
TensorFlow Lite 元数据提供了一种模型描述标准。元数据是了解模型功能及其输入/输出信息的重要知识来源。元数据包含
- 人可读部分,用于传达使用模型时的最佳实践,以及
- 机器可读部分,可供代码生成器使用,例如 TensorFlow Lite Android 代码生成器 和 Android Studio ML 绑定功能。
在 TensorFlow Hub 上发布的所有图像模型都已填充了元数据。
带元数据的模型格式
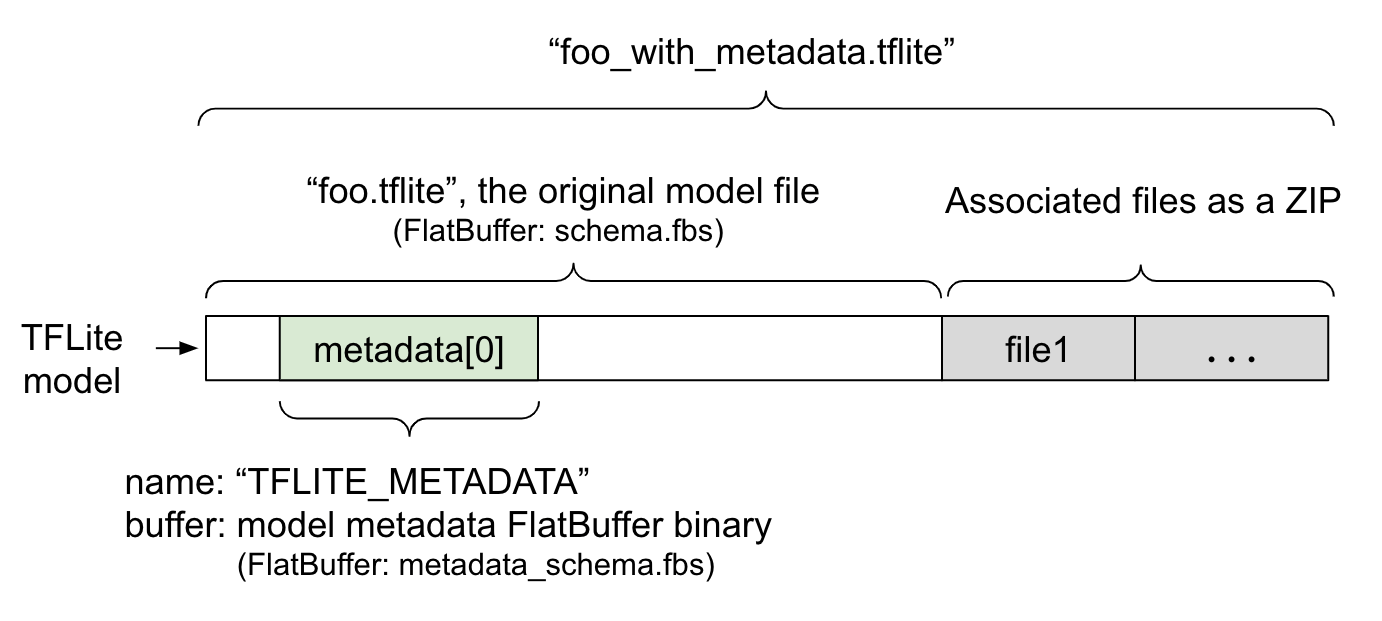
模型元数据在 metadata_schema.fbs 中定义,这是一个 FlatBuffer 文件。如图 1 所示,它存储在 metadata 字段中,该字段位于 TFLite 模型架构 下,名称为 "TFLITE_METADATA"。某些模型可能附带关联文件,例如 分类标签文件。这些文件使用 ZipFile "追加" 模式 ('a' 模式) 与原始模型文件连接在一起,形成一个 ZIP 文件。TFLite 解释器可以像以前一样使用这种新的文件格式。有关更多信息,请参阅 打包关联文件。
请参阅以下关于如何填充、可视化和读取元数据的说明。
设置元数据工具
在将元数据添加到模型之前,您需要为运行 TensorFlow 设置 Python 编程环境。有关如何设置此环境的详细指南,请访问 此处。
在设置好 Python 编程环境后,您需要安装额外的工具。
pip install tflite-support
TensorFlow Lite 元数据工具支持 Python 3。
使用 Flatbuffers Python API 添加元数据
模型元数据在 模式 中包含三个部分。
- 模型信息 - 模型的总体描述以及许可条款等项目。请参阅 ModelMetadata。
- 输入信息 - 输入的描述以及所需的预处理,例如规范化。请参阅 SubGraphMetadata.input_tensor_metadata。
- 输出信息 - 输出的描述以及所需的后期处理,例如映射到标签。请参阅 SubGraphMetadata.output_tensor_metadata。
由于 TensorFlow Lite 目前仅支持单个子图,因此 TensorFlow Lite 代码生成器 和 Android Studio ML 绑定功能 将使用 ModelMetadata.name 和 ModelMetadata.description,而不是 SubGraphMetadata.name 和 SubGraphMetadata.description,来显示元数据和生成代码。
支持的输入/输出类型
TensorFlow Lite 元数据针对输入和输出而设计,而不是针对特定模型类型。无论模型的功能如何,只要输入和输出类型包含以下类型或其组合,TensorFlow Lite 元数据就支持它。
- 特征 - 无符号整数或 float32 的数字。
- 图像 - 元数据目前支持 RGB 和灰度图像。
- 边界框 - 矩形形状的边界框。该模式支持 各种编号方案。
打包关联文件
TensorFlow Lite 模型可能附带不同的关联文件。例如,自然语言模型通常具有将词片段映射到词 ID 的词汇文件;分类模型可能具有指示对象类别的标签文件。如果没有关联文件(如果有),模型将无法正常运行。
现在可以通过元数据 Python 库将关联文件捆绑到模型中。新的 TensorFlow Lite 模型成为一个包含模型和关联文件的 zip 文件。它可以使用常见的 zip 工具解压缩。这种新的模型格式继续使用相同的扩展名 .tflite。它与现有的 TFLite 框架和解释器兼容。有关更多详细信息,请参阅 将元数据和关联文件打包到模型中。
关联文件信息可以记录在元数据中。根据文件类型和文件附加的位置(即 ModelMetadata、SubGraphMetadata 和 TensorMetadata),TensorFlow Lite Android 代码生成器 可能会自动对对象应用相应的预/后处理。有关更多详细信息,请参阅模式中 每个关联文件类型的“代码生成使用情况”部分。
规范化和量化参数
规范化是机器学习中一种常见的预处理技术。规范化的目标是将值更改为通用比例,而不会扭曲值范围的差异。
模型量化 是一种技术,它允许对权重进行精度降低的表示,并且可选地对存储和计算的激活进行精度降低的表示。
在预处理和后期处理方面,规范化和量化是两个独立的步骤。以下是详细信息。
| 规范化 | 量化 | |
|---|---|---|
MobileNet 中输入图像的参数值示例,分别用于浮点模型和量化模型。 |
浮点模型: - 均值:127.5 - 标准差:127.5 量化模型: - 均值:127.5 - 标准差:127.5 |
浮点模型: - 零点:0 - 比例:1.0 量化模型: - 零点:128.0 - 比例:0.0078125f |
何时调用? |
输入:如果在训练中对输入数据进行了规范化,则推断的输入数据需要相应地进行规范化。 输出:输出数据通常不会被规范化。 |
浮点模型不需要量化。 量化模型可能需要也可能不需要在预/后处理中进行量化。这取决于输入/输出张量的类型。 - 浮点张量:预/后处理中不需要量化。量化运算符和反量化运算符已烘焙到模型图中。 - int8/uint8 张量:预/后处理中需要量化。 |
公式 |
normalized_input = (input - mean) / std |
对输入进行量化:
q = f / scale + zeroPoint 对输出进行反量化: f = (q - zeroPoint) * scale |
参数在哪里 |
由模型创建者填充并存储在模型元数据中,作为 NormalizationOptions |
由 TFLite 转换器自动填充,并存储在 tflite 模型文件中。 |
| 如何获取参数? | 通过 MetadataExtractor API [2] |
通过 TFLite Tensor API [1] 或通过 MetadataExtractor API [2] |
| 浮点模型和量化模型是否共享相同的值? | 是的,浮点模型和量化模型具有相同的规范化参数。 | 否,浮点模型不需要量化。 |
| TFLite 代码生成器或 Android Studio ML 绑定是否会在数据处理中自动生成它? | 是的 |
是的 |
[1] TensorFlow Lite Java API 和 TensorFlow Lite C++ API。
[2] 元数据提取器库
在处理 uint8 模型的图像数据时,有时会跳过规范化和量化。当像素值在 [0, 255] 范围内时,这样做是可以的。但总的来说,您应该始终根据规范化和量化参数(如果适用)处理数据。
TensorFlow Lite 任务库 可以为您处理规范化,前提是在元数据中设置了 NormalizationOptions。量化和反量化处理始终被封装。
示例
您可以在此处找到有关如何为不同类型的模型填充元数据的示例。
图像分类
从 此处 下载脚本,该脚本将元数据填充到 mobilenet_v1_0.75_160_quantized.tflite 中。像这样运行脚本
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
要为其他图像分类模型填充元数据,请将模型规格(如 此)添加到脚本中。本指南的其余部分将重点介绍图像分类示例中的一些关键部分,以说明关键元素。
深入了解图像分类示例
模型信息
元数据首先创建一个新的模型信息
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"https://apache.ac.cn/licenses/LICENSE-2.0.")
输入/输出信息
本节向您展示如何描述模型的输入和输出签名。此元数据可供自动代码生成器使用,以创建预处理和后期处理代码。要创建有关张量的输入或输出信息
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
图像输入
图像是一种常见的机器学习输入类型。TensorFlow Lite 元数据支持诸如颜色空间和预处理信息(例如规范化)等信息。图像的维度不需要手动指定,因为它已由输入张量的形状提供,并且可以自动推断。
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
标签输出
标签可以通过关联文件使用 TENSOR_AXIS_LABELS 映射到输出张量。
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
创建元数据 Flatbuffers
以下代码将模型信息与输入和输出信息结合在一起
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
将元数据和关联文件打包到模型中
创建元数据 Flatbuffers 后,元数据和标签文件将通过 populate 方法写入 TFLite 文件。
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
您可以通过 load_associated_files 将任意数量的关联文件打包到模型中。但是,必须至少打包元数据中记录的那些文件。在本例中,打包标签文件是强制性的。
可视化元数据
您可以使用 Netron 可视化您的元数据,或者您可以使用 MetadataDisplayer 将元数据从 TensorFlow Lite 模型读取到 json 格式。
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio 还支持通过 Android Studio ML 绑定功能 显示元数据。
元数据版本控制
元数据模式 通过语义版本控制号(跟踪模式文件的更改)和 Flatbuffers 文件标识(指示真正的版本兼容性)进行版本控制。
语义版本控制号
元数据模式通过 语义版本控制号(例如 MAJOR.MINOR.PATCH)进行版本控制。它根据 此处 的规则跟踪模式更改。请参阅 版本 1.0.0 后添加的字段历史记录。
Flatbuffers 文件标识
语义版本控制 (Semantic Versioning) 通过遵循规则来保证兼容性,但它并不意味着真正的兼容性。当主版本号 (MAJOR) 递增时,并不一定意味着向后兼容性被破坏。因此,我们使用 [Flatbuffers 文件标识](https://ggdocs.cn/flatbuffers/md__schemas.html) 和 [file_identifier](https://github.com/tensorflow/tflite-support/blob/4cd0551658b6e26030e0ba7fc4d3127152e0d4ae/tensorflow_lite_support/metadata/metadata_schema.fbs#L61) 来表示元数据模式的真正兼容性。文件标识符长度固定为 4 个字符,它与特定的元数据模式绑定,用户无法修改。如果由于某些原因需要破坏元数据模式的向后兼容性,则 file_identifier 会递增,例如从 "M001" 递增到 "M002"。预计 file_identifier 的更改频率远低于 metadata_version 的更改频率。
最低必需的元数据解析器版本
[最低必需的元数据解析器版本](https://github.com/tensorflow/tflite-support/blob/4cd0551658b6e26030e0ba7fc4d3127152e0d4ae/tensorflow_lite_support/metadata/metadata_schema.fbs#L681) 是能够完整读取元数据 Flatbuffers 的最低元数据解析器版本(Flatbuffers 生成的代码)。该版本实际上是所有填充字段的版本号中的最大值,以及文件标识符指示的最小兼容版本。最低必需的元数据解析器版本由 `MetadataPopulator` 在将元数据填充到 TFLite 模型时自动填充。有关如何使用最低必需的元数据解析器版本的更多信息,请参阅 [元数据提取器](https://github.com/tensorflow/tflite-support/blob/4cd0551658b6e26030e0ba7fc4d3127152e0d4ae/tensorflow_lite_support/metadata/metadata_schema.fbs#L681)。
从模型中读取元数据
元数据提取器库是一个方便的工具,用于从不同平台的模型中读取元数据和关联文件(请参阅 [Java 版本](https://github.com/tensorflow/tflite-support/tree/master/tensorflow_lite_support/metadata/java) 和 [C++ 版本](https://github.com/tensorflow/tflite-support/tree/master/tensorflow_lite_support/metadata/cc))。您可以使用 Flatbuffers 库在其他语言中构建自己的元数据提取器工具。
在 Java 中读取元数据
要在您的 Android 应用程序中使用元数据提取器库,建议使用 [MavenCentral 上托管的 TensorFlow Lite Metadata AAR](https://search.maven.org/artifact/org.tensorflow/tensorflow-lite-metadata)。它包含 `MetadataExtractor` 类,以及用于 [元数据模式](https://github.com/tensorflow/tflite-support/blob/master/tensorflow_lite_support/metadata/metadata_schema.fbs) 和 [模型模式](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/schema/schema.fbs) 的 Flatbuffers Java 绑定。
您可以在 `build.gradle` 依赖项中指定如下:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
要使用 nightly 快照,请确保您已添加 [Sonatype 快照存储库](https://tensorflowcn.cn/lite/android/lite_build#use_nightly_snapshots)。
您可以使用指向模型的 `ByteBuffer` 初始化 `MetadataExtractor` 对象:
public MetadataExtractor(ByteBuffer buffer);
`ByteBuffer` 在 `MetadataExtractor` 对象的整个生命周期内必须保持不变。如果模型元数据的 Flatbuffers 文件标识符与元数据解析器的文件标识符不匹配,则初始化可能会失败。有关更多信息,请参阅 [元数据版本控制](https://github.com/tensorflow/tflite-support/blob/4cd0551658b6e26030e0ba7fc4d3127152e0d4ae/tensorflow_lite_support/metadata/metadata_schema.fbs#L61)。
如果文件标识符匹配,元数据提取器将成功读取从所有过去和未来模式生成的元数据,因为 Flatbuffers 具有向前和向后兼容机制。但是,较旧的元数据提取器无法提取来自未来模式的字段。元数据的 [最低必需解析器版本](https://github.com/tensorflow/tflite-support/blob/4cd0551658b6e26030e0ba7fc4d3127152e0d4ae/tensorflow_lite_support/metadata/metadata_schema.fbs#L681) 指示能够完整读取元数据 Flatbuffers 的最低元数据解析器版本。您可以使用以下方法来验证是否满足最低必需解析器版本条件:
public final boolean isMinimumParserVersionSatisfied();
允许传递没有元数据的模型。但是,调用从元数据读取的方法会导致运行时错误。您可以通过调用 `hasMetadata` 方法来检查模型是否具有元数据:
public boolean hasMetadata();
`MetadataExtractor` 提供了方便的函数供您获取输入/输出张量的元数据。例如:
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
虽然 [TensorFlow Lite 模型模式](https://github.com/tensorflow/tensorflow/blob/aa7ff6aa28977826e7acae379e82da22482b2bf2/tensorflow/lite/schema/schema.fbs#L1075) 支持多个子图,但 TFLite 解释器目前仅支持单个子图。因此,`MetadataExtractor` 在其方法中省略了子图索引作为输入参数。
从模型中读取关联文件
具有元数据和关联文件的 TensorFlow Lite 模型本质上是一个 zip 文件,可以使用常见的 zip 工具解压缩以获取关联文件。例如,您可以解压缩 [mobilenet_v1_0.75_160_quantized](https://tfhub.dev/tensorflow/lite-model/mobilenet_v1_0.75_160_quantized/1/metadata/1) 并提取模型中的标签文件,如下所示:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
您也可以通过元数据提取器库读取关联文件。
在 Java 中,将文件名传递到 `MetadataExtractor.getAssociatedFile` 方法中:
public InputStream getAssociatedFile(String fileName);
类似地,在 C++ 中,可以使用 `ModelMetadataExtractor::GetAssociatedFile` 方法:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;