|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概览
本教程演示了如何使用 TensorFlow Lattice (TFL) 库来训练行为“负责任”且不会违反某些“道德”或“公平”假设的模型。具体而言,我们将重点关注使用单调性约束来避免对某些属性进行“不公平惩罚”。本教程包含 Serena Wang 和 Maya Gupta 在 AISTATS 2020 上发表的论文 通过单调性形状约束实现道义伦理 中的实验演示。
我们将在公共数据集上使用 TFL 预制模型,但请注意,本教程中的所有内容也可以使用由 TFL Keras 层构建的模型来完成。
在继续之前,请确保您的运行时已安装所有必需的软件包(如下面的代码单元格中导入)。
设置
安装 TF Lattice 软件包
pip install --pre -U tensorflow tf-keras tensorflow-lattice tensorflow_decision_forests seaborn pydot graphviz
导入必需的软件包
import tensorflow as tf
import tensorflow_lattice as tfl
import tensorflow_decision_forests as tfdf
import logging
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import sys
import tempfile
logging.disable(sys.maxsize)
# Use Keras 2.
version_fn = getattr(tf.keras, "version", None)
if version_fn and version_fn().startswith("3."):
import tf_keras as keras
else:
keras = tf.keras
本教程中使用的默认值
# Default number of training epochs, batch sizes and learning rate.
NUM_EPOCHS = 256
BATCH_SIZE = 256
LEARNING_RATES = 0.01
# Directory containing dataset files.
DATA_DIR = 'https://raw.githubusercontent.com/serenalwang/shape_constraints_for_ethics/master'
案例研究 1:法学院录取
在本教程的第一部分,我们将使用来自法学院招生委员会 (LSAC) 的法学院招生数据集考虑一个案例研究。我们将训练一个分类器,使用两个特征(学生的 LSAT 分数和本科 GPA)来预测学生是否会通过律师资格考试。
假设分类器的分数用于指导法学院录取或奖学金。根据基于绩效的社会规范,我们希望 GPA 和 LSAT 分数较高的学生从分类器获得的分数也较高。然而,我们会观察到模型很容易违反这些直观的规范,有时还会因 GPA 或 LSAT 分数较高而惩罚人们。
为了解决这种不公平的惩罚问题,我们可以施加单调性约束,以便模型在其他条件相等的情况下绝不会惩罚较高的 GPA 或较高的 LSAT 分数。在本教程中,我们将展示如何使用 TFL 施加这些单调性约束。
加载法学院数据
# Load data file.
law_file_name = 'lsac.csv'
law_file_path = os.path.join(DATA_DIR, law_file_name)
raw_law_df = pd.read_csv(law_file_path, delimiter=',')
预处理数据集
# Define label column name.
LAW_LABEL = 'pass_bar'
def preprocess_law_data(input_df):
# Drop rows with where the label or features of interest are missing.
output_df = input_df[~input_df[LAW_LABEL].isna() & ~input_df['ugpa'].isna() &
(input_df['ugpa'] > 0) & ~input_df['lsat'].isna()]
return output_df
law_df = preprocess_law_data(raw_law_df)
将数据拆分为训练/验证/测试集
def split_dataset(input_df, random_state=888):
"""Splits an input dataset into train, val, and test sets."""
train_df, test_val_df = train_test_split(
input_df, test_size=0.3, random_state=random_state
)
val_df, test_df = train_test_split(
test_val_df, test_size=0.66, random_state=random_state
)
return train_df, val_df, test_df
dataframes = {}
datasets = {}
(dataframes['law_train'], dataframes['law_val'], dataframes['law_test']) = (
split_dataset(law_df)
)
for df_name, df in dataframes.items():
datasets[df_name] = tf.data.Dataset.from_tensor_slices(
((df[['ugpa']], df[['lsat']]), df[['pass_bar']])
).batch(BATCH_SIZE)
2024-03-27 11:20:52.644317: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:282] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
可视化数据分布
首先,我们将可视化数据的分布。我们将绘制通过律师资格考试的所有学生的 GPA 和 LSAT 分数,以及未通过律师资格考试的所有学生的 GPA 和 LSAT 分数。
def plot_dataset_contour(input_df, title):
plt.rcParams['font.family'] = ['serif']
g = sns.jointplot(
x='ugpa',
y='lsat',
data=input_df,
kind='kde',
xlim=[1.4, 4],
ylim=[0, 50])
g.plot_joint(plt.scatter, c='b', s=10, linewidth=1, marker='+')
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels('Undergraduate GPA', 'LSAT score', fontsize=14)
g.fig.suptitle(title, fontsize=14)
# Adust plot so that the title fits.
plt.subplots_adjust(top=0.9)
plt.show()
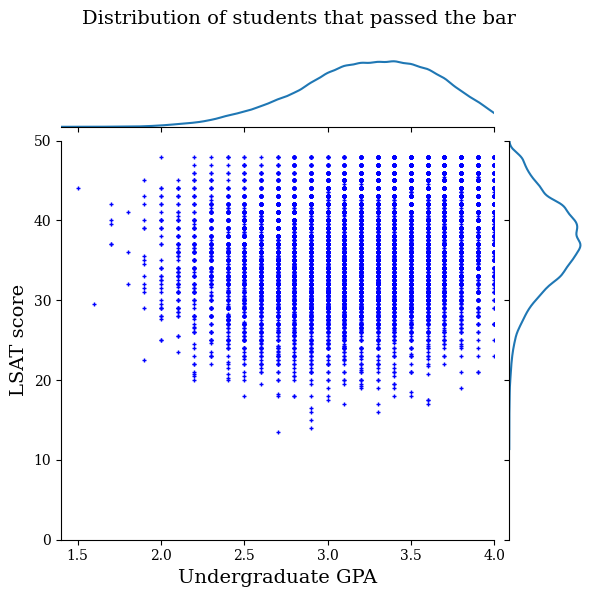
law_df_pos = law_df[law_df[LAW_LABEL] == 1]
plot_dataset_contour(
law_df_pos, title='Distribution of students that passed the bar')
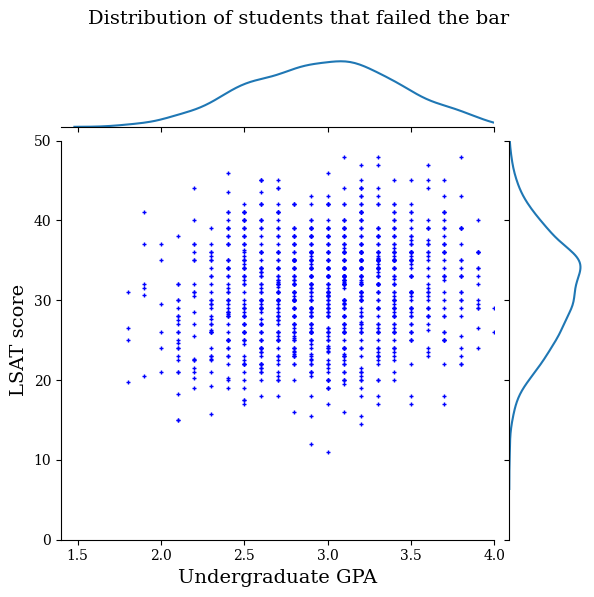
law_df_neg = law_df[law_df[LAW_LABEL] == 0]
plot_dataset_contour(
law_df_neg, title='Distribution of students that failed the bar')
训练校准晶格模型以预测律师资格考试通过情况
接下来,我们将从 TFL 训练一个校准晶格模型,以预测学生是否会通过律师资格考试。两个输入特征将是 LSAT 分数和本科 GPA,训练标签将是学生是否通过律师资格考试。
我们首先将训练一个没有任何约束的校准晶格模型。然后,我们将训练一个具有单调性约束的校准晶格模型,并观察模型输出和准确性的差异。
用于可视化训练模型输出的辅助函数
def plot_model_contour(model, from_logits=False, num_keypoints=20):
x = np.linspace(min(law_df['ugpa']), max(law_df['ugpa']), num_keypoints)
y = np.linspace(min(law_df['lsat']), max(law_df['lsat']), num_keypoints)
x_grid, y_grid = np.meshgrid(x, y)
positions = np.vstack([x_grid.ravel(), y_grid.ravel()])
plot_df = pd.DataFrame(positions.T, columns=['ugpa', 'lsat'])
plot_df[LAW_LABEL] = np.ones(len(plot_df))
predictions = model.predict((plot_df[['ugpa']], plot_df[['lsat']]))
if from_logits:
predictions = tf.math.sigmoid(predictions)
grid_predictions = np.reshape(predictions, x_grid.shape)
plt.rcParams['font.family'] = ['serif']
plt.contour(
x_grid,
y_grid,
grid_predictions,
colors=('k',),
levels=np.linspace(0, 1, 11),
)
plt.contourf(
x_grid,
y_grid,
grid_predictions,
cmap=plt.cm.bone,
levels=np.linspace(0, 1, 11),
)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
cbar = plt.colorbar()
cbar.ax.set_ylabel('Model score', fontsize=20)
cbar.ax.tick_params(labelsize=20)
plt.xlabel('Undergraduate GPA', fontsize=20)
plt.ylabel('LSAT score', fontsize=20)
训练不受约束(非单调)的校准晶格模型
我们使用 'CalibratedLatticeConfig 创建一个 TFL 预制模型。此模型是一个具有输出校准的校准晶格模型。
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name='ugpa',
lattice_size=3,
pwl_calibration_num_keypoints=16,
monotonicity=0,
pwl_calibration_always_monotonic=False,
),
tfl.configs.FeatureConfig(
name='lsat',
lattice_size=3,
pwl_calibration_num_keypoints=16,
monotonicity=0,
pwl_calibration_always_monotonic=False,
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=8),
)
我们使用 premade_lib API 计算并填充特征配置中的特征分位数。
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=model_config.feature_configs,
features=dataframes['law_train'][['ugpa', 'lsat', 'pass_bar']],
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
nomon_lattice_model = tfl.premade.CalibratedLattice(model_config=model_config)
keras.utils.plot_model(
nomon_lattice_model, expand_nested=True, show_layer_names=False, rankdir="LR"
)

nomon_lattice_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
keras.metrics.BinaryAccuracy(name='accuracy'),
],
optimizer=keras.optimizers.Adam(LEARNING_RATES),
)
nomon_lattice_model.fit(datasets['law_train'], epochs=NUM_EPOCHS, verbose=0)
train_acc = nomon_lattice_model.evaluate(datasets['law_train'])[1]
val_acc = nomon_lattice_model.evaluate(datasets['law_val'])[1]
test_acc = nomon_lattice_model.evaluate(datasets['law_test'])[1]
print(
'accuracies for train: %f, val: %f, test: %f'
% (train_acc, val_acc, test_acc)
)
63/63 [==============================] - 1s 1ms/step - loss: 0.1727 - accuracy: 0.9460 10/10 [==============================] - 0s 2ms/step - loss: 0.1877 - accuracy: 0.9390 18/18 [==============================] - 0s 1ms/step - loss: 0.1672 - accuracy: 0.9480 accuracies for train: 0.945995, val: 0.939003, test: 0.948020
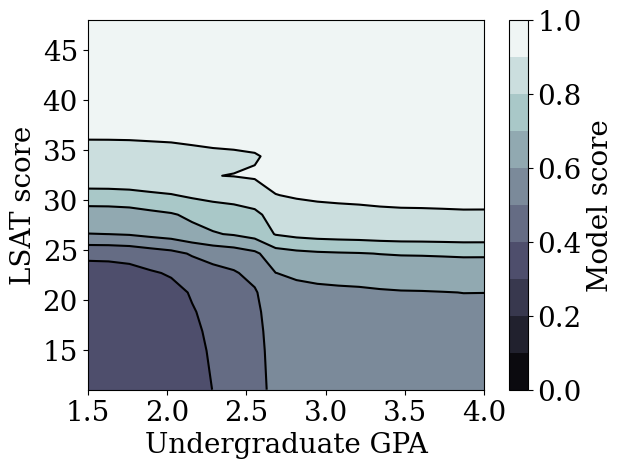
plot_model_contour(nomon_lattice_model, from_logits=True)
13/13 [==============================] - 0s 1ms/step
训练单调校准晶格模型
我们可以通过在特征配置中设置单调性约束来获得单调模型。
model_config.feature_configs[0].monotonicity = 1
model_config.feature_configs[1].monotonicity = 1
mon_lattice_model = tfl.premade.CalibratedLattice(model_config=model_config)
mon_lattice_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
keras.metrics.BinaryAccuracy(name='accuracy'),
],
optimizer=keras.optimizers.Adam(LEARNING_RATES),
)
mon_lattice_model.fit(datasets['law_train'], epochs=NUM_EPOCHS, verbose=0)
train_acc = mon_lattice_model.evaluate(datasets['law_train'])[1]
val_acc = mon_lattice_model.evaluate(datasets['law_val'])[1]
test_acc = mon_lattice_model.evaluate(datasets['law_test'])[1]
print(
'accuracies for train: %f, val: %f, test: %f'
% (train_acc, val_acc, test_acc)
)
63/63 [==============================] - 0s 1ms/step - loss: 0.1712 - accuracy: 0.9463 10/10 [==============================] - 0s 2ms/step - loss: 0.1869 - accuracy: 0.9403 18/18 [==============================] - 0s 2ms/step - loss: 0.1654 - accuracy: 0.9487 accuracies for train: 0.946308, val: 0.940292, test: 0.948684
plot_model_contour(mon_lattice_model, from_logits=True)
13/13 [==============================] - 0s 1ms/step
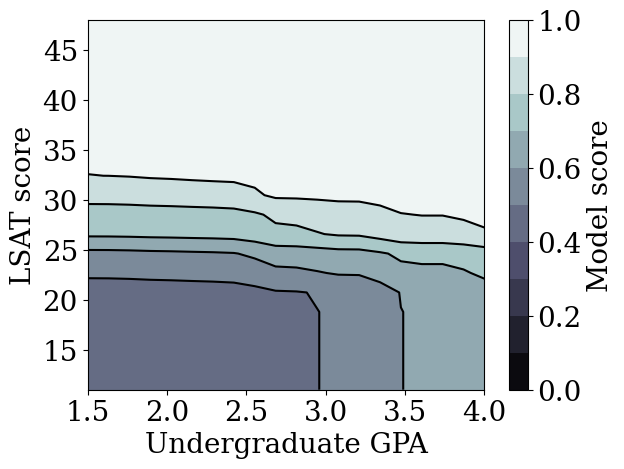
我们证明了 TFL 校准晶格模型可以在 LSAT 分数和 GPA 中训练为单调,而准确性不会有太大牺牲。
训练其他不受约束的模型
校准晶格模型与其他类型的模型(如深度神经网络 (DNN) 或梯度提升树 (GBT))相比如何?DNN 和 GBT 是否似乎具有相当公平的输出?为了解决这个问题,我们接下来将训练一个不受约束的 DNN 和 GBT。事实上,我们会观察到 DNN 和 GBT 都很容易违反 LSAT 分数和本科 GPA 中的单调性。
训练不受约束的深度神经网络 (DNN) 模型
该架构经过优化,以实现较高的验证准确性。
keras.utils.set_random_seed(42)
inputs = [
keras.Input(shape=(1,), dtype=tf.float32),
keras.Input(shape=(1), dtype=tf.float32),
]
inputs_flat = keras.layers.Concatenate()(inputs)
dense_layers = keras.Sequential(
[
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(1, activation=None),
],
name='dense_layers',
)
dnn_model = keras.Model(inputs=inputs, outputs=dense_layers(inputs_flat))
dnn_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy(name='accuracy')],
optimizer=keras.optimizers.Adam(LEARNING_RATES),
)
dnn_model.fit(datasets['law_train'], epochs=NUM_EPOCHS, verbose=0)
train_acc = dnn_model.evaluate(datasets['law_train'])[1]
val_acc = dnn_model.evaluate(datasets['law_val'])[1]
test_acc = dnn_model.evaluate(datasets['law_test'])[1]
print(
'accuracies for train: %f, val: %f, test: %f'
% (train_acc, val_acc, test_acc)
)
63/63 [==============================] - 0s 1ms/step - loss: 0.1729 - accuracy: 0.9482 10/10 [==============================] - 0s 2ms/step - loss: 0.1846 - accuracy: 0.9424 18/18 [==============================] - 0s 1ms/step - loss: 0.1658 - accuracy: 0.9505 accuracies for train: 0.948248, val: 0.942440, test: 0.950453
plot_model_contour(dnn_model, from_logits=True)
13/13 [==============================] - 0s 1ms/step
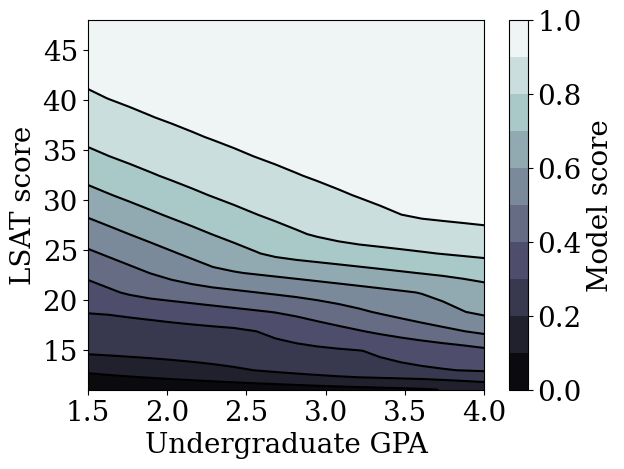
训练不受约束的梯度提升树 (GBT) 模型
树结构以前经过优化,以实现较高的验证准确率。
tree_model = tfdf.keras.GradientBoostedTreesModel(
exclude_non_specified_features=False,
num_threads=1,
num_trees=20,
max_depth=4,
growing_strategy='BEST_FIRST_GLOBAL',
random_seed=42,
temp_directory=tempfile.mkdtemp(),
)
tree_model.compile(metrics=[keras.metrics.BinaryAccuracy(name='accuracy')])
tree_model.fit(
datasets['law_train'], validation_data=datasets['law_val'], verbose=0
)
tree_train_acc = tree_model.evaluate(datasets['law_train'], verbose=0)[1]
tree_val_acc = tree_model.evaluate(datasets['law_val'], verbose=0)[1]
tree_test_acc = tree_model.evaluate(datasets['law_test'], verbose=0)[1]
print(
'accuracies for GBT: train: %f, val: %f, test: %f'
% (tree_train_acc, tree_val_acc, tree_test_acc)
)
[WARNING 24-03-27 11:22:52.3549 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS". [WARNING 24-03-27 11:22:52.3550 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS". [WARNING 24-03-27 11:22:52.3550 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB". Num validation examples: tf.Tensor(2328, shape=(), dtype=int32) [INFO 24-03-27 11:22:56.7210 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpl7y3whz4/model/ with prefix 9539d0c1bde64ba3 [INFO 24-03-27 11:22:56.7229 UTC quick_scorer_extended.cc:911] The binary was compiled without AVX2 support, but your CPU supports it. Enable it for faster model inference. [INFO 24-03-27 11:22:56.7230 UTC abstract_model.cc:1344] Engine "GradientBoostedTreesQuickScorerExtended" built [INFO 24-03-27 11:22:56.7230 UTC kernel.cc:1061] Use fast generic engine accuracies for GBT: train: 0.949625, val: 0.948024, test: 0.951559
plot_model_contour(tree_model)
13/13 [==============================] - 0s 1ms/step
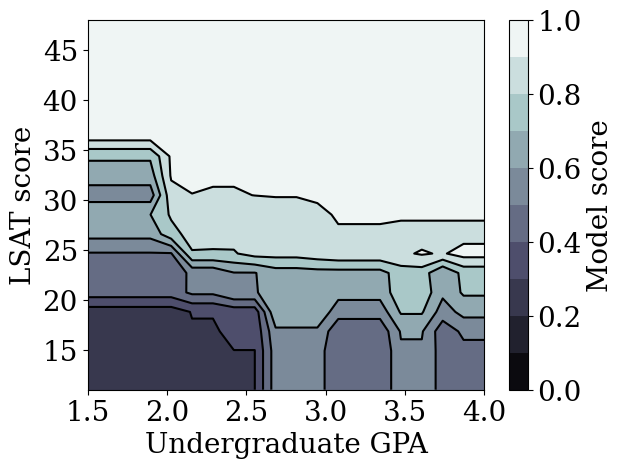
案例研究 #2:信用违约
本教程中将考虑的第二个案例研究是预测个人的信用违约概率。我们将使用 UCI 存储库中的信用卡客户违约数据集。该数据收集自 30,000 名台湾信用卡用户,包含用户在时间窗口内是否违约付款的二进制标签。特征包括婚姻状况、性别、教育程度,以及用户在 2005 年 4 月至 9 月期间每个月拖欠现有账单的时间长度。
与第一个案例研究一样,我们再次说明使用单调性约束来避免不公平的惩罚:如果模型用于确定用户的信用评分,那么如果用户因提前支付账单而受到惩罚,则许多人可能会觉得不公平,其他条件相同。因此,我们应用单调性约束,防止模型惩罚提前还款。
加载信用违约数据
# Load data file.
credit_file_name = 'credit_default.csv'
credit_file_path = os.path.join(DATA_DIR, credit_file_name)
credit_df = pd.read_csv(credit_file_path, delimiter=',')
# Define label column name.
CREDIT_LABEL = 'default'
将数据拆分为训练/验证/测试集
dfs = {}
datasets = {}
dfs["credit_train"], dfs["credit_val"], dfs["credit_test"] = split_dataset(
credit_df
)
for df_name, df in dfs.items():
datasets[df_name] = tf.data.Dataset.from_tensor_slices(
((df[['MARRIAGE']], df[['PAY_0']]), df[['default']])
).batch(BATCH_SIZE)
可视化数据分布
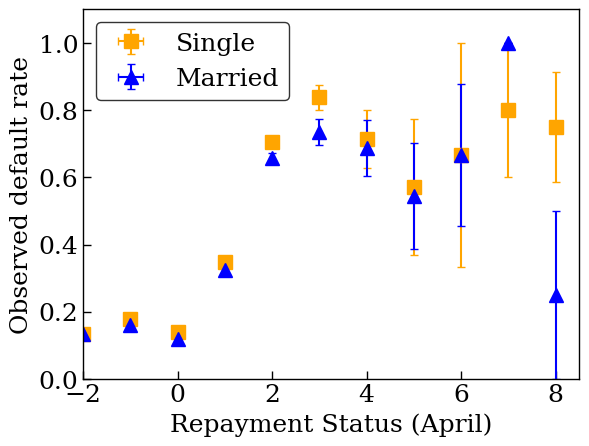
首先,我们将可视化数据的分布。我们将绘制具有不同婚姻状况和还款状况的人的观察违约率的平均值和标准误差。还款状态表示一个人拖欠还款的月份数(截至 2005 年 4 月)。
def get_agg_data(df, x_col, y_col, bins=11):
xbins = pd.cut(df[x_col], bins=bins)
data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem'])
return data
def plot_2d_means_credit(input_df, x_col, y_col, x_label, y_label):
plt.rcParams['font.family'] = ['serif']
_, ax = plt.subplots(nrows=1, ncols=1)
plt.setp(ax.spines.values(), color='black', linewidth=1)
ax.tick_params(
direction='in', length=6, width=1, top=False, right=False, labelsize=18)
df_single = get_agg_data(input_df[input_df['MARRIAGE'] == 1], x_col, y_col)
df_married = get_agg_data(input_df[input_df['MARRIAGE'] == 2], x_col, y_col)
ax.errorbar(
df_single[(x_col, 'mean')],
df_single[(y_col, 'mean')],
xerr=df_single[(x_col, 'sem')],
yerr=df_single[(y_col, 'sem')],
color='orange',
marker='s',
capsize=3,
capthick=1,
label='Single',
markersize=10,
linestyle='')
ax.errorbar(
df_married[(x_col, 'mean')],
df_married[(y_col, 'mean')],
xerr=df_married[(x_col, 'sem')],
yerr=df_married[(y_col, 'sem')],
color='b',
marker='^',
capsize=3,
capthick=1,
label='Married',
markersize=10,
linestyle='')
leg = ax.legend(loc='upper left', fontsize=18, frameon=True, numpoints=1)
ax.set_xlabel(x_label, fontsize=18)
ax.set_ylabel(y_label, fontsize=18)
ax.set_ylim(0, 1.1)
ax.set_xlim(-2, 8.5)
ax.patch.set_facecolor('white')
leg.get_frame().set_edgecolor('black')
leg.get_frame().set_facecolor('white')
leg.get_frame().set_linewidth(1)
plt.show()
plot_2d_means_credit(
dfs['credit_train'],
'PAY_0',
'default',
'Repayment Status (April)',
'Observed default rate',
)
/tmpfs/tmp/ipykernel_10210/4037607942.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning. data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem']) /tmpfs/tmp/ipykernel_10210/4037607942.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning. data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem'])
训练校准的晶格模型来预测信用违约率
接下来,我们将从 TFL 训练一个校准的晶格模型,以预测一个人是否会违约贷款。两个输入特征将是该人的婚姻状况以及该人在 4 月份拖欠还款的月份数(还款状态)。训练标签将是该人是否违约贷款。
我们首先将训练一个没有任何约束的校准晶格模型。然后,我们将训练一个具有单调性约束的校准晶格模型,并观察模型输出和准确性的差异。
用于可视化训练模型输出的辅助函数
def plot_predictions_credit(
input_df,
model,
x_col,
x_label='Repayment Status (April)',
y_label='Predicted default probability',
):
predictions = model.predict((input_df[['MARRIAGE']], input_df[['PAY_0']]))
predictions = tf.math.sigmoid(predictions)
new_df = input_df.copy()
new_df.loc[:, 'predictions'] = predictions
plot_2d_means_credit(new_df, x_col, 'predictions', x_label, y_label)
训练不受约束(非单调)的校准晶格模型
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name='MARRIAGE',
lattice_size=3,
pwl_calibration_num_keypoints=2,
monotonicity=0,
pwl_calibration_always_monotonic=False,
),
tfl.configs.FeatureConfig(
name='PAY_0',
lattice_size=3,
pwl_calibration_num_keypoints=16,
monotonicity=0,
pwl_calibration_always_monotonic=False,
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=8),
)
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=model_config.feature_configs,
features=dfs["credit_train"][['MARRIAGE', 'PAY_0', 'default']],
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
nomon_lattice_model = tfl.premade.CalibratedLattice(model_config=model_config)
nomon_lattice_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
keras.metrics.BinaryAccuracy(name='accuracy'),
],
optimizer=keras.optimizers.Adam(LEARNING_RATES),
)
nomon_lattice_model.fit(datasets['credit_train'], epochs=NUM_EPOCHS, verbose=0)
train_acc = nomon_lattice_model.evaluate(datasets['credit_train'])[1]
val_acc = nomon_lattice_model.evaluate(datasets['credit_val'])[1]
test_acc = nomon_lattice_model.evaluate(datasets['credit_test'])[1]
print(
'accuracies for train: %f, val: %f, test: %f'
% (train_acc, val_acc, test_acc)
)
83/83 [==============================] - 0s 1ms/step - loss: 0.4537 - accuracy: 0.8186 12/12 [==============================] - 0s 2ms/step - loss: 0.4423 - accuracy: 0.8291 24/24 [==============================] - 0s 1ms/step - loss: 0.4547 - accuracy: 0.8168 accuracies for train: 0.818619, val: 0.829085, test: 0.816835
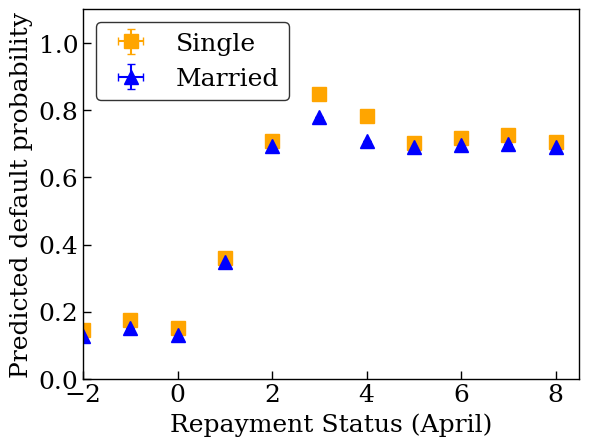
plot_predictions_credit(dfs['credit_train'], nomon_lattice_model, 'PAY_0')
657/657 [==============================] - 1s 1ms/step /tmpfs/tmp/ipykernel_10210/4037607942.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning. data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem']) /tmpfs/tmp/ipykernel_10210/4037607942.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning. data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem'])
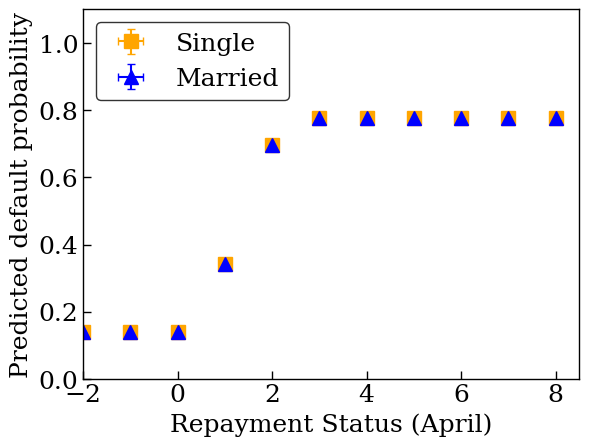
训练单调校准晶格模型
model_config.feature_configs[0].monotonicity = 1
model_config.feature_configs[1].monotonicity = 1
mon_lattice_model = tfl.premade.CalibratedLattice(model_config=model_config)
mon_lattice_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
keras.metrics.BinaryAccuracy(name='accuracy'),
],
optimizer=keras.optimizers.Adam(LEARNING_RATES),
)
mon_lattice_model.fit(datasets['credit_train'], epochs=NUM_EPOCHS, verbose=0)
train_acc = mon_lattice_model.evaluate(datasets['credit_train'])[1]
val_acc = mon_lattice_model.evaluate(datasets['credit_val'])[1]
test_acc = mon_lattice_model.evaluate(datasets['credit_test'])[1]
print(
'accuracies for train: %f, val: %f, test: %f'
% (train_acc, val_acc, test_acc)
)
83/83 [==============================] - 0s 1ms/step - loss: 0.4548 - accuracy: 0.8188 12/12 [==============================] - 0s 2ms/step - loss: 0.4426 - accuracy: 0.8301 24/24 [==============================] - 0s 1ms/step - loss: 0.4551 - accuracy: 0.8172 accuracies for train: 0.818762, val: 0.830065, test: 0.817172
plot_predictions_credit(dfs['credit_train'], mon_lattice_model, 'PAY_0')
657/657 [==============================] - 1s 1ms/step /tmpfs/tmp/ipykernel_10210/4037607942.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning. data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem']) /tmpfs/tmp/ipykernel_10210/4037607942.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning. data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem'])