
版权所有 2023 The TF-Agents Authors.
入门
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
设置
如果您尚未安装以下依赖项,请运行
pip install tf-agentspip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
导入
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
简介
多臂老虎机问题 (MAB) 是强化学习的一种特殊情况:代理通过在观察到环境的某些状态后采取一些行动来收集环境中的奖励。一般 RL 和 MAB 之间的主要区别在于,在 MAB 中,我们假设代理采取的行动不会影响环境的下一个状态。因此,代理不会对状态转换进行建模,不会将奖励归因于过去的行动,也不会“提前计划”以到达奖励丰富的状态。
与其他 RL 领域一样,MAB *代理* 的目标是找到一个可以收集尽可能多奖励的 *策略*。然而,始终尝试利用承诺最高奖励的行动将是一个错误,因为如果我们没有进行足够的探索,我们就有可能错过更好的行动。这是 (MAB) 中要解决的主要问题,通常称为 *探索-利用困境*。
可以在 tf_agents/bandits 的子目录中找到用于 MAB 的老虎机环境、策略和代理。
环境
在 TF-Agents 中,环境类负责提供有关当前状态的信息(这称为 **观察** 或 **上下文**),接收行动作为输入,执行状态转换,并输出奖励。此类还负责在剧集结束时重置,以便可以开始新的剧集。这是通过在状态被标记为剧集的“最后一个”状态时调用 reset 函数来实现的。
有关更多详细信息,请参阅 TF-Agents 环境教程。
如上所述,MAB 与一般 RL 的区别在于行动不会影响下一个观察结果。另一个区别是,在老虎机中,没有“剧集”:每次步都从一个新的观察结果开始,与之前的步无关。
为了确保观察结果是独立的,并抽象出 RL 剧集的概念,我们引入了 PyEnvironment 和 TFEnvironment 的子类:BanditPyEnvironment 和 BanditTFEnvironment。这些类公开了两个私有成员函数,这些函数需要由用户实现
@abc.abstractmethod
def _observe(self):
和
@abc.abstractmethod
def _apply_action(self, action):
_observe 函数返回一个观察结果。然后,策略根据此观察结果选择一个行动。 _apply_action 函数接收该行动作为输入,并返回相应的奖励。这些私有成员函数分别由函数 reset 和 step 调用。
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
上述中间抽象类实现了 PyEnvironment 的 _reset 和 _step 函数,并公开了抽象函数 _observe 和 _apply_action,以便由子类实现。
一个简单的示例环境类
以下类提供了一个非常简单的环境,其中观察结果是在 -2 到 2 之间的随机整数,有 3 个可能的行动 (0、1、2),奖励是行动和观察结果的乘积。
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
现在我们可以使用此环境来获取观察结果,并为我们的行动接收奖励。
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -2
action: 2
reward: -4.000000
/tmpfs/tmp/ipykernel_30068/1543604332.py:3: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
print("observation: %d" % observation)
/tmpfs/tmp/ipykernel_30068/1543604332.py:9: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
print("reward: %f" % reward)
TF 环境
可以通过子类化 BanditTFEnvironment 来定义老虎机环境,或者类似于 RL 环境,可以定义 BanditPyEnvironment 并将其包装在 TFPyEnvironment 中。为了简单起见,在本教程中,我们选择使用后一种方法。
tf_environment = tf_py_environment.TFPyEnvironment(environment)
策略
老虎机问题中的 *策略* 与 RL 问题中的策略工作方式相同:它提供一个行动(或行动分布),作为输入给定一个观察结果。
有关更多详细信息,请参阅 TF-Agents 策略教程。
与环境一样,有两种方法可以构建策略:可以创建一个 PyPolicy 并将其包装在 TFPyPolicy 中,或者直接创建一个 TFPolicy。在这里,我们选择使用直接方法。
由于此示例非常简单,因此我们可以手动定义最佳策略。行动仅取决于观察结果的符号,当观察结果为负时为 0,当观察结果为正时为 2。
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
现在我们可以从环境中请求一个观察结果,调用策略来选择一个行动,然后环境将输出奖励
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[-1]], shape=(1, 1), dtype=int32) Action: tf.Tensor([0], shape=(1,), dtype=int32) Reward: tf.Tensor([[0.]], shape=(1, 1), dtype=float32)
老虎机环境的实现方式确保每次我们采取一步时,我们不仅会收到我们采取的行动的奖励,还会收到下一个观察结果。
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[0.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[1]], shape=(1, 1), dtype=int32)
代理
现在我们有了老虎机环境和老虎机策略,是时候定义老虎机代理了,这些代理负责根据训练样本更改策略。
老虎机代理的 API 与 RL 代理的 API 不同:代理只需要实现 _initialize 和 _train 方法,并定义一个 policy 和一个 collect_policy。
一个更复杂的环境
在我们编写我们的 bandit 代理之前,我们需要一个更难理解的环境。为了让事情更有趣,下一个环境将始终给出 reward = observation * action 或 reward = -observation * action。这将在环境初始化时决定。
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: 1
更复杂的策略
更复杂的环境需要更复杂的策略。我们需要一个能够检测底层环境行为的策略。策略需要处理三种情况:
- 代理尚未检测到正在运行的环境版本。
- 代理检测到正在运行原始版本的环境。
- 代理检测到正在运行翻转版本的环境。
我们定义一个名为 _situation 的 tf_variable 来存储此信息,将其编码为 [0, 2] 中的值,然后使策略相应地执行。
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
代理
现在是时候定义一个代理,它可以检测环境的符号并适当地设置策略。
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
在上面的代码中,代理定义了策略,变量 situation 由代理和策略共享。
此外,_train 函数的参数 experience 是一个轨迹。
轨迹
在 TF-Agents 中,trajectories 是命名元组,包含来自先前执行步骤的样本。这些样本随后被代理用于训练和更新策略。在 RL 中,轨迹必须包含有关当前状态、下一个状态以及当前回合是否结束的信息。由于在 Bandit 世界中我们不需要这些东西,因此我们设置了一个辅助函数来创建轨迹。
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
训练代理
现在所有部分都已准备就绪,可以训练我们的 bandit 代理。
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
Trajectory(
{'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'policy_info': (),
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>})
从输出中可以看出,在第二步之后(除非第一步中的观察结果为 0),策略以正确的方式选择动作,因此收集到的奖励始终非负。
真实的上下文 Bandit 示例
在本教程的其余部分,我们将使用 TF-Agents Bandits 库中预先实现的 环境 和 代理。
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
具有线性收益函数的平稳随机环境
本示例中使用的环境是 StationaryStochasticPyEnvironment。此环境将一个(通常是带噪声的)函数作为参数,用于提供观察结果(上下文),并且对于每个臂,它都采用一个(也是带噪声的)函数,该函数根据给定的观察结果计算奖励。在本示例中,我们从 d 维立方体中均匀地采样上下文,并且奖励函数是上下文的线性函数,加上一些高斯噪声。
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
LinUCB 代理
下面的代理实现了 LinUCB 算法。
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
遗憾指标
Bandit 最重要的指标是遗憾,它计算为代理收集的奖励与具有访问环境奖励函数的预言策略的预期奖励之间的差值。因此,RegretMetric 需要一个baseline_reward_fn 函数,该函数计算给定观察结果的最佳可实现预期奖励。对于我们的示例,我们需要取我们已经为环境定义的奖励函数的无噪声等效值的最大值。
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
训练
现在我们将上面介绍的所有组件放在一起:环境、策略和代理。我们在环境上运行策略,并在驱动程序的帮助下输出训练数据,并在数据上训练代理。
请注意,有两个参数共同指定了执行的步骤数。 num_iterations 指定我们运行训练器循环的次数,而驱动程序将在每次迭代中执行 steps_per_loop 步。保留这两个参数的主要原因是,某些操作在每次迭代中执行,而某些操作由驱动程序在每一步中执行。例如,代理的 train 函数仅在每次迭代中调用一次。这里的权衡是,如果我们更频繁地训练,那么我们的策略会“更新”,另一方面,以更大的批次进行训练可能会更有效率。
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_30068/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
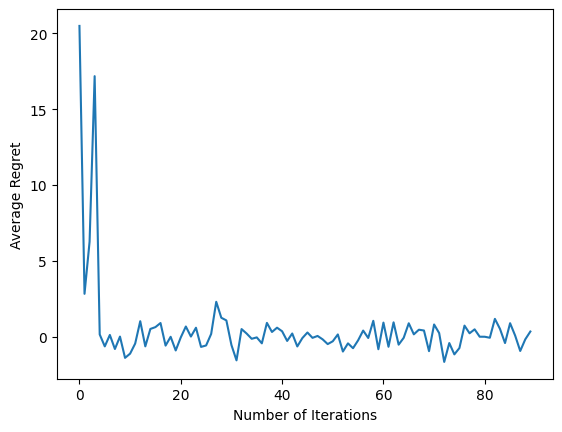
在运行最后一个代码片段后,生成的绘图(希望)显示出,随着代理的训练和策略在确定给定观察结果的正确动作方面变得更好,平均遗憾会下降。
下一步是什么?
要查看更多工作示例,请参阅 bandits/agents/examples,其中包含针对不同代理和环境的即用型示例。
TF-Agents 库还能够处理具有每臂特征的多臂 Bandit。为此,我们建议读者参考每臂 Bandit 教程。