
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
本教程探讨了部分本地联合学习,其中一些客户端参数永远不会在服务器上聚合。这对于具有用户特定参数的模型(例如矩阵分解模型)以及在通信受限环境中进行训练很有用。我们基于 用于图像分类的联合学习 教程中介绍的概念;与该教程一样,我们介绍了 tff.learning 中用于联合训练和评估的高级 API。
我们首先从为 矩阵分解 激励部分本地联合学习开始。我们描述了联合重建 (论文,博客文章),这是一种实用的算法,可用于大规模部分本地联合学习。我们准备 MovieLens 1M 数据集,构建部分本地模型,并对其进行训练和评估。
!pip install --quiet --upgrade tensorflow-federated
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
背景:矩阵分解
矩阵分解 一直是学习推荐和基于用户交互为项目嵌入表示的流行技术。典型的例子是电影推荐,其中有 \(n\) 个用户和 \(m\) 部电影,用户对一些电影进行了评分。给定一个用户,我们使用他们的评分历史记录和类似用户的评分来预测用户对他们未看过的电影的评分。如果我们有一个可以预测评分的模型,那么很容易向用户推荐他们会喜欢的新的电影。
对于此任务,将用户的评分表示为 \(n \times m\) 矩阵 \(R\) 很有用

此矩阵通常是稀疏的,因为用户通常只观看数据集中一小部分电影。矩阵分解的输出是两个矩阵:一个 \(n \times k\) 矩阵 \(U\),表示每个用户的 \(k\) 维用户嵌入,以及一个 \(m \times k\) 矩阵 \(I\),表示每个项目的 \(k\) 维项目嵌入。最简单的训练目标是确保用户和项目嵌入的点积可以预测观察到的评分 \(O\)
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
这等效于最小化观察到的评分与通过取相应用户和项目嵌入的点积预测的评分之间的均方误差。另一种解释方式是,这确保了 \(R \approx UI^T\) 适用于已知评分,因此称为“矩阵分解”。如果这令人困惑,别担心 - 我们不需要了解本教程其余部分的矩阵分解的详细信息。
探索 MovieLens 数据
让我们从加载 MovieLens 1M 数据开始,该数据包含 6040 个用户对 3706 部电影的 1,000,209 个电影评分。
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python",
encoding = "ISO-8859-1")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
让我们加载并探索几个包含评分和电影数据的 Pandas DataFrame。
ratings_df, movies_df = load_movielens_data()
我们可以看到,每个评分示例都有一个 1-5 的评分,一个相应的 UserID,一个相应的 MovieID 和一个时间戳。
ratings_df.head()
每部电影都有一个标题,可能有多个类型。
movies_df.head()
了解数据集的基本统计信息总是一个好主意
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
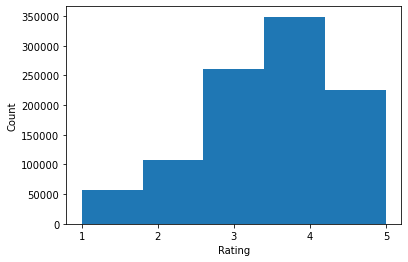
Average rating: 3.581564453029317 Median rating: 4.0
我们还可以绘制最受欢迎的电影类型。
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
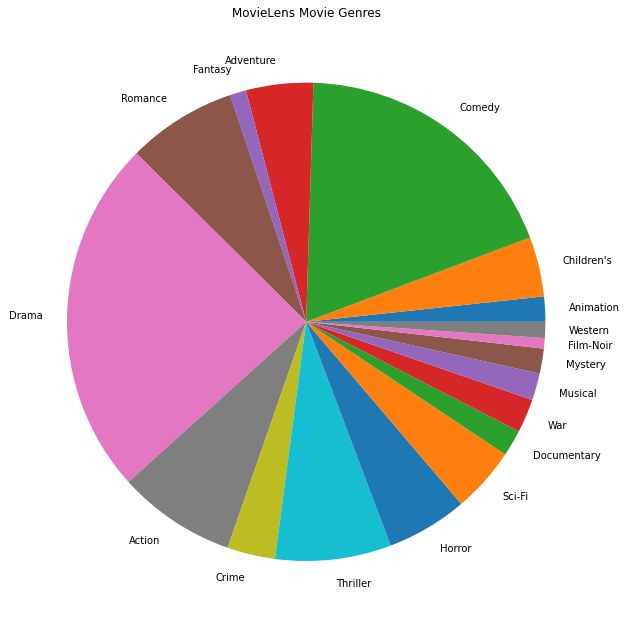
此数据自然地划分为来自不同用户的评分,因此我们预计客户端之间的数据存在一些异质性。下面我们显示了不同用户最常评分的电影类型。我们可以观察到用户之间存在显著差异。
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
预处理 MovieLens 数据
我们现在将准备 MovieLens 数据集作为 tf.data.Dataset 的列表,表示每个用户的用于 TFF 的数据。
我们实现了两个函数
create_tf_datasets:接受我们的评分 DataFrame 并生成一个用户拆分的tf.data.Dataset列表。split_tf_datasets: 将数据集列表拆分为训练集/验证集/测试集,按用户拆分,因此验证集/测试集仅包含训练期间未见用户的评分。通常在标准的集中式矩阵分解中,我们实际上会进行拆分,以便验证集/测试集包含来自已见用户的保留评分,因为未见用户没有用户嵌入。在我们的案例中,我们将在后面看到,我们用于在 FL 中启用矩阵分解的方法也能够快速重建未见用户的用户嵌入。
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
作为快速检查,我们可以打印一批训练数据。我们可以看到,每个单独的示例在 "x" 键下包含一个 MovieID,在 "y" 键下包含一个评分。请注意,我们不需要 UserID,因为每个用户只看到他们自己的数据。
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
我们可以绘制一个直方图,显示每个用户的评分数量。
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()

现在我们已经加载并探索了数据,我们将讨论如何将矩阵分解引入联邦学习。在此过程中,我们将激励部分本地联邦学习。
将矩阵分解引入 FL
虽然矩阵分解传统上用于集中式环境,但它在联邦学习中尤其重要:用户评分可能存在于不同的客户端设备上,我们可能希望学习用户和项目的嵌入和推荐,而无需集中数据。由于每个用户都有一个对应的用户嵌入,因此让每个客户端存储他们的用户嵌入是自然的——这比中央服务器存储所有用户嵌入的扩展性要好得多。
将矩阵分解引入 FL 的一个提议如下
- 服务器存储并向每轮采样的客户端发送项目矩阵 \(I\)
- 客户端使用 SGD 更新项目矩阵和他们个人用户嵌入 \(U_u\),使用上述目标函数
- 对 \(I\) 的更新在服务器上进行聚合,更新服务器的 \(I\) 副本,用于下一轮
这种方法是部分本地的——也就是说,一些客户端参数从未被服务器聚合。虽然这种方法很有吸引力,但它要求客户端在各轮之间维护状态,即他们的用户嵌入。有状态的联邦算法不太适合跨设备 FL 设置:在这些设置中,总体规模通常远大于每轮参与的客户端数量,并且客户端通常在训练过程中最多参与一次。除了依赖可能未初始化的状态之外,有状态的算法还会导致跨设备设置中的性能下降,因为当客户端很少被采样时,状态会变得陈旧。重要的是,在矩阵分解设置中,有状态的算法会导致所有未见客户端丢失训练过的用户嵌入,在大规模训练中,大多数用户可能是未见的。有关跨设备 FL 中无状态算法动机的更多信息,请参阅 Wang 等人 2021 年第 3.1.1 节 和 Reddi 等人 2020 年第 5.1 节。
联邦重建 (Singhal 等人 2021 年) 是上述方法的一种无状态替代方案。关键思想是,客户端在需要时重建用户嵌入,而不是在各轮之间存储用户嵌入。当 FedRecon 应用于矩阵分解时,训练过程如下
- 服务器存储并向每轮采样的客户端发送项目矩阵 \(I\)
- 每个客户端冻结 \(I\) 并使用一到多个 SGD 步训练他们的用户嵌入 \(U_u\)(重建)
- 每个客户端冻结 \(U_u\) 并使用一到多个 SGD 步训练 \(I\)
- 对 \(I\) 的更新在用户之间进行聚合,更新服务器的 \(I\) 副本,用于下一轮
这种方法不需要客户端在各轮之间维护状态。作者还在论文中表明,这种方法可以快速重建未见客户端的用户嵌入(第 4.2 节、图 3 和表 1),使大多数未参与训练的客户端拥有训练过的模型,从而为这些客户端提供推荐。有关更多关键结果,请参阅联邦重建 Google AI 博客文章。
定义模型
接下来,我们将定义要在客户端设备上训练的本地矩阵分解模型。该模型将包含完整的项目矩阵 \(I\) 和客户端 \(u\) 的单个用户嵌入 \(U_u\)。请注意,客户端不需要存储完整的用户矩阵 \(U\)。
我们将定义以下内容
UserEmbedding: 一个简单的 Keras 层,表示单个num_latent_factors维用户嵌入。get_matrix_factorization_model: 一个函数,返回一个tff.learning.models.ReconstructionModel,其中包含模型逻辑,包括哪些层在服务器上全局聚合,哪些层保持本地。我们需要这些额外信息来初始化联邦重建训练过程。在这里,我们使用tff.learning.models.ReconstructionModel.from_keras_model_and_layers从 Keras 模型生成tff.learning.models.ReconstructionModel。类似于tff.learning.models.VariableModel,我们也可以通过实现类接口来实现自定义tff.learning.models.ReconstructionModel。
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.models.ReconstructionModel:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.models.ReconstructionModel.from_keras_model_and_layers`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.models.ReconstructionModel.from_keras_model_and_layers(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
与联邦平均接口类似,联邦重建接口期望一个没有参数的 model_fn,它返回一个 tff.learning.models.ReconstructionModel。
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
接下来,我们将定义 loss_fn 和 metrics_fn,其中 loss_fn 是一个没有参数的函数,返回一个用于训练模型的 Keras 损失,metrics_fn 是一个没有参数的函数,返回一个用于评估的 Keras 指标列表。这些是构建训练和评估计算所需的。
我们将使用均方误差作为损失,如上所述。对于评估,我们将使用评分准确度(当模型的预测点积四舍五入到最接近的整数时,它与标签评分匹配的频率是多少?)。
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
训练和评估
现在我们拥有定义训练过程所需的一切。与 联邦平均接口 的一个重要区别是,我们现在传入一个 reconstruction_optimizer_fn,它将在重建本地参数(在本例中为用户嵌入)时使用。通常,在这里使用 SGD 是合理的,其学习率与客户端优化器学习率相似或略低。我们在下面提供了一个可行的配置。这还没有经过仔细调整,因此您可以随意尝试不同的值。
查看 文档,了解有关更多详细信息和选项的信息。
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.algorithms.build_fed_recon(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
我们还可以定义一个用于评估我们训练过的全局模型的计算。
evaluation_process = tff.learning.algorithms.build_fed_recon_eval(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
我们可以初始化训练过程状态并检查它。最重要的是,我们可以看到,此服务器状态仅存储项目变量(当前随机初始化),而不存储任何用户嵌入。
state = training_process.initialize()
model = training_process.get_model_weights(state)
print(model)
print('Item variables shape:', model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.01839826, 0.04044249, -0.04871846, ..., 0.01967763,
-0.03034571, -0.01698984],
[-0.03716197, 0.0374358 , 0.00968184, ..., -0.04857936,
-0.0385102 , -0.01883975],
[-0.01227728, -0.04690691, 0.00250578, ..., 0.01141983,
0.01773251, 0.03525344],
...,
[ 0.03374172, 0.02467764, 0.00621947, ..., -0.01521915,
-0.01185555, 0.0295455 ],
[-0.04029766, -0.02826073, 0.0358924 , ..., -0.02519268,
-0.03909808, -0.01965014],
[-0.04007702, -0.04353172, 0.04063287, ..., 0.01851353,
-0.00767929, -0.00816654]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
我们还可以尝试在验证客户端上评估我们随机初始化的模型。这里的联邦重建评估涉及以下步骤
- 服务器将项目矩阵 \(I\) 发送给采样的评估客户端
- 每个客户端冻结 \(I\) 并使用一到多个 SGD 步训练他们的用户嵌入 \(U_u\)(重建)
- 每个客户端使用服务器 \(I\) 和重建的 \(U_u\) 在其本地数据的未见部分上计算损失和指标
- 损失和指标在用户之间进行平均,以计算总损失和指标
请注意,步骤 1 和 2 与训练相同。这种联系很重要,因为以与我们评估相同的方式进行训练会导致一种元学习形式,或者学习如何学习。在本例中,模型正在学习如何学习导致本地变量(用户嵌入)性能良好的重建的全局变量(项目矩阵)。有关更多信息,请参阅论文的 第 4.2 节。
步骤 2 和 3 使用客户端本地数据的不同部分执行也很重要,以确保公平评估。默认情况下,训练过程和评估计算都使用每隔一个示例进行重建,并使用另一半进行重建后使用。可以使用 dataset_split_fn 参数自定义此行为(我们将在后面进一步探讨)。
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_state = evaluation_process.initialize()
eval_state = evaluation_process.set_model_weights(
eval_state, training_process.get_model_weights(state)
)
_, eval_metrics = evaluation_process.next(eval_state, tf_val_datasets)
print('Initial Eval:', eval_metrics['client_work']['eval'])
Initial Eval: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.365454)])
接下来,我们可以尝试运行一轮训练。为了使事情更现实,我们将在每轮中随机抽取 50 个客户端,不放回。我们仍然应该期望训练指标很差,因为我们只进行了一轮训练。
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['client_work']['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.183293)])
现在让我们设置一个训练循环,以便在多轮中进行训练。
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['client_work']['train'])
train_losses.append(metrics['client_work']['train']['loss'])
train_accs.append(metrics['client_work']['train']['rating_accuracy'])
eval_state = evaluation_process.set_model_weights(
eval_state, training_process.get_model_weights(state))
_, eval_metrics = evaluation_process.next(eval_state, tf_val_datasets)
print('Final Eval:', eval_metrics['client_work']['eval'])
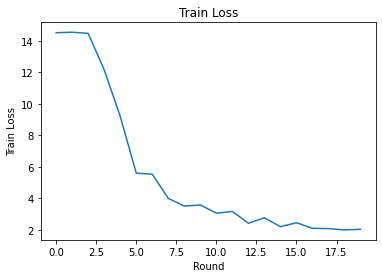
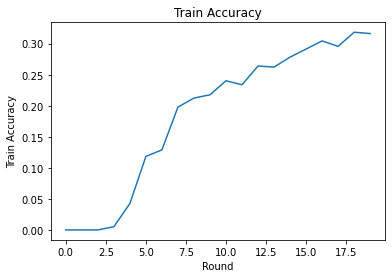
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.523704)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.552873)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.480412)])
Train round 3: OrderedDict([('rating_accuracy', 0.0051107327), ('loss', 12.155375)])
Train round 4: OrderedDict([('rating_accuracy', 0.042440318), ('loss', 9.201913)])
Train round 5: OrderedDict([('rating_accuracy', 0.11840491), ('loss', 5.5969186)])
Train round 6: OrderedDict([('rating_accuracy', 0.12890044), ('loss', 5.5303264)])
Train round 7: OrderedDict([('rating_accuracy', 0.19774501), ('loss', 3.9932375)])
Train round 8: OrderedDict([('rating_accuracy', 0.21234067), ('loss', 3.5070496)])
Train round 9: OrderedDict([('rating_accuracy', 0.21757619), ('loss', 3.5754187)])
Train round 10: OrderedDict([('rating_accuracy', 0.24020319), ('loss', 3.0558898)])
Train round 11: OrderedDict([('rating_accuracy', 0.2337753), ('loss', 3.1659348)])
Train round 12: OrderedDict([('rating_accuracy', 0.2638889), ('loss', 2.413888)])
Train round 13: OrderedDict([('rating_accuracy', 0.2622365), ('loss', 2.760038)])
Train round 14: OrderedDict([('rating_accuracy', 0.27820238), ('loss', 2.195349)])
Train round 15: OrderedDict([('rating_accuracy', 0.29124364), ('loss', 2.447856)])
Train round 16: OrderedDict([('rating_accuracy', 0.30438596), ('loss', 2.096729)])
Train round 17: OrderedDict([('rating_accuracy', 0.29557413), ('loss', 2.0750825)])
Train round 18: OrderedDict([('rating_accuracy', 0.31832394), ('loss', 1.99085)])
Train round 19: OrderedDict([('rating_accuracy', 0.3162333), ('loss', 2.0302613)])
Final Eval: OrderedDict([('rating_accuracy', 0.3126193), ('loss', 2.0305126)])
我们可以绘制各轮的训练损失和准确度。此笔记本中的超参数尚未经过仔细调整,因此您可以随意尝试不同的每轮客户端数量、学习率、轮数和总客户端数量,以改进这些结果。
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
最后,当我们完成调整后,可以在未见测试集上计算指标。
eval_state = evaluation_process.set_model_weights(
eval_state, training_process.get_model_weights(state)
)
_, eval_metrics = evaluation_process.next(eval_state, tf_test_datasets)
print('Final Test:', eval_metrics['client_work']['eval'])
Final Test: OrderedDict([('rating_accuracy', 0.3129535), ('loss', 1.9429641)])
进一步探索
完成此笔记本,干得好。我们建议您进行以下练习,以进一步探索部分本地联邦学习,大致按难度递增排序
联邦平均的典型实现对数据进行多次本地传递(轮次)(除了对数据进行一次跨多个批次的传递)。对于联邦重建,我们可能希望分别控制重建和重建后训练的步骤数量。将
dataset_split_fn参数传递给训练和评估计算构建器,可以控制重建和重建后数据集的步骤数量和轮次。作为练习,尝试执行 3 个本地轮次的重建训练,上限为 50 步,以及 1 个本地轮次的重建后训练,上限为 50 步。提示:您会发现tff.learning.models.ReconstructionModel.build_dataset_split_fn有用。完成此操作后,尝试调整这些超参数和其他相关超参数(如学习率和批次大小),以获得更好的结果。联邦重建训练和评估的默认行为是将客户端本地数据分成两半,分别用于重建和重建后使用。在客户端本地数据非常少的情况下,可以合理地将数据重复用于训练过程的重建和重建后使用(不适用于评估,这会导致不公平的评估)。尝试对训练过程进行此更改,确保评估的
dataset_split_fn仍然保持重建和重建后数据不同。提示:tff.learning.models.ReconstructionModel.simple_dataset_split_fn可能有用。上面,我们使用
tff.learning.models.VariableModel从 Keras 模型中生成了一个tff.learning.models.ReconstructionModel.from_keras_model_and_layers。我们也可以通过 实现模型接口 来使用纯 TensorFlow 2.0 实现自定义模型。尝试修改get_matrix_factorization_model来构建并返回一个扩展tff.learning.models.ReconstructionModel的类,并实现其方法。提示:tff.learning.models.ReconstructionModel.from_keras_model_and_layers的源代码提供了一个扩展tff.learning.models.ReconstructionModel类的示例。还可以参考 EMNIST 图像分类教程中的自定义模型实现,了解扩展tff.learning.models.VariableModel的类似练习。在本教程中,我们从矩阵分解的角度阐述了部分本地联邦学习的动机,其中将用户嵌入发送到服务器将毫无疑问地泄露用户偏好。我们也可以在其他情况下应用联邦重建,作为一种训练更个性化模型(因为模型的一部分完全是本地化的)并减少通信(因为本地参数不会发送到服务器)的方法。一般来说,使用这里介绍的接口,我们可以将任何通常完全全局训练的联邦模型的变量划分为全局变量和局部变量。在 联邦重建论文 中探讨的例子是个人下一个词预测:在这里,每个用户都有自己的本地词嵌入集,用于词库外的词,使模型能够捕捉用户的俚语并实现个性化,而无需额外的通信。作为练习,尝试实现(作为 Keras 模型或自定义 TensorFlow 2.0 模型)一个不同的模型,用于联邦重建。建议:实现一个带有个人用户嵌入的 EMNIST 分类模型,其中个人用户嵌入在模型的最后一个 Dense 层之前与 CNN 图像特征连接。您可以重用本教程中的大部分代码(例如
UserEmbedding类)和 图像分类教程。