
|
|
|
简介
大型语言模型 (LLM) 是一类机器学习模型,经过训练可以根据大型数据集生成文本。它们可用于自然语言处理 (NLP) 任务,包括文本生成、问答和机器翻译。它们基于 Transformer 架构,并使用大量文本数据进行训练,通常涉及数十亿个单词。即使是规模较小的 LLM,例如 GPT-2,也能表现出色。将 TensorFlow 模型转换为更轻、更快、低功耗的模型,使我们能够在设备上运行生成式 AI 模型,并带来更好的用户安全性,因为数据永远不会离开您的设备。
本运行手册向您展示如何使用 TensorFlow Lite 构建 Android 应用程序以运行 Keras LLM,并提供使用量化技术优化模型的建议,否则需要更大的内存量和更高的计算能力才能运行。
我们已经开源了我们的 Android 应用程序框架,任何兼容的 TFLite LLM 都可以插入其中。以下是两个演示
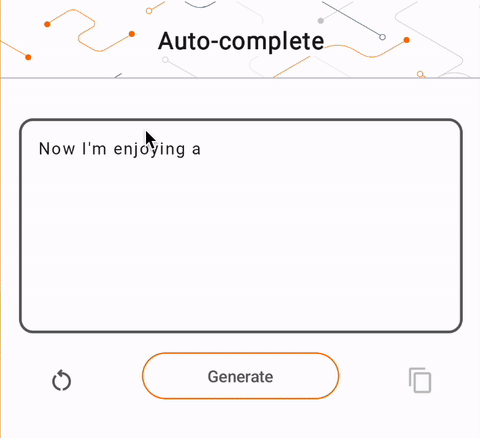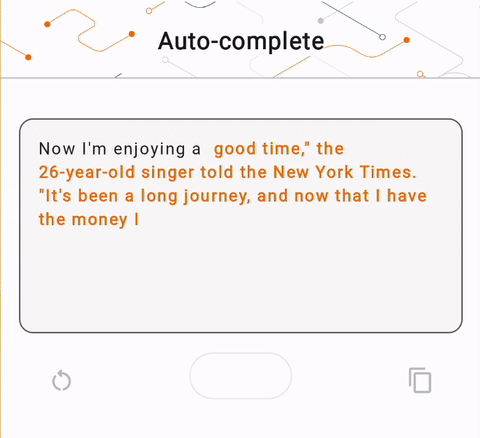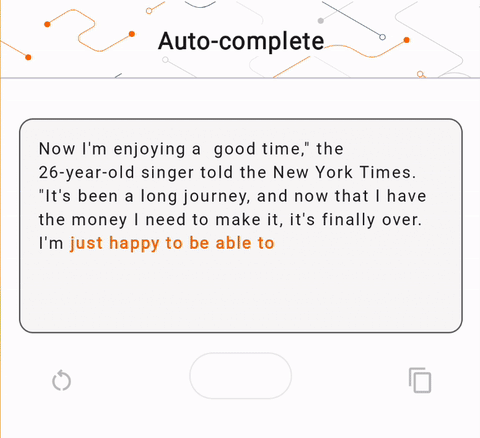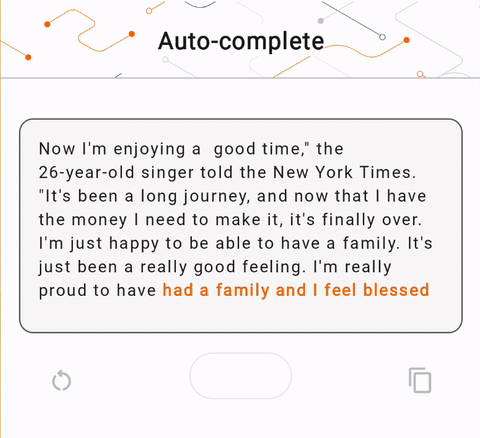
- 在图 1 中,我们使用 Keras GPT-2 模型在设备上执行文本完成任务。
- 在图 2 中,我们将一个经过指令微调的 PaLM 模型(15 亿个参数)版本转换为 TFLite,并通过 TFLite 运行时执行。
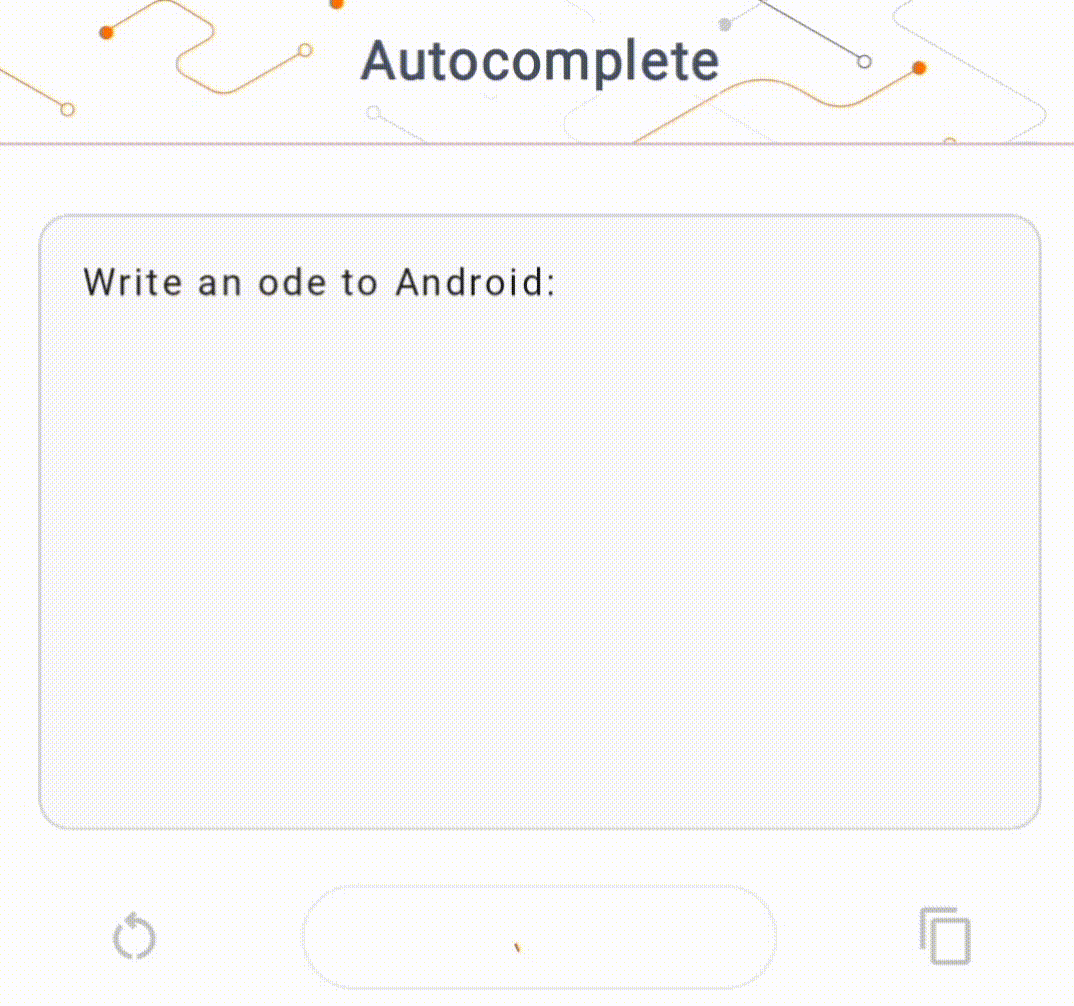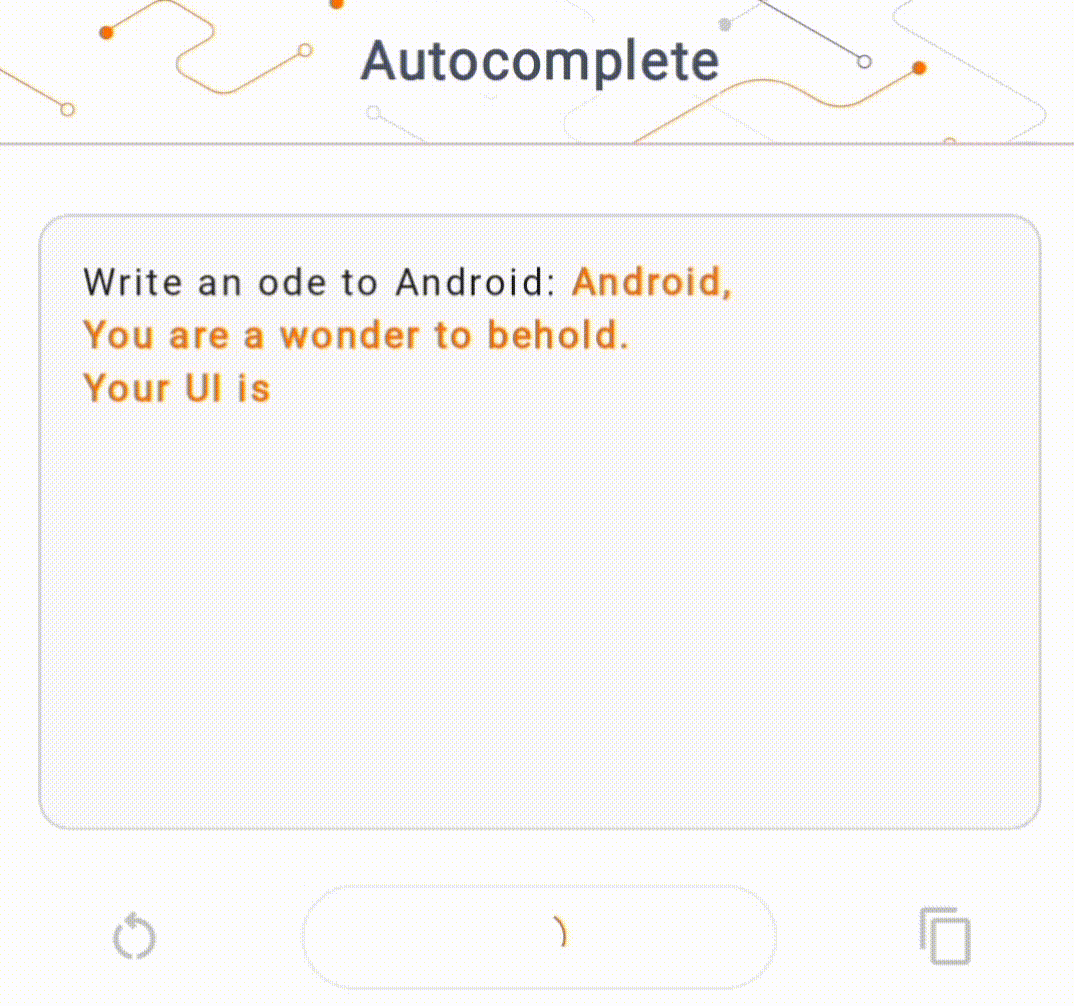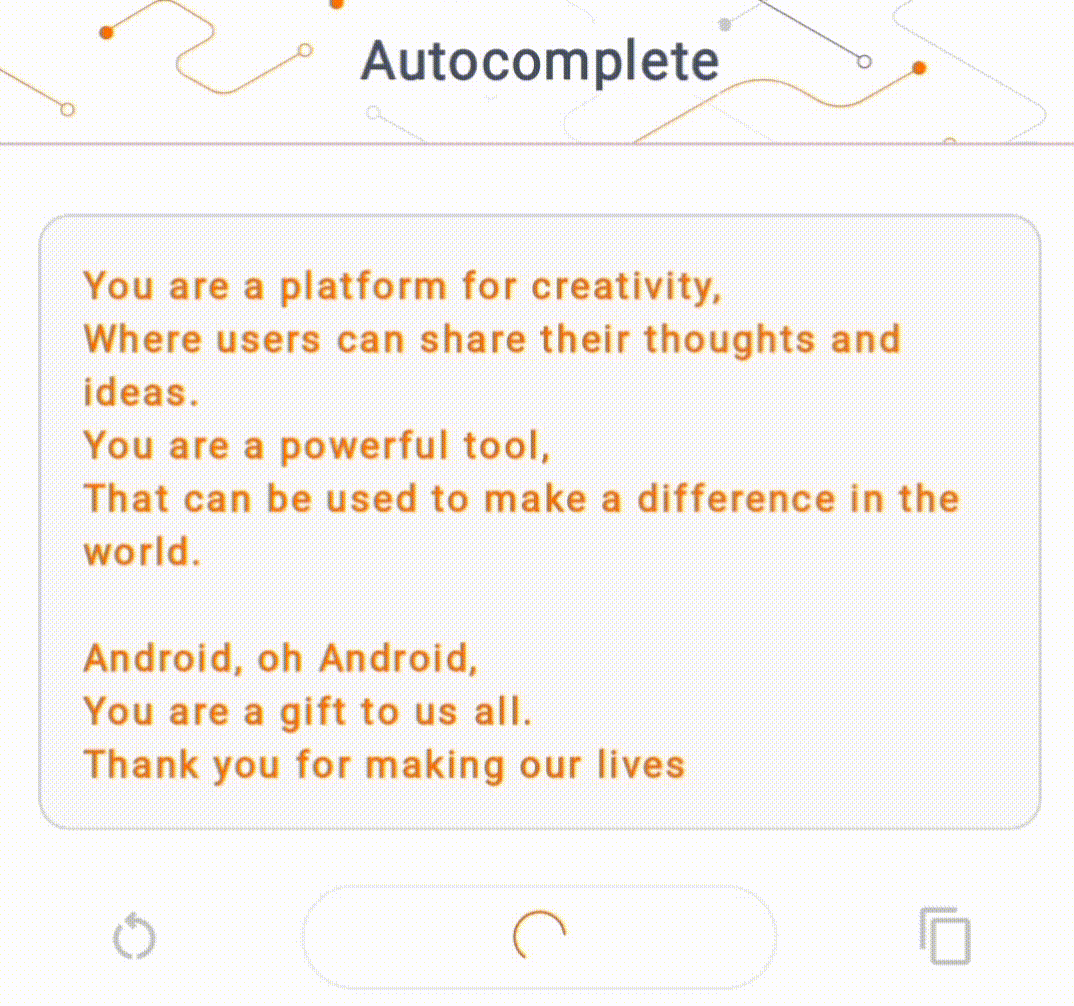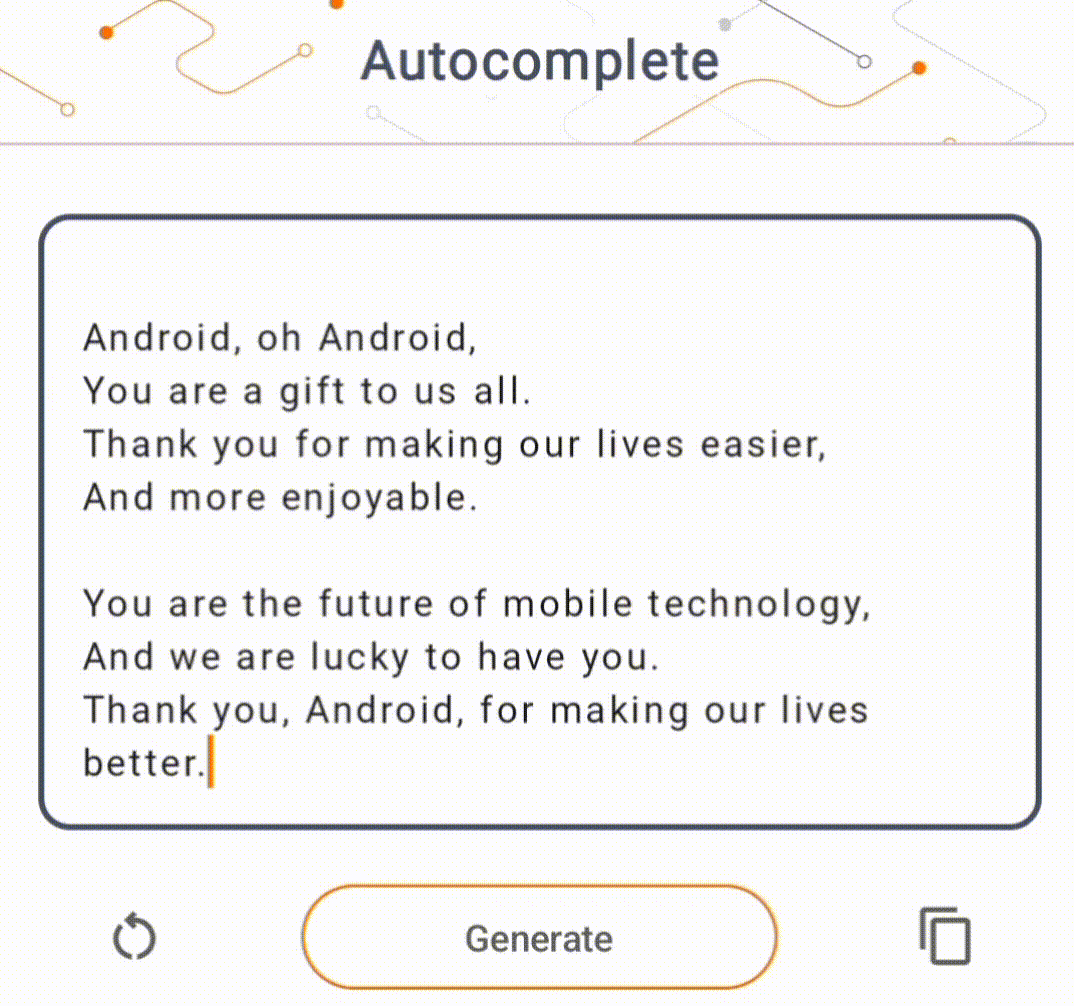
指南
模型创作
在本演示中,我们将使用 KerasNLP 获取 GPT-2 模型。KerasNLP 是一个包含用于自然语言处理任务的最先进预训练模型的库,可以支持用户完成整个开发周期。您可以在 KerasNLP 代码库 中查看可用的模型列表。工作流程由模块化组件构建,这些组件在开箱即用时具有最先进的预设权重和架构,并且在需要更多控制时易于定制。创建 GPT-2 模型可以通过以下步骤完成
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
这三行代码的一个共同点是 from_preset() 方法,该方法将从预设架构和/或权重实例化 Keras API 的一部分,从而加载预训练模型。从这段代码片段中,您还会注意到三个模块化组件
分词器:将原始字符串输入转换为适合 Keras Embedding 层的整数标记 ID。GPT-2 特别使用字节对编码 (BPE) 分词器。
预处理器:用于分词和打包输入以馈送到 Keras 模型的层。在这里,预处理器将在分词后将标记 ID 张量填充到指定长度(256)。
主干:遵循 SoTA 变形器主干架构并具有预设权重的 Keras 模型。
此外,您可以在 GitHub 上查看完整的 GPT-2 模型实现。
模型转换
TensorFlow Lite 是一个移动库,用于在移动设备、微控制器和其他边缘设备上部署方法。第一步是使用 TensorFlow Lite 转换器将 Keras 模型转换为更紧凑的 TensorFlow Lite 格式,然后使用 TensorFlow Lite 解释器(针对移动设备进行了高度优化)来运行转换后的模型。
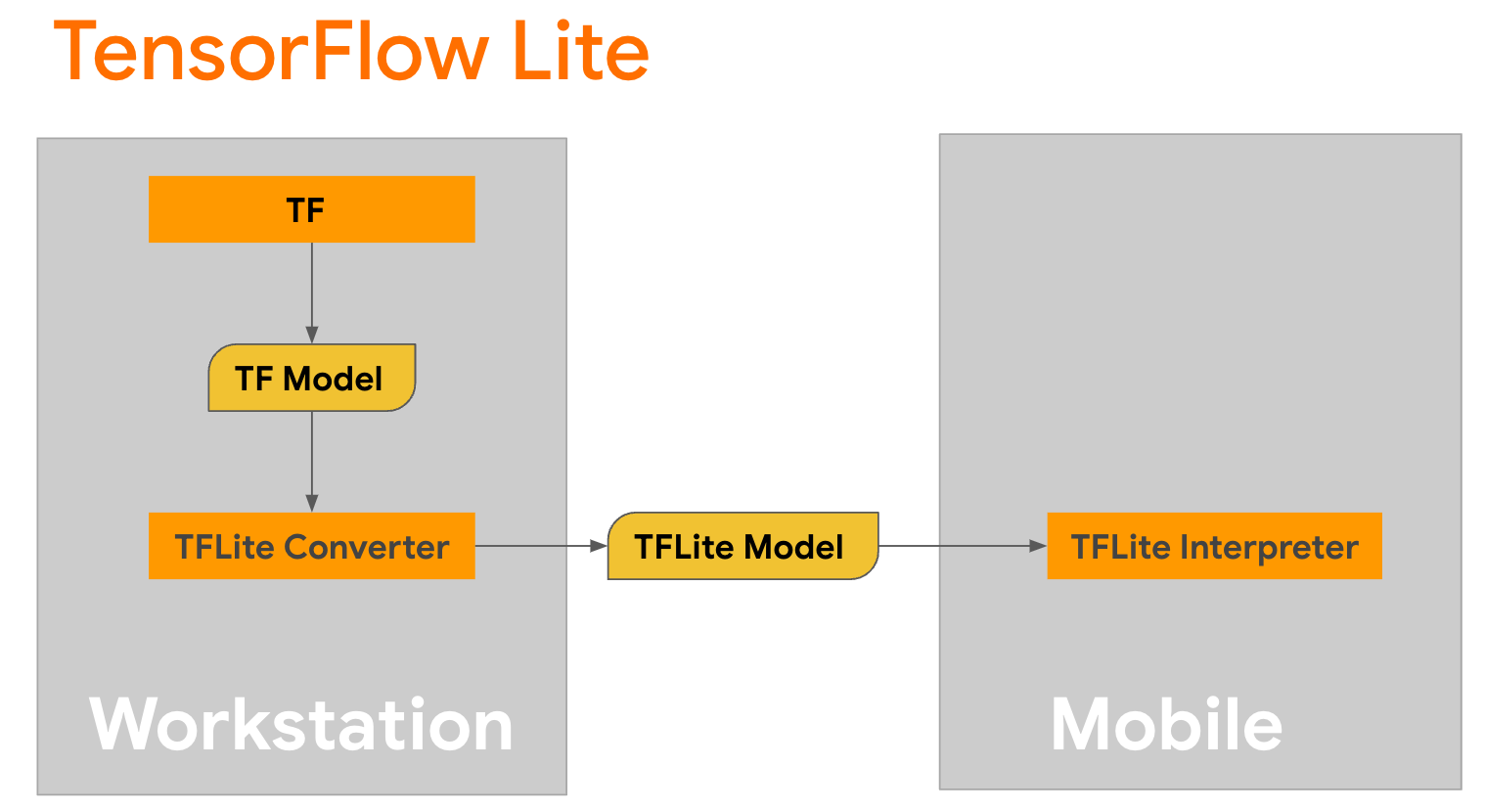 从
从 GPT2CausalLM 中的 generate() 函数开始,该函数执行转换。包装 generate() 函数以创建具体的 TensorFlow 函数
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
请注意,您也可以使用 TFLiteConverter 中的 from_keras_model() 来执行转换。
现在定义一个辅助函数,该函数将使用输入和 TFLite 模型运行推理。TensorFlow 文本操作不是 TFLite 运行时中的内置操作,因此您需要添加这些自定义操作,以便解释器能够对该模型进行推理。此辅助函数接受一个输入和一个执行转换的函数,即上面定义的 generator() 函数。
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
您现在可以转换模型
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
量化
TensorFlow Lite 实现了名为**量化**的优化技术,可以减小模型大小并加速推理。通过量化过程,将 32 位浮点数映射到更小的 8 位整数,从而将模型大小减少 4 倍,以便在现代硬件上更高效地执行。TensorFlow 中有几种量化方法。您可以访问 TFLite 模型优化 和 TensorFlow 模型优化工具包 页面以了解更多信息。下面简要介绍了量化类型。
在这里,您将使用 训练后动态范围量化 对 GPT-2 模型进行量化,方法是将转换器优化标志设置为 tf.lite.Optimize.DEFAULT,其余转换过程与之前详细介绍的相同。我们测试发现,使用这种量化技术,Pixel 7 上的延迟约为 6.7 秒,最大输出长度设置为 100。
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
动态范围
动态范围量化是优化设备上模型的推荐起点。它可以将模型大小减少约 4 倍,并且是推荐的起点,因为它可以减少内存使用量并加快计算速度,而无需您提供用于校准的代表性数据集。这种类型的量化在转换时仅将权重从浮点数静态量化为 8 位整数。
FP16
浮点模型也可以通过将权重量化为 float16 类型来优化。float16 量化 的优点是将模型大小减少一半(因为所有权重都变为原来的一半),精度损失最小,并且支持可以直接对 float16 数据进行操作的 GPU 代理(这比 float32 数据的计算速度更快)。转换为 float16 权重的模型仍然可以在 CPU 上运行,无需额外修改。float16 权重在第一次推理之前被上采样到 float32,这允许减少模型大小,以换取对延迟和精度的最小影响。
全整数量化
全整数量化 将 32 位浮点数(包括权重和激活)都转换为最接近的 8 位整数。这种类型的量化会产生更小的模型,并提高推理速度,这在使用微控制器时非常有价值。当激活对量化敏感时,建议使用此模式。
Android 应用集成
您可以按照此 Android 示例 将您的 TFLite 模型集成到 Android 应用中。
先决条件
如果您还没有安装 Android Studio,请按照网站上的说明进行安装。
- Android Studio 2022.2.1 或更高版本。
- 内存大于 4G 的 Android 设备或 Android 模拟器
使用 Android Studio 构建和运行
- 打开 Android Studio,从欢迎屏幕中选择**打开现有 Android Studio 项目**。
- 从出现的打开文件或项目窗口中,导航到并选择
lite/examples/generative_ai/android目录(您从 TensorFlow Lite 示例 GitHub 存储库中克隆的位置)。 - 您可能还需要根据错误消息安装各种平台和工具。
- 将转换后的 .tflite 模型重命名为
autocomplete.tflite并将其复制到app/src/main/assets/文件夹中。 - 选择菜单**构建 -> 生成项目**以构建应用。(Ctrl+F9,具体取决于您的版本)。
- 单击菜单**运行 -> 运行“app”**。(Shift+F10,具体取决于您的版本)
或者,您也可以使用 gradle 包装器 在命令行中构建它。有关更多信息,请参阅 Gradle 文档。
(可选)构建 .aar 文件
默认情况下,应用会自动下载所需的 .aar 文件。但是,如果您想自己构建,请切换到 app/libs/build_aar/ 文件夹并运行 ./build_aar.sh。此脚本将从 TensorFlow Text 中提取必要的运算符并构建 Select TF 运算符的 aar。
编译后,将生成一个新的文件 tftext_tflite_flex.aar。替换 app/libs/ 文件夹中的 .aar 文件并重新构建应用。
请注意,您仍然需要在 gradle 文件中包含标准的 tensorflow-lite aar。
上下文窗口大小
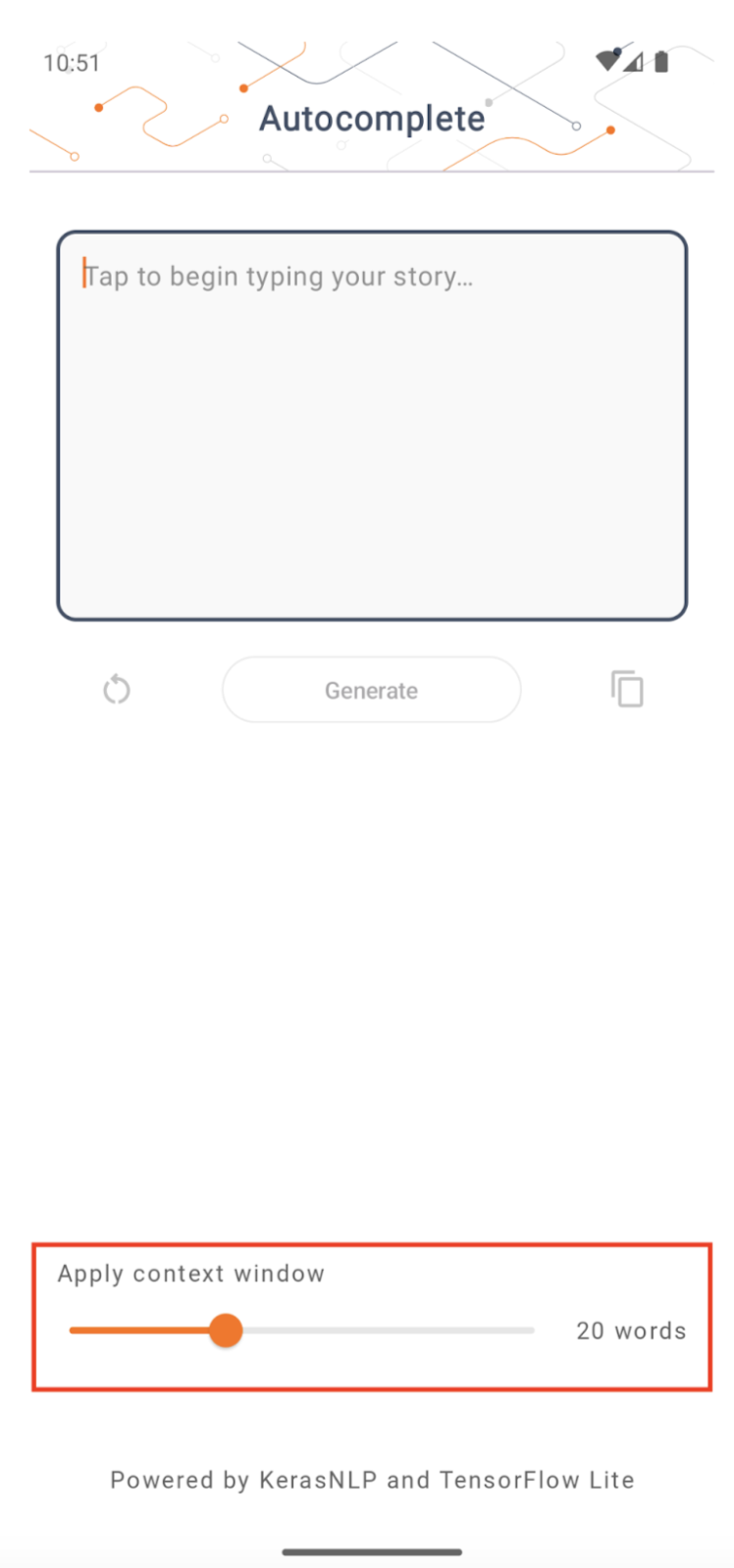
该应用有一个可更改的参数“上下文窗口大小”,这是必需的,因为当今的 LLM 通常具有固定的上下文大小,这限制了可以作为“提示”输入模型的单词/标记数量(请注意,在这种情况下,“单词”不一定等同于“标记”,因为不同的标记化方法)。这个数字很重要,因为
- 如果设置得太小,模型将没有足够的上下文来生成有意义的输出
- 如果设置得太大,模型将没有足够的空间来处理(因为输出序列包含提示)
您可以尝试一下,但将其设置为输出序列长度的约 50% 是一个不错的起点。
安全和负责任的 AI
如原始 OpenAI GPT-2 公告 中所述,GPT-2 模型存在 一些值得注意的注意事项和局限性。事实上,当今的 LLM 通常存在一些众所周知的挑战,例如幻觉、公平性和偏差;这是因为这些模型是在真实世界数据上训练的,这使得它们反映了真实世界的问题。
此代码实验室仅用于演示如何使用 TensorFlow 工具创建由 LLM 支持的应用。在此代码实验室中生成的模型仅供教育目的,不适合生产使用。
LLM 生产使用需要仔细选择训练数据集和全面的安全缓解措施。此 Android 应用中提供的一个此类功能是脏话过滤器,它会拒绝不良的用户输入或模型输出。如果检测到任何不适当的语言,应用将拒绝该操作。要了解有关 LLM 上下文中的负责任 AI 的更多信息,请务必观看 Google I/O 2023 上的“使用生成式语言模型进行安全和负责任的开发”技术会议,并查看 负责任的 AI 工具包。