

识别音频内容的任务称为音频分类。音频分类模型经过训练可以识别各种音频事件。例如,您可以训练一个模型来识别代表三种不同事件的事件:鼓掌、手指弹响和打字。TensorFlow Lite 提供了优化的预训练模型,您可以将其部署到您的移动应用程序中。了解更多关于使用 TensorFlow 进行音频分类的信息 这里.
下图显示了音频分类模型在 Android 上的输出。
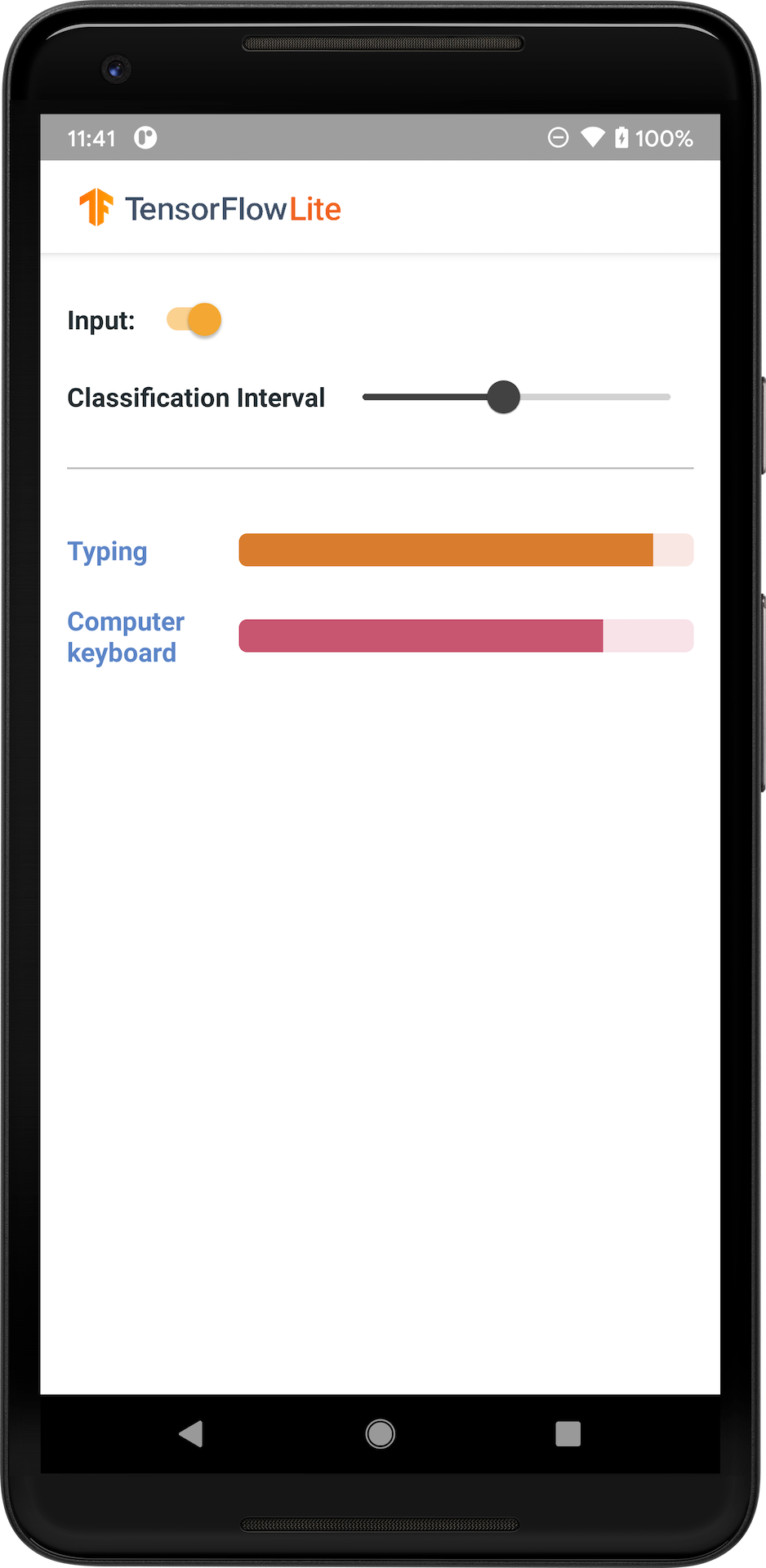
入门
如果您是 TensorFlow Lite 的新手,并且正在使用 Android,我们建议您探索以下示例应用程序,它们可以帮助您入门。
您可以利用 TensorFlow Lite 任务库 中的开箱即用的 API,只需几行代码即可集成音频分类模型。您还可以使用 TensorFlow Lite 支持库 构建自己的自定义推理管道。
以下 Android 示例演示了使用 TFLite 任务库 的实现
如果您使用的是 Android/iOS 以外的平台,或者您已经熟悉 TensorFlow Lite API,请下载入门模型和支持文件(如果适用)。
模型描述
YAMNet 是一种音频事件分类器,它以音频波形作为输入,并对来自 AudioSet 本体论的 521 个音频事件中的每一个进行独立预测。该模型使用 MobileNet v1 架构,并使用 AudioSet 语料库进行训练。该模型最初在 TensorFlow 模型花园中发布,其中包含模型源代码、原始模型检查点和更详细的文档。
工作原理
YAMNet 模型有两个版本已转换为 TFLite
YAMNet 是原始的音频分类模型,具有动态输入大小,适用于迁移学习、Web 和移动部署。它还具有更复杂的输出。
YAMNet/classification 是一个量化版本,具有更简单的固定长度帧输入(15600 个样本),并返回一个包含 521 个音频事件类别的分数的单个向量。
输入
该模型接受一个长度为 15600 的 1-D float32 张量或 NumPy 数组,其中包含一个 0.975 秒的波形,表示为范围在 [-1.0, +1.0] 内的单声道 16 kHz 样本。
输出
该模型返回一个形状为 (1, 521) 的 2-D float32 张量,其中包含对 AudioSet 本体论中 YAMNet 支持的 521 个类别中的每一个的预测分数。分数张量的列索引 (0-520) 使用 YAMNet 类别映射映射到相应的 AudioSet 类别名称,该映射作为关联文件 yamnet_label_list.txt 打包到模型文件中。有关用法,请参见下文。
适用用途
YAMNet 可用于
- 作为独立的音频事件分类器,在各种音频事件中提供合理的基线。
- 作为高级特征提取器:YAMNet 的 1024-D 嵌入输出可以用作另一个模型的输入特征,然后可以在少量数据上针对特定任务进行训练。这允许快速创建专门的音频分类器,而无需大量标记数据,也无需端到端训练大型模型。
- 作为热启动:YAMNet 模型参数可用于初始化更大模型的一部分,这允许更快的微调和模型探索。
局限性
- YAMNet 的分类器输出尚未在类别之间进行校准,因此您不能直接将输出视为概率。对于任何给定的任务,您很可能需要使用特定于任务的数据进行校准,这使您能够分配适当的每类别分数阈值和缩放。
- YAMNet 已在数百万个 YouTube 视频上进行训练,尽管这些视频非常多样,但平均 YouTube 视频与任何给定任务所需的音频输入之间仍然可能存在域不匹配。您应该预期进行一定程度的微调和校准,才能使 YAMNet 在您构建的任何系统中可用。
模型定制
提供的预训练模型经过训练可以检测 521 个不同的音频类别。有关类别的完整列表,请参见 模型存储库 中的标签文件。
您可以使用一种称为迁移学习的技术来重新训练模型,使其识别原始集中不存在的类别。例如,您可以重新训练模型以检测多种鸟鸣声。为此,您需要为每个要训练的新标签准备一组训练音频。推荐使用 TensorFlow Lite 模型制作器 库,它使用几行代码简化了使用自定义数据集训练 TensorFlow Lite 模型的过程。它使用迁移学习来减少所需的训练数据量和时间。您还可以从 音频识别迁移学习 中学习迁移学习的示例。
进一步阅读和资源
使用以下资源来了解更多关于音频分类相关概念的信息