
版权所有 2023 The TF-Agents Authors。
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
简介
此示例展示了如何在 Soft Actor Critic 代理上训练 Minitaur 环境。
如果您已经完成了 DQN Colab,那么您应该会觉得很熟悉。值得注意的变化包括
- 将代理从 DQN 更改为 SAC。
- 在 Minitaur 上进行训练,Minitaur 比 CartPole 复杂得多。Minitaur 环境旨在训练四足机器人向前移动。
- 使用 TF-Agents Actor-Learner API 进行分布式强化学习。
该 API 支持使用经验回放缓冲区和变量容器(参数服务器)进行分布式数据收集,以及在多个设备上进行分布式训练。该 API 的设计非常简单且模块化。我们利用 Reverb 作为回放缓冲区和变量容器,并利用 TF DistributionStrategy API 在 GPU 和 TPU 上进行分布式训练。
如果您尚未安装以下依赖项,请运行
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybulletpip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
设置
首先,我们将导入所需的各种工具。
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
2023-12-22 12:28:38.504926: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-12-22 12:28:38.504976: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-12-22 12:28:38.506679: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
超参数
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
环境
强化学习中的环境代表我们试图解决的任务或问题。可以使用 TF-Agents 中的 suites 轻松创建标准环境。我们有不同的 suites 用于从 OpenAI Gym、Atari、DM Control 等来源加载环境,前提是给定一个字符串环境名称。
现在,让我们从 Pybullet 套件中加载 Minitaur 环境。
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Nov 28 2023 23:52:03
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/gym/spaces/box.py:84: UserWarning: WARN: Box bound precision lowered by casting to float32
logger.warn(f"Box bound precision lowered by casting to {self.dtype}")
current_dir=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data

在这个环境中,目标是让代理训练一个策略,该策略将控制 Minitaur 机器人并使其尽可能快地向前移动。每集持续 1000 步,回报将是整个集的奖励总和。
让我们看看环境作为 observation 提供的信息,策略将使用这些信息来生成 actions。
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
观察结果相当复杂。我们收到 28 个值,代表所有电机角度、速度和扭矩。作为回报,环境期望 8 个动作值介于 [-1, 1] 之间。这些是所需的电机角度。
通常,我们会创建两个环境:一个用于在训练期间收集数据,另一个用于评估。这些环境是用纯 Python 编写的,并使用 NumPy 数组,Actor Learner API 直接使用这些数组。
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data
分布策略
我们使用 DistributionStrategy API 来启用跨多个设备(例如多个 GPU 或 TPU)运行训练步骤计算,使用数据并行性。训练步骤
- 接收一批训练数据
- 将其拆分到各个设备上
- 计算前向步骤
- 聚合并计算损失的平均值
- 计算反向步骤并执行梯度变量更新
使用 TF-Agents Learner API 和 DistributionStrategy API,在 GPU(使用 MirroredStrategy)和 TPU(使用 TPUStrategy)上运行训练步骤之间切换非常容易,而无需更改下面的任何训练逻辑。
启用 GPU
如果您想尝试在 GPU 上运行,则首先需要为笔记本启用 GPU
- 导航到编辑→笔记本设置
- 从硬件加速器下拉菜单中选择 GPU
选择策略
使用 strategy_utils 生成策略。在幕后,传递参数
use_gpu = False返回tf.distribute.get_strategy(),它使用 CPUuse_gpu = True返回tf.distribute.MirroredStrategy(),它使用一台机器上 TensorFlow 可见的所有 GPU
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
所有变量和代理都需要在 strategy.scope() 下创建,如下所示。
代理
要创建 SAC 代理,我们首先需要创建它将训练的网络。SAC 是一个演员-评论家代理,因此我们需要两个网络。
评论家将为我们提供 Q(s,a) 的价值估计。也就是说,它将接收观察结果和动作作为输入,并为给定状态提供该动作有多好的估计。
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
我们将使用这个评论器来训练一个 actor 网络,它将允许我们根据观察结果生成动作。
该 ActorNetwork 将预测 tanh 压缩的 MultivariateNormalDiag 分布的参数。每当我们需要生成动作时,该分布将根据当前观察结果进行采样。
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
有了这些网络,我们现在可以实例化代理。
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
回放缓冲区
为了跟踪从环境中收集的数据,我们将使用 Reverb,这是 Deepmind 开发的一个高效、可扩展且易于使用的回放系统。它存储由 Actor 收集并在训练期间由 Learner 使用的体验数据。
在本教程中,这不像 max_size 那样重要——但在具有异步收集和训练的分布式环境中,您可能希望尝试使用 rate_limiters.SampleToInsertRatio,使用介于 2 到 1000 之间的 samples_per_insert。例如
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:162] Initializing TFRecordCheckpointer in /tmpfs/tmp/tmp277hgu8l. [reverb/cc/platform/tfrecord_checkpointer.cc:565] Loading latest checkpoint from /tmpfs/tmp/tmp277hgu8l [reverb/cc/platform/default/server.cc:71] Started replay server on port 43327
回放缓冲区是使用描述要存储的张量的规范构建的,这些规范可以通过使用 tf_agent.collect_data_spec 从代理中获取。
由于 SAC 代理需要当前和下一个观察结果来计算损失,因此我们将 sequence_length 设置为 2。
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
现在,我们从 Reverb 回放缓冲区生成一个 TensorFlow 数据集。我们将将其传递给 Learner 以对训练体验进行采样。
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
策略
在 TF-Agents 中,策略代表 RL 中策略的标准概念:给定一个 time_step,生成一个动作或一个动作分布。主要方法是 policy_step = policy.step(time_step),其中 policy_step 是一个命名元组 PolicyStep(action, state, info)。该 policy_step.action 是要应用于环境的 action,state 代表有状态 (RNN) 策略的状态,而 info 可能包含辅助信息,例如动作的对数概率。
代理包含两个策略
agent.policy— 用于评估和部署的主要策略。agent.collect_policy— 用于数据收集的第二个策略。
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
策略可以独立于代理创建。例如,使用 tf_agents.policies.random_py_policy 创建一个策略,该策略将为每个 time_step 随机选择一个动作。
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Actor
Actor 管理策略和环境之间的交互。
- Actor 组件包含一个环境实例(作为
py_environment)和策略变量的副本。 - 每个 Actor 工作器在给定策略变量的本地值的情况下运行一系列数据收集步骤。
- 变量更新是在训练脚本中显式地使用变量容器客户端实例完成的,然后再调用
actor.run()。 - 观察到的体验在每个数据收集步骤中写入回放缓冲区。
当 Actor 运行数据收集步骤时,它们将 (状态、动作、奖励) 轨迹传递给观察者,观察者会缓存这些轨迹并将它们写入 Reverb 回放系统。
我们正在存储帧的轨迹 [(t0,t1) (t1,t2) (t2,t3), ...],因为 stride_length=1。
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
我们使用随机策略创建一个 Actor,并收集体验来为回放缓冲区播种。
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
使用收集策略实例化一个 Actor,以便在训练期间收集更多体验。
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
创建一个 Actor,它将在训练期间用于评估策略。我们传入 actor.eval_metrics(num_eval_episodes) 以便稍后记录指标。
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Learner
Learner 组件包含代理,并使用回放缓冲区中的体验数据对策略变量执行梯度步骤更新。在执行一个或多个训练步骤后,Learner 可以将一组新的变量值推送到变量容器。
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:absl:`0/step_type` is not a valid tf.function parameter name. Sanitizing to `arg_0_step_type`.
WARNING:absl:`0/reward` is not a valid tf.function parameter name. Sanitizing to `arg_0_reward`.
WARNING:absl:`0/discount` is not a valid tf.function parameter name. Sanitizing to `arg_0_discount`.
WARNING:absl:`0/observation` is not a valid tf.function parameter name. Sanitizing to `arg_0_observation`.
WARNING:absl:`0/step_type` is not a valid tf.function parameter name. Sanitizing to `arg_0_step_type`.
argv[0]=
argv[0]=
argv[0]=
argv[0]=
argv[0]=
argv[0]=
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tf_agents.distributions.utils.SquashToSpecNormal_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.MultivariateNormalDiag_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/policy/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/collect_policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tf_agents.distributions.utils.SquashToSpecNormal_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.MultivariateNormalDiag_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/collect_policy/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/greedy_policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.Deterministic_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/greedy_policy/assets
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
指标和评估
我们在上面使用 actor.eval_metrics 实例化了评估 Actor,它在策略评估期间创建了最常用的指标
- 平均回报。回报是在环境中运行策略一个回合时获得的奖励总和,我们通常会对几个回合进行平均。
- 平均回合长度。
我们运行 Actor 来生成这些指标。
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.796275, AverageEpisodeLength = 131.550003
查看 指标模块 以了解其他不同指标的标准实现。
训练代理
训练循环涉及从环境中收集数据和优化代理的网络。在此过程中,我们将偶尔评估代理的策略,以了解我们的进展情况。
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
2023-12-22 12:31:02.824292: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:933] Skipping loop optimization for Merge node with control input: while/body/_121/while/replica_1/Losses/alpha_loss/write_summary/summary_cond/branch_executed/_1946
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
step = 5000: loss = -54.42484664916992
step = 10000: AverageReturn = -0.739843, AverageEpisodeLength = 292.600006
step = 10000: loss = -54.64984130859375
step = 15000: loss = -35.02790451049805
step = 20000: AverageReturn = -1.259167, AverageEpisodeLength = 441.850006
step = 20000: loss = -26.131771087646484
step = 25000: loss = -19.544872283935547
step = 30000: AverageReturn = -0.818176, AverageEpisodeLength = 466.200012
step = 30000: loss = -13.54043197631836
step = 35000: loss = -10.158345222473145
step = 40000: AverageReturn = -1.347950, AverageEpisodeLength = 601.700012
step = 40000: loss = -6.913794040679932
step = 45000: loss = -5.61244010925293
step = 50000: AverageReturn = -1.182192, AverageEpisodeLength = 483.950012
step = 50000: loss = -4.762404441833496
step = 55000: loss = -3.82161545753479
step = 60000: AverageReturn = -1.674075, AverageEpisodeLength = 623.400024
step = 60000: loss = -4.256121635437012
step = 65000: loss = -3.6529903411865234
step = 70000: AverageReturn = -1.215892, AverageEpisodeLength = 728.500000
step = 70000: loss = -4.215447902679443
step = 75000: loss = -4.645144462585449
step = 80000: AverageReturn = -1.224958, AverageEpisodeLength = 615.099976
step = 80000: loss = -4.062835693359375
step = 85000: loss = -2.9989473819732666
step = 90000: AverageReturn = -0.896713, AverageEpisodeLength = 508.149994
step = 90000: loss = -3.086637020111084
step = 95000: loss = -3.242603302001953
step = 100000: AverageReturn = -0.280301, AverageEpisodeLength = 354.649994
step = 100000: loss = -3.288505792617798
[reverb/cc/platform/default/server.cc:84] Shutting down replay server
可视化
绘图
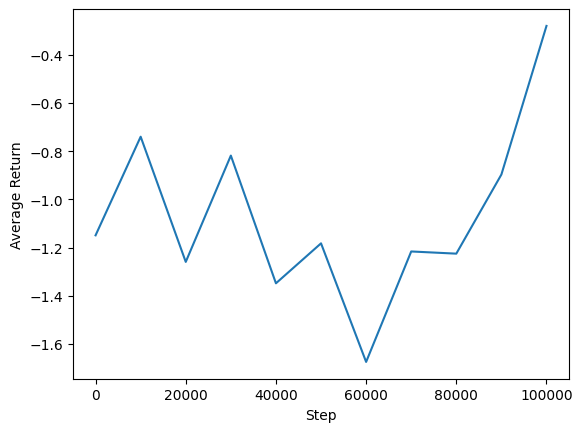
我们可以绘制平均回报与全局步骤的关系图,以查看代理的性能。在 Minitaur 中,奖励函数基于 Minitaur 在 1000 步中行走的距离,并对能量消耗进行惩罚。
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.743763194978237, -0.210612578690052)
视频
通过在每一步渲染环境来可视化代理的性能非常有用。在我们这样做之前,让我们先创建一个函数来将视频嵌入到这个 colab 中。
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
以下代码可视化了代理策略的几个回合
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)