
将数据放入 TFX 管道后,您可以使用 TFX 组件来分析和转换数据。您甚至可以在训练模型之前使用这些工具。
分析和转换数据有很多原因
- 查找数据中的问题。常见问题包括
- 缺失数据,例如具有空值的特征。
- 将标签视为特征,以便您的模型在训练期间可以查看正确答案。
- 特征值超出预期范围。
- 数据异常。
- 迁移学习模型的预处理与训练数据不匹配。
- 设计更有效的特征集。例如,您可以识别
- 特别有信息的特征。
- 冗余特征。
- 规模差异很大的特征,可能会减慢学习速度。
- 几乎没有或没有独特预测信息的特征。
TFX 工具既可以帮助查找数据错误,也可以帮助进行特征工程。
TensorFlow 数据验证
概述
TensorFlow 数据验证识别训练和服务数据中的异常,并可以通过检查数据自动创建模式。该组件可以配置为检测数据中的不同类别异常。它可以
- 通过将数据统计信息与编码用户期望的模式进行比较来执行有效性检查。
- 通过比较训练和服务数据中的示例来检测训练服务偏差。
- 通过查看一系列数据来检测数据漂移。
我们分别记录了这些功能中的每一个
基于模式的示例验证
TensorFlow 数据验证通过将数据统计信息与模式进行比较来识别输入数据中的任何异常。模式对输入数据应满足的属性进行编码,例如数据类型或分类值,并且可以由用户修改或替换。
Tensorflow 数据验证通常在 TFX 管道上下文中多次调用:(i) 对于从 ExampleGen 获得的每个拆分,(ii) 对于 Transform 使用的所有预转换数据,以及 (iii) 对于 Transform 生成的所有后转换数据。在 Transform 上下文中调用时 (ii-iii),可以通过定义 stats_options_updater_fn 来设置统计选项和基于模式的约束。当验证非结构化数据(例如文本特征)时,这特别有用。有关示例,请参阅 用户代码。
高级模式功能
本节介绍更高级的模式配置,可以帮助处理特殊设置。
稀疏特征
在示例中编码稀疏特征通常会引入多个特征,这些特征预计对所有示例具有相同的价态。例如,稀疏特征
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
稀疏特征定义需要一个或多个索引和一个值特征,这些特征引用模式中存在的特征。明确定义稀疏特征使 TFDV 能够检查所有引用特征的价态是否匹配。
一些用例在特征之间引入了类似的价态限制,但并不一定编码稀疏特征。使用稀疏特征可以解决您的问题,但并不理想。
模式环境
默认情况下,验证假设管道中的所有示例都遵循单个模式。在某些情况下,引入轻微的模式变化是必要的,例如用作标签的特征在训练期间是必需的(并且应该被验证),但在服务期间是缺失的。环境可以用来表达这些需求,特别是 default_environment()、in_environment()、not_in_environment()。
例如,假设一个名为“LABEL”的特征在训练期间是必需的,但在服务期间预计会缺失。这可以通过以下方式表达:
- 在模式中定义两个不同的环境:["SERVING", "TRAINING"],并将“LABEL”仅与环境“TRAINING”关联。
- 将训练数据与环境“TRAINING”关联,将服务数据与环境“SERVING”关联。
模式生成
输入数据模式被指定为 TensorFlow 模式 的实例。
开发者可以依靠 TensorFlow 数据验证的自动模式构建,而不是从头开始手动构建模式。具体来说,TensorFlow 数据验证会根据在管道中可用的训练数据的统计信息自动构建初始模式。用户只需查看此自动生成的模式,根据需要进行修改,将其检入版本控制系统,并将其显式地推送到管道中以进行进一步验证。
TFDV 包含 infer_schema() 来自动生成模式。例如
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
这将根据以下规则触发自动模式生成
如果模式已经自动生成,则按原样使用。
否则,TensorFlow 数据验证将检查可用的数据统计信息,并为数据计算合适的模式。
注意:自动生成的模式是尽力而为的,只尝试推断数据的基本属性。预计用户会根据需要对其进行审查和修改。
训练-服务偏差检测
概述
TensorFlow 数据验证可以检测训练数据和服务数据之间的分布偏差。分布偏差发生在训练数据的特征值分布与服务数据的特征值分布显著不同时。分布偏差的一个主要原因是使用完全不同的语料库来生成训练数据,以克服所需语料库中初始数据的缺乏。另一个原因是错误的采样机制,该机制只选择服务数据的子样本进行训练。
示例场景
有关配置训练-服务偏差检测的信息,请参阅 TensorFlow 数据验证入门指南。
漂移检测
漂移检测支持在连续的数据跨度之间(即跨度 N 和跨度 N+1 之间)进行,例如在不同天的训练数据之间。我们用 L-无穷大距离 来表示分类特征的漂移,用近似的 Jensen-Shannon 散度 来表示数值特征的漂移。您可以设置阈值距离,以便在漂移高于可接受范围时收到警告。设置正确的距离通常是一个需要领域知识和实验的迭代过程。
有关配置漂移检测的信息,请参阅 TensorFlow 数据验证入门指南。
使用可视化来检查您的数据
TensorFlow 数据验证提供了用于可视化特征值分布的工具。通过在 Jupyter 笔记本中使用 Facets 检查这些分布,您可以发现数据中的常见问题。
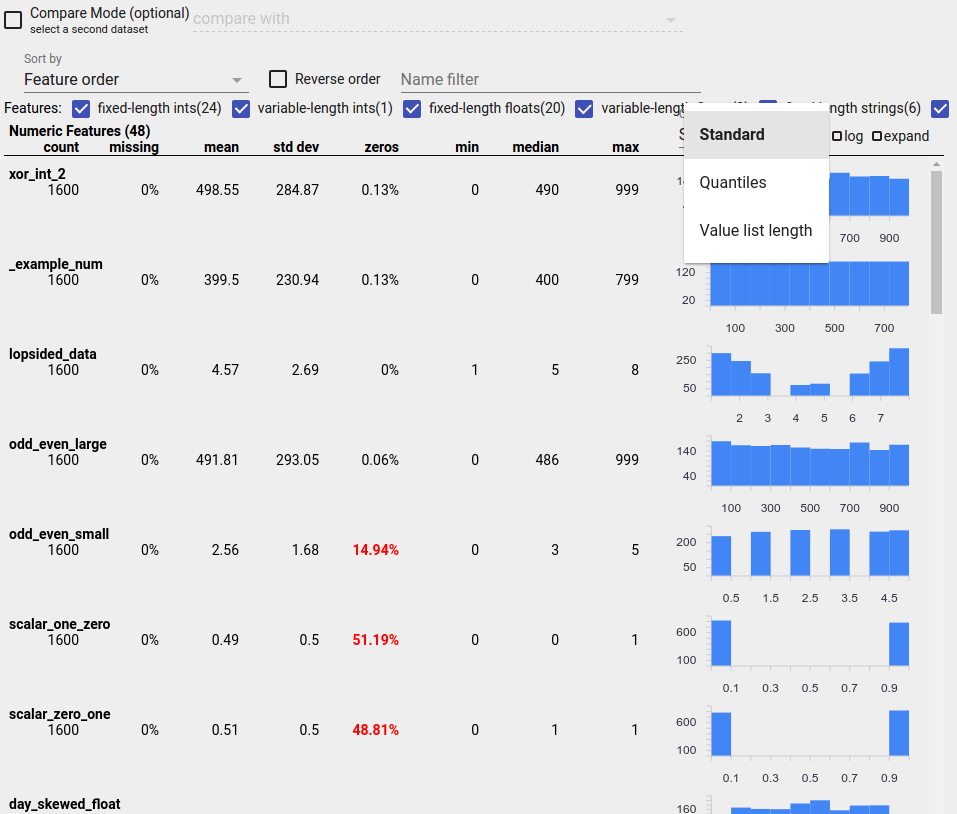
识别可疑分布
您可以使用 Facets 概述显示来查找特征值的可疑分布,从而识别数据中的常见错误。
不平衡数据
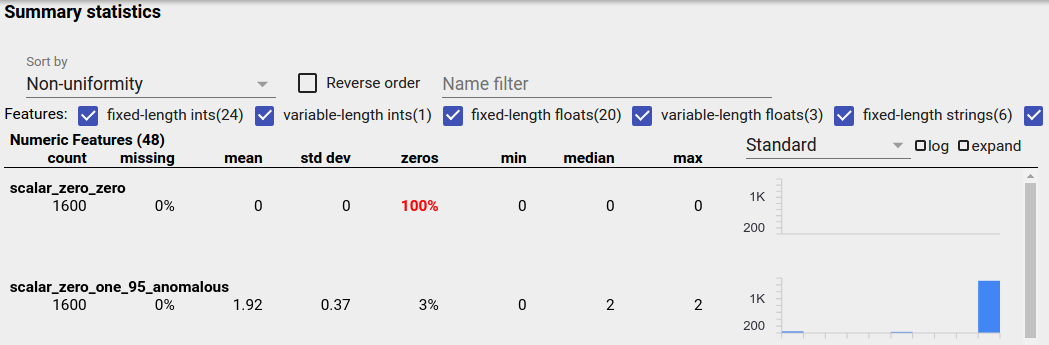
不平衡特征是指一个特征中一个值占主导地位的特征。不平衡特征可能自然出现,但如果一个特征始终具有相同的值,则可能存在数据错误。要在 Facets 概述中检测不平衡特征,请从“按排序”下拉菜单中选择“非均匀性”。
最不平衡的特征将列在每个特征类型列表的顶部。例如,以下屏幕截图显示了一个特征,该特征全部为零,另一个特征高度不平衡,位于“数值特征”列表的顶部
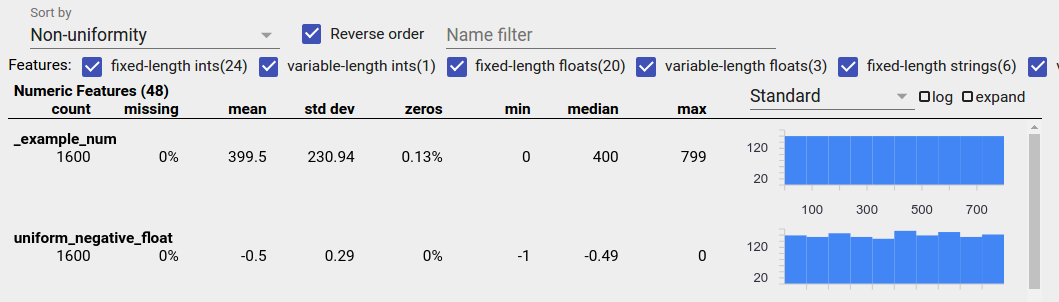
均匀分布的数据
均匀分布的特征是指所有可能的值以接近相同的频率出现的一个特征。与不平衡数据一样,这种分布可能自然出现,但也可能是由数据错误造成的。
要在 Facets 概述中检测均匀分布的特征,请从“按排序”下拉菜单中选择“非均匀性”,并选中“反转顺序”复选框
如果字符串数据有 20 个或更少的唯一值,则使用条形图表示,如果超过 20 个唯一值,则使用累积分布图表示。因此,对于字符串数据,均匀分布可能显示为上面的扁平条形图或下面的直线

可能产生均匀分布数据的错误
以下是一些可能产生均匀分布数据的常见错误
使用字符串来表示非字符串数据类型,例如日期。例如,对于具有“2017-03-01-11-45-03”等表示形式的日期时间特征,您将拥有许多唯一值。唯一值将均匀分布。
将“行号”等索引作为特征包含在内。在这里,您也有许多唯一值。
缺失数据
要检查一个特征是否完全缺失值
- 从“按排序”下拉菜单中选择“缺失/零的量”。
- 选中“反转顺序”复选框。
- 查看“缺失”列,以查看特征中具有缺失值的实例的百分比。
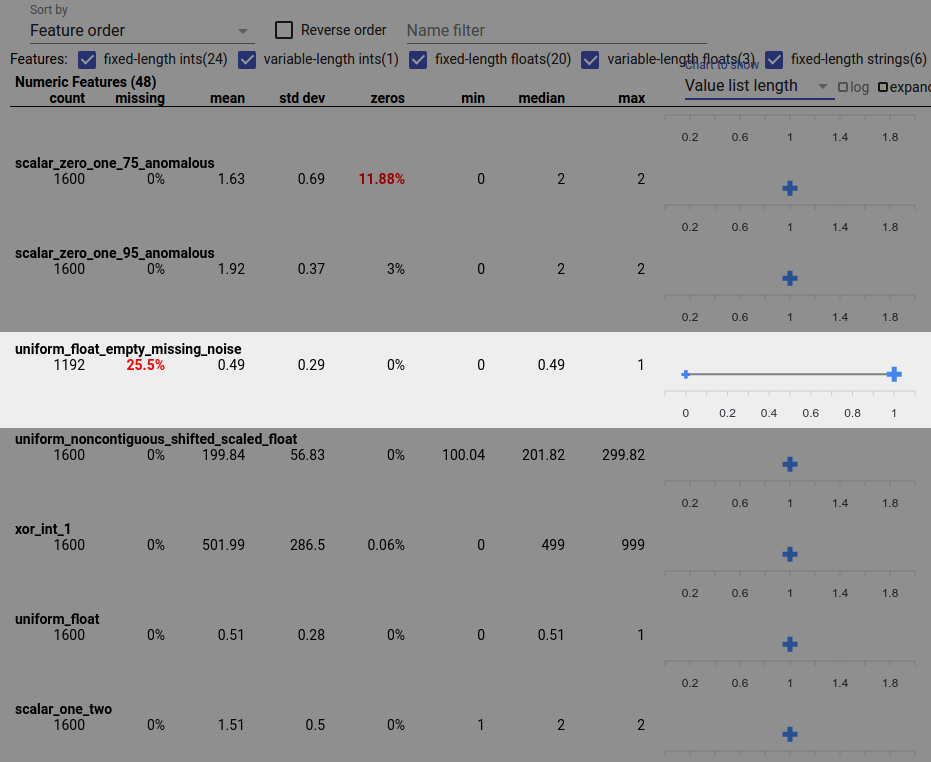
数据错误也会导致特征值不完整。例如,您可能期望一个特征的值列表始终包含三个元素,但发现有时它只包含一个元素。要检查不完整的值或特征值列表没有预期元素数量的其他情况
从右侧的“要显示的图表”下拉菜单中选择“值列表长度”。
查看每个特征行右侧的图表。该图表显示了特征的值列表长度范围。例如,下面屏幕截图中突出显示的行显示了一个特征,该特征具有一些零长度的值列表
特征之间规模的巨大差异
如果您的特征在规模上差异很大,则模型可能难以学习。例如,如果一些特征在 0 到 1 之间变化,而另一些特征在 0 到 1,000,000,000 之间变化,那么您在规模上存在很大差异。比较特征之间的“最大值”和“最小值”列,以查找规模差异很大的特征。
考虑对特征值进行归一化,以减少这些巨大的差异。
具有无效标签的标签
TensorFlow 的 Estimators 对它们接受的标签数据类型有限制。例如,二元分类器通常只适用于 {0, 1} 标签。
在 Facets 概述中查看标签值,并确保它们符合 Estimators 的要求。