_random_ops:
stateless_random_normal(shape, seed, mean=0.0, stddev=1.0, dtype=tf.float32, name=None, alg='auto_select')
Outputs deterministic pseudorandom values from a normal distribution.
This is a stateless version of `tf.random.normal`: if run twice with the
same seeds and shapes, it will produce the same pseudorandom numbers. The
output is consistent across multiple runs on the same hardware (and between
CPU and GPU), but may change between versions of TensorFlow or on non-CPU/GPU
hardware.
Args:
shape: A 1-D integer Tensor or Python array. The shape of the output tensor.
seed: A shape [2] Tensor, the seed to the random number generator. Must have
dtype `int32` or `int64`. (When using XLA, only `int32` is allowed.)
mean: A 0-D Tensor or Python value of type `dtype`. The mean of the normal
distribution.
stddev: A 0-D Tensor or Python value of type `dtype`. The standard deviation
of the normal distribution.
dtype: The float type of the output: `float16`, `bfloat16`, `float32`,
`float64`. Defaults to `float32`.
name: A name for the operation (optional).
alg: The RNG algorithm used to generate the random numbers. See
`tf.random.stateless_uniform` for a detailed explanation.
Returns:
A tensor of the specified shape filled with random normal values.
ones = dtensor.call_with_layout(
tf.function(tf.random.stateless_normal),
dtensor.Layout(['x', 'y'], mesh),
shape=(6, 4),
seed=(1, 1))
print(ones)
tf.Tensor({"CPU:0": [[0.0368092842 1.76192284]
[1.22868407 -0.731756687]], "CPU:1": [[0.255247623 -0.13820985]
[-0.747412503 1.06443202]], "CPU:2": [[-0.395325899 -0.836183369]
[0.581941128 -0.2587713]], "CPU:3": [[0.476060659 0.406645179]
[-0.110623844 -1.49052978]], "CPU:4": [[0.645035267 1.36384416]
[2.18210244 -0.965060234]], "CPU:5": [[-1.70534277 1.32558191]
[0.972473264 0.972343624]]}, layout="sharding_specs:x,y, mesh:|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(6, 4), dtype=float32)
允许使用 tf.function 包装发射单个 TensorFlow Op 的 Python 函数。 唯一的警告是支付创建 tf.function 的相关成本和复杂性。
ones = dtensor.call_with_layout(
tf.function(tf.ones),
dtensor.Layout(['x', 'y'], mesh),
shape=(6, 4))
print(ones)
tf.Tensor({"CPU:0": [[1 1]
[1 1]], "CPU:1": [[1 1]
[1 1]], "CPU:2": [[1 1]
[1 1]], "CPU:3": [[1 1]
[1 1]], "CPU:4": [[1 1]
[1 1]], "CPU:5": [[1 1]
[1 1]]}, layout="sharding_specs:x,y, mesh:|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(6, 4), dtype=float32)
从 tf.Variable 到 dtensor.DVariable
在 Tensorflow 中,tf.Variable 是可变 Tensor 值的持有者。 使用 DTensor,相应的变量语义由 dtensor.DVariable 提供。
为 DTensor 变量引入新类型 DVariable 的原因是,DVariable 还有一个额外的要求,即布局不能从其初始值更改。
mesh = dtensor.create_mesh([("x", 6)], devices=DEVICES)
layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)
v = dtensor.DVariable(
initial_value=dtensor.call_with_layout(
tf.function(tf.random.stateless_normal),
layout=layout,
shape=tf.TensorShape([64, 32]),
seed=[1, 1],
dtype=tf.float32))
print(v.handle)
assert layout == dtensor.fetch_layout(v)
tf.Tensor(<ResourceHandle(name="Variable/1", device="/job:localhost/replica:0/task:0/device:CPU:0", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>, layout="sharding_specs:unsharded,unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(), dtype=resource)
除了匹配 layout 的要求外,DVariable 的行为与 tf.Variable 相同。 例如,您可以将 DVariable 添加到 DTensor 中,
a = dtensor.call_with_layout(tf.ones, layout=layout, shape=(64, 32))
b = v + a # add DVariable and DTensor
print(b)
tf.Tensor([[2.66521645 2.36637592 1.77863169 ... -1.18624139 2.26035929 0.664066315] [0.511952519 0.655031443 0.122243524 ... 0.0424078107 1.67057109 0.912334144] [0.769825 1.42743981 3.13473773 ... 1.16159868 0.628931046 0.733521938] ... [0.388001859 2.72882509 2.92771554 ... 1.17472672 1.72462416 1.5047121] [-0.252545118 0.761886716 1.72119033 ... 0.775034547 2.8065362 1.00457215] [1.23498726 0.584536672 1.15659761 ... 0.955793858 1.11440909 0.18848455]], layout="sharding_specs:unsharded,unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(64, 32), dtype=float32)
您也可以将 DTensor 分配给 DVariable
v.assign(a) # assign a DTensor to a DVariable
print(a)
tf.Tensor([[1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] ... [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1]], layout="sharding_specs:unsharded,unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(64, 32), dtype=float32)
尝试通过分配具有不兼容布局的 DTensor 来改变 DVariable 的布局会导致错误
# variable's layout is immutable.
another_mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
b = dtensor.call_with_layout(tf.ones,
layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], another_mesh),
shape=(64, 32))
try:
v.assign(b)
except:
print("exception raised")
exception raised
下一步是什么?
在这个 colab 中,您了解了 DTensor,它是 TensorFlow 的扩展,用于分布式计算。 要在教程中尝试这些概念,请查看 使用 DTensor 进行分布式训练。