
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
TensorFlow Quantum 将量子基元引入 TensorFlow 生态系统。现在,量子研究人员可以利用 TensorFlow 中的工具。在本教程中,你将仔细了解如何将 TensorBoard 纳入你的量子计算研究。使用 TensorFlow 中的 DCGAN 教程,你可以快速建立类似于 Niu 等人 所做的工作实验和可视化。总体而言,你将
- 训练 GAN 以生成看起来像来自量子电路的样本。
- 可视化训练进度以及随时间推移的分布演变。
- 通过探索计算图对实验进行基准测试。
pip install tensorflow==2.15.0 tensorflow-quantum==0.7.3 tensorboard_plugin_profile==2.15.0
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
/tmpfs/tmp/ipykernel_16243/1875984233.py:2: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html import importlib, pkg_resources <module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pkg_resources/__init__.py'>
#docs_infra: no_execute
%load_ext tensorboard
import datetime
import time
import cirq
import tensorflow as tf
import tensorflow_quantum as tfq
from tensorflow.keras import layers
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
2024-05-18 11:28:15.992999: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-05-18 11:28:15.993049: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-05-18 11:28:15.994545: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2024-05-18 11:28:17.993011: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:274] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. 数据生成
首先收集一些数据。你可以使用 TensorFlow Quantum 快速生成一些比特串样本,这些样本将成为你其余实验的主要数据源。像 Niu 等人一样,你将探索模拟从深度大幅减少的随机电路中进行采样的难易程度。首先,定义一些帮助程序
def generate_circuit(qubits):
"""Generate a random circuit on qubits."""
random_circuit = cirq.experiments.random_rotations_between_grid_interaction_layers_circuit(
qubits, depth=2)
return random_circuit
def generate_data(circuit, n_samples):
"""Draw n_samples samples from circuit into a tf.Tensor."""
return tf.squeeze(tfq.layers.Sample()(circuit, repetitions=n_samples).to_tensor())
现在,你可以检查电路以及一些样本数据
qubits = cirq.GridQubit.rect(1, 5)
random_circuit_m = generate_circuit(qubits) + cirq.measure_each(*qubits)
SVGCircuit(random_circuit_m)
findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found. findfont: Font family 'Arial' not found.

samples = cirq.sample(random_circuit_m, repetitions=10)
print('10 Random bitstrings from this circuit:')
print(samples)
10 Random bitstrings from this circuit: q(0, 0)=1011111111 q(0, 1)=1111111111 q(0, 2)=1011111111 q(0, 3)=0100010111 q(0, 4)=1111111101
你可以在 TensorFlow Quantum 中使用以下命令执行相同操作
generate_data(random_circuit_m, 10)
<tf.Tensor: shape=(10, 5), dtype=int8, numpy=
array([[0, 1, 1, 1, 1],
[1, 1, 1, 0, 1],
[1, 1, 1, 0, 1],
[1, 1, 1, 0, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=int8)>
现在,你可以使用以下命令快速生成训练数据
N_SAMPLES = 60000
N_QUBITS = 10
QUBITS = cirq.GridQubit.rect(1, N_QUBITS)
REFERENCE_CIRCUIT = generate_circuit(QUBITS)
all_data = generate_data(REFERENCE_CIRCUIT, N_SAMPLES)
all_data
<tf.Tensor: shape=(60000, 10), dtype=int8, numpy=
array([[0, 1, 0, ..., 1, 1, 1],
[0, 1, 0, ..., 1, 1, 0],
[0, 1, 0, ..., 1, 1, 0],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]], dtype=int8)>
在训练过程中,定义一些帮助函数进行可视化将很有用。两个有趣的量是
- 样本的整数值,以便你可以创建分布的直方图。
- 一组样本的 线性 XEB 保真度估计,以指示样本的“真正量子随机性”。
@tf.function
def bits_to_ints(bits):
"""Convert tensor of bitstrings to tensor of ints."""
sigs = tf.constant([1 << i for i in range(N_QUBITS)], dtype=tf.int32)
rounded_bits = tf.clip_by_value(tf.math.round(
tf.cast(bits, dtype=tf.dtypes.float32)), clip_value_min=0, clip_value_max=1)
return tf.einsum('jk,k->j', tf.cast(rounded_bits, dtype=tf.dtypes.int32), sigs)
@tf.function
def xeb_fid(bits):
"""Compute linear XEB fidelity of bitstrings."""
final_probs = tf.squeeze(
tf.abs(tfq.layers.State()(REFERENCE_CIRCUIT).to_tensor()) ** 2)
nums = bits_to_ints(bits)
return (2 ** N_QUBITS) * tf.reduce_mean(tf.gather(final_probs, nums)) - 1.0
在这里,你可以使用 XEB 可视化你的分布并对事物进行健全性检查
plt.hist(bits_to_ints(all_data).numpy(), 50)
plt.show()
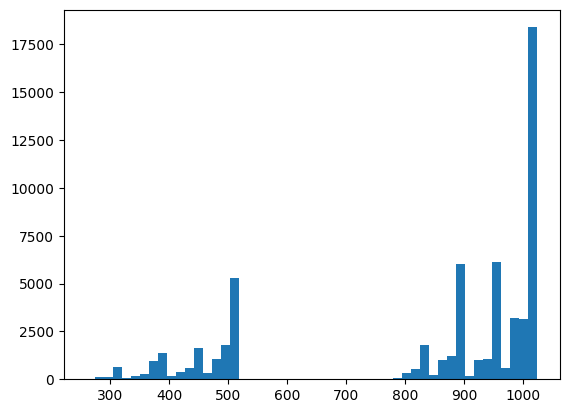
xeb_fid(all_data)
WARNING:tensorflow:You are casting an input of type complex64 to an incompatible dtype float32. This will discard the imaginary part and may not be what you intended. <tf.Tensor: shape=(), dtype=float32, numpy=46.323647>
2. 构建模型
在这里,你可以使用 DCGAN 教程 中与量子情况相关的组件。新的 GAN 将用于生成长度为 N_QUBITS 的比特串样本,而不是生成 MNIST 数字
LATENT_DIM = 100
def make_generator_model():
"""Construct generator model."""
model = tf.keras.Sequential()
model.add(layers.Dense(256, use_bias=False, input_shape=(LATENT_DIM,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(N_QUBITS, activation='relu'))
return model
def make_discriminator_model():
"""Constrcut discriminator model."""
model = tf.keras.Sequential()
model.add(layers.Dense(256, use_bias=False, input_shape=(N_QUBITS,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
return model
接下来,实例化你的生成器和鉴别器模型,定义损失并创建 train_step 函数,以用于你的主训练循环
discriminator = make_discriminator_model()
generator = make_generator_model()
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
"""Compute discriminator loss."""
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
"""Compute generator loss."""
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
BATCH_SIZE=256
@tf.function
def train_step(images):
"""Run train step on provided image batch."""
noise = tf.random.normal([BATCH_SIZE, LATENT_DIM])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(
gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(
disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(
zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(
zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss
现在你已经拥有了模型所需的所有构建模块,你可以设置一个包含 TensorBoard 可视化的训练函数。首先设置一个 TensorBoard 文件写入器
logdir = "tb_logs/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer = tf.summary.create_file_writer(logdir + "/metrics")
file_writer.set_as_default()
使用 tf.summary 模块,你现在可以在主 train 函数中将 scalar、histogram(以及其他)日志记录到 TensorBoard 中
def train(dataset, epochs, start_epoch=1):
"""Launch full training run for the given number of epochs."""
# Log original training distribution.
tf.summary.histogram('Training Distribution', data=bits_to_ints(dataset), step=0)
batched_data = tf.data.Dataset.from_tensor_slices(dataset).shuffle(N_SAMPLES).batch(512)
t = time.time()
for epoch in range(start_epoch, start_epoch + epochs):
for i, image_batch in enumerate(batched_data):
# Log batch-wise loss.
gl, dl = train_step(image_batch)
tf.summary.scalar(
'Generator loss', data=gl, step=epoch * len(batched_data) + i)
tf.summary.scalar(
'Discriminator loss', data=dl, step=epoch * len(batched_data) + i)
# Log full dataset XEB Fidelity and generated distribution.
generated_samples = generator(tf.random.normal([N_SAMPLES, 100]))
tf.summary.scalar(
'Generator XEB Fidelity Estimate', data=xeb_fid(generated_samples), step=epoch)
tf.summary.histogram(
'Generator distribution', data=bits_to_ints(generated_samples), step=epoch)
# Log new samples drawn from this particular random circuit.
random_new_distribution = generate_data(REFERENCE_CIRCUIT, N_SAMPLES)
tf.summary.histogram(
'New round of True samples', data=bits_to_ints(random_new_distribution), step=epoch)
if epoch % 10 == 0:
print('Epoch {}, took {}(s)'.format(epoch, time.time() - t))
t = time.time()
3. 可视化训练和性能
现在可以使用以下命令启动 TensorBoard 仪表板
#docs_infra: no_execute
%tensorboard --logdir tb_logs/
在调用 train 时,TensoBoard 仪表板将自动更新训练循环中给出的所有摘要统计信息。
train(all_data, epochs=50)
Epoch 10, took 8.953658819198608(s) Epoch 20, took 6.647485971450806(s) Epoch 30, took 6.6542747020721436(s) Epoch 40, took 6.638120889663696(s) Epoch 50, took 6.668101072311401(s)
在训练运行期间(以及完成后),你可以检查标量量

切换到直方图选项卡,你还可以看到生成器网络在从量子分布中重新创建样本方面的表现
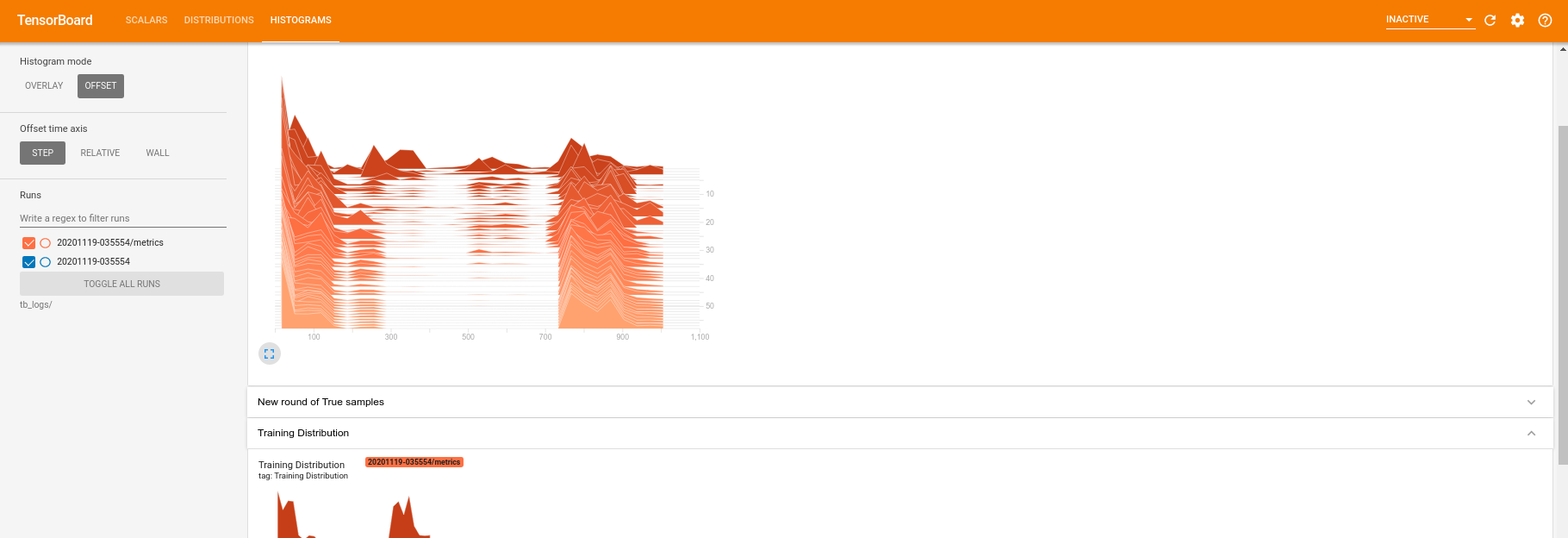
除了允许实时监视与你的实验相关的摘要统计信息之外,TensorBoard 还可以帮助你分析你的实验以识别性能瓶颈。若要使用性能监视重新运行你的模型,你可以执行以下操作
tf.profiler.experimental.start(logdir)
train(all_data, epochs=10, start_epoch=50)
tf.profiler.experimental.stop()
Epoch 50, took 0.7739055156707764(s)
TensorBoard 将分析 tf.profiler.experimental.start 和 tf.profiler.experimental.stop 之间的所有代码。然后可以在 TensorBoard 的 profile 页面中查看此分析数据
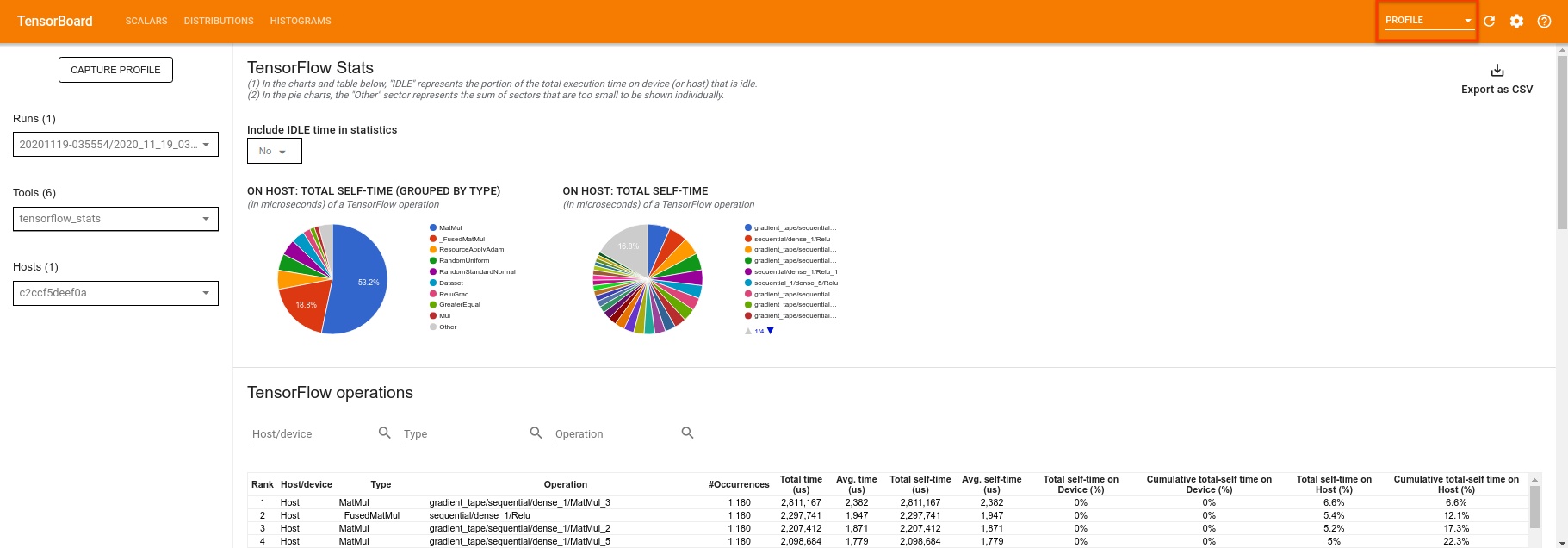
尝试增加深度或尝试使用不同类别的量子电路。查看 TensorBoard 的所有其他出色功能,例如 超参数调整,你可以将其纳入 TensorFlow Quantum 实验中。