
版权所有 2023 TF-Agents 作者。
入门
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
本教程是有关如何使用 TF-Agents 库解决上下文老虎机问题的分步指南,其中动作(臂)具有自己的特征,例如由特征(类型、发行年份、...)表示的电影列表。
先决条件
假设读者对 TF-Agents 的 Bandit 库有所了解,特别是已经完成了 TF-Agents 中老虎机的教程,然后再阅读本教程。
带臂特征的多臂老虎机
在“经典”上下文多臂老虎机设置中,代理在每个时间步接收一个上下文向量(也称为观察结果),并且必须从一组有限的编号动作(臂)中进行选择,以最大限度地提高其累积奖励。
现在考虑代理向用户推荐下一部要观看的电影的情况。每次需要做出决定时,代理都会接收有关用户的一些信息(观看历史记录、类型偏好等)以及要从中选择的电影列表。
我们可以尝试通过将用户信息作为上下文,并将臂设置为 movie_1, movie_2, ..., movie_K 来制定这个问题,但这种方法有几个缺点
- 动作的数量必须是系统中的所有电影,并且添加新电影很麻烦。
- 代理必须为每部电影学习一个模型。
- 没有考虑电影之间的相似性。
与其对电影进行编号,我们可以做一些更直观的事情:我们可以使用一组特征来表示电影,包括类型、长度、演员阵容、评分、年份等。这种方法的优点很多
- 跨电影泛化。
- 代理只学习一个奖励函数,该函数使用用户和电影特征来模拟奖励。
- 易于从系统中删除或引入新电影。
在这种新设置中,动作的数量甚至不必在每个时间步都相同。
TF-Agents 中的每臂老虎机
TF-Agents Bandit 套件的开发是为了让人们能够将其用于每臂情况。存在每臂环境,并且大多数策略和代理也可以在每臂模式下运行。
在我们深入研究编码示例之前,我们需要必要的导入。
安装
pip install tf-agentspip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
导入
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
参数 - 随意尝试
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
一个简单的每臂环境
在其他 教程 中解释的固定随机环境有一个每臂对应物。
要初始化每臂环境,必须定义以下函数:
- 全局和每臂特征:这些函数没有输入参数,并在调用时生成单个(全局或每臂)特征向量。
- 奖励:此函数将全局和每臂特征向量的串联作为参数,并生成一个奖励。基本上,这是代理必须“猜测”的函数。值得注意的是,在每臂情况下,每个臂的奖励函数都是相同的。这是与经典老虎机情况的根本区别,在经典老虎机情况下,代理必须独立地估计每个臂的奖励函数。
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
现在我们已经准备好初始化我们的环境了。
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
下面我们可以检查此环境的输出。
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -4., 8., -5., 7., -3., -7., -1., 8., 4., 2., -8.,
5., 9., 7., 4., -6., -1., 1., -10., 1., 3., 1.,
3., 8., -4., 1., 5., -8., 1., -10., 7., 7., -5.,
8., -4., 7., 4., -3., -5., 9.],
[ 9., 2., 3., 1., -2., 7., 6., 2., -9., -3., -2.,
8., 5., -1., 6., -4., 2., -2., -5., 6., -2., -10.,
-3., 3., -7., 5., -3., 4., -2., 0., 2., -4., -6.,
2., 1., -4., 9., -1., 8., -3.],
[ 3., 9., -3., 8., -1., 0., 9., 9., 6., 8., 2.,
1., -5., -3., -4., 7., -7., -4., 2., 3., 4., -4.,
6., -3., -3., 7., 2., 1., -3., -8., 7., -2., 2.,
5., -5., 4., 6., 7., 9., 2.],
[ -2., 7., 8., -3., 8., -10., -9., -5., 7., 9., 0.,
-3., -1., -10., 2., 8., -8., 4., -2., 6., 3., -4.,
-8., -10., 9., -2., -8., -7., -4., 0., 6., -3., 9.,
-4., 1., -5., 4., 2., -2., 0.],
[ -6., 5., -8., 3., 2., 2., -8., 4., -6., 6., 0.,
3., 4., -4., 2., -10., -7., 3., 6., 9., -9., -2.,
6., 0., -4., 8., 0., -4., 0., 3., -3., 9., 0.,
-5., 0., 5., -7., -2., 0., 3.],
[ 4., 9., -2., -6., -3., -10., -2., 8., 8., 3., 0.,
3., -1., -9., 1., -6., 8., -5., 1., 2., 3., -3.,
4., 7., 8., -8., 0., -3., 1., 0., -4., -7., -2.,
-5., -6., 4., -2., 3., 1., -4.],
[ -3., -2., 7., -5., -7., -3., 0., -1., 8., -6., 1.,
9., -9., -6., 3., 2., -6., 6., -10., 6., -6., 6.,
-5., 3., -7., -4., 6., 4., -7., -4., -5., 1., -10.,
5., -6., -9., -3., -2., -10., -4.],
[ 7., 9., 2., 4., -4., -7., 4., -6., 2., 9., 7.,
8., -10., 7., 6., 7., -4., -1., -4., 8., -4., -9.,
-6., -1., 7., -8., -5., -6., -3., 2., -5., 9., -6.,
-6., 8., -2., -1., -2., -5., -6.],
[ 5., 7., 7., -8., -3., 9., 6., 7., 1., -3., -2.,
7., -5., 5., 0., -7., 2., -1., -1., 6., -8., -2.,
-10., 6., 2., 8., 0., 3., 1., -7., 5., 3., 4.,
8., -2., -2., -8., 8., 5., 0.],
[ 1., 0., -2., -6., 7., 8., -5., -8., -7., -8., -4.,
-9., 3., -9., 8., -4., -1., -10., 2., -1., 1., -4.,
6., -1., 4., 1., -7., -4., -8., -6., 7., 4., -8.,
-3., -7., 5., -1., -4., -10., -4.],
[ -7., 4., 0., -9., -8., -6., -7., 8., 3., 7., -7.,
-1., 7., -3., 5., 6., 1., -5., 3., -10., -7., 0.,
-4., -4., -7., 2., -5., 3., 2., -3., 3., -7., -1.,
-10., 9., 1., -2., 3., 4., -8.],
[ 8., -5., -10., 7., 7., -7., 2., 7., -1., -10., 6.,
-4., -5., -3., -8., -2., -2., 3., 1., 2., 1., -6.,
8., -7., 7., 8., -8., -10., 2., -7., 1., -2., -3.,
-6., 9., 4., 2., -1., -7., -1.],
[ 2., 5., -2., -10., -2., 2., 2., -9., -9., -8., -1.,
-7., -9., -4., -2., -3., -9., -3., 5., 5., -1., 0.,
8., -8., 9., -3., 8., 9., 7., -8., 4., -7., 0.,
1., -1., 1., 0., 8., -1., -10.],
[ -6., -1., 9., 4., -8., -5., 8., 0., -10., -10., -10.,
-3., 8., -7., -2., -2., -10., 2., -3., -9., 0., 7.,
0., 2., -7., -6., -6., 3., 2., 6., 8., 9., -10.,
7., -4., -9., 7., -9., 3., -5.],
[ -2., 4., 1., 7., -5., -7., -1., -8., -9., -1., -7.,
4., -7., -7., 7., -2., -5., 3., -10., 9., 9., -5.,
1., 4., 5., 0., -1., 5., 9., 1., 8., -9., -9.,
6., -6., -9., 6., 7., 5., 9.],
[-10., -3., -5., 7., -9., -4., 7., -9., -2., 3., -1.,
-5., -9., -7., -6., 6., -4., -7., 2., 0., 1., -10.,
-3., -10., -7., -4., -9., 0., 3., -8., -7., 7., -2.,
3., 1., 3., -9., -2., -9., -3.],
[ 8., 3., -4., -2., -7., -9., -10., -1., 1., -5., 0.,
6., 0., 5., 9., -3., -10., 5., 9., 0., -8., -2.,
4., 8., 3., 5., 0., -6., -5., -2., -1., 3., -2.,
-3., -1., 8., -1., 1., -1., 5.],
[ -8., 3., -6., 4., -8., 8., -8., 4., 2., 1., 4.,
-8., -9., 8., -8., 3., 2., 0., -10., -5., 5., -3.,
-7., -3., 1., 1., -7., 9., 1., -3., 8., 8., 1.,
7., -2., -9., -3., -6., -1., -10.],
[-10., -5., 4., 4., -9., -5., -8., 6., 5., -9., -8.,
4., -7., 2., 7., 2., 6., -1., 0., 8., -6., 3.,
2., 7., -2., -7., -7., -3., 5., 1., 9., 8., 2.,
-1., 3., -5., 6., -1., -9., -8.],
[ -6., -8., -7., -2., -10., 7., 3., -2., -8., 7., -8.,
-10., 7., 8., -2., 6., 3., 6., -1., 0., -6., -7.,
7., 2., -4., 7., -9., -5., 2., 1., -1., -9., 7.,
9., -5., -10., 6., 9., 6., -2.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 0., 5., 3., ..., -2., 0., -4.],
[-5., 5., -5., ..., 3., 3., 4.],
[ 1., -6., 2., ..., 0., -4., -1.],
...,
[ 1., -3., -5., ..., -5., 4., 3.],
[ 3., -4., 0., ..., -5., -4., 2.],
[-3., -4., -6., ..., -1., -5., -2.]],
[[ 3., -3., -6., ..., -2., -4., -1.],
[-5., 5., -4., ..., -1., 3., -1.],
[-4., 4., 5., ..., 3., -3., -3.],
...,
[-4., -4., 5., ..., -2., 0., -4.],
[ 5., -6., 1., ..., -1., -5., -5.],
[ 5., -4., 5., ..., 4., -4., -4.]],
[[-3., 4., 0., ..., 1., 0., 0.],
[ 1., -1., -5., ..., -4., 5., -4.],
[ 2., 4., 1., ..., -6., -4., -4.],
...,
[ 0., 3., 4., ..., -6., -4., 1.],
[ 3., 5., -5., ..., 5., -2., 4.],
[ 3., -5., 4., ..., 2., -3., -5.]],
...,
[[ 1., -5., -3., ..., -1., -1., 1.],
[-5., 2., -4., ..., -3., 4., -6.],
[-3., -3., 1., ..., 0., -3., -1.],
...,
[-1., 2., -2., ..., -4., 3., 1.],
[-4., 1., -3., ..., 2., -5., -5.],
[-4., -4., -2., ..., 4., -6., -4.]],
[[ 3., 4., 5., ..., -5., -2., -1.],
[-6., 4., -4., ..., 3., -5., -3.],
[ 2., -3., 5., ..., -2., 2., 1.],
...,
[ 4., 2., -1., ..., -5., 5., 1.],
[ 1., -6., 2., ..., 3., 3., 0.],
[ 0., 4., -6., ..., 4., 4., -6.]],
[[ 0., 5., -4., ..., 4., 1., -6.],
[ 3., -1., 4., ..., 1., -1., -2.],
[ 0., -4., -1., ..., 5., 0., 3.],
...,
[ 0., 1., -3., ..., 0., 5., 4.],
[-1., 4., -6., ..., 2., -4., -1.],
[ 4., -2., -6., ..., -5., -5., 5.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-496.27966 94.56397 47.344288 326.10242 82.47867
-287.3221 -148.02356 184.77959 330.40982 -78.458405
436.3813 -13.64361 251.81743 375.51117 6.9300766
414.30618 434.41226 373.14758 374.16064 229.50754 ], shape=(20,), dtype=float32)
我们看到观察结果规范是一个包含两个元素的字典
- 一个键为
'global':这是全局上下文部分,其形状与参数GLOBAL_DIM相匹配。 - 一个键为
'per_arm':这是每臂上下文,其形状为[NUM_ACTIONS, PER_ARM_DIM]。这部分是每个时间步中每个臂的臂特征的占位符。
LinUCB 代理
LinUCB 代理实现了同名的 Bandit 算法,该算法估计线性奖励函数的参数,同时还维护围绕估计值的置信椭球。代理选择估计预期奖励最高的臂,假设参数位于置信椭球内。
创建代理需要了解观察和动作规范。在定义代理时,我们将布尔参数 accepts_per_arm_features 设置为 True。
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
训练数据的流程
本节将简要介绍每臂特征从策略到训练的机制。如果您有兴趣,可以跳到下一节(定义遗憾指标)并稍后再回来。
首先,让我们看一下代理中的数据规范。代理的 training_data_spec 属性指定了训练数据应该具有的元素和结构。
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32))})
如果我们仔细观察规范的 observation 部分,我们会发现它不包含每臂特征!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
每臂特征去哪里了?为了回答这个问题,首先要注意的是,当 LinUCB 代理训练时,它不需要 **所有** 臂的每臂特征,它只需要 **选择** 的臂的特征。因此,删除形状为 [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] 的张量是有意义的,因为它非常浪费,尤其是在动作数量很大的情况下。
但是,所选臂的每臂特征必须在某个地方!为此,我们确保 LinUCB 策略将所选臂的特征存储在训练数据的 policy_info 字段中
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
从形状可以看出,chosen_arm_features 字段只有单个臂的特征向量,并且该臂将是所选臂。请注意,policy_info 以及 chosen_arm_features 是训练数据的一部分,正如我们从检查训练数据规范中看到的那样,因此它在训练时可用。
定义遗憾指标
在开始训练循环之前,我们定义了一些帮助计算代理遗憾的实用程序函数。这些函数有助于确定给定动作集(由其臂特征给出)和隐藏在代理之外的线性参数的最佳预期奖励。
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
现在我们已经准备好开始我们的强盗训练循环。下面的驱动程序负责使用策略选择动作,将所选动作的奖励存储在重放缓冲区中,计算预定义的遗憾指标,并执行代理的训练步骤。
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_24657/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
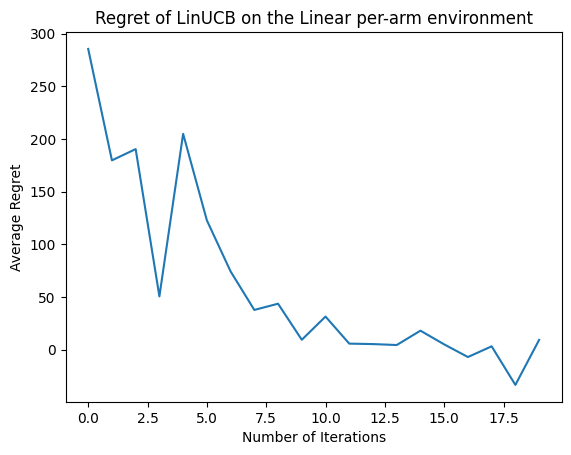
现在让我们看看结果。如果我们做对了所有事情,代理能够很好地估计线性奖励函数,因此策略可以选择预期奖励接近最佳奖励的动作。这由我们上面定义的遗憾指标表示,该指标下降并接近零。
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
下一步是什么?
上面的示例在我们的代码库中 实现,您也可以从其他代理中选择,包括 神经 epsilon-贪婪代理。