
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
将 TensorFlow Lite 机器学习模型部署到设备或移动应用程序时,您可能希望使模型能够根据设备或最终用户的输入进行改进或个性化。使用设备端训练技术,您可以更新模型,而无需 数据离开用户的设备,从而提高用户隐私,并且无需用户更新设备软件。
例如,您的移动应用程序中可能有一个模型可以识别时尚商品,但您希望用户能够根据他们的兴趣随着时间的推移获得改进的识别性能。启用设备端训练,允许对鞋子感兴趣的用户在使用您的应用程序时越频繁,就越能识别出特定风格的鞋子或鞋子的品牌。
本教程将向您展示如何构建一个 TensorFlow Lite 模型,该模型可以在已安装的 Android 应用程序中进行增量训练和改进。
设置
本教程使用 Python 在将 TensorFlow 模型合并到 Android 应用程序之前对其进行训练和转换。首先安装并导入以下软件包。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
TensorFlow version: 2.8.0
对服装图像进行分类
此示例代码使用 Fashion MNIST 数据集 来训练一个神经网络模型,用于对服装图像进行分类。该数据集包含 60,000 个小型(28 x 28 像素)灰度图像,包含 10 种不同的时尚配饰类别,包括连衣裙、衬衫和凉鞋。
您可以在 Keras 分类教程 中更深入地了解此数据集。
构建用于设备端训练的模型
TensorFlow Lite 模型通常只有一个公开的函数方法(或 签名),允许您调用模型以运行推理。为了使模型能够在设备上进行训练和使用,您必须能够执行多个独立的操作,包括模型的训练、推理、保存和恢复函数。您可以通过首先扩展 TensorFlow 模型以具有多个函数,然后在将模型转换为 TensorFlow Lite 模型格式时将这些函数公开为签名来启用此功能。
下面的代码示例展示了如何将以下函数添加到 TensorFlow 模型中
train函数使用训练数据训练模型。infer函数调用推理。save函数将可训练权重保存到文件系统中。restore函数从文件系统加载可训练权重。
IMG_SIZE = 28
class Model(tf.Module):
def __init__(self):
self.model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(IMG_SIZE, IMG_SIZE), name='flatten'),
tf.keras.layers.Dense(128, activation='relu', name='dense_1'),
tf.keras.layers.Dense(10, name='dense_2')
])
self.model.compile(
optimizer='sgd',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True))
# The `train` function takes a batch of input images and labels.
@tf.function(input_signature=[
tf.TensorSpec([None, IMG_SIZE, IMG_SIZE], tf.float32),
tf.TensorSpec([None, 10], tf.float32),
])
def train(self, x, y):
with tf.GradientTape() as tape:
prediction = self.model(x)
loss = self.model.loss(y, prediction)
gradients = tape.gradient(loss, self.model.trainable_variables)
self.model.optimizer.apply_gradients(
zip(gradients, self.model.trainable_variables))
result = {"loss": loss}
return result
@tf.function(input_signature=[
tf.TensorSpec([None, IMG_SIZE, IMG_SIZE], tf.float32),
])
def infer(self, x):
logits = self.model(x)
probabilities = tf.nn.softmax(logits, axis=-1)
return {
"output": probabilities,
"logits": logits
}
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def save(self, checkpoint_path):
tensor_names = [weight.name for weight in self.model.weights]
tensors_to_save = [weight.read_value() for weight in self.model.weights]
tf.raw_ops.Save(
filename=checkpoint_path, tensor_names=tensor_names,
data=tensors_to_save, name='save')
return {
"checkpoint_path": checkpoint_path
}
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def restore(self, checkpoint_path):
restored_tensors = {}
for var in self.model.weights:
restored = tf.raw_ops.Restore(
file_pattern=checkpoint_path, tensor_name=var.name, dt=var.dtype,
name='restore')
var.assign(restored)
restored_tensors[var.name] = restored
return restored_tensors
上面的代码中的 train 函数使用 GradientTape 类来记录用于自动微分的操作。有关如何使用此类的更多信息,请参阅 梯度和自动微分简介。
您可以使用 Keras 模型的 Model.train_step 方法,而不是从头开始实现。请注意,Model.train_step 返回的损失(和指标)是运行平均值,应该定期重置(通常每个 epoch)。有关详细信息,请参阅 Customize Model.fit。
准备数据
获取 Fashion MNIST 数据集来训练您的模型。
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
预处理数据集
此数据集中的像素值介于 0 到 255 之间,必须将其归一化为 0 到 1 之间的数值,以便模型进行处理。将值除以 255 以进行此调整。
train_images = (train_images / 255.0).astype(np.float32)
test_images = (test_images / 255.0).astype(np.float32)
通过执行独热编码将数据标签转换为分类值。
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
训练模型
在转换和设置 TensorFlow Lite 模型之前,请使用预处理的数据集和 train 签名方法完成模型的初始训练。以下代码运行模型训练 100 个 epoch,每次处理 100 张图像的批次,并在每 10 个 epoch 后显示损失值。由于此训练运行处理了相当多的数据,因此可能需要几分钟才能完成。
NUM_EPOCHS = 100
BATCH_SIZE = 100
epochs = np.arange(1, NUM_EPOCHS + 1, 1)
losses = np.zeros([NUM_EPOCHS])
m = Model()
train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
train_ds = train_ds.batch(BATCH_SIZE)
for i in range(NUM_EPOCHS):
for x,y in train_ds:
result = m.train(x, y)
losses[i] = result['loss']
if (i + 1) % 10 == 0:
print(f"Finished {i+1} epochs")
print(f" loss: {losses[i]:.3f}")
# Save the trained weights to a checkpoint.
m.save('/tmp/model.ckpt')
Finished 10 epochs
loss: 0.428
Finished 20 epochs
loss: 0.378
Finished 30 epochs
loss: 0.344
Finished 40 epochs
loss: 0.317
Finished 50 epochs
loss: 0.299
Finished 60 epochs
loss: 0.283
Finished 70 epochs
loss: 0.266
Finished 80 epochs
loss: 0.252
Finished 90 epochs
loss: 0.240
Finished 100 epochs
loss: 0.230
{'checkpoint_path': <tf.Tensor: shape=(), dtype=string, numpy=b'/tmp/model.ckpt'>}
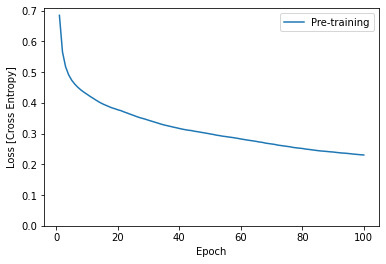
plt.plot(epochs, losses, label='Pre-training')
plt.ylim([0, max(plt.ylim())])
plt.xlabel('Epoch')
plt.ylabel('Loss [Cross Entropy]')
plt.legend();
将模型转换为 TensorFlow Lite 格式
在您扩展 TensorFlow 模型以启用设备上训练的附加功能并完成模型的初始训练后,您可以将其转换为 TensorFlow Lite 格式。以下代码将您的模型转换为该格式并保存到该格式,包括您在设备上使用 TensorFlow Lite 模型时使用的签名集:train, infer, save, restore。
SAVED_MODEL_DIR = "saved_model"
tf.saved_model.save(
m,
SAVED_MODEL_DIR,
signatures={
'train':
m.train.get_concrete_function(),
'infer':
m.infer.get_concrete_function(),
'save':
m.save.get_concrete_function(),
'restore':
m.restore.get_concrete_function(),
})
# Convert the model
converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL_DIR)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TensorFlow Lite ops.
tf.lite.OpsSet.SELECT_TF_OPS # enable TensorFlow ops.
]
converter.experimental_enable_resource_variables = True
tflite_model = converter.convert()
设置 TensorFlow Lite 签名
您在上一步中保存的 TensorFlow Lite 模型包含多个函数签名。您可以通过 tf.lite.Interpreter 类访问它们,并分别调用每个 restore、train、save 和 infer 签名。
interpreter = tf.lite.Interpreter(model_content=tflite_model)
interpreter.allocate_tensors()
infer = interpreter.get_signature_runner("infer")
比较原始模型和转换后的 Lite 模型的输出
logits_original = m.infer(x=train_images[:1])['logits'][0]
logits_lite = infer(x=train_images[:1])['logits'][0]
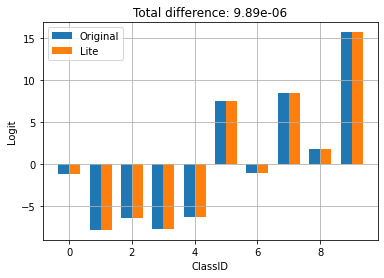
在上面,您可以看到模型的行为并没有因为转换为 TFLite 而改变。
在设备上重新训练模型
将模型转换为 TensorFlow Lite 并将其与您的应用程序一起部署后,您可以使用新数据和模型的 train 签名方法在设备上重新训练模型。每次训练运行都会生成一组新的权重,您可以将其保存以供重复使用和进一步改进模型,如下一节所示。
在 Android 上,您可以使用 Java 或 C++ API 使用 TensorFlow Lite 执行设备上训练。在 Java 中,使用 Interpreter 类加载模型并驱动模型训练任务。以下示例展示了如何使用 runSignature 方法运行训练过程
try (Interpreter interpreter = new Interpreter(modelBuffer)) {
int NUM_EPOCHS = 100;
int BATCH_SIZE = 100;
int IMG_HEIGHT = 28;
int IMG_WIDTH = 28;
int NUM_TRAININGS = 60000;
int NUM_BATCHES = NUM_TRAININGS / BATCH_SIZE;
List<FloatBuffer> trainImageBatches = new ArrayList<>(NUM_BATCHES);
List<FloatBuffer> trainLabelBatches = new ArrayList<>(NUM_BATCHES);
// Prepare training batches.
for (int i = 0; i < NUM_BATCHES; ++i) {
FloatBuffer trainImages = FloatBuffer.allocateDirect(BATCH_SIZE * IMG_HEIGHT * IMG_WIDTH).order(ByteOrder.nativeOrder());
FloatBuffer trainLabels = FloatBuffer.allocateDirect(BATCH_SIZE * 10).order(ByteOrder.nativeOrder());
// Fill the data values...
trainImageBatches.add(trainImages.rewind());
trainImageLabels.add(trainLabels.rewind());
}
// Run training for a few steps.
float[] losses = new float[NUM_EPOCHS];
for (int epoch = 0; epoch < NUM_EPOCHS; ++epoch) {
for (int batchIdx = 0; batchIdx < NUM_BATCHES; ++batchIdx) {
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", trainImageBatches.get(batchIdx));
inputs.put("y", trainLabelBatches.get(batchIdx));
Map<String, Object> outputs = new HashMap<>();
FloatBuffer loss = FloatBuffer.allocate(1);
outputs.put("loss", loss);
interpreter.runSignature(inputs, outputs, "train");
// Record the last loss.
if (batchIdx == NUM_BATCHES - 1) losses[epoch] = loss.get(0);
}
// Print the loss output for every 10 epochs.
if ((epoch + 1) % 10 == 0) {
System.out.println(
"Finished " + (epoch + 1) + " epochs, current loss: " + loss.get(0));
}
}
// ...
}
您可以在 模型个性化演示应用程序 中看到模型重新训练在 Android 应用程序中的完整代码示例。
运行训练几个 epoch 以改进或个性化模型。在实践中,您将使用在设备上收集的数据运行此附加训练。为简单起见,此示例使用与先前训练步骤相同的训练数据。
train = interpreter.get_signature_runner("train")
NUM_EPOCHS = 50
BATCH_SIZE = 100
more_epochs = np.arange(epochs[-1]+1, epochs[-1] + NUM_EPOCHS + 1, 1)
more_losses = np.zeros([NUM_EPOCHS])
for i in range(NUM_EPOCHS):
for x,y in train_ds:
result = train(x=x, y=y)
more_losses[i] = result['loss']
if (i + 1) % 10 == 0:
print(f"Finished {i+1} epochs")
print(f" loss: {more_losses[i]:.3f}")
Finished 10 epochs loss: 0.223 Finished 20 epochs loss: 0.216 Finished 30 epochs loss: 0.210 Finished 40 epochs loss: 0.204 Finished 50 epochs loss: 0.198
plt.plot(epochs, losses, label='Pre-training')
plt.plot(more_epochs, more_losses, label='On device')
plt.ylim([0, max(plt.ylim())])
plt.xlabel('Epoch')
plt.ylabel('Loss [Cross Entropy]')
plt.legend();
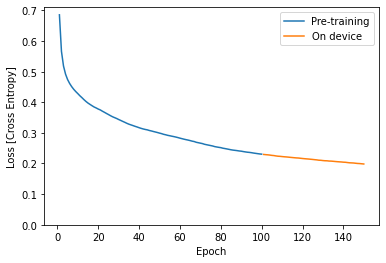
在上面,您可以看到设备上训练从预训练停止的地方继续。
保存训练后的权重
在您完成设备上的训练运行后,模型会更新它在内存中使用的权重集。使用您在 TensorFlow Lite 模型中创建的 save 签名方法,您可以将这些权重保存到检查点文件以供以后重复使用并改进您的模型。
save = interpreter.get_signature_runner("save")
save(checkpoint_path=np.array("/tmp/model.ckpt", dtype=np.string_))
{'checkpoint_path': array(b'/tmp/model.ckpt', dtype=object)}
在您的 Android 应用程序中,您可以将生成的权重作为检查点文件存储在为您的应用程序分配的内部存储空间中。
try (Interpreter interpreter = new Interpreter(modelBuffer)) {
// Conduct the training jobs.
// Export the trained weights as a checkpoint file.
File outputFile = new File(getFilesDir(), "checkpoint.ckpt");
Map<String, Object> inputs = new HashMap<>();
inputs.put("checkpoint_path", outputFile.getAbsolutePath());
Map<String, Object> outputs = new HashMap<>();
interpreter.runSignature(inputs, outputs, "save");
}
恢复训练后的权重
每次从 TFLite 模型创建解释器时,解释器最初都会加载原始模型权重。
因此,在您完成一些训练并保存检查点文件后,您需要运行 restore 签名方法来加载检查点。
一个好的规则是“每次您为模型创建解释器时,如果检查点存在,请加载它”。如果您需要将模型重置为基线行为,只需删除检查点并创建一个新的解释器。
another_interpreter = tf.lite.Interpreter(model_content=tflite_model)
another_interpreter.allocate_tensors()
infer = another_interpreter.get_signature_runner("infer")
restore = another_interpreter.get_signature_runner("restore")
logits_before = infer(x=train_images[:1])['logits'][0]
# Restore the trained weights from /tmp/model.ckpt
restore(checkpoint_path=np.array("/tmp/model.ckpt", dtype=np.string_))
logits_after = infer(x=train_images[:1])['logits'][0]
compare_logits({'Before': logits_before, 'After': logits_after})
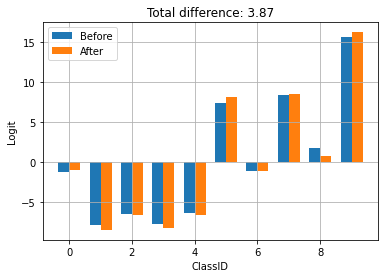
检查点是通过使用 TFLite 进行训练和保存生成的。在上面,您可以看到应用检查点会更新模型的行为。
在您的 Android 应用程序中,您可以从之前存储的检查点文件恢复序列化后的训练权重。
try (Interpreter anotherInterpreter = new Interpreter(modelBuffer)) {
// Load the trained weights from the checkpoint file.
File outputFile = new File(getFilesDir(), "checkpoint.ckpt");
Map<String, Object> inputs = new HashMap<>();
inputs.put("checkpoint_path", outputFile.getAbsolutePath());
Map<String, Object> outputs = new HashMap<>();
anotherInterpreter.runSignature(inputs, outputs, "restore");
}
使用训练后的权重运行推断
从检查点文件加载之前保存的权重后,运行 infer 方法会将这些权重与您的原始模型一起使用以改进预测。加载保存的权重后,您可以使用 infer 签名方法,如下所示。
infer = another_interpreter.get_signature_runner("infer")
result = infer(x=test_images)
predictions = np.argmax(result["output"], axis=1)
true_labels = np.argmax(test_labels, axis=1)
result['output'].shape
(10000, 10)
绘制预测的标签。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
def plot(images, predictions, true_labels):
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(images[i], cmap=plt.cm.binary)
color = 'b' if predictions[i] == true_labels[i] else 'r'
plt.xlabel(class_names[predictions[i]], color=color)
plt.show()
plot(test_images, predictions, true_labels)

predictions.shape
(10000,)
在您的 Android 应用程序中,在恢复训练后的权重后,根据加载的数据运行推断。
try (Interpreter anotherInterpreter = new Interpreter(modelBuffer)) {
// Restore the weights from the checkpoint file.
int NUM_TESTS = 10;
FloatBuffer testImages = FloatBuffer.allocateDirect(NUM_TESTS * 28 * 28).order(ByteOrder.nativeOrder());
FloatBuffer output = FloatBuffer.allocateDirect(NUM_TESTS * 10).order(ByteOrder.nativeOrder());
// Fill the test data.
// Run the inference.
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", testImages.rewind());
Map<String, Object> outputs = new HashMap<>();
outputs.put("output", output);
anotherInterpreter.runSignature(inputs, outputs, "infer");
output.rewind();
// Process the result to get the final category values.
int[] testLabels = new int[NUM_TESTS];
for (int i = 0; i < NUM_TESTS; ++i) {
int index = 0;
for (int j = 1; j < 10; ++j) {
if (output.get(i * 10 + index) < output.get(i * 10 + j)) index = testLabels[j];
}
testLabels[i] = index;
}
}
恭喜!您现在已经构建了一个支持设备上训练的 TensorFlow Lite 模型。有关更多编码详细信息,请查看 模型个性化演示应用程序 中的示例实现。
如果您有兴趣了解更多关于图像分类的信息,请查看 TensorFlow 官方指南页面中的 Keras 分类教程。本教程基于该练习,并提供了关于分类主题的更多深度。