
本教程向您展示如何使用 TensorFlow Transform(tf.Transform 库)为机器学习 (ML) 实现数据预处理。TensorFlow 的 tf.Transform 库允许您通过数据预处理管道定义实例级和全通道数据转换。这些管道使用 Apache Beam 高效执行,并创建 TensorFlow 图作为副产品,以便在模型提供服务时应用与训练期间相同的转换。
本教程提供了一个端到端示例,使用 Dataflow 作为 Apache Beam 的运行器。它假设您熟悉 BigQuery、Dataflow、Vertex AI 和 TensorFlow 的 Keras API。它还假设您有一些使用 Jupyter Notebook 的经验,例如使用 Vertex AI Workbench。
本教程还假设您熟悉 Google Cloud 上的预处理类型、挑战和选项的概念,如 ML 数据预处理:选项和建议 中所述。
目标
- 使用
tf.Transform库实现 Apache Beam 管道。 - 在 Dataflow 中运行管道。
- 使用
tf.Transform库实现 TensorFlow 模型。 - 训练和使用模型进行预测。
成本
本教程使用 Google Cloud 的以下计费组件
要估计运行本教程的成本(假设您将所有资源使用了一整天),请使用预配置的 定价计算器。
开始之前
在 Google Cloud Console 中,在项目选择器页面上,选择或 创建 Google Cloud 项目。
确保您的 Cloud 项目已启用结算。了解如何 检查项目是否已启用结算。
启用 Dataflow、Vertex AI 和 Notebooks API。 启用 API
此解决方案的 Jupyter Notebook
以下 Jupyter Notebook 显示了实现示例
- Notebook 1 涵盖数据预处理。详细信息将在后面的 实现 Apache Beam 管道 部分中提供。
- Notebook 2 涵盖模型训练。详细信息将在后面的 实现 TensorFlow 模型 部分中提供。
在以下部分中,您将克隆这些 Notebook,然后执行这些 Notebook 以了解实现示例的工作原理。
启动用户管理的 Notebook 实例
在 Google Cloud Console 中,转到 **Vertex AI Workbench** 页面。
在 **用户管理的 Notebook** 选项卡上,点击 **+ 新建 Notebook**。
为实例类型选择 **TensorFlow Enterprise 2.8(带 LTS)无 GPU**。
点击 **创建**。
创建 Notebook 后,等待 JupyterLab 的代理完成初始化。准备就绪后,将在 Notebook 名称旁边显示 **打开 JupyterLab**。
克隆 Notebook
在 **用户管理的 Notebook** 选项卡上,在 Notebook 名称旁边,点击 **打开 JupyterLab**。JupyterLab 界面将在新选项卡中打开。
如果 JupyterLab 显示 **构建推荐** 对话框,请点击 **取消** 以拒绝建议的构建。
在 **启动器** 选项卡上,点击 **终端**。
在终端窗口中,克隆 Notebook
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
实现 Apache Beam 管道
本节和下一节 在 Dataflow 中运行管道 提供了笔记本 1 的概述和上下文。笔记本提供了一个实际示例,描述了如何使用 tf.Transform 库来预处理数据。本示例使用 Natality 数据集,该数据集用于根据各种输入预测婴儿体重。数据存储在公共 natality 表中 BigQuery。
运行笔记本 1
在 JupyterLab 界面中,点击 **文件 > 从路径打开**,然后输入以下路径
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynb点击 **编辑 > 清除所有输出**。
在 **安装所需软件包** 部分,执行第一个单元格以运行
pip install apache-beam命令。输出的最后部分如下
Successfully installed ...您可以忽略输出中的依赖项错误。您无需立即重启内核。
执行第二个单元格以运行
pip install tensorflow-transform命令。输出的最后部分如下Successfully installed ... Note: you may need to restart the kernel to use updated packages.您可以忽略输出中的依赖项错误。
点击 **内核 > 重启内核**。
执行 **确认已安装的软件包** 和 **创建 setup.py 以将软件包安装到 Dataflow 容器** 部分中的单元格。
在 **设置全局标志** 部分,在
PROJECT和BUCKET旁边,将your-project替换为您的 Cloud 项目 ID,然后执行单元格。执行笔记本中所有剩余的单元格,直到最后一个单元格。有关每个单元格中操作的详细信息,请参阅笔记本中的说明。
管道的概述
在笔记本示例中,Dataflow 以大规模运行 tf.Transform 管道来准备数据并生成转换工件。本文档后面的部分将描述执行管道中每个步骤的函数。总体管道步骤如下
- 从 BigQuery 读取训练数据。
- 使用
tf.Transform库分析和转换训练数据。 - 将转换后的训练数据写入 Cloud Storage 中的 TFRecord 格式。
- 从 BigQuery 读取评估数据。
- 使用步骤 2 生成的
transform_fn图表转换评估数据。 - 将转换后的训练数据写入 Cloud Storage 中的 TFRecord 格式。
- 将转换工件写入 Cloud Storage,这些工件将在以后用于创建和导出模型。
以下示例显示了总体管道的 Python 代码。后面的部分将提供对每个步骤的解释和代码清单。
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
从 BigQuery 读取原始训练数据
第一步是使用 read_from_bq 函数从 BigQuery 读取原始训练数据。此函数返回一个从 BigQuery 中提取的 raw_dataset 对象。您传递一个 data_size 值,并传递一个 step 值,该值可以是 train 或 eval。BigQuery 源查询使用 get_source_query 函数构建,如以下示例所示
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
在执行 tf.Transform 预处理之前,您可能需要执行典型的基于 Apache Beam 的处理,包括 Map、Filter、Group 和 Window 处理。在本示例中,代码使用 beam.Map(prep_bq_row) 方法清理从 BigQuery 读取的记录,其中 prep_bq_row 是一个自定义函数。此自定义函数将分类特征的数字代码转换为人类可读的标签。
此外,为了使用 tf.Transform 库来分析和转换从 BigQuery 中提取的 raw_data 对象,您需要创建一个 raw_dataset 对象,该对象是 raw_data 和 raw_metadata 对象的元组。 raw_metadata 对象使用 create_raw_metadata 函数创建,如下所示
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
当您执行笔记本中定义此方法的单元格后面的单元格时,将显示 raw_metadata.schema 对象的内容。它包含以下列
gestation_weeks(类型:FLOAT)is_male(类型:BYTES)mother_age(类型:FLOAT)mother_race(类型:BYTES)plurality(类型:FLOAT)weight_pounds(类型:FLOAT)
转换原始训练数据
假设您想对训练数据的输入原始特征应用典型的预处理转换,以将其准备用于 ML。这些转换包括全通和实例级别操作,如以下表格所示
| 输入特征 | 转换 | 所需的统计信息 | 类型 | 输出特征 |
|---|---|---|---|---|
weight_pound |
无 | 无 | NA | weight_pound |
mother_age |
归一化 | 平均值、方差 | 全通 | mother_age_normalized |
mother_age |
等大小分箱 | 分位数 | 全通 | mother_age_bucketized |
mother_age |
计算对数 | 无 | 实例级别 |
mother_age_log
|
plurality |
指示是单胎还是多胎 | 无 | 实例级别 | is_multiple |
is_multiple |
将名义值转换为数字索引 | 词汇表 | 全通 | is_multiple_index |
gestation_weeks |
在 0 到 1 之间缩放 | 最小值、最大值 | 全通 | gestation_weeks_scaled |
mother_race |
将名义值转换为数字索引 | 词汇表 | 全通 | mother_race_index |
is_male |
将名义值转换为数字索引 | 词汇表 | 全通 | is_male_index |
这些转换在 preprocess_fn 函数中实现,该函数期望一个张量字典 (input_features) 并返回一个已处理特征字典 (output_features)。
以下代码显示了 preprocess_fn 函数的实现,使用 tf.Transform 全通转换 API(以 tft. 为前缀)和 TensorFlow(以 tf. 为前缀)实例级别操作
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
除了前面的示例中的转换之外,tf.Transform 框架 还有其他几种转换,包括以下表格中列出的转换
| 转换 | 应用于 | 描述 |
|---|---|---|
scale_by_min_max |
数值特征 | 将数值列缩放至范围 [output_min, output_max] |
scale_to_0_1 |
数值特征 | 返回一个列,该列是输入列缩放至范围 [0,1] |
scale_to_z_score |
数值特征 | 返回一个标准化列,其平均值为 0,方差为 1 |
tfidf |
文本特征 | 将 x 中的词语映射到它们的词频 * 逆文档频率 |
compute_and_apply_vocabulary |
分类特征 | 为分类特征生成词汇表,并将其映射到具有此词汇表的整数 |
ngrams |
文本特征 | 创建 SparseTensor 的 n 元语法 |
hash_strings |
分类特征 | 将字符串哈希到桶中 |
pca |
数值特征 | 使用有偏协方差计算数据集上的 PCA |
bucketize |
数值特征 | 返回一个等大小(基于分位数)的分箱列,为每个输入分配一个分箱索引 |
为了将 preprocess_fn 函数中实现的转换应用于上一管道步骤中生成的 raw_train_dataset 对象,您使用 AnalyzeAndTransformDataset 方法。此方法期望 raw_dataset 对象作为输入,应用 preprocess_fn 函数,并生成 transformed_dataset 对象和 transform_fn 图表。以下代码说明了此处理
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
转换在两个阶段应用于原始数据:分析阶段和转换阶段。本文档后面的图 3 显示了如何将 AnalyzeAndTransformDataset 方法分解为 AnalyzeDataset 方法和 TransformDataset 方法。
分析阶段
在分析阶段,原始训练数据在全通过程中进行分析,以计算转换所需的统计信息。这包括计算平均值、方差、最小值、最大值、分位数和词汇表。分析过程期望一个原始数据集(原始数据加上原始元数据),并生成两个输出
transform_fn:一个 TensorFlow 图表,其中包含分析阶段中计算的统计信息以及转换逻辑(使用这些统计信息)作为实例级别操作。如 保存图表 中的后面讨论,transform_fn图表被保存以附加到模型serving_fn函数。这使得能够对在线预测数据点应用相同的转换。transform_metadata:一个描述转换后数据的预期模式的对象。
以下图表(图 1)说明了分析阶段

tf.Transform 分析阶段。tf.Transform 分析器 包括 min、max、sum、size、mean、var、covariance、quantiles、vocabulary 和 pca。
转换阶段
在转换阶段,分析阶段生成的 transform_fn 图表用于在实例级别过程中转换原始训练数据,以生成转换后的训练数据。转换后的训练数据与转换后的元数据(由分析阶段生成)配对,以生成 transformed_train_dataset 数据集。
以下图表(图 2)说明了转换阶段

tf.Transform 转换阶段。为了预处理特征,您在 preprocess_fn 函数的实现中调用所需的 tensorflow_transform 转换(在代码中导入为 tft)。例如,当您调用 tft.scale_to_z_score 操作时,tf.Transform 库将此函数调用转换为平均值和方差分析器,在分析阶段计算统计信息,然后将这些统计信息应用于在转换阶段归一化数值特征。所有这些操作都是通过调用 AnalyzeAndTransformDataset(preprocess_fn) 方法自动完成的。
此调用生成的 transformed_metadata.schema 实体包含以下列
gestation_weeks_scaled(类型:FLOAT)is_male_index(类型:INT,is_categorical:True)is_multiple_index(类型:INT,is_categorical:True)mother_age_bucketized(类型:INT, 是否为分类特征:True)mother_age_log(类型:FLOAT)mother_age_normalized(类型:FLOAT)mother_race_index(类型:INT, 是否为分类特征:True)weight_pounds(类型:FLOAT)
如本系列第一部分的预处理操作中所述,特征转换将分类特征转换为数值表示。转换后,分类特征由整数值表示。在transformed_metadata.schema实体中,INT类型列的is_categorical标志指示该列表示分类特征还是真实数值特征。
写入转换后的训练数据
在使用preprocess_fn函数通过分析和转换阶段对训练数据进行预处理后,您可以将数据写入接收器,以便用于训练 TensorFlow 模型。当您使用 Dataflow 执行 Apache Beam 管道时,接收器是 Cloud Storage。否则,接收器是本地磁盘。虽然您可以将数据写入固定宽度格式文件的 CSV 文件,但 TensorFlow 数据集的推荐文件格式是 TFRecord 格式。这是一种简单的面向记录的二进制格式,由tf.train.Example 协议缓冲区消息组成。
每个tf.train.Example 记录包含一个或多个特征。这些特征在被馈送到模型进行训练时会转换为张量。以下代码将转换后的数据集写入指定位置的 TFRecord 文件
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
读取、转换和写入评估数据
在您转换训练数据并生成transform_fn 图之后,您可以使用它来转换评估数据。首先,您使用前面在从 BigQuery 读取原始训练数据中描述的read_from_bq函数从 BigQuery 读取和清理评估数据,并为step参数传递eval的值。然后,您使用以下代码将原始评估数据集(raw_dataset)转换为预期的转换格式(transformed_dataset)
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
当您转换评估数据时,仅实例级操作适用,使用transform_fn 图中的逻辑和从训练数据分析阶段计算的统计信息。换句话说,您不会以全通方式分析评估数据以计算新的统计信息,例如评估数据中用于数值特征的 z 分数归一化的均值和方差。相反,您使用从训练数据计算的统计信息以实例级方式转换评估数据。
因此,您在训练数据的上下文中使用AnalyzeAndTransform方法来计算统计信息并转换数据。同时,您在转换评估数据的上下文中使用TransformDataset方法仅使用在训练数据上计算的统计信息来转换数据。
然后,您将数据写入接收器(Cloud Storage 或本地磁盘,具体取决于运行器)中的 TFRecord 格式,以便在训练过程中评估 TensorFlow 模型。为此,您使用写入转换后的训练数据中讨论的write_tfrecords函数。以下图表(图 3)显示了在训练数据的分析阶段生成的transform_fn 图如何用于转换评估数据。

transform_fn 图转换评估数据。保存图
tf.Transform 预处理管道中的最后一步是存储工件,其中包括由训练数据的分析阶段生成的transform_fn 图。存储工件的代码显示在以下write_transform_artefacts函数中
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
这些工件将在以后用于模型训练和导出以供服务。还将生成以下工件,如下一节所示
saved_model.pb: 表示 TensorFlow 图,其中包含转换逻辑(transform_fn图),该逻辑将附加到模型服务接口以将原始数据点转换为转换后的格式。variables: 包含在训练数据的分析阶段计算的统计信息,并在saved_model.pb工件中的转换逻辑中使用。assets: 包含词汇表文件,每个使用compute_and_apply_vocabulary方法处理的分类特征一个,用于在服务期间将输入的原始名义值转换为数值索引。transformed_metadata: 包含描述转换后数据的模式的schema.json文件的目录。
在 Dataflow 中运行管道
在您定义tf.Transform 管道后,您可以使用 Dataflow 运行该管道。以下图表(图 4)显示了示例中描述的tf.Transform 管道的 Dataflow 执行图。
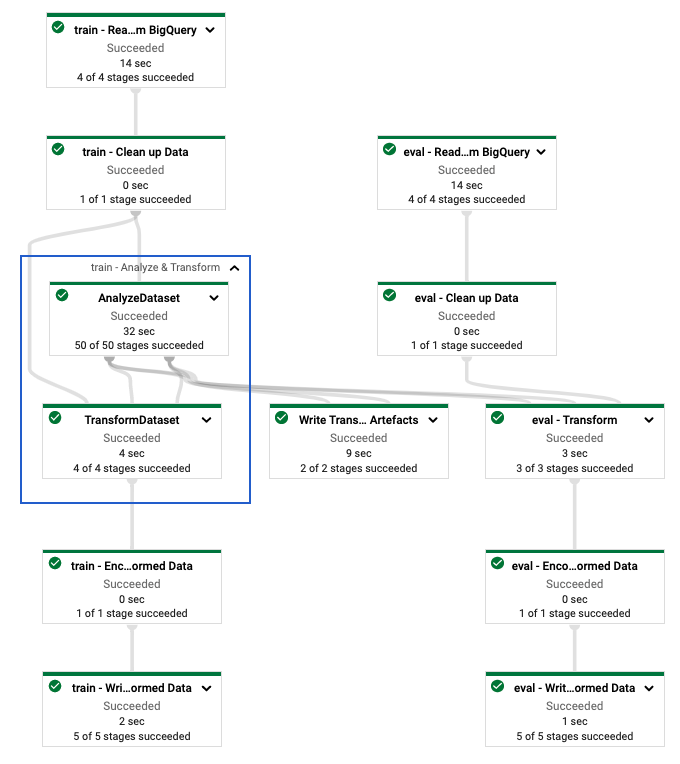
tf.Transform 管道的 Dataflow 执行图。在您执行 Dataflow 管道以预处理训练和评估数据后,您可以通过执行笔记本中的最后一个单元格来探索生成的 Cloud Storage 中的对象。本节中的代码片段显示了结果,其中YOUR_BUCKET_NAME 是您的 Cloud Storage 存储桶的名称。
TFRecord 格式的转换后的训练和评估数据存储在以下位置
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
转换工件生成在以下位置
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
以下列表是管道的输出,显示了生成的數據对象和工件
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
实现 TensorFlow 模型
本节和下一节训练模型并将其用于预测,为笔记本 2 提供了概述和上下文。笔记本提供了一个预测婴儿体重的示例 ML 模型。在本示例中,TensorFlow 模型使用 Keras API 实现。该模型使用由前面解释的tf.Transform 预处理管道生成的數據和工件。
运行笔记本 2
在 JupyterLab 界面中,点击 **文件 > 从路径打开**,然后输入以下路径
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynb点击 **编辑 > 清除所有输出**。
在**安装所需软件包**部分中,执行第一个单元格以运行
pip install tensorflow-transform命令。输出的最后部分如下
Successfully installed ... Note: you may need to restart the kernel to use updated packages.您可以忽略输出中的依赖项错误。
在**内核**菜单中,选择**重启内核**。
执行 **确认已安装的软件包** 和 **创建 setup.py 以将软件包安装到 Dataflow 容器** 部分中的单元格。
在**设置全局标志**部分中,在
PROJECT和BUCKET旁边,将your-project替换为您的 Cloud 项目 ID,然后执行该单元格。执行笔记本中所有剩余的单元格,直到最后一个单元格。有关每个单元格中操作的详细信息,请参阅笔记本中的说明。
模型创建概述
创建模型的步骤如下
- 使用存储在
transformed_metadata目录中的模式信息创建特征列。 - 使用 Keras API 创建宽而深的模型,使用特征列作为模型的输入。
- 创建
tfrecords_input_fn函数,使用转换工件读取和解析训练和评估数据。 - 训练和评估模型。
- 通过定义一个包含附加了
transform_fn图的serving_fn函数来导出训练后的模型。 - 使用
saved_model_cli工具检查导出的模型。 - 使用导出的模型进行预测。
本文档没有解释如何构建模型,因此没有详细讨论模型的构建或训练方式。但是,以下部分显示了如何使用存储在transformed_metadata 目录中的信息(由tf.Transform 过程生成)来创建模型的特征列。本文档还显示了在导出模型以供服务时,如何将transform_fn 图用于serving_fn 函数中。
在模型训练中使用生成的转换工件
当您训练 TensorFlow 模型时,您使用在前面的数据处理步骤中生成的转换后的train 和eval 对象。这些对象存储为 TFRecord 格式的碎片文件。在前面的步骤中生成的transformed_metadata 目录中的模式信息可用于解析数据(tf.train.Example 对象),以馈送到模型进行训练和评估。
解析数据
因为您读取 TFRecord 格式的文件以使用训练和评估数据馈送模型,所以您需要解析文件中的每个tf.train.Example 对象以创建特征(张量)字典。这确保了特征使用特征列映射到模型输入层,特征列充当模型训练和评估接口。要解析数据,您使用从前面的步骤中生成的工件创建的TFTransformOutput 对象
从在前面的预处理步骤中生成并保存的工件创建
TFTransformOutput对象,如保存图部分中所述tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)从
TFTransformOutput对象中提取feature_spec对象tf_transform_output.transformed_feature_spec()使用
feature_spec对象指定tf.train.Example对象中包含的特征,如tfrecords_input_fn函数中所示def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
创建特征列
管道在transformed_metadata 目录中生成模式信息,该信息描述了模型在训练和评估时预期的转换后数据的模式。模式包含特征名称和数据类型,例如以下内容
gestation_weeks_scaled(类型:FLOAT)is_male_index(类型:INT,is_categorical:True)is_multiple_index(类型:INT,is_categorical:True)mother_age_bucketized(类型:INT, 是否为分类特征:True)mother_age_log(类型:FLOAT)mother_age_normalized(类型:FLOAT)mother_race_index(类型:INT, 是否为分类特征:True)weight_pounds(类型:FLOAT)
要查看此信息,请使用以下命令
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
以下代码显示了如何使用特征名称创建特征列
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
该代码为数值特征创建tf.feature_column.numeric_column 列,为分类特征创建tf.feature_column.categorical_column_with_identity 列。
您还可以创建扩展特征列,如本系列第一部分的选项 C:TensorFlow 中所述。在本系列使用的示例中,通过使用tf.feature_column.crossed_column 特征列交叉mother_race 和mother_age_bucketized 特征,创建了一个新的特征mother_race_X_mother_age_bucketized。使用tf.feature_column.embedding_column 特征列创建此交叉特征的低维密集表示。
以下图表(图 5)显示了转换后的数据以及如何使用转换后的元数据来定义和训练 TensorFlow 模型

导出模型以供服务预测
使用 Keras API 训练 TensorFlow 模型后,您需要将训练后的模型导出为 SavedModel 对象,以便它可以为新的数据点提供预测服务。导出模型时,您需要定义其接口,即服务期间预期的输入特征模式。此输入特征模式在 serving_fn 函数中定义,如下面的代码所示
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
在服务期间,模型期望数据点以原始形式(即转换前的原始特征)提供。因此,serving_fn 函数接收原始特征并将它们存储在 features 对象中,作为 Python 字典。但是,如前所述,训练后的模型期望数据点以转换后的模式提供。为了将原始特征转换为模型接口预期的 transformed_features 对象,您可以使用以下步骤将保存的 transform_fn 图应用于 features 对象
从在之前预处理步骤中生成和保存的工件创建
TFTransformOutput对象tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)从
TFTransformOutput对象创建TransformFeaturesLayer对象model.tft_layer = tf_transform_output.transform_features_layer()使用
TransformFeaturesLayer对象应用transform_fn图transformed_features = model.tft_layer(features)
下图(图 6)说明了导出用于服务的模型的最后一步

transform_fn 图。训练模型并将其用于预测
您可以通过执行笔记本的单元格在本地训练模型。有关如何使用 Vertex AI 训练打包代码并在规模上训练模型的示例,请参阅 Google Cloud cloudml-samples GitHub 存储库中的示例和指南。
当您使用 saved_model_cli 工具检查导出的 SavedModel 对象时,您会看到签名定义 signature_def 的 inputs 元素包含原始特征,如下面的示例所示
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
笔记本的剩余单元格将向您展示如何使用导出的模型进行本地预测,以及如何使用 Vertex AI Prediction 将模型部署为微服务。重要的是要强调,在这两种情况下,输入(样本)数据点都处于原始模式。
清理
为了避免因本教程中使用的资源而给您的 Google Cloud 帐户带来额外费用,请删除包含这些资源的项目。
删除项目
在 Google Cloud Console 中,转到管理资源页面。
在项目列表中,选择要删除的项目,然后单击删除。
在对话框中,键入项目 ID,然后单击关闭以删除项目。
下一步
- 要了解有关 Google Cloud 上机器学习的数据预处理的概念、挑战和选项,请参阅本系列的第一篇文章,用于 ML 的数据预处理:选项和建议。
- 有关如何在 Dataflow 上实现、打包和运行 tf.Transform 管道的更多信息,请参阅使用人口普查数据集预测收入示例。
- 参加 Coursera 上的 ML 专业化课程,学习Google Cloud 上的 TensorFlow。
- 在ML 规则中了解有关 ML 工程最佳实践的信息。
- 有关更多参考架构、图表和最佳实践,请探索Cloud 架构中心。