
TensorFlow Extended 的关键组件示例
 在 GitHub 上查看源代码
在 GitHub 上查看源代码此示例 Colab 笔记本说明了如何使用 TensorFlow 数据验证 (TFDV) 来调查和可视化您的数据集。这包括查看描述性统计信息、推断模式、检查和修复异常以及检查数据集中的漂移和偏差。了解数据集的特征非常重要,包括它在生产管道中如何随时间变化。查看数据中的异常也很重要,并比较您的训练、评估和服务数据集以确保它们一致。
我们将使用来自芝加哥市发布的 出租车行程数据集 的数据。
阅读更多 关于 Google BigQuery 中的数据集信息。在 BigQuery UI 中探索完整的数据集。
数据集中的列为
| pickup_community_area | fare | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | payment_type | company |
| trip_seconds | dropoff_community_area | tips |
安装和导入包
安装 TensorFlow 数据验证的包。
升级 Pip
为了避免在本地运行时升级系统中的 Pip,请检查我们是否在 Colab 中运行。本地系统当然可以单独升级。
try:
import colab
!pip install --upgrade pip
except:
pass
安装数据验证包
安装 TensorFlow 数据验证包和依赖项,这需要几分钟。您可能会看到有关不兼容依赖项版本的警告和错误,您将在下一节中解决这些问题。
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
导入 TensorFlow 并重新加载更新的包
上一步更新了 Google Colab 环境中的默认包,因此您必须重新加载包资源以解决新的依赖项。
import pkg_resources
import importlib
importlib.reload(pkg_resources)
/tmpfs/tmp/ipykernel_183404/3239164719.py:1: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html import pkg_resources <module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pkg_resources/__init__.py'>
在继续之前,请检查 TensorFlow 和数据验证的版本。
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
2024-04-30 10:45:22.158704: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-04-30 10:45:22.158751: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-04-30 10:45:22.160265: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered TF version: 2.15.1 TFDV version: 1.15.1
加载数据集
我们将从 Google Cloud Storage 下载数据集。
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmpfs/tmp/tmp7em4lo4u/data: eval serving train /tmpfs/tmp/tmp7em4lo4u/data/eval: data.csv /tmpfs/tmp/tmp7em4lo4u/data/serving: data.csv /tmpfs/tmp/tmp7em4lo4u/data/train: data.csv
计算和可视化统计信息
首先,我们将使用 tfdv.generate_statistics_from_csv 来计算训练数据的统计信息。(忽略 snappy 警告)
TFDV 可以计算描述性的 统计信息,这些信息可以快速概述数据中存在的特征及其值分布的形状。
在内部,TFDV 使用 Apache Beam 的数据并行处理框架来扩展对大型数据集的统计计算。对于希望与 TFDV 深度集成的应用程序(例如,在数据生成管道末尾附加统计信息生成),该 API 还公开了一个用于统计信息生成的 Beam PTransform。
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_data_validation/utils/artifacts_io_impl.py:93: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_data_validation/utils/artifacts_io_impl.py:93: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
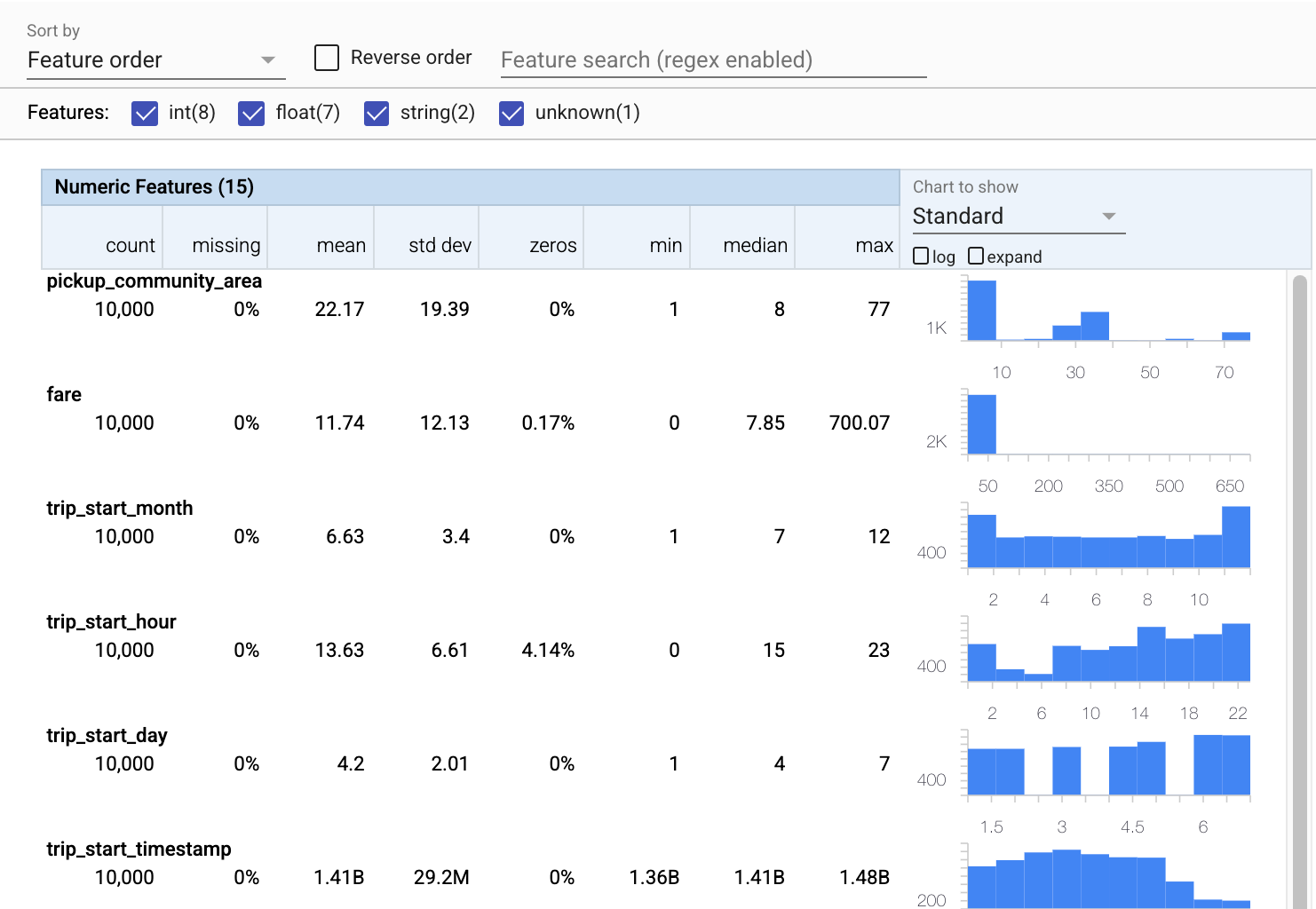
现在让我们使用 tfdv.visualize_statistics,它使用 Facets 来创建我们训练数据的简洁可视化。
- 请注意,数值特征和分类特征是分别可视化的,并且显示了图表,显示了每个特征的分布。
- 请注意,具有缺失值或零值的特征会以红色显示百分比,作为视觉指示,表明这些特征中的示例可能存在问题。百分比是具有该特征的缺失值或零值的示例的百分比。
- 请注意,没有示例具有
pickup_census_tract的值。这是一个降维的机会! - 尝试单击图表上方的“展开”以更改显示
- 尝试将鼠标悬停在图表中的条形上以显示桶范围和计数
- 尝试在对数和线性刻度之间切换,并注意对数刻度如何揭示有关
payment_type分类特征的更多细节 - 尝试从“要显示的图表”菜单中选择“分位数”,并将鼠标悬停在标记上以显示分位数百分比
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
推断模式
现在让我们使用 tfdv.infer_schema 为我们的数据创建模式。模式定义了与 ML 相关的约束。示例约束包括每个特征的数据类型,它是数值的还是分类的,或者它在数据中出现的频率。对于分类特征,模式还定义了域 - 可接受值的列表。由于编写模式可能是一项繁琐的任务,尤其是对于具有大量特征的数据集,因此 TFDV 提供了一种基于描述性统计信息生成模式初始版本的方法。
获得正确的模式很重要,因为我们生产管道的其余部分将依赖于 TFDV 生成的模式的正确性。模式还为数据提供文档,因此在不同的开发人员处理相同数据时很有用。让我们使用 tfdv.display_schema 来显示推断的模式,以便我们可以对其进行审查。
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
检查评估数据是否有错误
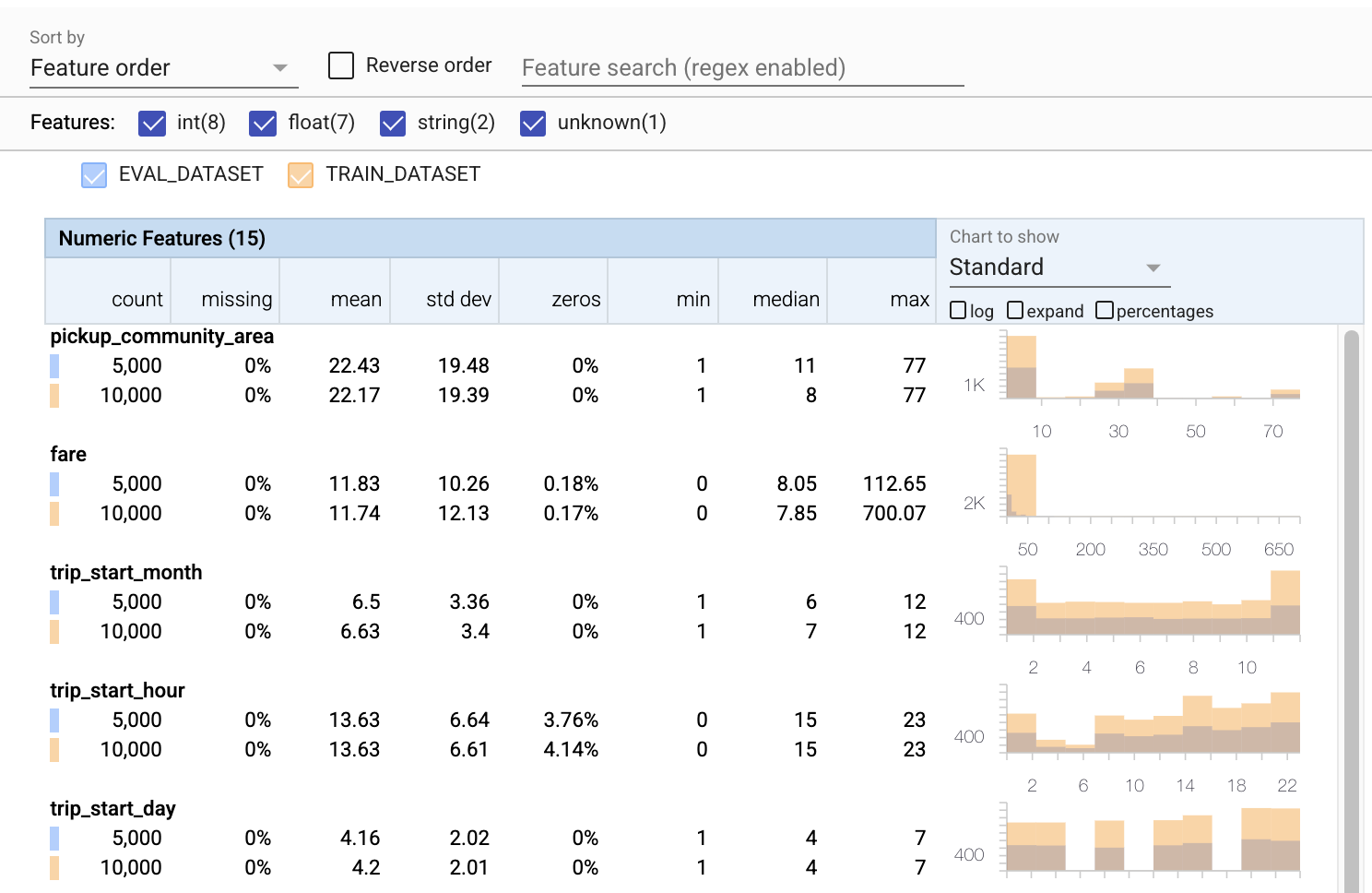
到目前为止,我们只查看了训练数据。重要的是,我们的评估数据与我们的训练数据一致,包括它使用相同的模式。同样重要的是,评估数据包含与我们的训练数据大致相同的数值特征值的范围的示例,以便我们在评估期间对损失面的覆盖范围与训练期间大致相同。对于分类特征也是如此。否则,我们可能会遇到在评估期间未识别的训练问题,因为我们没有评估损失面的部分。
- 请注意,每个特征现在都包含训练和评估数据集的统计信息。
- 请注意,图表现在同时覆盖了训练和评估数据集,这使得比较它们变得容易。
- 请注意,图表现在包含百分比视图,可以与对数或默认线性刻度结合使用。
- 请注意,
trip_miles的平均值和中位数在训练和评估数据集之间有所不同。这会导致问题吗? - 哇,训练和评估数据集的
tips最大值差异很大。这会导致问题吗? - 单击“数值特征”图表上的展开,然后选择对数刻度。查看
trip_seconds特征,并注意最大值的差异。评估会错过损失面的部分吗?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
检查评估异常
我们的评估数据集是否与训练数据集的模式匹配?这对于分类特征尤其重要,因为我们希望识别可接受值的范围。
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
修复模式中的评估异常
糟糕!看起来我们的评估数据中有一些新的 company 值,这些值不在我们的训练数据中。我们还有一个新的 payment_type 值。这些应该被视为异常,但我们决定如何处理它们取决于我们对数据的领域知识。如果异常确实表明数据错误,那么应该修复基础数据。否则,我们可以简单地更新模式以包含评估数据集中的值。
除非我们更改评估数据集,否则我们无法修复所有问题,但我们可以修复我们愿意接受的模式中的问题。这包括放宽我们对特定特征的异常是什么和不是什么的看法,以及更新我们的模式以包含分类特征的缺失值。TFDV 使我们能够发现我们需要修复的内容。
现在让我们进行这些修复,然后再次审查。
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
嘿,看看!我们验证了训练和评估数据现在一致!感谢 TFDV ;)
模式环境
我们还为本示例分离了一个“服务”数据集,因此我们也应该检查它。默认情况下,管道中的所有数据集都应该使用相同的模式,但通常会有例外。例如,在监督学习中,我们需要在我们的数据集中包含标签,但是当我们为推理提供模型时,标签将不会包含在内。在某些情况下,引入轻微的模式变化是必要的。
环境可用于表达此类要求。特别是,模式中的特征可以使用 default_environment、in_environment 和 not_in_environment 与一组环境相关联。
例如,在这个数据集中,tips 特征作为训练的标签包含在内,但在服务数据中缺失。如果没有指定环境,它将显示为异常。
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
我们将在下面处理 tips 特征。我们的行程秒数中还有一个 INT 值,而我们的模式期望一个 FLOAT。通过让我们意识到这种差异,TFDV 有助于发现为训练和服务生成数据的过程中存在的不一致。在模型性能下降之前,甚至灾难性下降之前,很容易不知道这样的问题。它可能是也可能不是一个重大问题,但无论如何,这都应该引起进一步调查。
在这种情况下,我们可以安全地将 INT 值转换为 FLOAT,因此我们希望告诉 TFDV 使用我们的模式来推断类型。现在就让我们这样做吧。
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
现在我们只有 tips 特征(它是我们的标签)显示为异常(“列已删除”)。当然,我们不希望在服务数据中包含标签,因此让我们告诉 TFDV 忽略它。
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
检查漂移和偏差
除了检查数据集是否符合模式中设置的期望之外,TFDV 还提供检测漂移和偏差的功能。TFDV 通过根据模式中指定的漂移/偏差比较器比较不同数据集的统计信息来执行此检查。
漂移
漂移检测支持分类特征和连续数据跨度(即跨度 N 和跨度 N+1 之间),例如训练数据的不同日期之间。我们将漂移表示为 L-无穷大距离,您可以设置阈值距离,以便在漂移高于可接受范围时收到警告。设置正确的距离通常是一个需要领域知识和实验的迭代过程。
偏差
TFDV 可以检测数据中的三种不同类型的偏差 - 模式偏差、特征偏差和分布偏差。
模式偏差
模式偏差发生在训练和服务数据不符合相同模式时。训练和服务数据都应符合相同的模式。两者之间任何预期的偏差(例如,标签特征仅存在于训练数据中,而不在服务数据中)都应通过模式中的环境字段指定。
特征偏差
特征偏差发生在模型训练的特征值与它在服务时看到的特征值不同时。例如,这可能发生在
- 提供一些特征值的資料來源在训练和服务时间之间被修改
- 训练和服务之间生成特征的逻辑不同。例如,如果您只在两个代码路径之一中应用了一些转换。
分布偏差
分布偏差发生在训练数据集的分布与服务数据集的分布显着不同时。分布偏差的主要原因之一是使用不同的代码或不同的数据源来生成训练数据集。另一个原因是错误的采样机制,该机制选择服务数据的非代表性子样本进行训练。
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
在本例中,我们确实看到了一些漂移,但它远低于我们设置的阈值。
冻结模式
现在模式已经过审查和整理,我们将将其存储在一个文件中以反映其“冻结”状态。
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
何时使用 TFDV
很容易将 TFDV 视为仅应用于训练管道的开头,就像我们在这里所做的那样,但实际上它有很多用途。这里还有一些
- 验证用于推理的新数据,以确保我们没有突然开始接收错误的特征
- 验证用于推理的新数据,以确保我们的模型已在决策面的该部分上进行过训练。
- 在对数据进行转换和特征工程(可能使用 TensorFlow Transform)后验证我们的数据,以确保我们没有做错任何事情。