在 GitHub 上查看源代码
在 GitHub 上查看源代码此笔记本向您展示如何训练文本分类器以识别攻击性内容,以及如何使用 反事实逻辑配对 (CLP) 来避免身份术语不公平地扭曲被分类为攻击性的内容。这种类型的模型试图识别粗鲁、不尊重或可能导致某人离开讨论的内容,并为内容分配一个毒性分数。 CLP 技术可用于识别和缓解身份术语与毒性分数之间的相关性,并且作为 TensorFlow 模型修复库的一部分提供。
在 Perspective API 首次发布后,用户发现包含种族或性取向信息的身份术语与预测的毒性分数之间存在正相关性。例如,短语“我是一个女同性恋”的毒性分数为 0.51,而“我是一个男人”的毒性分数为 0.2。在这种情况下,身份术语没有被贬义使用,因此分数不应该存在如此大的差异。
在此 Colab 中,您将探索如何使用 CLP 训练与 Perspective API 具有类似偏差的文本分类器,以及如何修复偏差。您将按照以下步骤进行操作
- 构建一个基线模型来对文本的毒性进行分类。
- 使用
CounterfactualPackedInputs创建一个实例,其中包含original_input和counterfactual_data,以评估模型在翻转率和翻转次数方面的性能,以确定是否需要干预。 - 使用 CLP 技术进行训练,以避免模型输出与敏感身份术语之间出现意外的相关性。
- 评估新模型在翻转率和翻转次数方面的性能。
本教程演示了 CLP 技术的最小使用。在评估模型在负责任的 AI 原则方面的性能时,请考虑还有许多其他工具可用
- 评估不同群体之间的错误率
- 使用 公平性指标 中提供的其他指标进行评估
- 考虑探索 负责任的 AI 工具包。
设置
您首先安装公平性指标和 TensorFlow 模型修复。
pip install --upgrade tensorflow-model-remediationpip install --upgrade fairness-indicators
导入所有必要的组件,包括用于评估的 CLP 和公平性指标。
import os
import requests
import tempfile
import zipfile
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_model_analysis as tfma
from google.protobuf import text_format
# Import Counterfactuals.
from tensorflow_model_remediation import counterfactual
import pkg_resources
import importlib
importlib.reload(pkg_resources)
您使用下面提供的名为 download_and_process_civil_comments_data 的实用程序函数来下载预处理数据并准备标签以匹配模型的输出形状。该函数还将数据下载为 TFRecords,以加快以后的评估速度。
将 comment_text 特征设置为输入,将 toxicity 设置为标签。
TEXT_FEATURE = 'comment_text'
LABEL = 'toxicity'
BATCH_SIZE = 512
实用程序函数
定义和训练基线模型
为了减少运行时间,您可以使用默认情况下将加载的预训练模型。它是一个简单的 Keras 顺序模型,具有初始嵌入和卷积层,输出毒性预测。如果您愿意,您可以更改此模型并使用上面定义的实用程序函数从头开始训练,以创建模型。
use_pretrained_model = True
if use_pretrained_model:
URL = 'https://storage.googleapis.com/civil_comments_model/baseline_model.zip'
ZIPPATH = 'baseline_model.zip'
DIRPATH = '/tmp/baseline_model'
with requests.get(URL, allow_redirects=True) as r:
with open(ZIPPATH, 'wb') as z:
z.write(r.content)
with zipfile.ZipFile(ZIPPATH, 'r') as zip_ref:
zip_ref.extractall('/')
baseline_model = tf.keras.models.load_model(
DIRPATH, custom_objects={'KerasLayer' : hub.KerasLayer})
else:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
baseline_model = (
create_keras_sequential_model())
baseline_model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'])
baseline_model.fit(x=data_train[TEXT_FEATURE],
y=labels_train, batch_size=BATCH_SIZE,
epochs=1)
要使用公平性指标评估原始模型的性能,您需要保存模型。
base_dir = tempfile.mkdtemp(prefix='saved_models')
baseline_model_location = os.path.join(base_dir, 'model_export_baseline')
baseline_model.save(baseline_model_location, save_format='tf')
确定是否需要干预
使用 CLP 尝试减少数据集中与性别相关的术语的翻转率和翻转次数。
准备 CounterfactualPackedInputs
要使用 CLP,您首先需要创建一个 CounterfactualPackedInputs 实例,其中包含 original_input 和 counterfactual_data。
CounterfactualPackedInputs 如下所示
CounterfactualPackedInputs(
original_input=(x, y, sample_weight),
counterfactual_data=(original_x, counterfactual_x,
counterfactual_sample_weight)
)
original_input 应该是用于训练 Keras 模型的原始数据集。 counterfactual_data 应该是一个 tf.data.Dataset,包含原始的 x 值、相应的反事实值和样本权重。 counterfactual_x 值与原始值几乎相同,但删除或替换了一个或多个敏感属性。 此数据集用于将原始值和反事实值之间的损失函数配对,目的是确保当敏感属性不同时,模型的预测不会改变。
以下是一个 counterfactual_data 的示例,如果您删除了“gay”一词。
original_x: “I am a gay man”
counterfactual_x: “I am a man”
counterfactual_sample_weight”: 1
如果您使用的是文本,可以使用提供的辅助函数 build_counterfactual_data 来创建 counterfactual_data。 对于所有其他数据类型,您需要直接提供 counterfactual_data。
有关使用 build_counterfactual_data 创建 counterfactual_data 的示例,请参阅 创建自定义反事实数据集 Colab。
在此示例中,您将使用 build_counterfactual_data 删除性别特定术语列表。 您必须只包含非贬义词,因为贬义词应该具有不同的毒性评分。 要求对包含贬义词的示例进行相同预测可能会意外地损害更脆弱的群体。
sensitive_terms_to_remove = [
'aunt', 'boy', 'brother', 'dad', 'daughter', 'father', 'female', 'gay',
'girl', 'grandma', 'grandpa', 'grandson', 'grannie', 'granny', 'he',
'heir', 'her', 'him', 'his', 'hubbies', 'hubby', 'husband', 'king',
'knight', 'lad', 'ladies', 'lady', 'lesbian', 'lord', 'man', 'male',
'mom', 'mother', 'mum', 'nephew', 'niece', 'prince', 'princess',
'queen', 'queens', 'she', 'sister', 'son', 'uncle', 'waiter',
'waitress', 'wife', 'wives', 'woman', 'women'
]
# Convert the Pandas DataFrame to a TF Dataset
dataset_train_main = tf.data.Dataset.from_tensor_slices(
(data_train[TEXT_FEATURE].values, labels_train))
counterfactual_data = counterfactual.keras.utils.build_counterfactual_data(
original_input=dataset_train_main,
sensitive_terms_to_remove=sensitive_terms_to_remove)
counterfactual_packed_input = counterfactual.keras.utils.pack_counterfactual_data(
dataset_train_main,
counterfactual_data).batch(BATCH_SIZE)
计算示例数量、翻转率和翻转次数
接下来运行公平性指标以计算翻转率和翻转次数,以查看模型是否错误地将某些性别身份术语与毒性相关联。 运行公平性指标还使您能够计算示例数量,以确保有足够的示例来应用该技术。 翻转 定义为分类器在示例中的身份术语发生变化时给出不同的预测。 翻转次数 衡量分类器在给定示例中的身份术语发生变化时给出不同决策的次数。 翻转率 衡量分类器在给定示例中的身份术语发生变化时给出不同决策的概率。
def get_eval_results(model_location,
eval_result_path,
validate_tfrecord_file,
slice_selection='gender',
compute_confidence_intervals=True):
"""Get Fairness Indicators eval results."""
# Define slices that you want the evaluation to run on.
eval_config = text_format.Parse("""
model_specs {
label_key: '%s'
}
metrics_specs {
metrics {class_name: "AUC"}
metrics {class_name: "ExampleCount"}
metrics {class_name: "Accuracy"}
metrics {
class_name: "FairnessIndicators"
}
metrics {
class_name: "FlipRate"
config: '{ "counterfactual_prediction_key": "toxicity", '
'"example_id_key": 1 }'
}
}
slicing_specs {
feature_keys: '%s'
}
slicing_specs {}
options {
compute_confidence_intervals { value: %s }
disabled_outputs{values: "analysis"}
}
""" % (LABEL, slice_selection, compute_confidence_intervals),
tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=model_location, tags=[tf.saved_model.SERVING])
return tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
data_location=validate_tfrecord_file,
eval_config=eval_config,
output_path=eval_result_path)
base_dir = tempfile.mkdtemp(prefix='eval')
eval_dir = os.path.join(base_dir, 'tfma_eval_result_no_cf')
base_eval_result = get_eval_results(
baseline_model_location,
eval_dir,
validate_tfrecord_file,
slice_selection='gender')
# docs-infra: no-execute
tfma.addons.fairness.view.widget_view.render_fairness_indicator(
eval_result=base_eval_result)
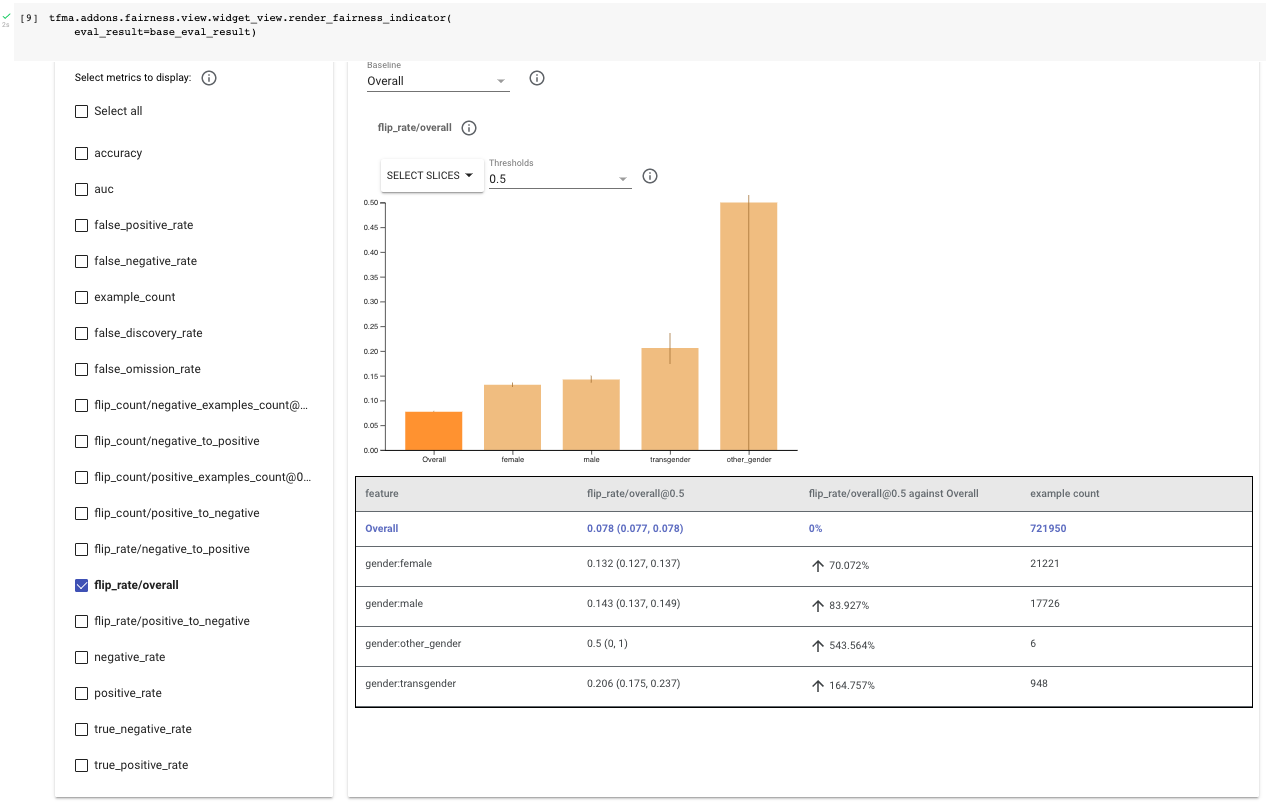
检查评估结果,从整体翻转率(“flip_rate/overall”)开始。 在此示例中,您将考虑此数据集中四个与性别相关的属性:“female”、“male”、“transgender” 和 “other_gender”。
首先检查示例数量。 与整个数据集相比,“其他性别” 和 “变性人” 的示例数量较少;这在某种程度上是预料之中的,因为历史上边缘化的群体在 ML 数据集中往往代表性不足。 它们还具有较宽的置信区间,这表明计算的指标可能不具有代表性。 本笔记本重点关注 “female” 和 “male” 子组,因为没有足够的数据将该技术应用于 “other gender” 和 “transgender”。 评估 “other gender” 和 “transgender” 群体的反事实公平性非常重要。 您可以收集更多数据以缩小置信区间。
通过在公平性指标中选择 flip_rate/overall,请注意女性的整体翻转率约为 13%,男性约为 14%,两者都高于整个数据集的 8%。 这意味着模型很可能会根据 sensitive_terms_to_remove 中列出的术语的存在来改变分类。
您现在将使用 CLP 来尝试降低我们数据集中与性别相关的术语的翻转率和翻转次数。
训练和评估 CLP 模型
要使用 CLP 进行训练,请传入您的原始预训练模型、反事实损失和 CounterfactualPackedInputs 形式的数据。 请注意,CounterfactualModel 中有两个可选参数,loss_weight 和 loss,您可以调整它们来微调模型。
接下来,以正常方式编译模型(使用常规的非反事实损失),并将其拟合以进行训练。
counterfactual_weight = 1.0
base_dir = tempfile.mkdtemp(prefix='saved_models')
counterfactual_model_location = os.path.join(
base_dir, 'model_export_counterfactual')
counterfactual_model = counterfactual.keras.CounterfactualModel(
baseline_model,
loss=counterfactual.losses.PairwiseMSELoss(),
loss_weight=counterfactual_weight)
# Compile the model normally after wrapping the original model.
# Note that this means we use the baseline's model's loss here.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
counterfactual_model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'])
counterfactual_model.fit(counterfactual_packed_input,
epochs=1)
counterfactual_model.save_original_model(counterfactual_model_location,
save_format='tf')
# docs-infra: no-execute
def get_eval_results_counterfactual(
baseline_model_location,
counterfactual_model_location,
eval_result_path,
validate_tfrecord_file,
slice_selection='gender'):
"""Get Fairness Indicators eval results."""
eval_config = text_format.Parse("""
model_specs { name: 'original' label_key: '%s' }
model_specs { name: 'counterfactual' label_key: '%s' is_baseline: true }
metrics_specs {
metrics {class_name: "AUC"}
metrics {class_name: "ExampleCount"}
metrics {class_name: "Accuracy"}
metrics { class_name: "FairnessIndicators" }
metrics { class_name: "FlipRate" config: '{ "example_ids_count": 0 }' }
metrics { class_name: "FlipCount" config: '{ "example_ids_count": 0 }' }
}
slicing_specs { feature_keys: '%s' }
slicing_specs {}
options { disabled_outputs{ values: "analysis"} }
""" % (LABEL, LABEL, slice_selection,), tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name='original',
eval_saved_model_path=baseline_model_location,
eval_config=eval_config,
tags=[tf.saved_model.SERVING]),
tfma.default_eval_shared_model(
model_name='counterfactual',
eval_saved_model_path=counterfactual_model_location,
eval_config=eval_config,
tags=[tf.saved_model.SERVING]),
]
return tfma.run_model_analysis(
eval_shared_model=eval_shared_models,
data_location=validate_tfrecord_file,
eval_config=eval_config,
output_path=eval_result_path)
counterfactual_eval_dir = os.path.join(base_dir, 'tfma_eval_result_cf')
counterfactual_eval_result = get_eval_results_counterfactual(
baseline_model_location,
counterfactual_model_location,
counterfactual_eval_dir,
validate_tfrecord_file)
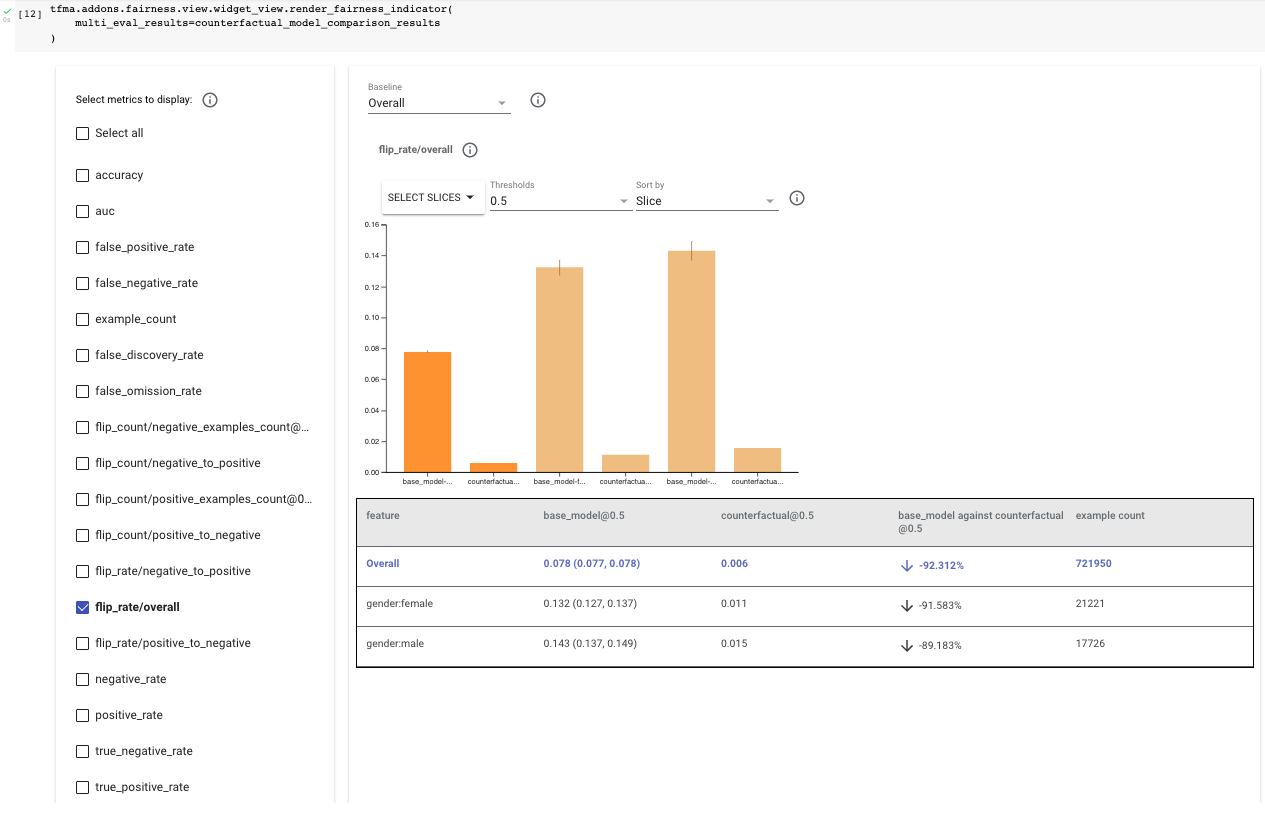
通过将原始模型和反事实模型都传递到公平性指标中以进行并排比较来评估反事实模型。 再次,在公平性指标中选择 “flip_rate/overall”,并比较两个模型之间女性和男性的结果。 您应该注意到,整体、女性和男性的翻转率都下降了约 90%,这使得女性的最终翻转率约为 1.3%,男性的最终翻转率约为 1.4%。
此外,查看 “flip_rate/negative_to_positive” 和 “flip_rate/positive_to_negative”,您会注意到模型仍然更有可能将与性别相关的內容翻转为有毒的,但总数下降了 35% 以上。
# docs-infra: no-execute
counterfactual_model_comparison_results = {
'base_model': base_eval_result,
'counterfactual': counterfactual_eval_result.get_results()[0],
}
tfma.addons.fairness.view.widget_view.render_fairness_indicator(
multi_eval_results=counterfactual_model_comparison_results
)
要详细了解 CLP 和其他补救技术,请探索 负责任的 AI 网站。