
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
在 特征化教程 中,我们将多个特征合并到我们的模型中,但模型仅包含一个嵌入层。我们可以向模型添加更多密集层以提高其表达能力。
通常,更深层的模型能够学习比更浅层的模型更复杂的模式。例如,我们的 用户模型 将用户 ID 和时间戳合并以模拟用户在特定时间点的偏好。浅层模型(例如,单个嵌入层)可能只能学习这些特征和电影之间最简单的关系:给定电影在其发布时最受欢迎,而给定用户通常更喜欢恐怖片而不是喜剧片。为了捕捉更复杂的关系,例如用户偏好随时间推移而变化,我们可能需要一个具有多个堆叠密集层的更深层模型。
当然,复杂模型也有其缺点。第一个是计算成本,因为更大的模型需要更多内存和更多计算才能拟合和服务。第二个是需要更多数据:通常,需要更多训练数据才能利用更深层的模型。由于参数更多,深层模型可能会过拟合,甚至只是记住训练示例,而不是学习一个可以泛化的函数。最后,训练更深层的模型可能更难,在选择正则化和学习率等设置时需要更加小心。
为实际的推荐系统找到一个好的架构是一门复杂的艺术,需要良好的直觉和仔细的 超参数调整。例如,模型的深度和宽度、激活函数、学习率和优化器等因素会极大地改变模型的性能。建模选择进一步复杂化,因为良好的离线评估指标可能不对应于良好的在线性能,并且优化目标的选择通常比模型本身的选择更关键。
尽管如此,在构建和微调更大模型方面付出的努力通常会有所回报。在本教程中,我们将说明如何使用 TensorFlow Recommenders 构建深度检索模型。我们将通过构建逐步更复杂的模型来实现这一点,以了解这将如何影响模型性能。
准备工作
我们首先导入必要的包。
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
2022-12-14 13:06:15.089641: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2022-12-14 13:06:15.089741: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2022-12-14 13:06:15.089751: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
/tmpfs/tmp/ipykernel_91398/2468769046.py:13: MatplotlibDeprecationWarning: The seaborn styles shipped by Matplotlib are deprecated since 3.6, as they no longer correspond to the styles shipped by seaborn. However, they will remain available as 'seaborn-v0_8-<style>'. Alternatively, directly use the seaborn API instead.
plt.style.use('seaborn-whitegrid')
在本教程中,我们将使用 特征化教程 中的模型来生成嵌入。因此,我们只使用用户 ID、时间戳和电影标题特征。
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
我们还进行一些准备工作,以准备特征词汇表。
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
模型定义
查询模型
我们从 特征化教程 中定义的用户模型开始,作为我们模型的第一层,负责将原始输入示例转换为特征嵌入。
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
定义更深层的模型将要求我们在该第一输入之上堆叠更多层。一个逐步变窄的层堆栈,由激活函数隔开,是一种常见的模式
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
由于深度线性模型的表达能力不比浅层线性模型强,因此我们对除最后一个隐藏层之外的所有层使用 ReLU 激活。最后一个隐藏层不使用任何激活函数:使用激活函数会限制最终嵌入的输出空间,并可能对模型的性能产生负面影响。例如,如果在投影层中使用 ReLU,则输出嵌入中的所有组件都将是非负的。
我们将在这里尝试类似的方法。为了便于对不同深度的模型进行实验,让我们定义一个模型,其深度(和宽度)由一组构造函数参数定义。
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes 参数为我们提供了模型的深度和宽度。我们可以对其进行更改以实验更浅层或更深层的模型。
候选模型
我们可以对电影模型采用相同的方法。同样,我们从 特征化 教程中的 MovieModel 开始
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
并使用隐藏层对其进行扩展
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
组合模型
定义了 QueryModel 和 CandidateModel 后,我们可以将它们组合在一起,并实现我们的损失和指标逻辑。为了简化操作,我们将强制模型结构在查询模型和候选模型之间保持一致。
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
训练模型
准备数据
我们首先将数据分成训练集和测试集。
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
浅层模型
我们准备尝试第一个浅层模型!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
这使我们获得了约 0.27 的前 100 准确率。我们可以将其用作评估更深层模型的参考点。
更深层模型
具有两层的更深层模型怎么样?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.28.
这里的准确率为 0.29,比浅层模型好很多。
我们可以绘制验证准确率曲线来说明这一点
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f5d9402a670>
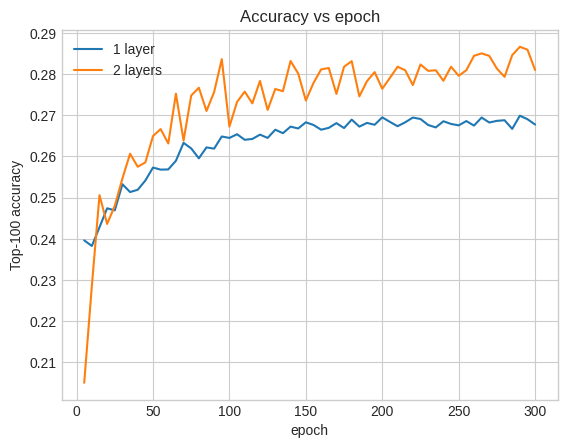
即使在训练的早期阶段,更大的模型也明显且稳定地领先于浅层模型,这表明增加深度有助于模型捕获数据中更细微的关系。
然而,即使更深的模型也不一定更好。以下模型将深度扩展到三层
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.25.
事实上,我们没有看到比浅层模型的改进
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f5d9406d070>
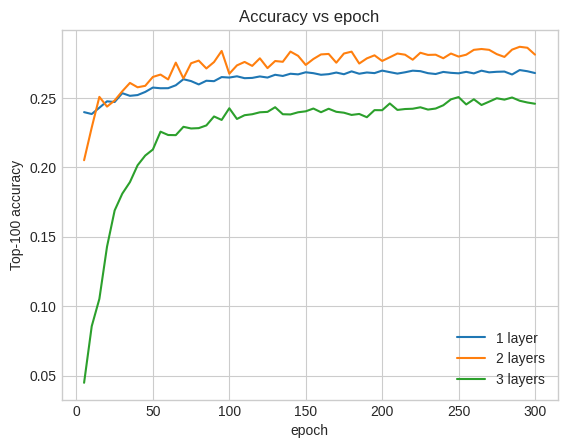
这很好地说明了这样一个事实,即更深更大模型虽然能够实现更优异的性能,但通常需要非常仔细的调整。例如,在本教程中,我们使用了单个固定学习率。其他选择可能会产生截然不同的结果,值得探索。
通过适当的调整和足够的数据,在许多情况下,投入构建更大更深模型的努力是值得的:更大的模型可以显著提高预测精度。
下一步
在本教程中,我们使用密集层和激活函数扩展了检索模型。要了解如何创建既可以执行检索任务又可以执行评分任务的模型,请查看 多任务教程。