
概述
TensorFlow 模型分析 (TFMA) 是一个用于执行模型评估的库。
- 适用于:机器学习工程师或数据科学家
- 他们:希望分析和理解他们的 TensorFlow 模型
- 它:是一个独立的库或 TFX 管道的组件
- 它:以分布式方式对大量数据上的模型进行评估,使用与训练中定义相同的指标。这些指标在数据切片上进行比较,并在 Jupyter 或 Colab 笔记本中可视化。
- 与:一些模型自省工具(如 TensorBoard)提供模型自省不同
TFMA 使用 Apache Beam 以分布式方式对大量数据执行计算。以下部分介绍如何设置基本的 TFMA 评估管道。有关底层实现的更多详细信息,请参阅 架构。
如果您只想直接开始,请查看我们的 colab 笔记本。
您也可以从 tensorflow.org 查看此页面。
支持的模型类型
TFMA 旨在支持基于 TensorFlow 的模型,但也可以轻松扩展以支持其他框架。从历史上看,TFMA 需要创建 EvalSavedModel 才能使用 TFMA,但最新版本的 TFMA 支持多种类型的模型,具体取决于用户的需求。如果使用基于 tf.estimator 的模型并且需要自定义训练时间指标,则仅需 设置 EvalSavedModel。
请注意,由于 TFMA 现在基于服务模型运行,因此 TFMA 将不再自动评估在训练时添加的指标。如果使用 keras 模型,则此情况的例外情况是,因为 keras 会将使用的指标与保存的模型一起保存。但是,如果这是硬性要求,则最新版本的 TFMA 向后兼容,因此仍然可以在 TFMA 管道中运行 EvalSavedModel。
下表总结了默认支持的模型
| 模型类型 | 训练时间指标 | 训练后指标 |
|---|---|---|
| TF2 (keras) | Y* | Y |
| TF2 (通用) | N/A | Y |
| EvalSavedModel (estimator) | Y | Y |
| 无 (pd.DataFrame 等) | N/A | Y |
- 训练时间指标是指在训练时定义并与模型一起保存的指标(无论是 TFMA EvalSavedModel 还是 keras 保存的模型)。训练后指标是指通过
tfma.MetricConfig添加的指标。 - 通用 TF2 模型是自定义模型,它们导出可用于推理的签名,并且不基于 keras 或 estimator。
有关如何设置和配置这些不同模型类型的更多信息,请参阅 常见问题解答。
设置
在运行评估之前,需要进行少量设置。首先,必须定义一个 tfma.EvalConfig 对象,该对象提供要评估的模型、指标和切片的规范。其次,需要创建一个 tfma.EvalSharedModel,它指向评估期间要使用的实际模型(或模型)。定义完这些后,通过调用 tfma.run_model_analysis 并提供适当的数据集来执行评估。有关更多详细信息,请参阅 设置 指南。
如果在 TFX 管道中运行,请参阅 TFX 指南,了解如何配置 TFMA 以作为 TFX 评估器 组件运行。
示例
单模型评估
以下示例使用 tfma.run_model_analysis 对服务模型执行评估。有关所需不同设置的说明,请参阅 设置 指南。
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
对于分布式评估,请使用分布式运行器构建 Apache Beam 管道。在管道中,使用 tfma.ExtractEvaluateAndWriteResults 进行评估并写入结果。可以使用 tfma.load_eval_result 加载结果以进行可视化。
例如
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
模型验证
要对候选模型和基线模型执行模型验证,请更新配置以包含阈值设置,并将两个模型传递给 tfma.run_model_analysis。
例如
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
可视化
可以使用 TFMA 中包含的前端组件在 Jupyter 笔记本中可视化 TFMA 评估结果。例如
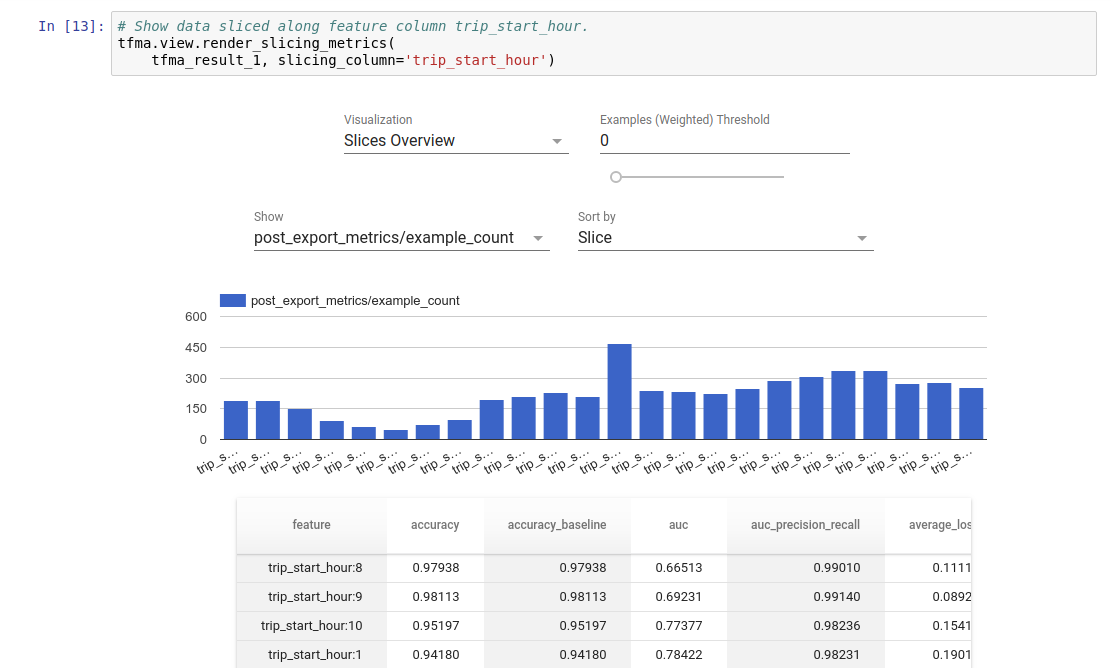 .
.