|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概述
本教程概述了 TensorFlow Lattice (TFL) 库提供的约束和正则化器。在这里,我们在合成数据集上使用 TFL 预制模型,但请注意,本教程中的所有内容也可以使用由 TFL Keras 层构建的模型来完成。
在继续之前,请确保您的运行时已安装所有必需的软件包(如以下代码单元中导入的软件包)。
设置
安装 TF Lattice 包
pip install --pre -U tensorflow tf-keras tensorflow-lattice tensorflow_decision_forests pydot graphviz
导入必需的软件包
import tensorflow as tf
import tensorflow_lattice as tfl
import tensorflow_decision_forests as tfdf
from IPython.core.pylabtools import figsize
import functools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tempfile
logging.disable(sys.maxsize)
# Use Keras 2.
version_fn = getattr(tf.keras, "version", None)
if version_fn and version_fn().startswith("3."):
import tf_keras as keras
else:
keras = tf.keras
本指南中使用的默认值
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
用于对餐厅进行排名的训练数据集
想象一个简化的场景,我们想要确定用户是否会点击餐厅搜索结果。任务是在给定输入特征的情况下预测点击率 (CTR)。
- 平均评分 (
avg_rating):数值特征,其值范围为 [1,5]。 - 评论数量 (
num_reviews):数值特征,其值上限为 200,我们将其用作趋势的衡量标准。 - 美元评分 (
dollar_rating):分类特征,其字符串值在集合 {"D", "DD", "DDD", "DDDD"} 中。
在这里,我们创建一个合成数据集,其中真实的 CTR 由以下公式给出
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
其中 \(b(\cdot)\) 将每个 dollar_rating 转换为基线值
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
此公式反映了典型的用户模式。例如,在其他条件相同的情况下,用户更喜欢星级更高的餐厅,而“$$”餐厅的点击率将高于“$”,其次是“$$$”和“$$$$”。
dollar_ratings_vocab = ["D", "DD", "DDD", "DDDD"]
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
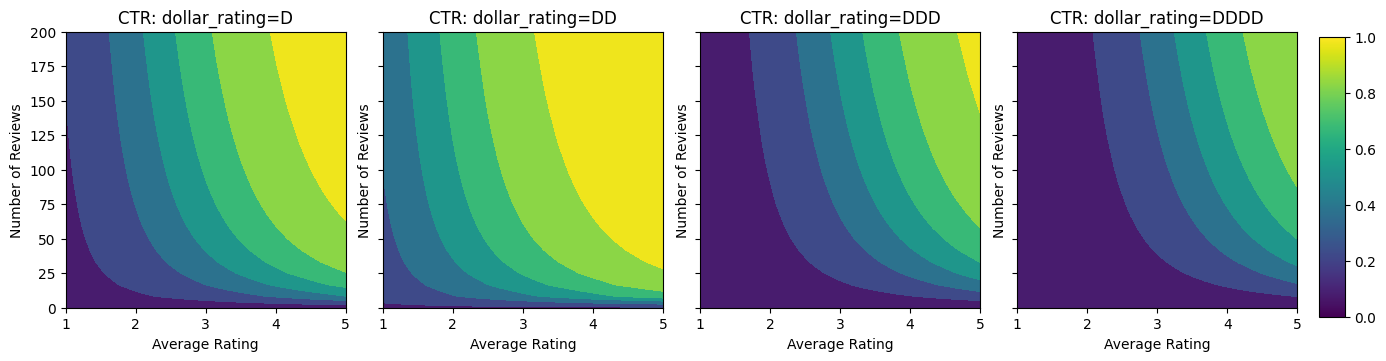
让我们看一下此 CTR 函数的等高线图。
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
figsize(13, 3.5 * len(fns))
fig, axes = plt.subplots(
len(fns), len(dollar_ratings_vocab), sharey=True, layout="constrained"
)
axes = axes.flatten()
axes_index = 0
for fn_name, fn in fns:
for dollar_rating_split in dollar_ratings_vocab:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(), dollar_ratings)
title = "{}: dollar_rating={}".format(fn_name, dollar_rating_split)
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1,
)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
if len(fns) <= 2:
cax = fig.add_axes([
axes[-1].get_position().x1 + 0.11,
axes[-1].get_position().y0,
0.02,
0.8,
])
_ = fig.colorbar(color_bar(), cax=cax)
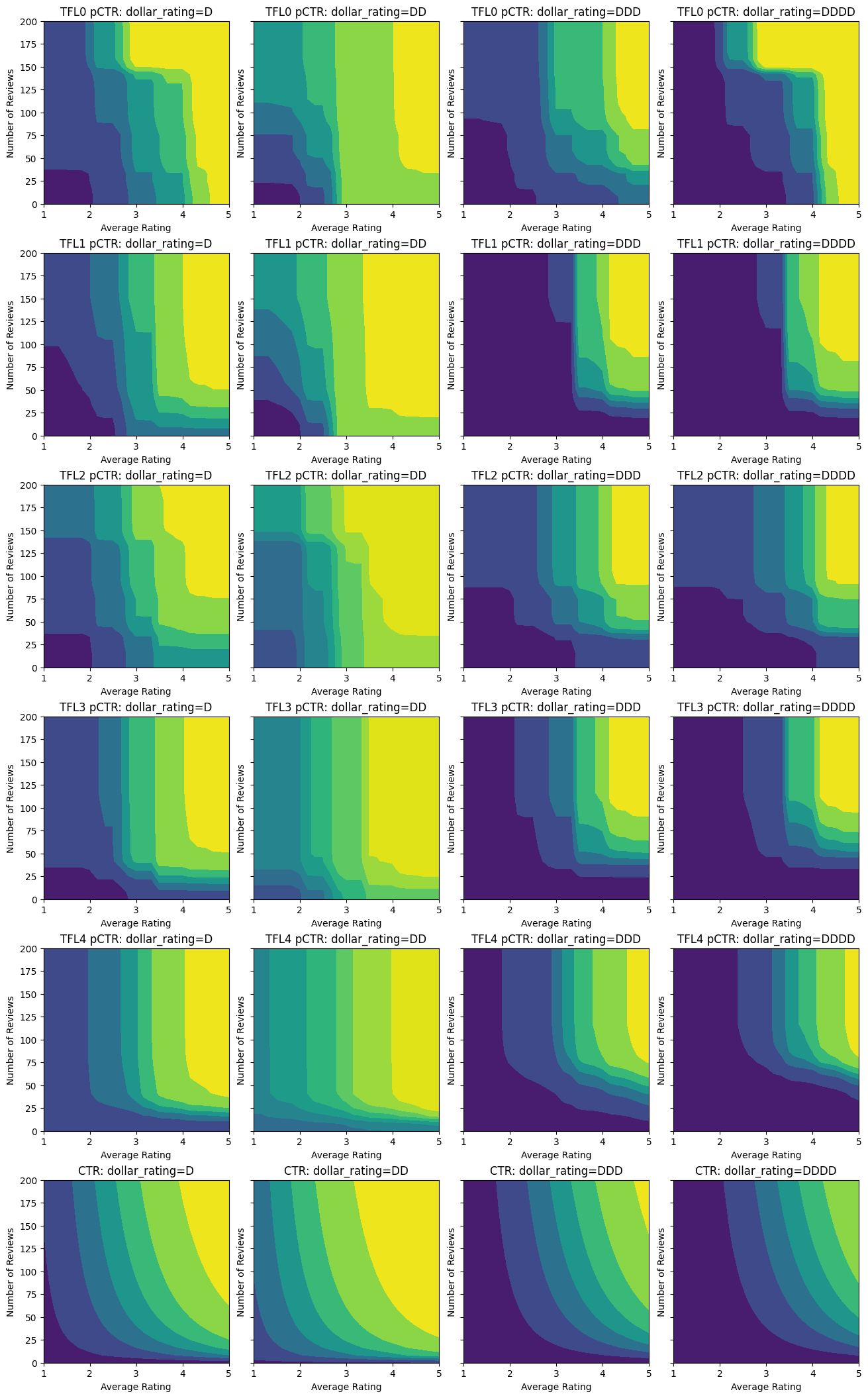
plot_fns([("CTR", click_through_rate)])
准备数据
现在我们需要创建我们的合成数据集。我们首先生成一个模拟的餐厅及其特征数据集。
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(dollar_ratings_vocab, n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
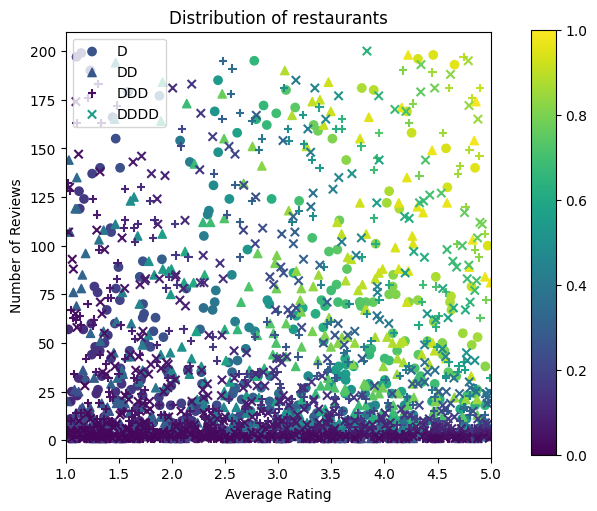
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, layout="constrained")
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([1.05, 0.1, 0.05, 0.85]))
让我们生成训练、验证和测试数据集。当餐厅在搜索结果中被查看时,我们可以记录用户的参与度(点击或不点击)作为样本点。
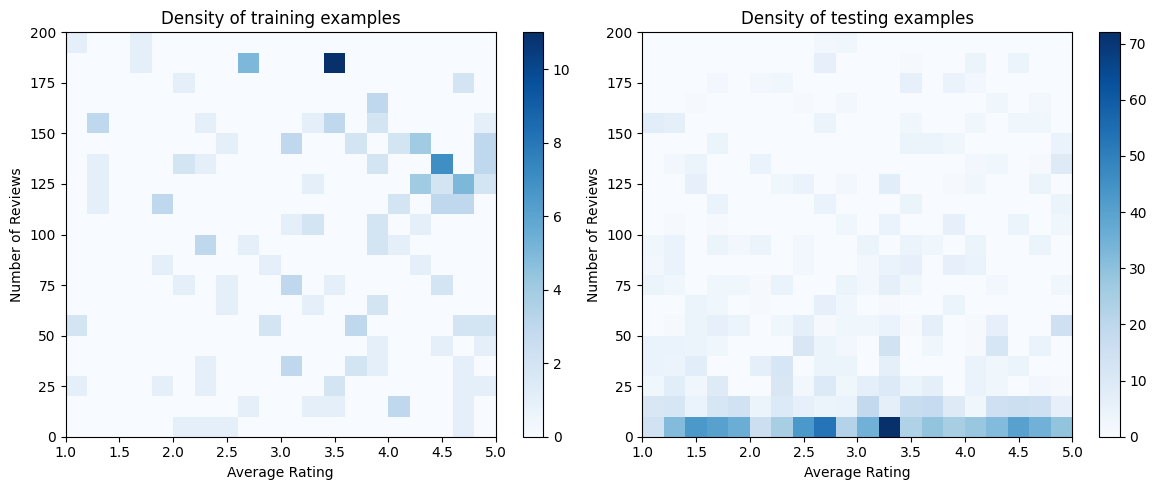
在实践中,用户通常不会浏览所有搜索结果。这意味着用户可能只会看到当前使用的排名模型认为“好”的餐厅。因此,“好”的餐厅更容易被留下深刻印象,并且在训练数据集中过度表示。当使用更多特征时,训练数据集在特征空间的“坏”部分可能存在较大差距。
当模型用于排名时,它通常在所有相关结果上进行评估,这些结果具有更均匀的分布,而训练数据集无法很好地表示这种分布。灵活且复杂的模型可能会在这种情况下失败,因为它过度拟合了过度表示的数据点,因此缺乏泛化能力。我们通过应用领域知识来添加形状约束来解决此问题,这些约束引导模型在无法从训练数据集中获取预测时做出合理的预测。
在本例中,训练数据集主要包含用户与良好且受欢迎的餐厅的互动。测试数据集具有均匀分布,以模拟上面讨论的评估设置。请注意,这种测试数据集在实际问题设置中将不可用。
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views)),
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
ds_train = tfdf.keras.pd_dataframe_to_tf_dataset(
data_train, label="clicked", batch_size=BATCH_SIZE
)
ds_val = tfdf.keras.pd_dataframe_to_tf_dataset(
data_val, label="clicked", batch_size=BATCH_SIZE
)
ds_test = tfdf.keras.pd_dataframe_to_tf_dataset(
data_test, label="clicked", batch_size=BATCH_SIZE
)
# feature_analysis_data is used to find quantiles of featurse.
feature_analysis_data = data_train.copy()
feature_analysis_data["dollar_rating"] = feature_analysis_data[
"dollar_rating"
].map({v: i for i, v in enumerate(dollar_ratings_vocab)})
feature_analysis_data = dict(feature_analysis_data)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [
(axs[0], data_train, "training"),
(axs[1], data_test, "testing"),
]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
2024-03-23 11:20:52.020222: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:282] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
拟合梯度提升树
我们首先创建一些用于绘制和计算验证和测试指标的辅助函数。
def pred_fn(model, from_logits, avg_ratings, num_reviews, dollar_rating):
preds = model.predict(
tf.data.Dataset.from_tensor_slices({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}).batch(1),
verbose=0,
)
if from_logits:
preds = tf.math.sigmoid(preds)
return preds
def analyze_model(models, from_logits=False, print_metrics=True):
pred_fns = []
for model, name in models:
if print_metrics:
metric = model.evaluate(ds_val, return_dict=True, verbose=0)
print("Validation AUC: {}".format(metric["auc"]))
metric = model.evaluate(ds_test, return_dict=True, verbose=0)
print("Testing AUC: {}".format(metric["auc"]))
pred_fns.append(
("{} pCTR".format(name), functools.partial(pred_fn, model, from_logits))
)
pred_fns.append(("CTR", click_through_rate))
plot_fns(pred_fns)
我们可以将 TensorFlow 梯度提升决策树拟合到数据集上
gbt_model = tfdf.keras.GradientBoostedTreesModel(
features=[
tfdf.keras.FeatureUsage(name="num_reviews"),
tfdf.keras.FeatureUsage(name="avg_rating"),
tfdf.keras.FeatureUsage(name="dollar_rating"),
],
exclude_non_specified_features=True,
num_threads=1,
num_trees=32,
max_depth=6,
min_examples=10,
growing_strategy="BEST_FIRST_GLOBAL",
random_seed=42,
temp_directory=tempfile.mkdtemp(),
)
gbt_model.compile(metrics=[keras.metrics.AUC(name="auc")])
gbt_model.fit(ds_train, validation_data=ds_val, verbose=0)
analyze_model([(gbt_model, "GBT")])
[WARNING 24-03-23 11:20:53.0848 UTC gradient_boosted_trees.cc:1840] "goss_alpha" set but "sampling_method" not equal to "GOSS". [WARNING 24-03-23 11:20:53.0849 UTC gradient_boosted_trees.cc:1851] "goss_beta" set but "sampling_method" not equal to "GOSS". [WARNING 24-03-23 11:20:53.0849 UTC gradient_boosted_trees.cc:1865] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB". Num validation examples: tf.Tensor(155, shape=(), dtype=int32) [INFO 24-03-23 11:20:56.9615 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpr9581nmh/model/ with prefix 2d8654c85f474a4e [INFO 24-03-23 11:20:56.9631 UTC quick_scorer_extended.cc:911] The binary was compiled without AVX2 support, but your CPU supports it. Enable it for faster model inference. [INFO 24-03-23 11:20:56.9632 UTC abstract_model.cc:1344] Engine "GradientBoostedTreesQuickScorerExtended" built [INFO 24-03-23 11:20:56.9632 UTC kernel.cc:1061] Use fast generic engine Validation AUC: 0.7145258188247681 Testing AUC: 0.8356180191040039
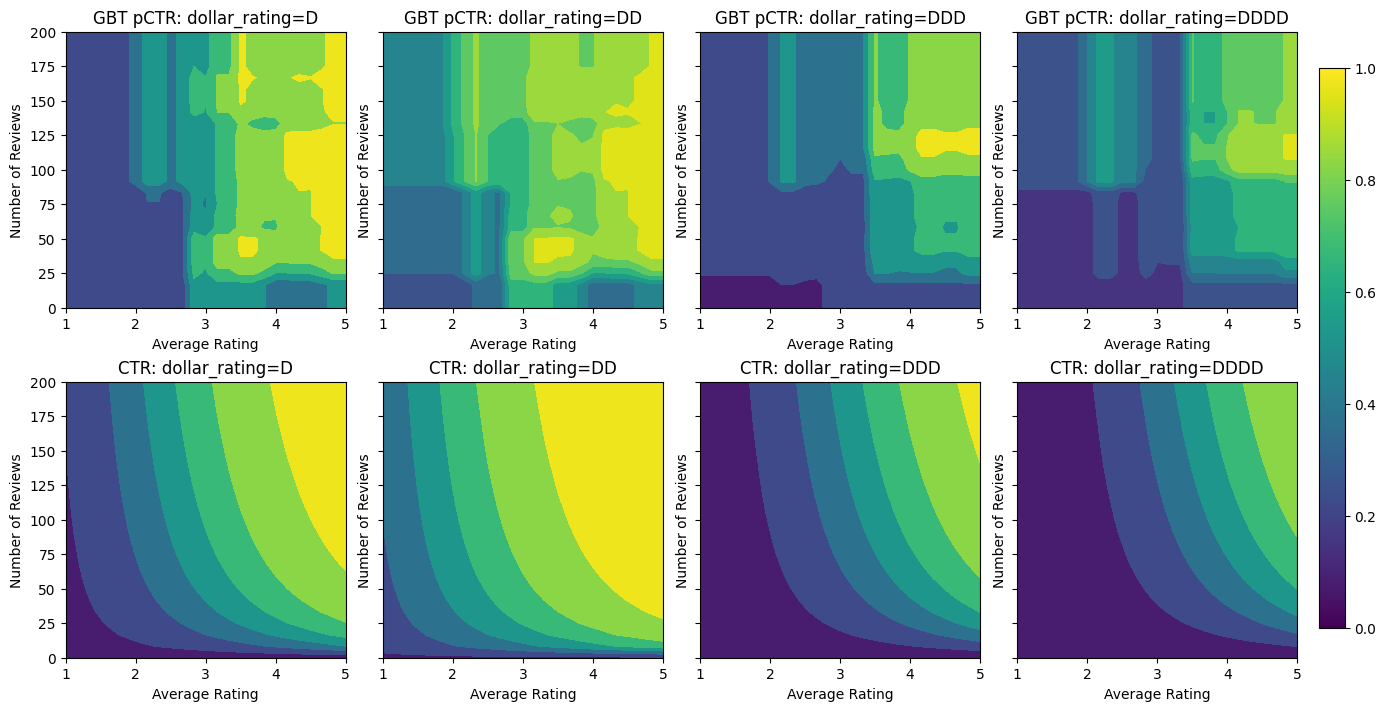
即使模型已经捕获了真实 CTR 的总体形状,并且具有不错的验证指标,但在输入空间的几个部分,它仍然表现出违反直觉的行为:估计的 CTR 随着平均评分或评论数量的增加而下降。这是由于训练数据集未涵盖的区域缺乏样本点。模型仅仅无法从数据中推断出正确的行为。
为了解决此问题,我们强制执行形状约束,即模型必须输出相对于平均评分和评论数量单调递增的值。我们将在后面看到如何在 TFL 中实现这一点。
拟合 DNN
我们可以使用 DNN 分类器重复相同的步骤。我们可以观察到类似的模式:没有足够的样本点,评论数量很少,会导致毫无意义的推断。
keras.utils.set_random_seed(42)
inputs = {
"num_reviews": keras.Input(shape=(1,), dtype=tf.float32),
"avg_rating": keras.Input(shape=(1), dtype=tf.float32),
"dollar_rating": keras.Input(shape=(1), dtype=tf.string),
}
inputs_flat = keras.layers.Concatenate()([
inputs["num_reviews"],
inputs["avg_rating"],
keras.layers.StringLookup(
vocabulary=dollar_ratings_vocab,
num_oov_indices=0,
output_mode="one_hot",
)(inputs["dollar_rating"]),
])
dense_layers = keras.Sequential(
[
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(1, activation=None),
],
name="dense_layers",
)
dnn_model = keras.Model(inputs=inputs, outputs=dense_layers(inputs_flat))
keras.utils.plot_model(
dnn_model, expand_nested=True, show_layer_names=False, rankdir="LR"
)

dnn_model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
dnn_model.fit(ds_train, epochs=200, verbose=0)
analyze_model([(dnn_model, "DNN")], from_logits=True)
Validation AUC: 0.7568147778511047 Testing AUC: 0.8183510899543762
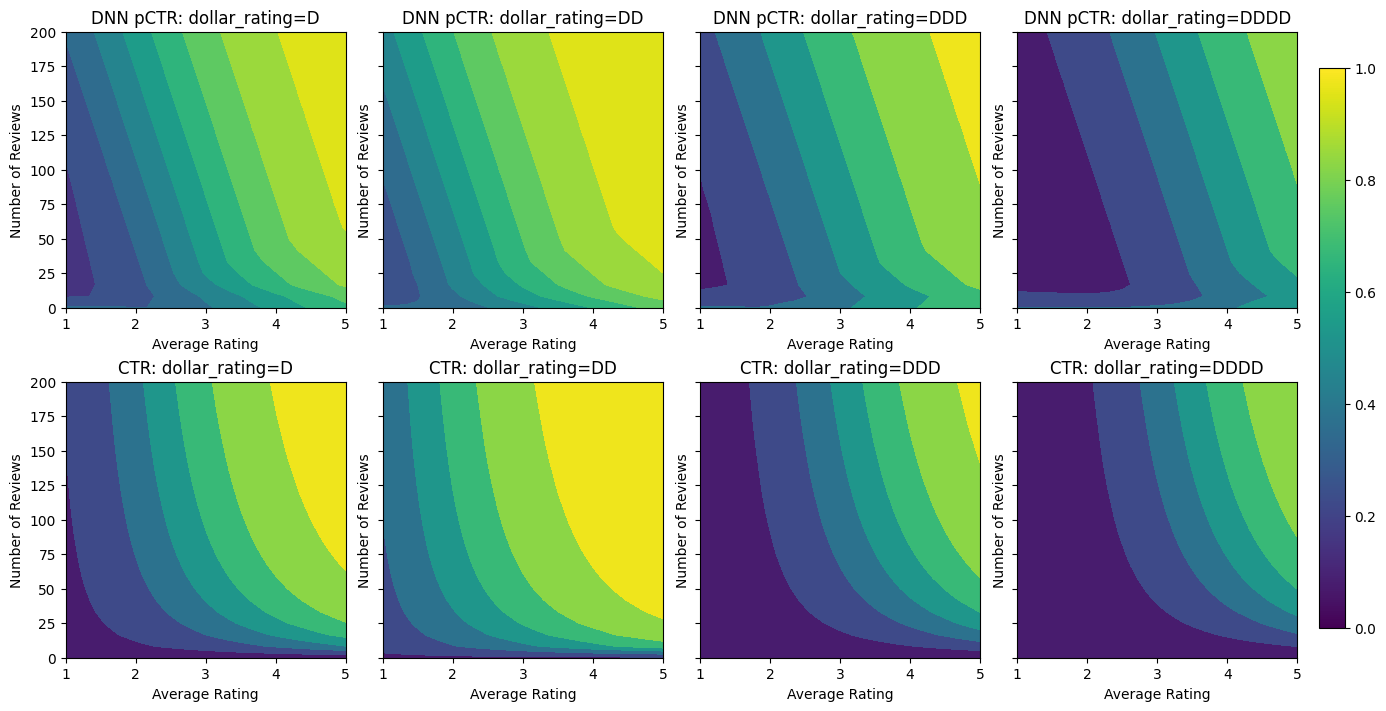
形状约束
TensorFlow Lattice (TFL) 专注于强制执行形状约束,以保护训练数据之外的模型行为。这些形状约束应用于 TFL Keras 层。有关详细信息,请参阅我们的 JMLR 论文。
在本教程中,我们使用 TF 预制模型来涵盖各种形状约束,但请注意,所有这些步骤都可以使用由 TFL Keras 层创建的模型来完成。
使用 TFL 预制模型还需要
- 模型配置:定义模型架构以及每个特征的形状约束和正则化器。
- 特征分析数据集:用于 TFL 初始化(特征分位数计算)的数据集。
有关更详细的说明,请参阅预制模型或 API 文档。
单调性
我们首先通过向连续特征添加单调性形状约束来解决单调性问题。我们使用经过校准的格模型,并添加了输出校准:每个特征使用分类或分段线性校准器进行校准,然后馈送到格模型,最后经过输出分段线性校准器。
为了指示 TFL 强制执行形状约束,我们在特征配置中指定约束。以下代码显示了如何通过设置 monotonicity="increasing" 来要求输出相对于 num_reviews 和 avg_rating 单调递增。
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
现在,我们使用 feature_analysis_data 来查找并设置输入特征的分位数值。这些值可以根据训练管道预先计算并显式设置在特征配置中。
feature_analysis_data = data_train.copy()
feature_analysis_data["dollar_rating"] = feature_analysis_data[
"dollar_rating"
].map({v: i for i, v in enumerate(dollar_ratings_vocab)})
feature_analysis_data = dict(feature_analysis_data)
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=model_config.feature_configs, features=feature_analysis_data
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
keras.utils.set_random_seed(42)
inputs = {
"num_reviews": keras.Input(shape=(1,), dtype=tf.float32),
"avg_rating": keras.Input(shape=(1), dtype=tf.float32),
"dollar_rating": keras.Input(shape=(1), dtype=tf.string),
}
ordered_inputs = [
inputs["num_reviews"],
inputs["avg_rating"],
keras.layers.StringLookup(
vocabulary=dollar_ratings_vocab,
num_oov_indices=0,
output_mode="int",
)(inputs["dollar_rating"]),
]
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_0 = keras.Model(inputs=inputs, outputs=outputs)
keras.utils.plot_model(
tfl_model_0, expand_nested=True, show_layer_names=False, rankdir="LR"
)
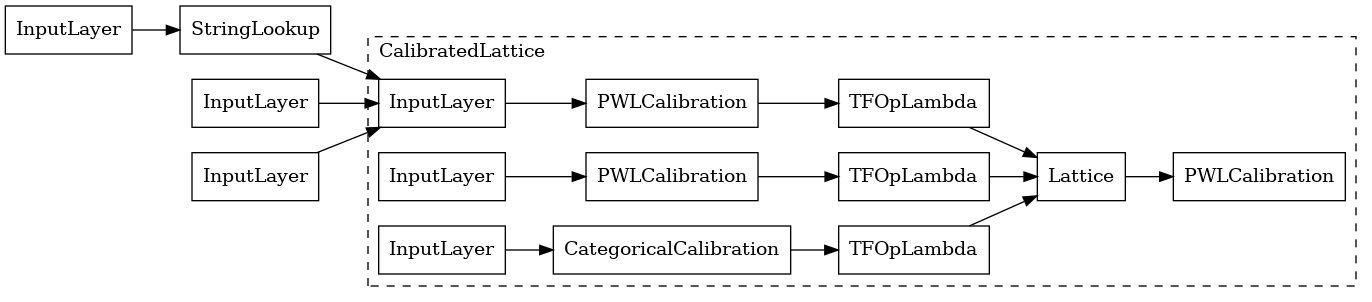
使用 CalibratedLatticeConfig 创建一个预制的分类器,它首先将一个 *校准器* 应用于每个输入(数值特征的分段线性函数),然后将一个 *格点* 层应用于校准后的特征,以非线性方式融合这些特征。我们还启用了输出分段线性校准。
tfl_model_0.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_0.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_0, "TFL0")], from_logits=True)
Validation AUC: 0.7199402451515198 Testing AUC: 0.798313558101654
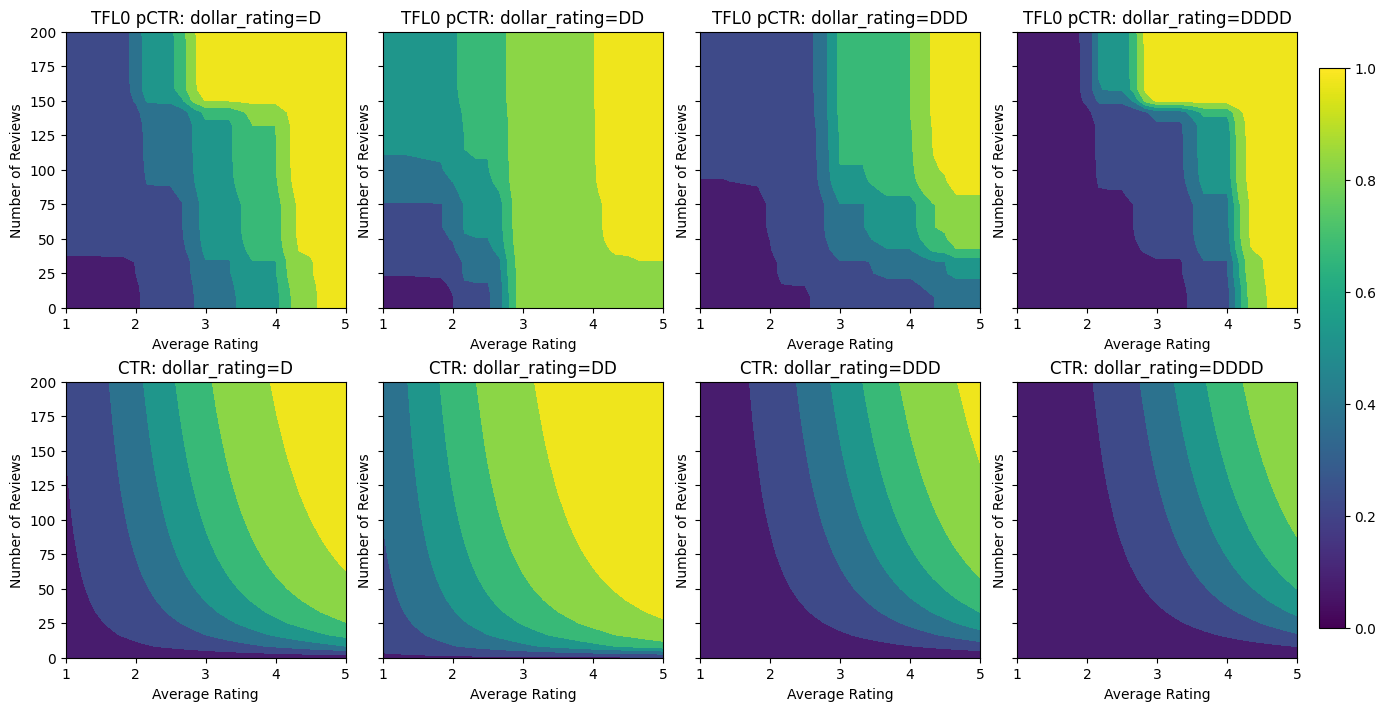
在添加了约束之后,估计的 CTR 将随着平均评分或评论数量的增加而始终增加。这是通过确保校准器和格点是单调的来实现的。
分类校准的部分单调性
要对第三个特征 dollar_rating 使用约束,我们应该记住,分类特征在 TFL 中需要稍微不同的处理。在这里,我们强制执行部分单调性约束,即当所有其他输入固定时,"DD" 餐厅的输出应该大于 "D" 餐厅的输出。这是通过在特征配置中使用 monotonicity 设置来实现的。我们还需要使用 tfl.premade_lib.set_categorical_monotonicities 将字符串值中指定的约束转换为库理解的数值格式。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_1 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_1.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_1.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_1, "TFL1")], from_logits=True)
Validation AUC: 0.741411566734314 Testing AUC: 0.8500608205795288
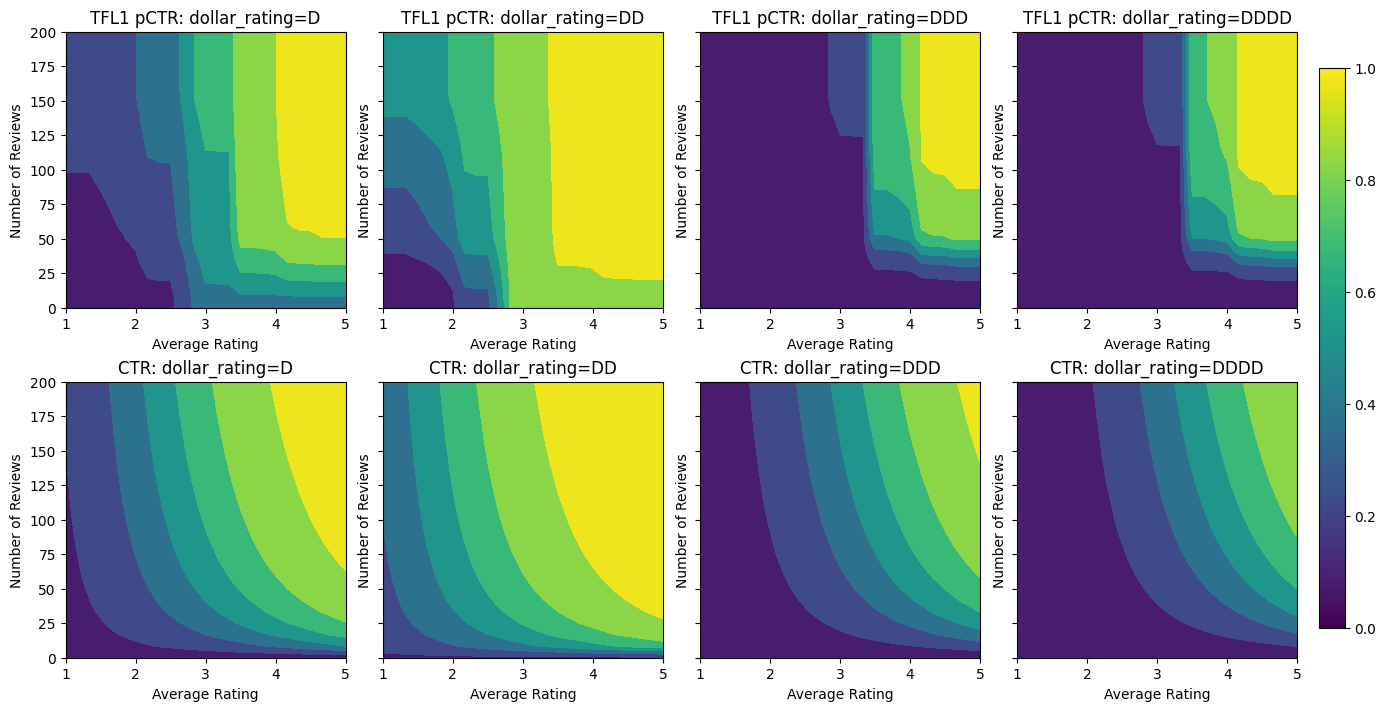
这里我们还绘制了该模型的预测 CTR,该模型以 dollar_rating 为条件。请注意,我们在每个切片中都满足了我们要求的所有约束。
二维形状约束:信任
对于只有一两条评论的餐厅,五星评级可能不可靠(餐厅可能并不真正好),而对于有数百条评论的餐厅,四星评级则可靠得多(在这种情况下,餐厅可能很好)。我们可以看到,餐厅的评论数量会影响我们对平均评分的信任程度。
我们可以使用 TFL 信任约束来告知模型,一个特征的较大(或较小)值表示对另一个特征的更多依赖或信任。这是通过在特征配置中设置 reflects_trust_in 配置来实现的。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"
),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_2 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_2.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_2.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_2, "TFL2")], from_logits=True)
Validation AUC: 0.774645209312439 Testing AUC: 0.8462862372398376
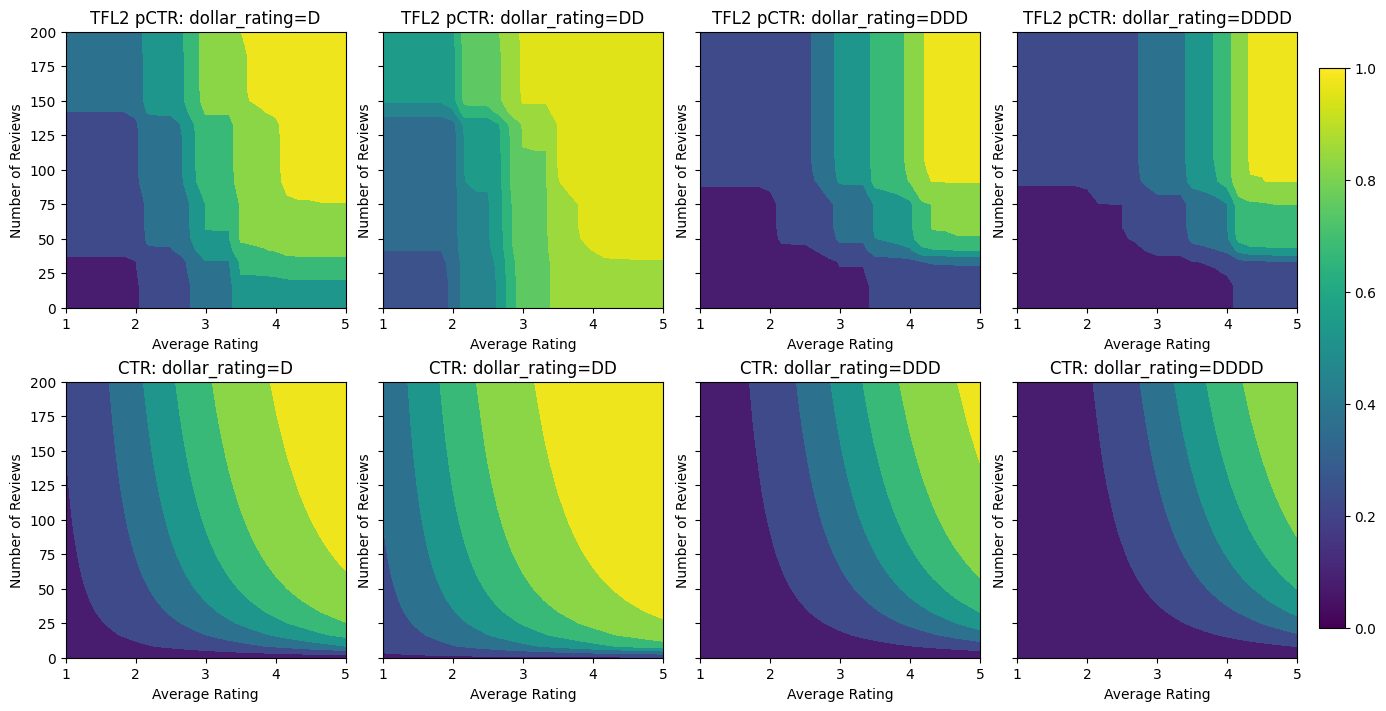
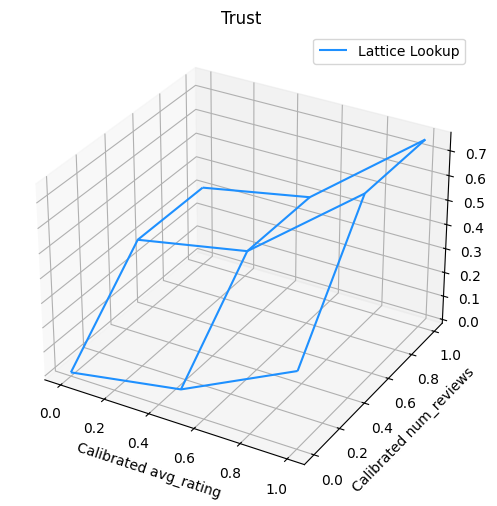
下面的图显示了训练后的格点函数。由于信任约束,我们预计校准后的 num_reviews 的较大值会迫使相对于校准后的 avg_rating 具有更高的斜率,从而导致格点输出发生更显著的变化。
lattice_params = tfl_model_2.layers[-1].layers[-2].weights[0].numpy()
lat_mesh_x, lat_mesh_y = np.meshgrid(
np.linspace(0, 1, num=3),
np.linspace(0, 1, num=3),
)
lat_mesh_z = np.reshape(np.asarray(lattice_params[0::3]), (3, 3))
figure = plt.figure(figsize=(6, 6))
axes = figure.add_subplot(projection="3d")
axes.plot_wireframe(lat_mesh_x, lat_mesh_y, lat_mesh_z, color="dodgerblue")
plt.legend(["Lattice Lookup"])
plt.title("Trust")
plt.xlabel("Calibrated avg_rating")
plt.ylabel("Calibrated num_reviews")
plt.show()
边际收益递减
边际收益递减 意味着,随着我们增加某个特征值的增加,增加该特征值的边际收益将减少。在我们的案例中,我们预计 num_reviews 特征遵循这种模式,因此我们可以相应地配置其校准器。请注意,我们可以将边际收益递减分解为两个充分条件
- 校准器单调递增,并且
- 校准器是凹的(设置
pwl_calibration_convexity="concave")。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=32,
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"
),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_3 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_3.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_3.fit(
ds_train,
epochs=100,
verbose=0
)
analyze_model([(tfl_model_3, "TFL3")], from_logits=True)
Validation AUC: 0.7506535053253174 Testing AUC: 0.8575603365898132
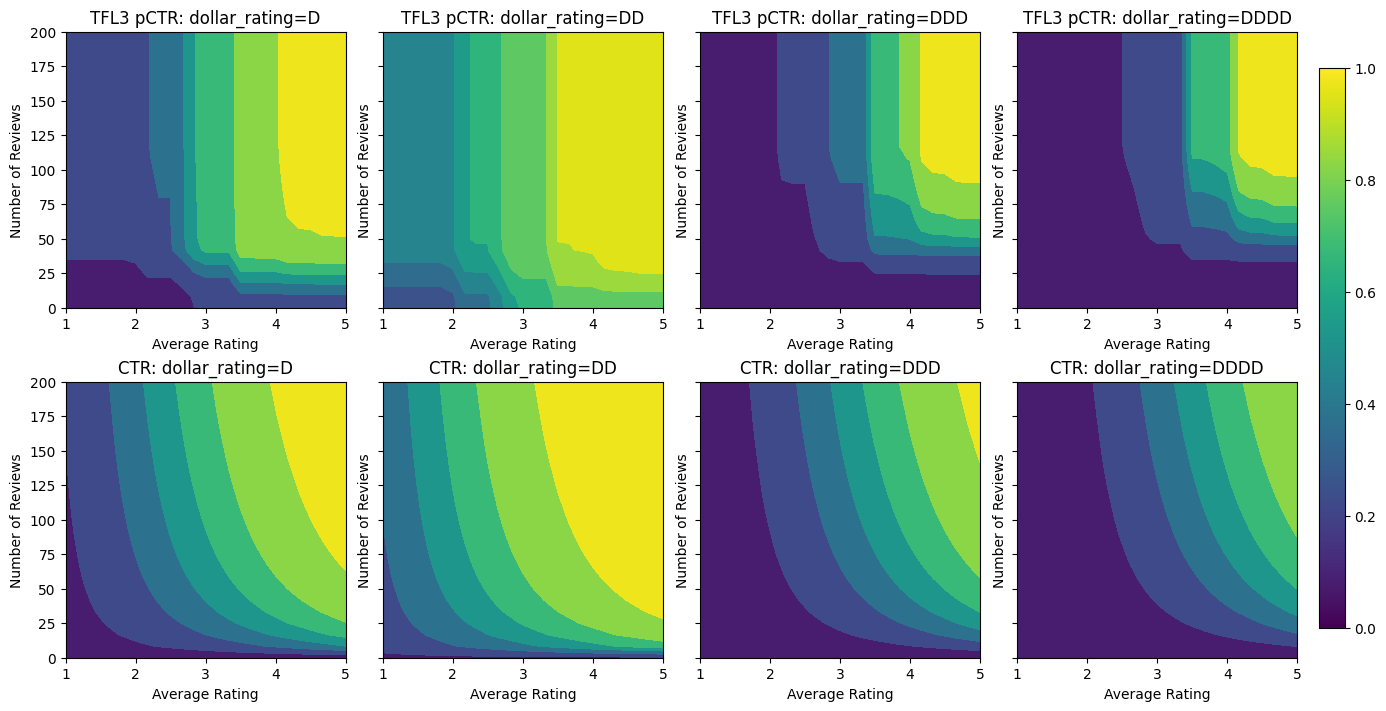
请注意,通过添加凹度约束,测试指标如何得到改善。预测图也更接近于真实值。
平滑校准器
我们在上面的预测曲线中注意到,即使输出在指定的特征中是单调的,但斜率的变化是突然的,难以解释。这表明我们可能需要考虑使用 regularizer_configs 中的正则化器设置来平滑此校准器。
这里我们应用了一个 hessian 正则化器,使校准更加线性。您还可以使用 laplacian 正则化器来平坦校准器,以及使用 wrinkle 正则化器来减少曲率的变化。
keras.utils.set_random_seed(42)
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=32,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_hessian", l2=0.5),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"
),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=3,
monotonicity="increasing",
pwl_calibration_num_keypoints=32,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_hessian", l2=0.5),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=3,
pwl_calibration_num_keypoints=4,
vocabulary_list=dollar_ratings_vocab,
num_buckets=len(dollar_ratings_vocab),
monotonicity=[("D", "DD")],
),
],
output_calibration=True,
output_initialization=np.linspace(-2, 2, num=5),
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_hessian", l2=0.1),
],
)
tfl.premade_lib.set_feature_keypoints(
feature_configs=model_config.feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False,
)
tfl.premade_lib.set_categorical_monotonicities(model_config.feature_configs)
outputs = tfl.premade.CalibratedLattice(
model_config=model_config, name="CalibratedLattice"
)(ordered_inputs)
tfl_model_4 = keras.Model(inputs=inputs, outputs=outputs)
tfl_model_4.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.AUC(from_logits=True, name="auc")],
optimizer=keras.optimizers.Adam(LEARNING_RATE),
)
tfl_model_4.fit(ds_train, epochs=100, verbose=0)
analyze_model([(tfl_model_4, "TFL4")], from_logits=True)
Validation AUC: 0.7562546730041504 Testing AUC: 0.8593733310699463
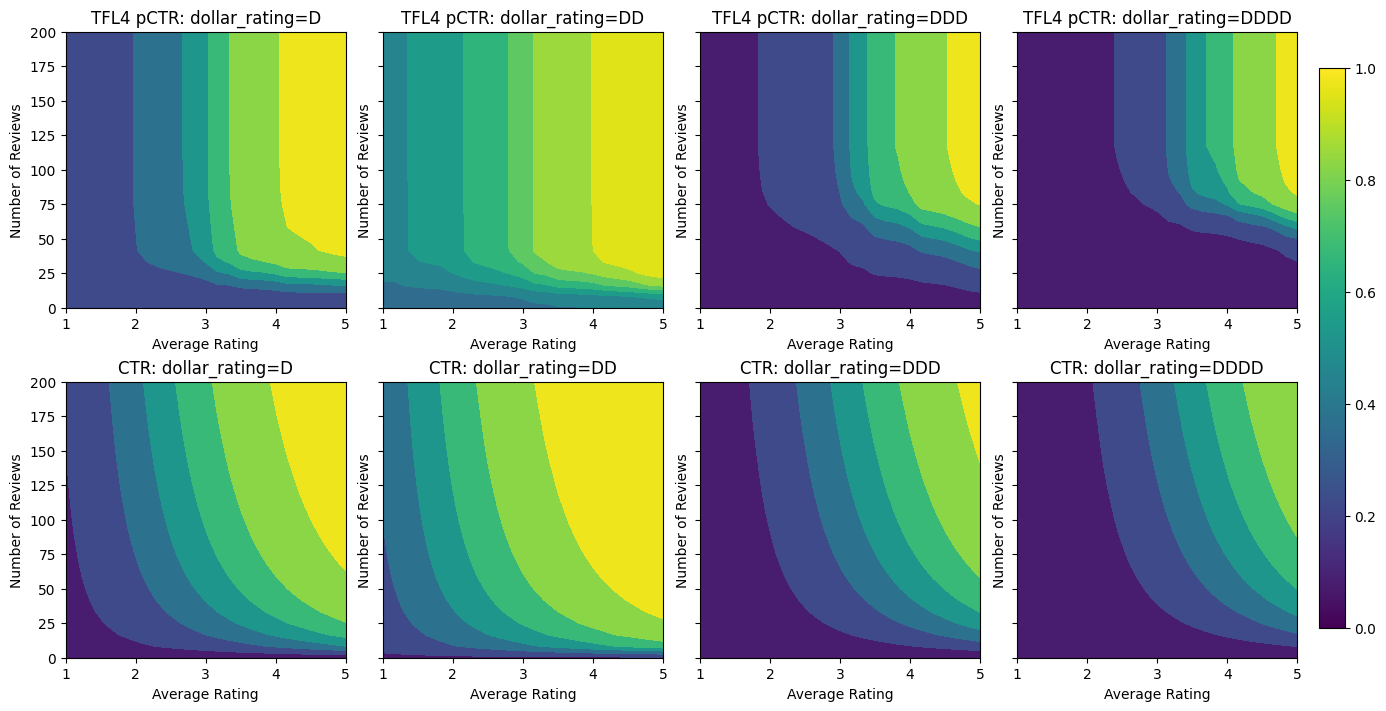
校准器现在很平滑,并且估计的总体 CTR 更接近于真实值。这在测试指标和等高线图中都有所体现。
在这里,您可以看到我们向模型添加特定于领域的约束和正则化器时每个步骤的结果。
analyze_model(
[
(tfl_model_0, "TFL0"),
(tfl_model_1, "TFL1"),
(tfl_model_2, "TFL2"),
(tfl_model_3, "TFL3"),
(tfl_model_4, "TFL4"),
],
from_logits=True,
print_metrics=False,
)