
简介
本教程旨在介绍 TensorFlow Extended (TFX) 和 AIPlatform Pipelines,并帮助您学习在 Google Cloud 上创建自己的机器学习管道。它展示了与 TFX、AI Platform Pipelines 和 Kubeflow 的集成,以及在 Jupyter 笔记本中与 TFX 的交互。
在本教程结束时,您将已创建并运行了一个机器学习管道,并将其托管在 Google Cloud 上。您将能够可视化每次运行的结果,并查看已创建工件的谱系。
您将遵循典型的机器学习开发流程,从检查数据集开始,最终得到一个完整的可运行管道。在此过程中,您将探索调试和更新管道的方法,以及衡量性能。
芝加哥出租车数据集


您将使用芝加哥市发布的 出租车行程数据集。
您可以在 此处 了解有关 Google BigQuery 中的数据集的更多信息。在 BigQuery UI 中探索完整的数据集。
模型目标 - 二元分类
客户的小费会超过 20% 吗?
1. 设置 Google Cloud 项目
1.a 在 Google Cloud 上设置您的环境
要开始使用,您需要一个 Google Cloud 帐户。如果您已经拥有帐户,请跳过此步骤,直接进入 创建新项目。
同意 Google Cloud 的条款和条件
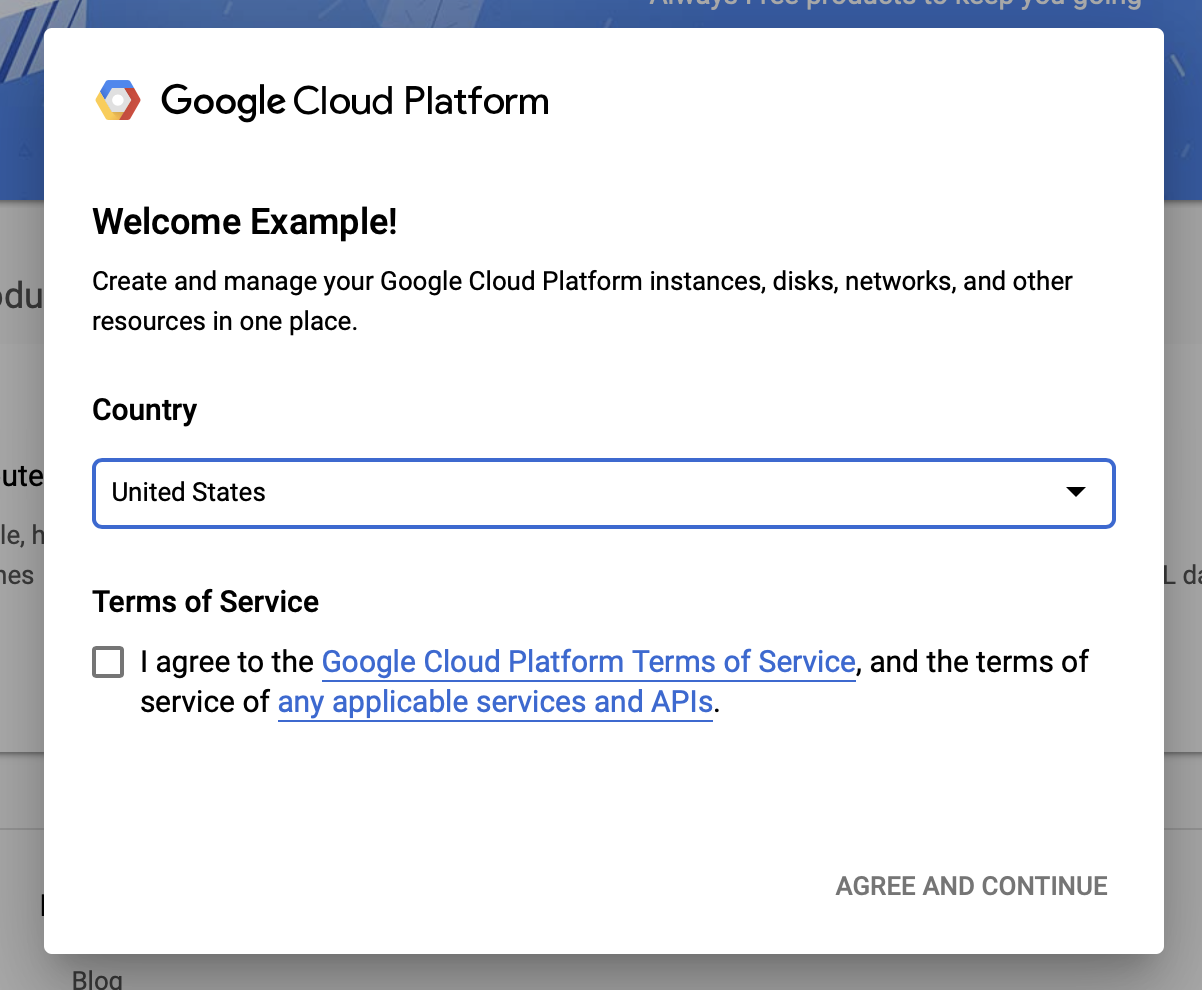
如果您想从免费试用帐户开始,请点击 免费试用(或 免费开始)。
选择您的国家/地区。
同意服务条款。
输入账单信息。
您目前不会被收费。如果您没有其他 Google Cloud 项目,您可以完成本教程,而不会超过 Google Cloud 免费套餐 的限制,其中包括同时运行的最大 8 个核心。
1.b 创建一个新项目。
- 从 Google Cloud 主仪表板 中,点击Google Cloud Platform 标题旁边的项目下拉菜单,然后选择新建项目。
- 为您的项目命名并输入其他项目详细信息
- 创建项目后,请确保从项目下拉菜单中选择该项目。
2. 在新的 Kubernetes 集群上设置和部署 AI Platform Pipeline
转到 AI Platform Pipelines 集群 页面。
在主导航菜单下:≡ > AI Platform > Pipelines
点击+ 新实例以创建新的集群。
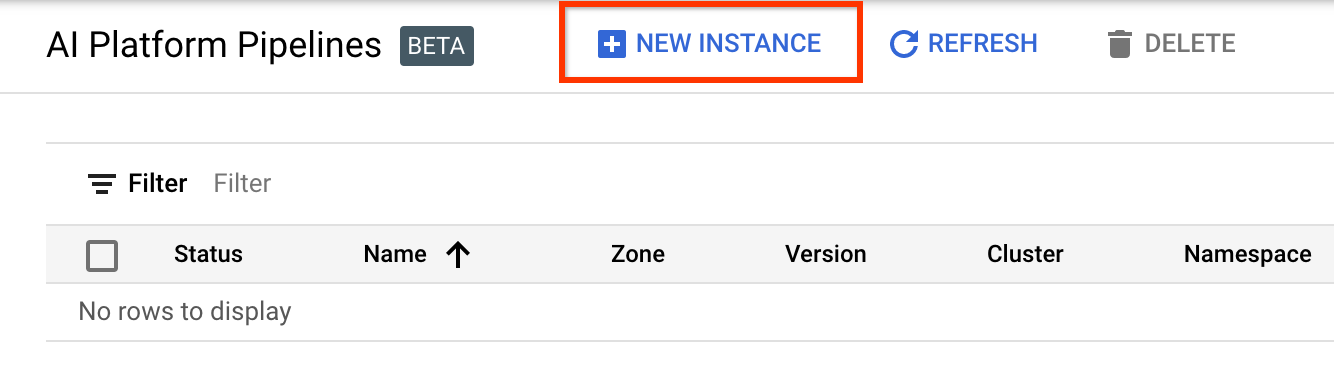
在Kubeflow Pipelines 概述页面上,点击配置。

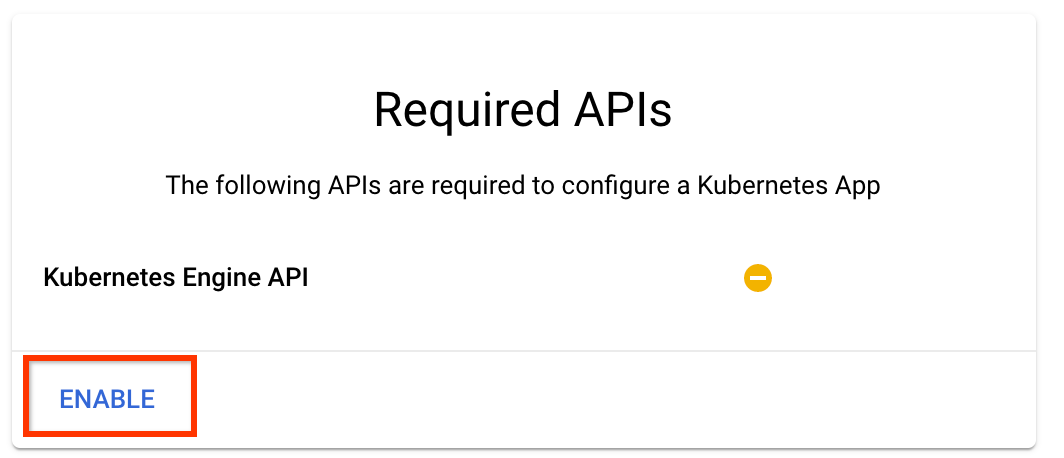
点击“启用”以启用 Kubernetes Engine API
在部署 Kubeflow Pipelines 页面上
选择集群的 区域(或“区域”)。可以设置网络和子网,但为了本教程的目的,我们将保留默认设置。
重要 选中标记为允许访问以下云 API 的框。(这是此集群访问项目其他部分所必需的。如果您错过了此步骤,稍后修复起来会有点棘手。)
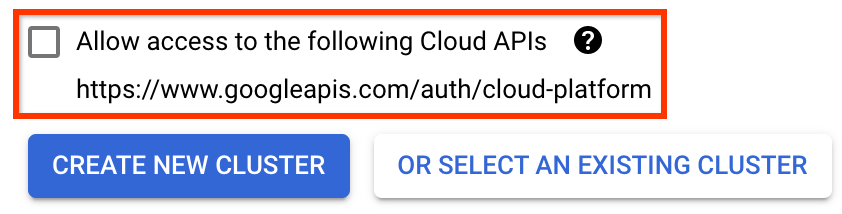
点击创建新集群,并等待几分钟,直到集群创建完成。这将需要几分钟。完成后,您将看到类似以下的消息
集群“cluster-1”已在区域“us-central1-a”中成功创建。
选择命名空间和实例名称(使用默认值即可)。为了本教程的目的,不要选中executor.emissary 或managedstorage.enabled。
点击部署,并等待几分钟,直到管道部署完成。通过部署 Kubeflow Pipelines,您即表示接受服务条款。
3. 设置 Cloud AI Platform Notebook 实例。
转到 Vertex AI Workbench 页面。首次运行 Workbench 时,您需要启用 Notebooks API。
在主导航菜单下:≡ -> Vertex AI -> Workbench
如果出现提示,请启用 Compute Engine API。
创建一个安装了 TensorFlow Enterprise 2.7(或更高版本)的新笔记本。
新笔记本 -> TensorFlow Enterprise 2.7 -> 无 GPU
选择区域和区域,并为笔记本实例命名。
为了保持在免费套餐限制内,您可能需要在此处更改默认设置,将此实例可用的 vCPU 数量从 4 减少到 2
- 在新笔记本表单的底部选择高级选项。
在机器配置下,如果您需要保持在免费套餐内,您可能需要选择一个配置,其中包含 1 或 2 个 vCPU。
等待新笔记本创建完成,然后点击启用 Notebooks API
4. 启动入门笔记本
转到 AI Platform Pipelines 集群 页面。
在主导航菜单下:≡ -> AI Platform -> Pipelines
在您在本教程中使用的集群的行上,点击打开 Pipelines 仪表板。

在入门页面上,点击在 Google Cloud 上打开 Cloud AI Platform 笔记本。

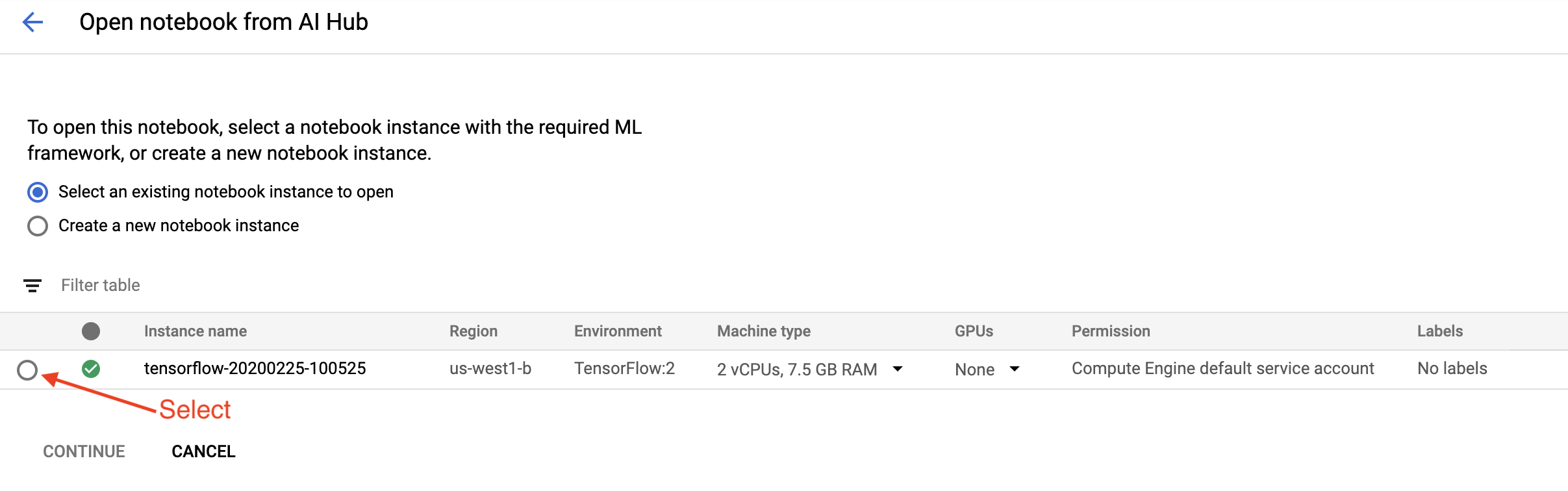
选择您在本教程中使用的笔记本实例,然后点击继续,然后点击确认。
5. 继续在笔记本中工作
安装
入门笔记本首先将 TFX 和 Kubeflow Pipelines (KFP) 安装到 Jupyter Lab 运行所在的虚拟机中。
然后它检查安装的 TFX 版本,进行导入,并设置和打印项目 ID

连接到您的 Google Cloud 服务
管道配置需要您的项目 ID,您可以通过笔记本获取并将其设置为环境变量。
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
现在设置您的 KFP 集群端点。
这可以从 Pipelines 仪表板的 URL 中找到。转到 Kubeflow Pipeline 仪表板并查看 URL。端点是 URL 中从https://开始,到googleusercontent.com(包括)为止的所有内容。
ENDPOINT='' # Enter YOUR ENDPOINT here.
然后笔记本为自定义 Docker 镜像设置一个唯一的名称
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. 将模板复制到您的项目目录
编辑下一个笔记本单元格以设置管道的名称。在本教程中,我们将使用my_pipeline。
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
然后笔记本使用tfx CLI 复制管道模板。本教程使用芝加哥出租车数据集执行二元分类,因此模板将模型设置为taxi
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
然后笔记本将它的 CWD 上下文更改为项目目录
%cd {PROJECT_DIR}
浏览管道文件
在 Cloud AI Platform 笔记本的左侧,您应该看到一个文件浏览器。应该有一个包含您的管道名称(my_pipeline)的目录。打开它并查看文件。(您也可以从笔记本环境中打开和编辑它们。)
# You can also list the files from the shellls
上面的tfx template copy 命令创建了一个构建管道的基本文件脚手架。这些包括 Python 源代码、示例数据和 Jupyter 笔记本。这些是针对此特定示例的。对于您自己的管道,这些将是您的管道所需的辅助文件。
以下是 Python 文件的简要说明。
pipeline- 此目录包含管道的定义configs.py— 为管道运行器定义通用常量pipeline.py— 定义 TFX 组件和管道
models- 此目录包含 ML 模型定义。features.pyfeatures_test.py— 为模型定义特征preprocessing.py/preprocessing_test.py— 使用tf::Transform定义预处理作业estimator- 此目录包含一个基于 Estimator 的模型。constants.py— 定义模型的常量model.py/model_test.py— 使用 TF estimator 定义 DNN 模型
keras- 此目录包含一个基于 Keras 的模型。constants.py— 定义模型的常量model.py/model_test.py— 使用 Keras 定义 DNN 模型
beam_runner.py/kubeflow_runner.py— 为每个编排引擎定义运行器
7. 在 Kubeflow 上运行您的第一个 TFX 管道
笔记本将使用tfx run CLI 命令运行管道。
连接到存储
运行管道会创建必须存储在 ML-Metadata 中的工件。工件指的是有效负载,有效负载是必须存储在文件系统或块存储中的文件。在本教程中,我们将使用 GCS 来存储我们的元数据有效负载,使用在设置过程中自动创建的存储桶。它的名称将是<your-project-id>-kubeflowpipelines-default。
创建管道
笔记本将把我们的示例数据上传到 GCS 存储桶,以便我们稍后可以在管道中使用它。
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv
然后笔记本使用tfx pipeline create 命令创建管道。
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
在创建管道时,将生成Dockerfile 来构建 Docker 镜像。不要忘记将这些文件与其他源文件一起添加到您的源代码控制系统(例如,git)中。
运行管道
然后笔记本使用tfx run create 命令启动管道执行运行。您还将在 Kubeflow Pipelines 仪表板的实验中看到此运行。
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}
您可以从 Kubeflow Pipelines 仪表板查看您的管道。
8. 验证您的数据
任何数据科学或 ML 项目中的第一个任务是了解和清理数据。
- 了解每个特征的数据类型
- 查找异常和缺失值
- 了解每个特征的分布
组件


- ExampleGen 会摄取和拆分输入数据集。
- StatisticsGen 会计算数据集的统计信息。
- SchemaGen SchemaGen 会检查统计信息并创建数据架构。
- ExampleValidator 会查找数据集中的异常和缺失值。
在 Jupyter lab 文件编辑器中
在pipeline/pipeline.py 中,取消注释将这些组件追加到您的管道的行
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
(ExampleGen 在复制模板文件时已启用。)
更新管道并重新运行它
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
检查管道
要查看 Kubeflow Orchestrator,请访问 KFP 仪表板并在您的管道运行页面中查找管道输出。单击左侧的“实验”选项卡,然后在“实验”页面中单击“所有运行”。您应该能够找到与您的管道名称相同的运行。
更高级的示例
此处提供的示例仅用于入门。有关更高级的示例,请参阅 TensorFlow 数据验证 Colab。
有关使用 TFDV 探索和验证数据集的更多信息,请 参阅 tensorflow.org 上的示例。
9. 特征工程
您可以通过特征工程来提高数据的预测质量和/或降低维度。
- 特征交叉
- 词汇表
- 嵌入
- PCA
- 类别编码
使用 TFX 的好处之一是,您只需编写一次转换代码,生成的转换在训练和服务之间将保持一致。
组件

- Transform 对数据集执行特征工程。
在 Jupyter lab 文件编辑器中
在 pipeline/pipeline.py 中,找到并取消注释将 Transform 附加到管道的行。
# components.append(transform)
更新管道并重新运行它
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
检查管道输出
要查看 Kubeflow Orchestrator,请访问 KFP 仪表板并在您的管道运行页面中查找管道输出。单击左侧的“实验”选项卡,然后在“实验”页面中单击“所有运行”。您应该能够找到与您的管道名称相同的运行。
更高级的示例
此处提供的示例仅用于入门。有关更高级的示例,请参阅 TensorFlow Transform Colab。
10. 训练
使用您干净、经过转换的数据训练 TensorFlow 模型。
- 包含来自上一步的转换,以便它们始终如一地应用
- 将结果保存为用于生产的 SavedModel
- 使用 TensorBoard 可视化和探索训练过程
- 还保存 EvalSavedModel 以分析模型性能
组件
- Trainer 训练 TensorFlow 模型。
在 Jupyter lab 文件编辑器中
在 pipeline/pipeline.py 中,找到并取消注释将 Trainer 附加到管道的行
# components.append(trainer)
更新管道并重新运行它
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
检查管道输出
要查看 Kubeflow Orchestrator,请访问 KFP 仪表板并在您的管道运行页面中查找管道输出。单击左侧的“实验”选项卡,然后在“实验”页面中单击“所有运行”。您应该能够找到与您的管道名称相同的运行。
更高级的示例
此处提供的示例仅用于入门。有关更高级的示例,请参阅 TensorBoard 教程。
11. 分析模型性能
了解不仅仅是顶级指标。
- 用户仅体验其查询的模型性能
- 数据切片的性能不佳可能会被顶级指标隐藏
- 模型公平性很重要
- 通常,用户或数据的关键子集非常重要,并且可能很小
- 关键但异常情况下的性能
- 关键受众(如影响者)的性能
- 如果您要替换当前正在生产的模型,请首先确保新模型更好
组件
- Evaluator 对训练结果进行深入分析。
在 Jupyter lab 文件编辑器中
在 pipeline/pipeline.py 中,找到并取消注释将 Evaluator 附加到管道的行
components.append(evaluator)
更新管道并重新运行它
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
检查管道输出
要查看 Kubeflow Orchestrator,请访问 KFP 仪表板并在您的管道运行页面中查找管道输出。单击左侧的“实验”选项卡,然后在“实验”页面中单击“所有运行”。您应该能够找到与您的管道名称相同的运行。
12. 提供模型
如果新模型已准备就绪,请将其设置为已准备就绪。
- Pusher 将 SavedModel 部署到众所周知的 location
部署目标从众所周知的 location 接收新模型
- TensorFlow Serving
- TensorFlow Lite
- TensorFlow JS
- TensorFlow Hub
组件
- Pusher 将模型部署到服务基础设施。
在 Jupyter lab 文件编辑器中
在 pipeline/pipeline.py 中,找到并取消注释将 Pusher 附加到管道的行
# components.append(pusher)
检查管道输出
要查看 Kubeflow Orchestrator,请访问 KFP 仪表板并在您的管道运行页面中查找管道输出。单击左侧的“实验”选项卡,然后在“实验”页面中单击“所有运行”。您应该能够找到与您的管道名称相同的运行。
可用的部署目标
您现在已训练和验证了模型,并且模型现在已准备好投入生产。您现在可以将模型部署到任何 TensorFlow 部署目标,包括
- TensorFlow Serving,用于在服务器或服务器场群上提供模型,并处理 REST 和/或 gRPC 推理请求。
- TensorFlow Lite,用于将模型包含在 Android 或 iOS 本机移动应用程序中,或包含在 Raspberry Pi、IoT 或微控制器应用程序中。
- TensorFlow.js,用于在 Web 浏览器或 Node.JS 应用程序中运行模型。
更高级的示例
上面提供的示例仅用于入门。以下是一些与其他云服务的集成示例。
Kubeflow Pipelines 资源注意事项
根据工作负载的要求,Kubeflow Pipelines 部署的默认配置可能满足您的需求,也可能不满足您的需求。您可以使用 pipeline_operator_funcs 在调用 KubeflowDagRunnerConfig 时自定义资源配置。
pipeline_operator_funcs 是 OpFunc 项的列表,它将从 KubeflowDagRunner 编译的 KFP 管道规范中的所有生成的 ContainerOp 实例进行转换。
例如,要配置内存,我们可以使用 set_memory_request 来声明所需的内存量。一种典型的做法是为 set_memory_request 创建一个包装器,并使用它将其添加到管道 OpFunc 列表中
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
类似的资源配置函数包括
set_memory_limitset_cpu_requestset_cpu_limitset_gpu_limit
尝试 BigQueryExampleGen
BigQuery 是一种无服务器、高度可扩展且经济高效的云数据仓库。BigQuery 可用作 TFX 中训练示例的来源。在此步骤中,我们将 BigQueryExampleGen 添加到管道。
在 Jupyter lab 文件编辑器中
双击打开 pipeline.py。注释掉 CsvExampleGen,并取消注释创建 BigQueryExampleGen 实例的行。您还需要取消注释 create_pipeline 函数的 query 参数。
我们需要指定要用于 BigQuery 的 GCP 项目,这可以通过在创建管道时在 beam_pipeline_args 中设置 --project 来完成。
双击打开 configs.py。取消注释 BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS 和 BIG_QUERY_QUERY 的定义。您应该将此文件中的项目 ID 和区域值替换为 GCP 项目的正确值。
将目录更改到上一级。单击文件列表上方目录的名称。目录的名称是管道的名称,如果您没有更改管道名称,则为 my_pipeline。
双击打开 kubeflow_runner.py。取消注释 create_pipeline 函数的两个参数 query 和 beam_pipeline_args。
现在,管道已准备好使用 BigQuery 作为示例来源。与之前一样更新管道,并像我们在步骤 5 和 6 中所做的那样创建新的执行运行。
更新管道并重新运行它
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
尝试 Dataflow
几个 TFX 组件使用 Apache Beam 来实现数据并行管道,这意味着您可以使用 Google Cloud Dataflow 分发数据处理工作负载。在此步骤中,我们将设置 Kubeflow 编排器以使用 Dataflow 作为 Apache Beam 的数据处理后端。
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
双击 pipeline 更改目录,然后双击打开 configs.py。取消注释 GOOGLE_CLOUD_REGION 和 DATAFLOW_BEAM_PIPELINE_ARGS 的定义。
将目录更改到上一级。单击文件列表上方目录的名称。目录的名称是管道的名称,如果您没有更改,则为 my_pipeline。
双击打开 kubeflow_runner.py。取消注释 beam_pipeline_args。(还要确保注释掉您在步骤 7 中添加的当前 beam_pipeline_args。)
更新管道并重新运行它
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
您可以在 Cloud Console 中的 Dataflow 中找到您的 Dataflow 作业。
尝试使用 KFP 进行 Cloud AI Platform 训练和预测
TFX 与几个托管的 GCP 服务互操作,例如 用于训练和预测的 Cloud AI Platform。您可以将 Trainer 组件设置为使用 Cloud AI Platform 训练,这是一种用于训练 ML 模型的托管服务。此外,当您的模型构建并准备好提供服务时,您可以将模型推送到 Cloud AI Platform 预测以提供服务。在此步骤中,我们将设置 Trainer 和 Pusher 组件以使用 Cloud AI Platform 服务。
在编辑文件之前,您可能首先需要启用AI Platform 训练和预测 API。
双击 pipeline 更改目录,然后双击打开 configs.py。取消注释 GOOGLE_CLOUD_REGION、GCP_AI_PLATFORM_TRAINING_ARGS 和 GCP_AI_PLATFORM_SERVING_ARGS 的定义。我们将使用我们自定义构建的容器映像在 Cloud AI Platform 训练中训练模型,因此我们应该将 GCP_AI_PLATFORM_TRAINING_ARGS 中的 masterConfig.imageUri 设置为与上面的 CUSTOM_TFX_IMAGE 相同的值。
将目录更改到上一级,然后双击打开 kubeflow_runner.py。取消注释 ai_platform_training_args 和 ai_platform_serving_args。
更新管道并重新运行它
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
您可以在 Cloud AI Platform 作业 中找到您的训练作业。如果您的管道成功完成,您可以在 Cloud AI Platform 模型 中找到您的模型。
14. 使用您自己的数据
在本教程中,您使用芝加哥出租车数据集创建了一个模型管道。现在尝试将您自己的数据放入管道中。您的数据可以存储在管道可以访问的任何地方,包括 Google Cloud Storage、BigQuery 或 CSV 文件。
您需要修改管道定义以适应您的数据。
如果您的数据存储在文件中
- 修改
kubeflow_runner.py中的DATA_PATH,指示位置。
如果您的数据存储在 BigQuery 中
- 修改 configs.py 中的
BIG_QUERY_QUERY为您的查询语句。 - 在
models/features.py中添加特征。 - 修改
models/preprocessing.py以 转换用于训练的输入数据。 - 修改
models/keras/model.py和models/keras/constants.py以 描述您的 ML 模型。
了解有关 Trainer 的更多信息
有关训练管道的更多详细信息,请参阅 Trainer 组件指南。
清理
要清理本项目中使用的所有 Google Cloud 资源,您可以 删除您用于本教程的 Google Cloud 项目。
或者,您可以通过访问每个控制台来清理单个资源:- Google Cloud Storage - Google Container Registry - Google Kubernetes Engine