
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
TensorFlow Ranking 可以处理异构的稠密和稀疏特征,并且可以扩展到数百万个数据点。但是,构建和部署学习排名模型以大规模运行会带来额外的挑战,而不仅仅是设计模型。排名库提供了用于构建 分布式训练 的工作流实用程序类,以用于大规模排名应用程序。有关这些功能的更多信息,请参阅 TensorFlow Ranking 概述。
本教程将向您展示如何构建一个排名模型,该模型通过使用排名库对管道处理架构的支持来启用分布式处理策略。
ANTIQUE 数据集
在本教程中,您将为 ANTIQUE(一个问答数据集)构建一个排名模型。给定一个查询和一个答案列表,目标是使用最佳排名相关指标(例如 NDCG)对答案进行排名。有关排名指标的更多详细信息,请查看评估措施 离线指标。
ANTIQUE 是一个公开可用的数据集,用于开放域非事实问答,收集自 Yahoo! 答案。每个问题都有一个答案列表,其相关性按 0-4 的等级进行分级,0 表示不相关,4 表示完全相关。列表大小可能会因查询而异,因此我们使用固定的“列表大小”50,其中列表被截断或用默认值填充。该数据集被分成 2206 个查询用于训练和 200 个查询用于测试。有关更多详细信息,请阅读 arXiv 上的技术论文。
设置
下载并安装 TensorFlow Ranking 和 TensorFlow Serving 软件包。
pip install -q tensorflow-ranking tensorflow-serving-apipip install -U "tensorflow-text==2.11.*"
通过笔记本导入 TensorFlow Ranking 库和有用的库。
import pathlib
import tensorflow as tf
import tensorflow_ranking as tfr
import tensorflow_text as tf_text
from tensorflow_serving.apis import input_pb2
from google.protobuf import text_format
数据准备
下载训练、测试数据和词汇表文件。
wget -O "/tmp/train.tfrecords" "http://ciir.cs.umass.edu/downloads/Antique/tf-ranking/ELWC/train.tfrecords"wget -O "/tmp/test.tfrecords" "http://ciir.cs.umass.edu/downloads/Antique/tf-ranking//ELWC/test.tfrecords"wget -O "/tmp/vocab.txt" "http://ciir.cs.umass.edu/downloads/Antique/tf-ranking/vocab.txt"
在此,数据集保存在特定于排名的 ExampleListWithContext (ELWC) 格式中。下一部分中详细说明如何生成数据并将其存储在 ELWC 格式中。
用于排名的 ELWC 数据格式
单个问题的包含一个 query_tokens 列表,表示问题(“上下文”),以及一个答案列表(“示例”)。每个答案都表示为一个 document_tokens 列表和一个 relevance 分数。以下代码显示了问题的简化数据表示
example_list_with_context = {
"context": {
"query_tokens": ["this", "is", "a", "question"]
},
"examples": [
{
"document_tokens": ["this", "is", "a", "relevant", "answer"],
"relevance": [4]
},
{
"document_tokens": ["irrelevant", "data"],
"relevance": [0]
}
]
}
在上一部分中下载的数据文件包含此类数据的序列化 protobuffer 表示形式。当以文本形式查看时,这些 protobuffer 非常长,但会对相同的数据进行编码。
CONTEXT = text_format.Parse(
"""
features {
feature {
key: "query_tokens"
value { bytes_list { value: ["this", "is", "a", "question"] } }
}
}""", tf.train.Example())
EXAMPLES = [
text_format.Parse(
"""
features {
feature {
key: "document_tokens"
value { bytes_list { value: ["this", "is", "a", "relevant", "answer"] } }
}
feature {
key: "relevance"
value { int64_list { value: 4 } }
}
}""", tf.train.Example()),
text_format.Parse(
"""
features {
feature {
key: "document_tokens"
value { bytes_list { value: ["irrelevant", "data"] } }
}
feature {
key: "relevance"
value { int64_list { value: 0 } }
}
}""", tf.train.Example()),
]
ELWC = input_pb2.ExampleListWithContext()
ELWC.context.CopyFrom(CONTEXT)
for example in EXAMPLES:
example_features = ELWC.examples.add()
example_features.CopyFrom(example)
print(ELWC)
examples {
features {
feature {
key: "document_tokens"
value {
bytes_list {
value: "this"
value: "is"
value: "a"
value: "relevant"
value: "answer"
}
}
}
feature {
key: "relevance"
value {
int64_list {
value: 4
}
}
}
}
}
examples {
features {
feature {
key: "document_tokens"
value {
bytes_list {
value: "irrelevant"
value: "data"
}
}
}
feature {
key: "relevance"
value {
int64_list {
value: 0
}
}
}
}
}
context {
features {
feature {
key: "query_tokens"
value {
bytes_list {
value: "this"
value: "is"
value: "a"
value: "question"
}
}
}
}
}
虽然文本格式很冗长,但可以将 proto 有效地序列化为字节字符串(并解析回 proto)
serialized_elwc = ELWC.SerializeToString()
print(serialized_elwc)
b"\nL\nJ\n4\n\x0fdocument_tokens\x12!\n\x1f\n\x04this\n\x02is\n\x01a\n\x08relevant\n\x06answer\n\x12\n\trelevance\x12\x05\x1a\x03\n\x01\x04\n?\n=\n\x12\n\trelevance\x12\x05\x1a\x03\n\x01\x00\n'\n\x0fdocument_tokens\x12\x14\n\x12\n\nirrelevant\n\x04data\x12-\n+\n)\n\x0cquery_tokens\x12\x19\n\x17\n\x04this\n\x02is\n\x01a\n\x08question"
以下解析器配置将二进制表示形式解析为张量词典
def parse_elwc(elwc):
return tfr.data.parse_from_example_list(
[elwc],
list_size=2,
context_feature_spec={"query_tokens": tf.io.RaggedFeature(dtype=tf.string)},
example_feature_spec={
"document_tokens":
tf.io.RaggedFeature(dtype=tf.string),
"relevance":
tf.io.FixedLenFeature(shape=[], dtype=tf.int64, default_value=0)
},
size_feature_name="_list_size_",
mask_feature_name="_mask_")
parse_elwc(serialized_elwc)
{'_list_size_': <tf.Tensor: shape=(1,), dtype=int32, numpy=array([2], dtype=int32)>,
'_mask_': <tf.Tensor: shape=(1, 2), dtype=bool, numpy=array([[ True, True]])>,
'document_tokens': <tf.RaggedTensor [[[b'this', b'is', b'a', b'relevant', b'answer'], [b'irrelevant', b'data']]]>,
'query_tokens': <tf.RaggedTensor [[b'this', b'is', b'a', b'question']]>,
'relevance': <tf.Tensor: shape=(1, 2), dtype=int64, numpy=array([[4, 0]])>}
请注意,对于 ELWC,您还可以生成 size 和/或 mask 特征,以指示有效大小和/或屏蔽列表中的有效条目,只要定义了 size_feature_name 和/或 mask_feature_name 即可。
上述解析器在 tfr.data 中定义,并包装在我们的预定义数据集构建器 tfr.keras.pipeline.BaseDatasetBuilder 中。
排名管道概述
按照下图中描述的步骤,使用排名管道训练排名模型。特别是,此示例使用 tfr.keras.model.FeatureSpecInputCreator 和 tfr.keras.pipeline.BaseDatasetBuilder,这些是专门针对具有 feature_spec 的数据集定义的。
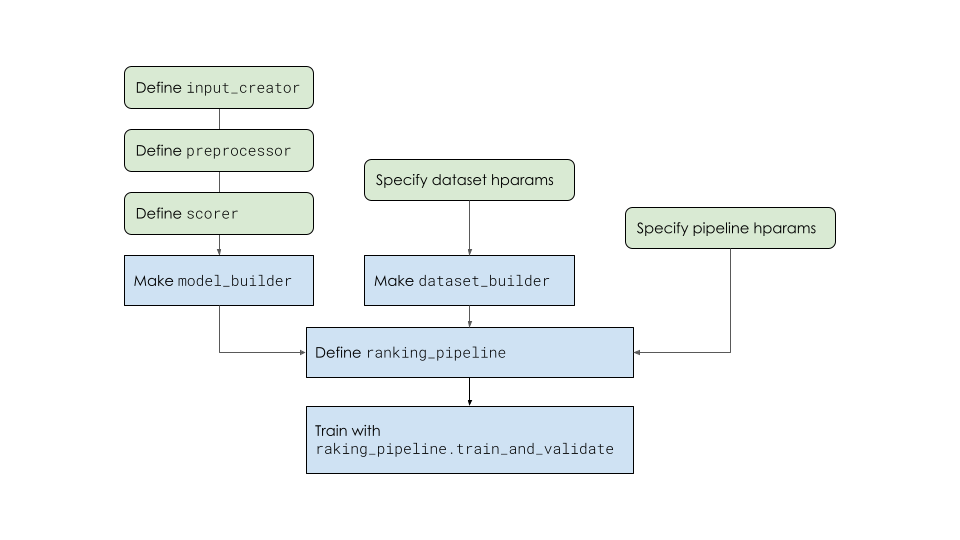
创建模型构建器
不要直接构建 tf.keras.Model 对象,而是创建一个模型构建器,在排名管道中调用它来构建 tf.keras.Model,因为所有训练参数都必须在 strategy.scope(在排名管道中调用 train_and_validate 函数中)下定义,才能使用分布式策略进行训练。
此框架使用 keras 函数式 API 构建模型,其中需要输入(tf.keras.Input)、预处理器(tf.keras.layers.experimental.preprocessing)和评分器(tf.keras.Sequential)来定义模型。
指定特征
特征规范是 TensorFlow 抽象,用于捕获有关每个特征的丰富信息。
创建与排名输入格式(例如 ELWC 格式)一致的上下文特征、示例特征和标签的特征规范。
将 label_spec 特征的 default_value 设置为 -1,以处理要屏蔽的填充项。
context_feature_spec = {
"query_tokens": tf.io.RaggedFeature(dtype=tf.string),
}
example_feature_spec = {
"document_tokens":
tf.io.RaggedFeature(dtype=tf.string),
}
label_spec = (
"relevance",
tf.io.FixedLenFeature(shape=(1,), dtype=tf.int64, default_value=-1)
)
定义 input_creator
input_creator 为 context_feature_spec 和 example_feature_spec 中定义的输入特征创建上下文和示例 tf.keras.Input 的字典。
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
调用 input_creator 返回 Keras 张量字典,这些字典在构建模型时用作输入
input_creator()
({'query_tokens': <KerasTensor: type_spec=RaggedTensorSpec(TensorShape([None, None]), tf.string, 1, tf.int64) (created by layer 'query_tokens')>},
{'document_tokens': <KerasTensor: type_spec=RaggedTensorSpec(TensorShape([None, None, None]), tf.string, 2, tf.int64) (created by layer 'document_tokens')>})
定义 preprocessor
在 preprocessor 中,通过字符串查找预处理层将输入标记转换为独热向量,然后通过嵌入预处理层将其嵌入为嵌入向量。最后,通过标记嵌入的平均值计算整个句子的嵌入向量。
class LookUpTablePreprocessor(tfr.keras.model.Preprocessor):
def __init__(self, vocab_file, vocab_size, embedding_dim):
self._vocab_file = vocab_file
self._vocab_size = vocab_size
self._embedding_dim = embedding_dim
def __call__(self, context_inputs, example_inputs, mask):
list_size = tf.shape(mask)[1]
lookup = tf.keras.layers.StringLookup(
max_tokens=self._vocab_size,
vocabulary=self._vocab_file,
mask_token=None)
embedding = tf.keras.layers.Embedding(
input_dim=self._vocab_size,
output_dim=self._embedding_dim,
embeddings_initializer=None,
embeddings_constraint=None)
# StringLookup and Embedding are shared over context and example features.
context_features = {
key: tf.reduce_mean(embedding(lookup(value)), axis=-2)
for key, value in context_inputs.items()
}
example_features = {
key: tf.reduce_mean(embedding(lookup(value)), axis=-2)
for key, value in example_inputs.items()
}
return context_features, example_features
_VOCAB_FILE = '/tmp/vocab.txt'
_VOCAB_SIZE = len(pathlib.Path(_VOCAB_FILE).read_text().split())
preprocessor = LookUpTablePreprocessor(_VOCAB_FILE, _VOCAB_SIZE, 20)
请注意,词汇表使用与 BERT 相同的分词器。您还可以使用 BertTokenizer 对原始句子进行分词。
tokenizer = tf_text.BertTokenizer(_VOCAB_FILE)
example_tokens = tokenizer.tokenize("Hello TensorFlow!".lower())
print(example_tokens)
print(tokenizer.detokenize(example_tokens))
<tf.RaggedTensor [[[7592], [23435, 12314], [999]]]> <tf.RaggedTensor [[[b'hello'], [b'tensorflow'], [b'!']]]>
定义 scorer
此示例使用 TensorFlow Ranking 中预定义的深度神经网络 (DNN) 单变量评分器。
scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[64, 32, 16],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True)
制作 model_builder
除了 input_creator、preprocessor 和 scorer 之外,指定掩码特征名称以获取数据集中生成的掩码特征。
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=scorer,
mask_feature_name="example_list_mask",
name="antique_model",
)
检查模型架构,
model = model_builder.build()
tf.keras.utils.plot_model(model, expand_nested=True)
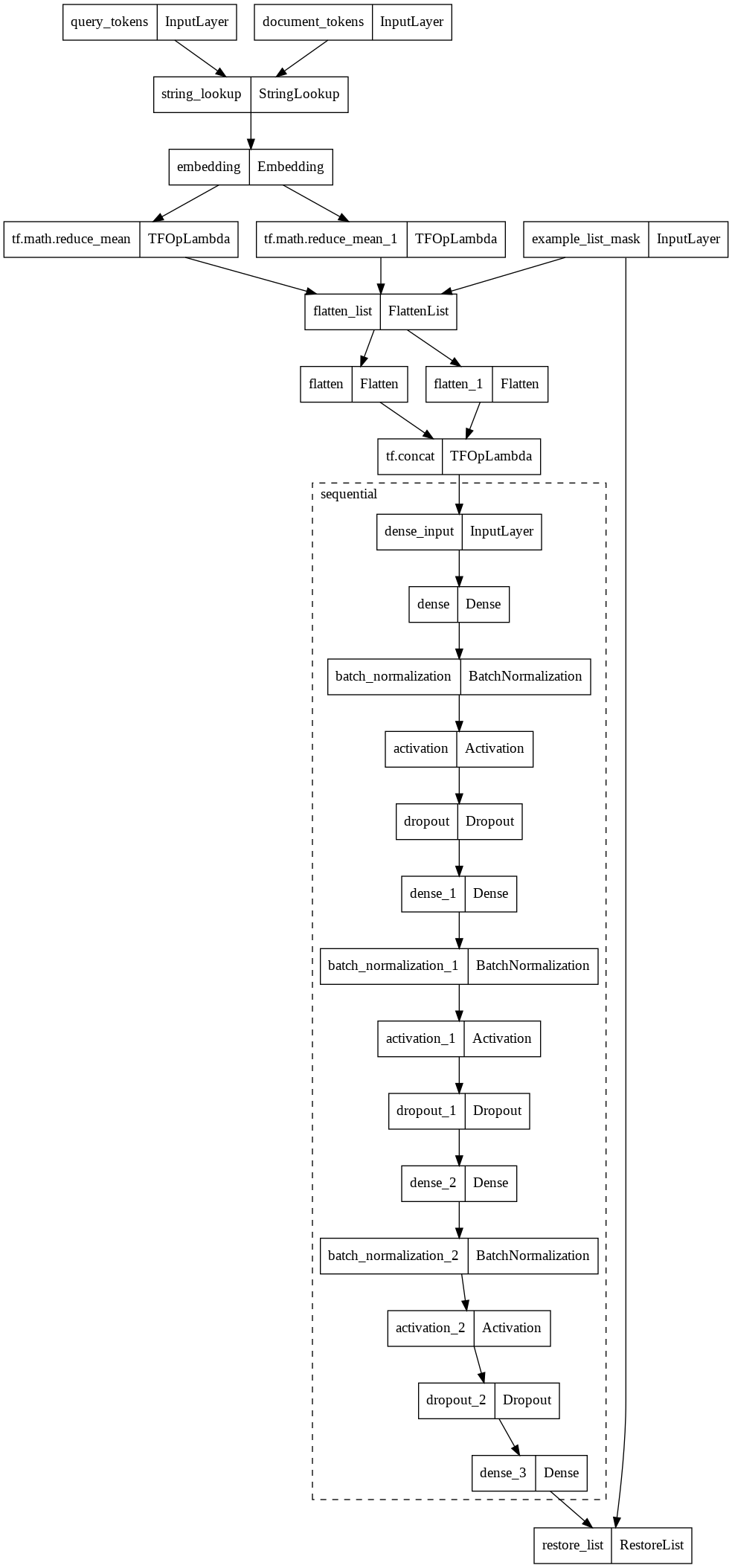
创建数据集构建器
dataset_builder 旨在创建用于训练和验证的数据集,并定义 签名 以将训练好的模型导出为 tf.function。
指定数据超参数
通过创建 dataset_hparams 对象,定义在 dataset_builder 中用于构建数据集的超参数。
使用 tf.data.TFRecordDataset 读取器在 /tmp/train.tfrecords 处加载训练数据集。在每个批次中,每个特征张量的形状为 (batch_size, list_size, feature_sizes),其中 batch_size 等于 32,list_size 等于 50。使用 /tmp/test.tfrecords 处的测试数据在相同的 batch_size 和 list_size 下验证。
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern="/tmp/train.tfrecords",
valid_input_pattern="/tmp/test.tfrecords",
train_batch_size=32,
valid_batch_size=32,
list_size=50,
dataset_reader=tf.data.TFRecordDataset)
创建 dataset_builder
TensorFlow Ranking 提供了一个预定义的 SimpleDatasetBuilder,用于使用 feature_spec 从 ELWC 生成数据集。由于掩码特征用于确定每个填充列表中的有效示例,因此必须指定与 model_builder 中使用的 mask_feature_name 一致的 mask_feature_name。
dataset_builder = tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec,
example_feature_spec,
mask_feature_name="example_list_mask",
label_spec=label_spec,
hparams=dataset_hparams)
ds_train = dataset_builder.build_train_dataset()
ds_train.element_spec
({'document_tokens': RaggedTensorSpec(TensorShape([None, 50, None]), tf.string, 2, tf.int32),
'example_list_mask': TensorSpec(shape=(32, 50), dtype=tf.bool, name=None),
'query_tokens': RaggedTensorSpec(TensorShape([32, None]), tf.string, 1, tf.int32)},
TensorSpec(shape=(32, 50), dtype=tf.float32, name=None))
创建排名管道
ranking_pipeline 是一个经过优化的排名模型训练包,它实现分布式训练、将模型导出为 tf.function,并集成有用的回调,包括 tensorboard 和在发生故障时恢复。
指定管道超参数
通过创建一个 pipeline_hparams 对象,指定在 ranking_pipeline 中运行管道时要使用的超参数。
使用 approx_ndcg_loss 以等于 0.05 的学习率训练模型,每个 epoch 1000 个步骤,共 5 个 epoch,使用 MirroredStrategy。在每个 epoch 之后,对验证数据集评估模型 100 个步骤。将训练后的模型保存在 /tmp/ranking_model_dir 下。
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir="/tmp/ranking_model_dir",
num_epochs=5,
steps_per_epoch=1000,
validation_steps=100,
learning_rate=0.05,
loss="approx_ndcg_loss",
strategy="MirroredStrategy")
定义 ranking_pipeline
TensorFlow Ranking 提供了一个预定义的 SimplePipeline,以支持使用分布式策略进行模型训练。
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams)
WARNING:tensorflow:There are non-GPU devices in `tf.distribute.Strategy`, not using nccl allreduce.
WARNING:tensorflow:There are non-GPU devices in `tf.distribute.Strategy`, not using nccl allreduce.
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:CPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:CPU:0',)
训练和评估模型
train_and_validate 函数在每个 epoch 之后对验证数据集评估训练后的模型。
ranking_pipeline.train_and_validate(verbose=1)
Epoch 1/5
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/indexed_slices.py:450: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape_1:0", shape=(1600,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0), values=Tensor("gradient_tape/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape:0", shape=(1600, 20), dtype=float32, device=/job:localhost/replica:0/task:0/device:CPU:0), dense_shape=Tensor("gradient_tape/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Cast:0", shape=(2,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/indexed_slices.py:450: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/while/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape_1:0", shape=(1600,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0), values=Tensor("gradient_tape/while/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Reshape:0", shape=(1600, 20), dtype=float32, device=/job:localhost/replica:0/task:0/device:CPU:0), dense_shape=Tensor("gradient_tape/while/antique_model/flatten_list_2/RaggedGatherNd/RaggedGatherNd/RaggedGather/Cast:0", shape=(2,), dtype=int32, device=/job:localhost/replica:0/task:0/device:CPU:0))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1000/1000 [==============================] - 121s 121ms/step - loss: -0.8845 - metric/ndcg_1: 0.7122 - metric/ndcg_5: 0.7813 - metric/ndcg_10: 0.8413 - metric/ndcg: 0.8856 - val_loss: -0.8672 - val_metric/ndcg_1: 0.6557 - val_metric/ndcg_5: 0.7689 - val_metric/ndcg_10: 0.8243 - val_metric/ndcg: 0.8678
Epoch 2/5
1000/1000 [==============================] - 88s 88ms/step - loss: -0.8957 - metric/ndcg_1: 0.7428 - metric/ndcg_5: 0.8005 - metric/ndcg_10: 0.8551 - metric/ndcg: 0.8959 - val_loss: -0.8731 - val_metric/ndcg_1: 0.6614 - val_metric/ndcg_5: 0.7812 - val_metric/ndcg_10: 0.8348 - val_metric/ndcg: 0.8733
Epoch 3/5
1000/1000 [==============================] - 50s 50ms/step - loss: -0.8955 - metric/ndcg_1: 0.7422 - metric/ndcg_5: 0.7991 - metric/ndcg_10: 0.8545 - metric/ndcg: 0.8957 - val_loss: -0.8695 - val_metric/ndcg_1: 0.6414 - val_metric/ndcg_5: 0.7759 - val_metric/ndcg_10: 0.8315 - val_metric/ndcg: 0.8699
Epoch 4/5
1000/1000 [==============================] - 53s 53ms/step - loss: -0.9009 - metric/ndcg_1: 0.7563 - metric/ndcg_5: 0.8094 - metric/ndcg_10: 0.8620 - metric/ndcg: 0.9011 - val_loss: -0.8624 - val_metric/ndcg_1: 0.6179 - val_metric/ndcg_5: 0.7627 - val_metric/ndcg_10: 0.8253 - val_metric/ndcg: 0.8626
Epoch 5/5
1000/1000 [==============================] - 52s 52ms/step - loss: -0.9042 - metric/ndcg_1: 0.7646 - metric/ndcg_5: 0.8152 - metric/ndcg_10: 0.8662 - metric/ndcg: 0.9044 - val_loss: -0.8733 - val_metric/ndcg_1: 0.6579 - val_metric/ndcg_5: 0.7741 - val_metric/ndcg_10: 0.8362 - val_metric/ndcg: 0.8741
INFO:tensorflow:Assets written to: /tmp/ranking_model_dir/export/latest_model/assets
INFO:tensorflow:Assets written to: /tmp/ranking_model_dir/export/latest_model/assets
启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir="/tmp/ranking_model_dir" --port 12345
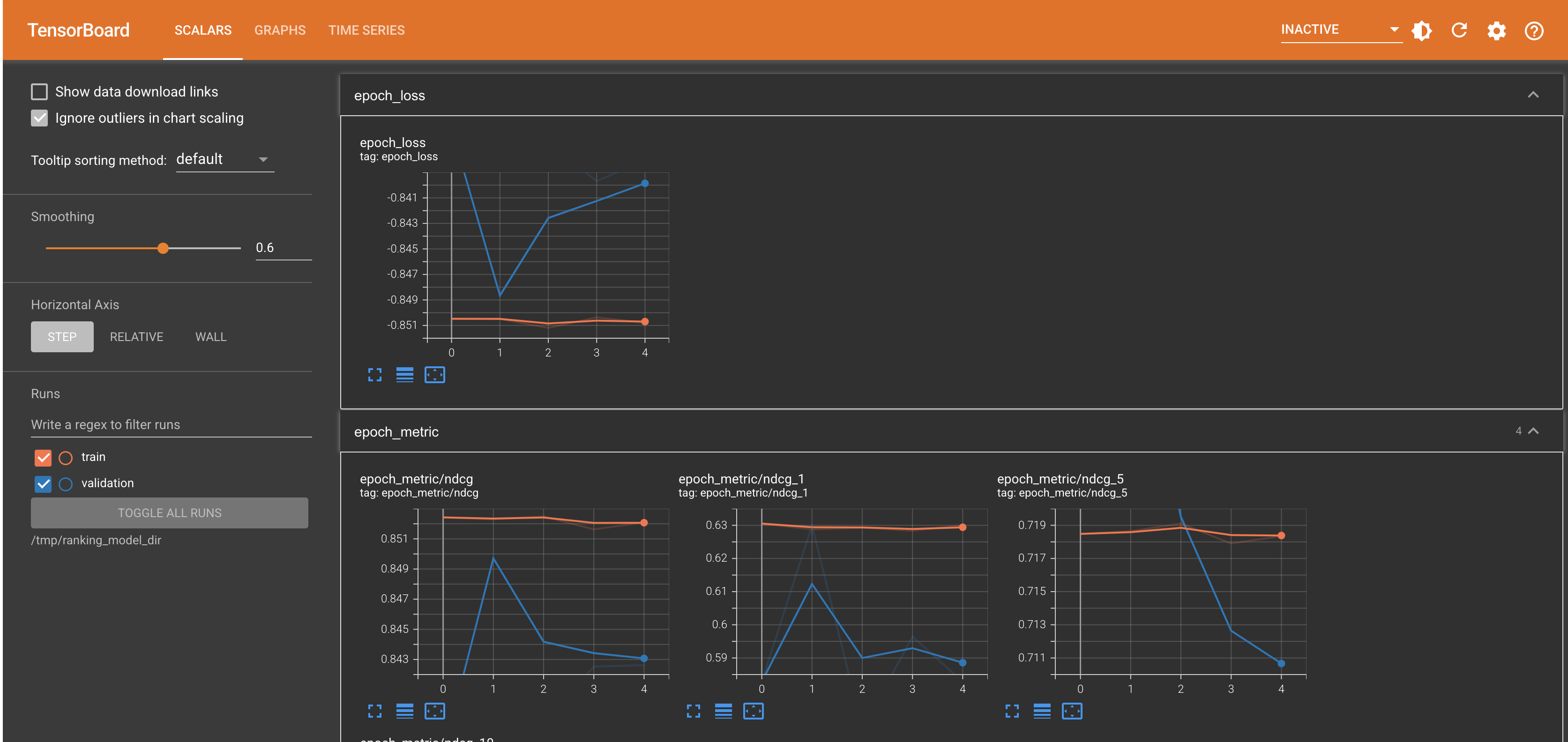
生成预测并评估
获取测试数据。
ds_test = dataset_builder.build_valid_dataset()
# Get input features from the first batch of the test data
for x, y in ds_test.take(1):
break
加载已保存的模型并运行预测。
loaded_model = tf.keras.models.load_model("/tmp/ranking_model_dir/export/latest_model")
# Predict ranking scores
scores = loaded_model.predict(x)
min_score = tf.reduce_min(scores)
scores = tf.where(tf.greater_equal(y, 0.), scores, min_score - 1e-5)
# Sort the answers by scores
sorted_answers = tfr.utils.sort_by_scores(
scores,
[tf.strings.reduce_join(x['document_tokens'], -1, separator=' ')])[0]
查看问题 4 的前 5 个答案。
question = tf.strings.reduce_join(
x['query_tokens'][4, :], -1, separator=' ').numpy()
top_answers = sorted_answers[4, :5].numpy()
print(
f'Q: {question.decode()}\n' +
'\n'.join([f'A{i+1}: {ans.decode()}' for i, ans in enumerate(top_answers)]))
Q: why do people ask questions they know ? A1: because it re ##as ##ures them that they were right in the first place . A2: people like to that be ##cao ##use they want to be recognise that they are the one knows the answer and the questions int ##he first place . A3: to rev ##ali ##date their knowledge and perhaps they choose answers that are mostly with their side simply because they are being subjective . . . . A4: so they can weasel out the judge mental and super ##ci ##lio ##us know all cr ##aa ##p like yourself . . . don ##t judge others , what gives you the right ? . . how do you know what others know . ? . . by asking this question you are putting yourself in the same league as the others you want ot condemn . . face it you already know what your shallow , self absorbed answer is . . . get a reality check pill ##ock , . . . and if you want to go gr ##iz ##z ##ling to the yahoo policeman bring it on . . it will only reinforce my answer and the pathetic ##iness of your q ##est ##ion . . . the only thing you could do that would be even more pathetic is give me the top answer award . . . then you would suck beyond all measure A5: human nature i guess . i have noticed that too . maybe it is just for re ##ass ##urance or approval .