
训练后量化是一种转换技术,它可以减小模型大小,同时还能提高 CPU 和硬件加速器的延迟,而模型精度的下降很小。使用 TensorFlow Lite 转换器 将已训练的浮点 TensorFlow 模型转换为 TensorFlow Lite 格式时,可以量化该模型。
优化方法
有多种训练后量化选项可供选择。以下是这些选项的汇总表以及它们提供的优势
| 技术 | 优势 | 硬件 |
|---|---|---|
| 动态范围量化 | 缩小 4 倍,速度提高 2-3 倍 | CPU |
| 全整数量化 | 缩小 4 倍,速度提高 3 倍以上 | CPU、Edge TPU、微控制器 |
| Float16 量化 | 缩小 2 倍,GPU 加速 | CPU、GPU |
以下决策树可以帮助确定哪种训练后量化方法最适合您的用例
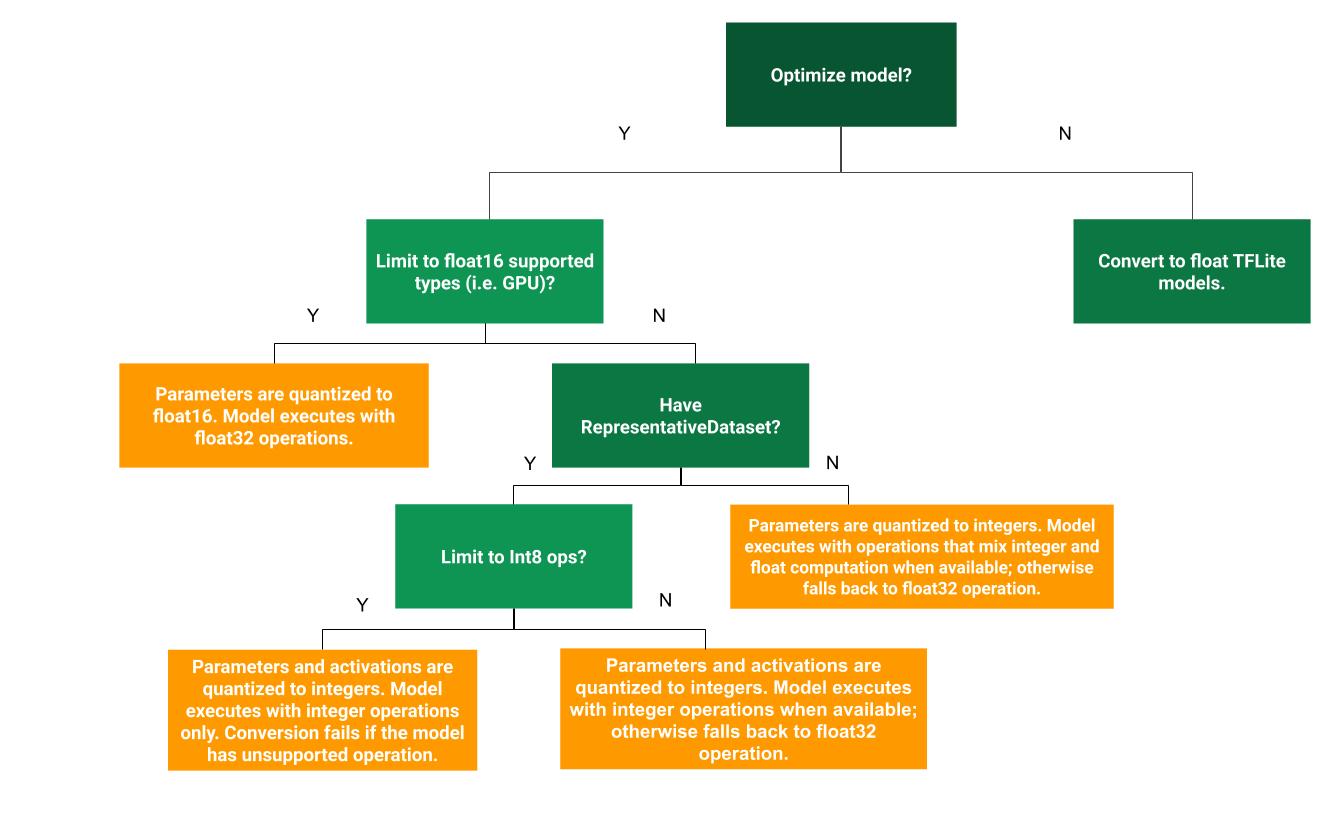
动态范围量化
动态范围量化是一个推荐的起点,因为它可以减少内存使用量并加快计算速度,而无需您提供代表性数据集进行校准。这种类型的量化在转换时仅静态地将权重从浮点量化为整数,从而提供 8 位精度
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
为了进一步减少推理过程中的延迟,"动态范围" 运算符会根据其范围动态地将激活量化为 8 位,并使用 8 位权重和激活进行计算。这种优化可以提供接近全定点推理的延迟。但是,输出仍然使用浮点存储,因此动态范围运算符的加速速度低于全定点计算。
全整数量化
通过确保所有模型数学运算都进行整数量化,您可以获得进一步的延迟改进、峰值内存使用量的减少以及与仅整数硬件设备或加速器的兼容性。
对于全整数量化,您需要校准或估计模型中所有浮点张量的范围,即 (min, max)。与权重和偏差等常量张量不同,模型输入、激活(中间层的输出)和模型输出等可变张量无法进行校准,除非我们运行一些推理周期。因此,转换器需要一个代表性数据集来校准它们。此数据集可以是训练或验证数据的较小子集(大约 ~100-500 个样本)。请参阅下面的 representative_dataset() 函数。
从 TensorFlow 2.7 版本开始,您可以通过 签名 指定代表性数据集,如下例所示
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
如果给定的 TensorFlow 模型中有多个签名,您可以通过指定签名键来指定多个数据集
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
您可以通过提供输入张量列表来生成代表性数据集
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
从 TensorFlow 2.7 版本开始,我们建议使用基于签名的方案而不是基于输入张量列表的方案,因为输入张量排序很容易被颠倒。
为了测试目的,您可以使用以下虚拟数据集
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
带浮点型回退的整数(使用默认浮点型输入/输出)
为了完全对模型进行整数量化,但在没有整数实现的运算符时使用浮点运算符(以确保转换顺利进行),请执行以下步骤
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
仅支持整数
创建仅支持整数的模型是 TensorFlow Lite for Microcontrollers 和 Coral Edge TPUs 的常见用例。
此外,为了确保与仅支持整数的设备(如 8 位微控制器)和加速器(如 Coral Edge TPU)的兼容性,您可以通过以下步骤对所有运算符(包括输入和输出)强制执行完全整数量化
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 量化
您可以通过将权重量化为 float16(IEEE 16 位浮点数标准)来减小浮点模型的大小。要启用权重的 float16 量化,请执行以下步骤
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 量化的优点如下
- 它将模型大小减少了一半(因为所有权重都变成了原来的一半)。
- 它会导致精度损失最小。
- 它支持一些委托(例如 GPU 委托),这些委托可以直接对 float16 数据进行操作,从而比 float32 计算更快地执行。
float16 量化的缺点如下
- 它不像量化为定点数学那样能减少延迟。
- 默认情况下,float16 量化模型在 CPU 上运行时会将权重值“反量化”为 float32。(请注意,GPU 委托不会执行此反量化,因为它可以对 float16 数据进行操作。)
仅支持整数:带 8 位权重的 16 位激活(实验性)
这是一种实验性的量化方案。它类似于“仅支持整数”方案,但激活根据其范围量化为 16 位,权重量化为 8 位整数,偏差量化为 64 位整数。这被称为 16x8 量化。
这种量化的主要优点是它可以显着提高精度,但只会略微增加模型大小。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
如果模型中某些运算符不支持 16x8 量化,则模型仍然可以量化,但不受支持的运算符将保留为浮点型。应将以下选项添加到 target_spec 以允许这样做。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
此量化方案提供的精度改进的用例示例包括
- 超分辨率,
- 音频信号处理,如降噪和波束成形,
- 图像去噪,
- 从单个图像重建 HDR。
这种量化的缺点是
- 由于缺乏优化的内核实现,目前推理速度明显慢于 8 位全整数。
- 目前它与现有的硬件加速 TFLite 委托不兼容。
此量化模式的教程可以在 此处 找到。
模型精度
由于权重是在训练后量化的,因此可能会出现精度损失,特别是对于较小的网络。 TensorFlow Hub 上提供了针对特定网络的预训练全量化模型。重要的是要检查量化模型的精度,以验证任何精度下降是否在可接受的范围内。有一些工具可以评估 TensorFlow Lite 模型精度。
或者,如果精度下降过高,请考虑使用 量化感知训练 。但是,这样做需要在模型训练期间进行修改以添加伪量化节点,而此页面上的训练后量化技术使用现有的预训练模型。
量化张量的表示
8 位量化使用以下公式来近似浮点值。
\[real\_value = (int8\_value - zero\_point) \times scale\]
该表示有两个主要部分
每个轴(也称为每个通道)或每个张量权重由范围为 [-127, 127] 的 int8 二进制补码值表示,零点等于 0。
每个张量激活/输入由范围为 [-128, 127] 的 int8 二进制补码值表示,零点在范围 [-128, 127] 内。
有关我们量化方案的详细视图,请参阅我们的 量化规范。希望接入 TensorFlow Lite 委托接口的硬件供应商应实施其中描述的量化方案。