
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
本教程演示了如何使用深度与交叉网络 (DCN) 有效地学习特征交叉。
背景
**什么是特征交叉,为什么它们很重要?** 想象一下,我们正在构建一个推荐系统来向客户销售搅拌机。那么,客户的过去购买历史,例如 purchased_bananas 和 purchased_cooking_books,或地理特征,都是单个特征。如果一个人购买了香蕉 **和** 烹饪书籍,那么这位客户更有可能点击推荐的搅拌机。 purchased_bananas 和 purchased_cooking_books 的组合被称为 **特征交叉**,它提供了超出单个特征的额外交互信息。
**学习特征交叉的挑战是什么?** 在 Web 规模的应用程序中,数据大多是分类的,导致特征空间庞大且稀疏。在这种情况下,识别有效的特征交叉通常需要手动特征工程或穷举搜索。传统的正向多层感知器 (MLP) 模型是通用函数逼近器;但是,它们不能有效地逼近甚至 2 阶或 3 阶特征交叉 [1, 2]。
**什么是深度与交叉网络 (DCN)?** DCN 旨在更有效地学习显式和有界度的交叉特征。它从一个输入层(通常是嵌入层)开始,然后是一个包含多个交叉层的 *交叉网络*,该网络对显式特征交互进行建模,然后与一个对隐式特征交互进行建模的 *深度网络* 相结合。
- 交叉网络。这是 DCN 的核心。它在每一层显式地应用特征交叉,并且最高多项式次数随着层深度的增加而增加。下图显示了 \((i+1)\)-th 交叉层。
- 深度网络。它是一个传统的正向多层感知器 (MLP)。
深度网络和交叉网络然后组合起来形成 DCN [1]。通常,我们可以将深度网络堆叠在交叉网络之上(堆叠结构);我们也可以将它们并排放置(并行结构)。
接下来,我们将首先通过一个玩具示例展示 DCN 的优势,然后我们将引导您完成使用 MovieLen-1M 数据集利用 DCN 的一些常见方法。
让我们首先安装并导入此 colab 所需的软件包。
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
2022-12-14 12:19:17.483745: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 12:19:17.483841: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 12:19:17.483851: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
玩具示例
为了说明 DCN 的好处,让我们完成一个简单的示例。假设我们有一个数据集,我们试图对客户点击搅拌机广告的可能性进行建模,其特征和标签描述如下。
| 特征/标签 | 描述 | 值类型/范围 |
|---|---|---|
| \(x_1\) = 国家 | 该客户居住的国家 | Int 在 [0, 199] 中 |
| \(x_2\) = 香蕉 | 客户购买的香蕉数量 | Int 在 [0, 23] 中 |
| \(x_3\) = 烹饪书 | 客户购买的烹饪书籍数量 | Int 在 [0, 5] 中 |
| \(y\) | 点击搅拌机广告的可能性 | -- |
然后,我们让数据遵循以下潜在分布
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
其中可能性 \(y\) 线性地依赖于特征 \(x_i\) 的值,但也依赖于 \(x_i\) 之间的乘法交互。在我们的案例中,我们会说购买搅拌机的可能性 (\(y\)) 不仅取决于购买香蕉 (\(x_2\)) 或烹饪书籍 (\(x_3\)),还取决于购买香蕉和烹饪书籍 *一起* (\(x_2x_3\))。
我们可以如下生成此数据
合成数据生成
我们首先定义如上所述的 \(f(x_1, x_2, x_3)\)。
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
cookbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, cookbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * cookbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * cookbooks + (
0.1 * cookbooks * cookbooks)
return x, y
让我们生成遵循该分布的数据,并将数据分成 90% 用于训练,10% 用于测试。
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
模型构建
我们将尝试交叉网络和深度网络,以说明交叉网络可以为推荐器带来的优势。由于我们刚刚创建的数据只包含 2 阶特征交互,因此使用单层交叉网络就足够了。如果我们想对更高阶的特征交互进行建模,我们可以堆叠多个交叉层并使用多层交叉网络。我们将构建的两个模型是
- 仅包含一个交叉层的交叉网络;
- 具有更宽和更深 ReLU 层的深度网络。
我们首先构建一个统一的模型类,其损失是均方误差。
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
然后,我们指定交叉网络(具有大小为 3 的 1 个交叉层)和基于 ReLU 的 DNN(具有层大小 [512, 256, 128])
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
模型训练
现在我们已经准备好了数据和模型,我们将训练模型。我们首先对数据进行洗牌和批处理,以准备模型训练。
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
然后,我们定义时期数以及学习率。
epochs = 100
learning_rate = 0.4
好了,现在一切都准备就绪,让我们编译和训练模型。如果要查看模型的进度,可以设置 verbose=True。
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7fc688388bb0>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7fc5f0386af0>
模型评估
我们验证模型在评估数据集上的性能,并报告均方根误差 (RMSE,越低越好)。
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0001 using 16 parameters. DeepNet(large) RMSE is 0.0933 using 166401 parameters.
我们看到,交叉网络实现了比基于 ReLU 的 DNN **低几个数量级的 RMSE**,并且 **参数数量少几个数量级**。这表明交叉网络在学习特征交叉方面的效率。
模型理解
我们已经知道数据中哪些特征交叉很重要,检查我们的模型是否确实学习了重要的特征交叉会很有趣。这可以通过可视化 DCN 中学习到的权重矩阵来完成。权重 \(W_{ij}\) 表示学习到的特征 \(x_i\) 和 \(x_j\) 之间交互的重要性。
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/tmp/ipykernel_40470/2879280353.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator _ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10) /tmpfs/tmp/ipykernel_40470/2879280353.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator _ = ax.set_yticklabels([''] + features, fontsize=10) <Figure size 900x900 with 0 Axes>
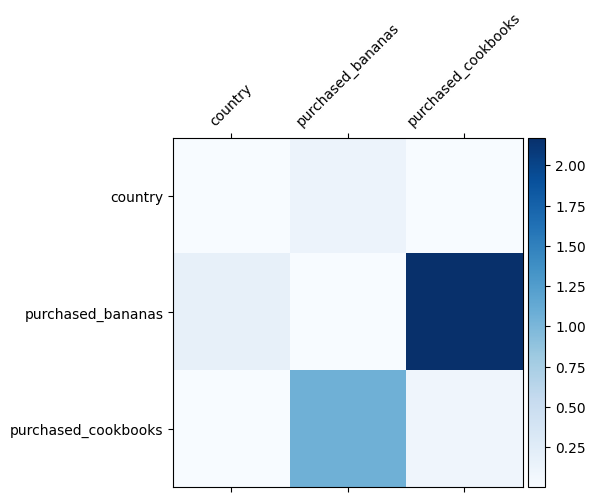
颜色越深表示学习到的交互越强 - 在这种情况下,很明显模型学习到购买香蕉和烹饪书一起很重要。
如果您有兴趣尝试更复杂的合成数据,请随时查看 这篇论文。
Movielens 1M 示例
我们现在考察 DCN 在真实世界数据集上的有效性:Movielens 1M [3]。Movielens 1M 是推荐研究中一个流行的数据集。它根据用户相关特征和电影相关特征预测用户的电影评分。我们使用此数据集来演示一些使用 DCN 的常见方法。
数据处理
数据处理过程遵循与 基本排名教程 相似的过程。
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
接下来,我们将数据随机分成 80% 用于训练,20% 用于测试。
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
然后,我们为每个特征创建词汇表。
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
模型构建
我们将要构建的模型架构从一个嵌入层开始,该层被馈送到交叉网络,然后是深度网络。所有特征的嵌入维度都设置为 32。您也可以对不同的特征使用不同的嵌入大小。
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
模型训练
我们对训练和测试数据进行洗牌、批处理和缓存。
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
让我们定义一个函数,该函数多次运行模型并返回模型在多次运行中的 RMSE 均值和标准差。
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
我们为模型设置了一些超参数。请注意,这些超参数是为所有模型全局设置的,用于演示目的。如果您想为每个模型获得最佳性能,或进行模型之间的公平比较,那么我们建议您微调超参数。请记住,模型架构和优化方案是相互交织的。
epochs = 8
learning_rate = 0.01
DCN(堆叠)。 我们首先训练一个具有堆叠结构的 DCN 模型,即输入被馈送到交叉网络,然后是深度网络。
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 2s 19ms/step - RMSE: 0.9322 - loss: 0.8695 - regularization_loss: 0.0000e+00 - total_loss: 0.8695 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9350 - loss: 0.8744 - regularization_loss: 0.0000e+00 - total_loss: 0.8744 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8654 - regularization_loss: 0.0000e+00 - total_loss: 0.8654 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9322 - loss: 0.8695 - regularization_loss: 0.0000e+00 - total_loss: 0.8695 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9333 - loss: 0.8718 - regularization_loss: 0.0000e+00 - total_loss: 0.8718
低秩 DCN。 为了降低训练和服务成本,我们利用低秩技术来近似 DCN 权重矩阵。秩通过参数 projection_dim 传入;较小的 projection_dim 会导致更低的成本。请注意,projection_dim 需要小于 (输入大小)/2 才能降低成本。在实践中,我们观察到使用秩为 (输入大小)/4 的低秩 DCN 一直保持了全秩 DCN 的准确性。
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9358 - loss: 0.8761 - regularization_loss: 0.0000e+00 - total_loss: 0.8761 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9349 - loss: 0.8746 - regularization_loss: 0.0000e+00 - total_loss: 0.8746 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9330 - loss: 0.8715 - regularization_loss: 0.0000e+00 - total_loss: 0.8715 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8648 - regularization_loss: 0.0000e+00 - total_loss: 0.8648 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9310 - loss: 0.8672 - regularization_loss: 0.0000e+00 - total_loss: 0.8672
DNN。 我们训练了一个与之大小相同的 DNN 模型作为参考。
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9379 - loss: 0.8803 - regularization_loss: 0.0000e+00 - total_loss: 0.8803 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8660 - regularization_loss: 0.0000e+00 - total_loss: 0.8660 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9384 - loss: 0.8814 - regularization_loss: 0.0000e+00 - total_loss: 0.8814 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8771 - regularization_loss: 0.0000e+00 - total_loss: 0.8771 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9324 - loss: 0.8706 - regularization_loss: 0.0000e+00 - total_loss: 0.8706
我们在测试数据上评估模型,并报告 5 次运行的均值和标准差。
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9326, stdv: 0.0015 DCN (low-rank) RMSE mean: 0.9329, stdv: 0.0022 DNN RMSE mean: 0.9350, stdv: 0.0032
我们看到 DCN 的性能优于具有 ReLU 层的相同大小的 DNN。此外,低秩 DCN 能够在保持准确性的同时减少参数。
关于 DCN 的更多信息。 除了上面演示的内容之外,还有更多创造性但实际上有用的方法来利用 DCN [1]。
具有并行结构的 DCN。输入并行馈送到交叉网络和深度网络。
连接交叉层。 输入并行馈送到多个交叉层以捕获互补的特征交叉。
模型理解
DCN 中的权重矩阵 \(W\) 显示了模型学习到的哪些特征交叉很重要。回想一下,在前面的玩具示例中,\(i\) 次和 \(j\) 次特征之间交互的重要性由 \(W\) 的 (\(i, j\)) 次元素捕获。
这里有点不同的是,特征嵌入的大小为 32 而不是 1。因此,重要性将由 (\(i, j\)) 次块 \(W_{i,j}\) 来表征,该块的维度为 32 乘 32。在下面,我们可视化每个块的 Frobenius 范数 [4] \(||W_{i,j}||_F\),更大的范数表示更高的重要性(假设特征的嵌入具有相似的尺度)。
除了块范数之外,我们还可以可视化整个矩阵,或每个块的平均值/中位数/最大值。
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/tmp/ipykernel_40470/1244897914.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator _ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10) /tmpfs/tmp/ipykernel_40470/1244897914.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator _ = ax.set_yticklabels([""] + features, fontsize=10) <Figure size 900x900 with 0 Axes>
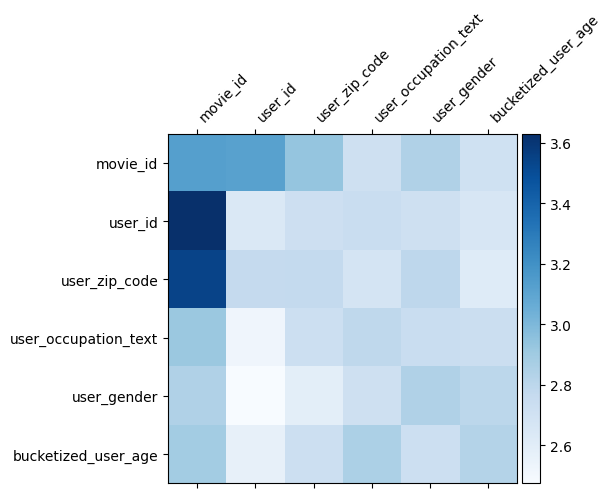
这就是这个 colab 的全部内容!我们希望您喜欢学习 DCN 的一些基础知识以及使用它的常见方法。如果您有兴趣了解更多信息,可以查看两篇相关的论文:DCN-v1-paper,DCN-v2-paper。
参考文献
DCN V2:改进的深度与交叉网络以及用于 Web 规模学习排名系统的实践经验.
Ruoxi Wang、Rakesh Shivanna、Derek Zhiyuan Cheng、Sagar Jain、Dong Lin、Lichan Hong、Ed Chi。(2020 年)
用于广告点击预测的深度与交叉网络.
Ruoxi Wang、Bin Fu、Gang Fu、Mingliang Wang。(AdKDD 2017 年)