
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
个性化推荐广泛用于移动设备上的各种用例,例如媒体内容检索、购物产品建议和下一个应用程序推荐。如果您有兴趣在您的应用程序中提供个性化推荐,同时尊重用户隐私,我们建议您探索以下示例和工具包。
入门
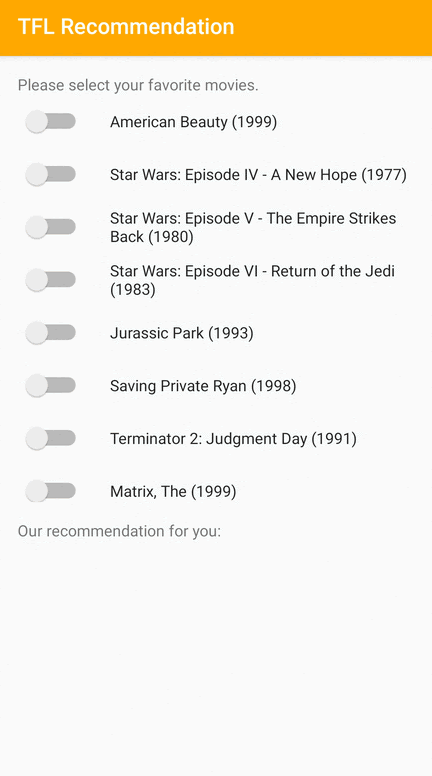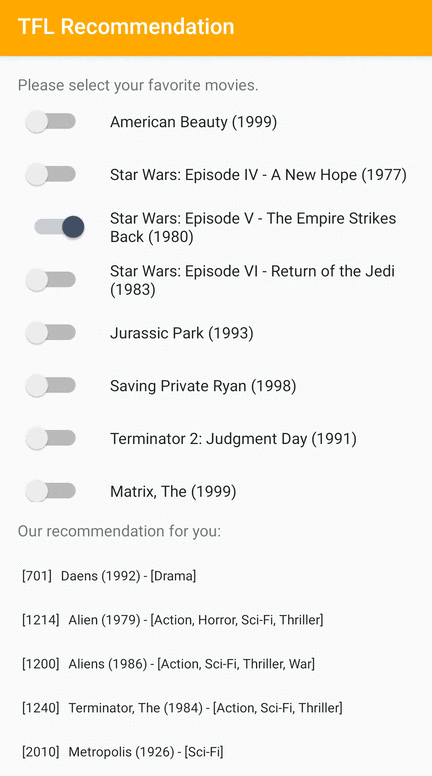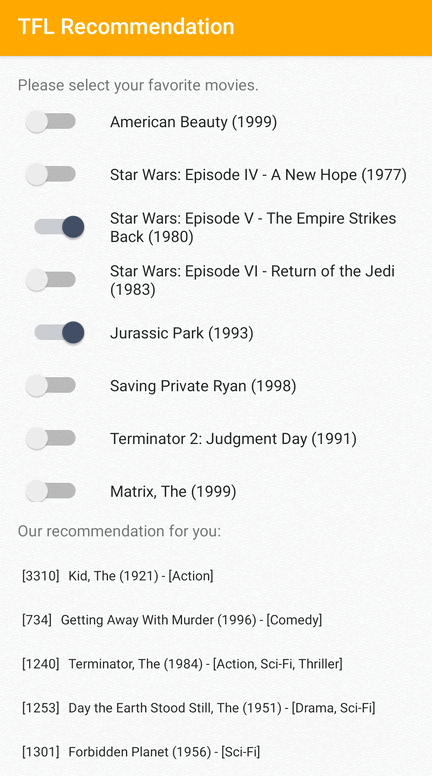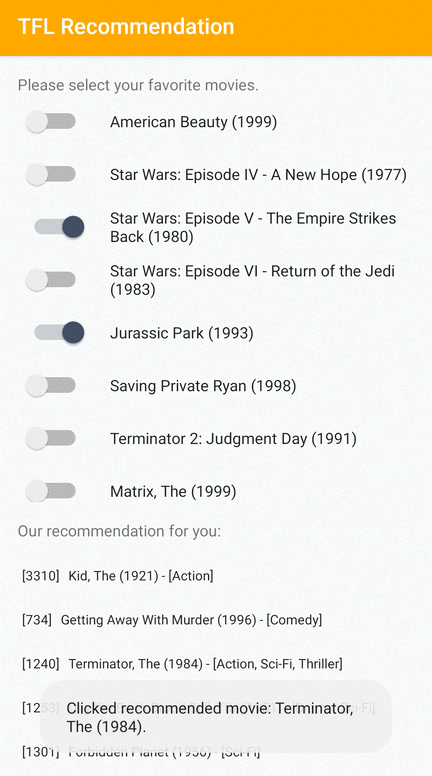
我们提供了一个 TensorFlow Lite 示例应用程序,演示了如何在 Android 上向用户推荐相关项目。
如果您使用的是 Android 以外的平台,或者您已经熟悉 TensorFlow Lite API,您可以下载我们的推荐模型入门程序。
我们还在 Github 中提供训练脚本,以便以可配置的方式训练您自己的模型。
了解模型架构
我们利用双编码器模型架构,使用上下文编码器来编码顺序用户历史记录,并使用标签编码器来编码预测的推荐候选。上下文和标签编码之间的相似性用于表示预测的候选满足用户需求的可能性。
此代码库提供了三种不同的顺序用户历史记录编码技术
- 词袋编码器 (BOW):平均用户活动的嵌入,不考虑上下文顺序。
- 卷积神经网络编码器 (CNN):应用多层卷积神经网络来生成上下文编码。
- 循环神经网络编码器 (RNN):应用循环神经网络来编码上下文序列。
为了对每个用户活动进行建模,我们可以使用活动项目的 ID(基于 ID),或项目的多个特征(基于特征),或两者的组合。基于特征的模型利用多个特征来共同编码用户的行为。使用此代码库,您可以以可配置的方式创建基于 ID 或基于特征的模型。
训练后,将导出一个 TensorFlow Lite 模型,该模型可以直接在推荐候选者中提供前 K 个预测。
使用您的训练数据
除了训练模型之外,我们还提供了一个开源的 GitHub 中的工具包,用于使用您自己的数据训练模型。您可以按照本教程学习如何使用该工具包并在您自己的移动应用程序中部署训练模型。
请按照此 教程 将此处使用的相同技术应用于使用您自己的数据集训练推荐模型。
示例
例如,我们使用基于 ID 和基于特征的方法训练了推荐模型。基于 ID 的模型仅将电影 ID 作为输入,而基于特征的模型将电影 ID 和电影类型 ID 作为输入。请找到以下输入和输出示例。
输入
上下文电影 ID
- 狮子王 (ID: 362)
- 玩具总动员 (ID: 1)
- (等等)
上下文电影类型 ID
- 动画 (ID: 15)
- 儿童 (ID: 9)
- 音乐 (ID: 13)
- 动画 (ID: 15)
- 儿童 (ID: 9)
- 喜剧 (ID: 2)
- (等等)
输出
- 推荐电影 ID
- 玩具总动员 2 (ID: 3114)
- (等等)
性能基准
性能基准数字是使用 此处描述的工具 生成的。
| 模型名称 | 模型大小 | 设备 | CPU |
|---|---|---|---|
| 推荐(电影 ID 作为输入) | 0.52 Mb | Pixel 3 | 0.09ms* |
| Pixel 4 | 0.05ms* | ||
| 推荐(电影 ID 和电影类型作为输入) | 1.3 Mb | Pixel 3 | 0.13ms* |
| Pixel 4 | 0.06ms* |
* 使用了 4 个线程。
使用您的训练数据
除了训练模型之外,我们还提供了一个开源的 GitHub 中的工具包,用于使用您自己的数据训练模型。您可以按照本教程学习如何使用该工具包并在您自己的移动应用程序中部署训练模型。
请按照此 教程 将此处使用的相同技术应用于使用您自己的数据集训练推荐模型。
使用您的数据自定义模型的技巧
此演示应用程序中集成的预训练模型是使用 MovieLens 数据集训练的,您可能希望根据您自己的数据修改模型配置,例如词汇量大小、嵌入维度和输入上下文长度。以下是一些技巧
输入上下文长度:最佳输入上下文长度因数据集而异。我们建议根据标签事件与长期兴趣的相关性与短期上下文的相关性来选择输入上下文长度。
编码器类型选择:我们建议根据输入上下文长度选择编码器类型。词袋编码器适用于较短的输入上下文长度(例如,<10),CNN 和 RNN 编码器在较长的输入上下文长度下具有更强的摘要能力。
使用底层特征来表示项目或用户活动可以提高模型性能,更好地适应新项目,可能缩小嵌入空间,从而减少内存消耗,更适合在设备上使用。