
近年来,新型可微分图形层不断涌现,这些层可以插入神经网络架构中。从空间变换器到可微分图形渲染器,这些新层利用多年来计算机视觉和图形研究积累的知识来构建新的、更高效的网络架构。将几何先验和约束显式地建模到神经网络中,为能够以稳健、高效的方式进行训练的架构打开了大门,更重要的是,以自监督的方式进行训练。
从高层次来看,计算机图形管道需要表示 3D 对象及其在场景中的绝对位置、它们所用材料的描述、灯光和相机。然后,渲染器会解释此场景描述以生成合成渲染。
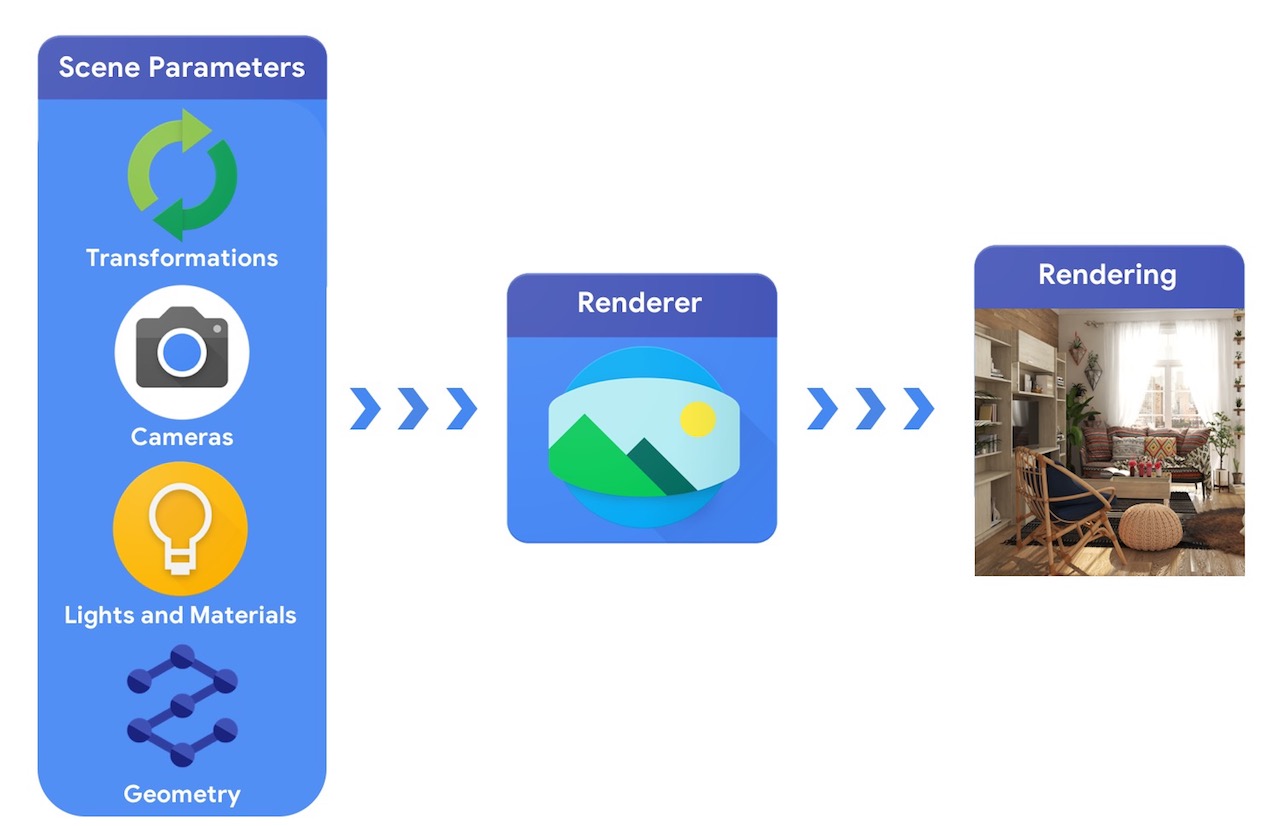
相比之下,计算机视觉系统将从图像开始,并尝试推断场景参数。这允许预测场景中有哪些物体、它们由什么材料制成,以及三维位置和方向。
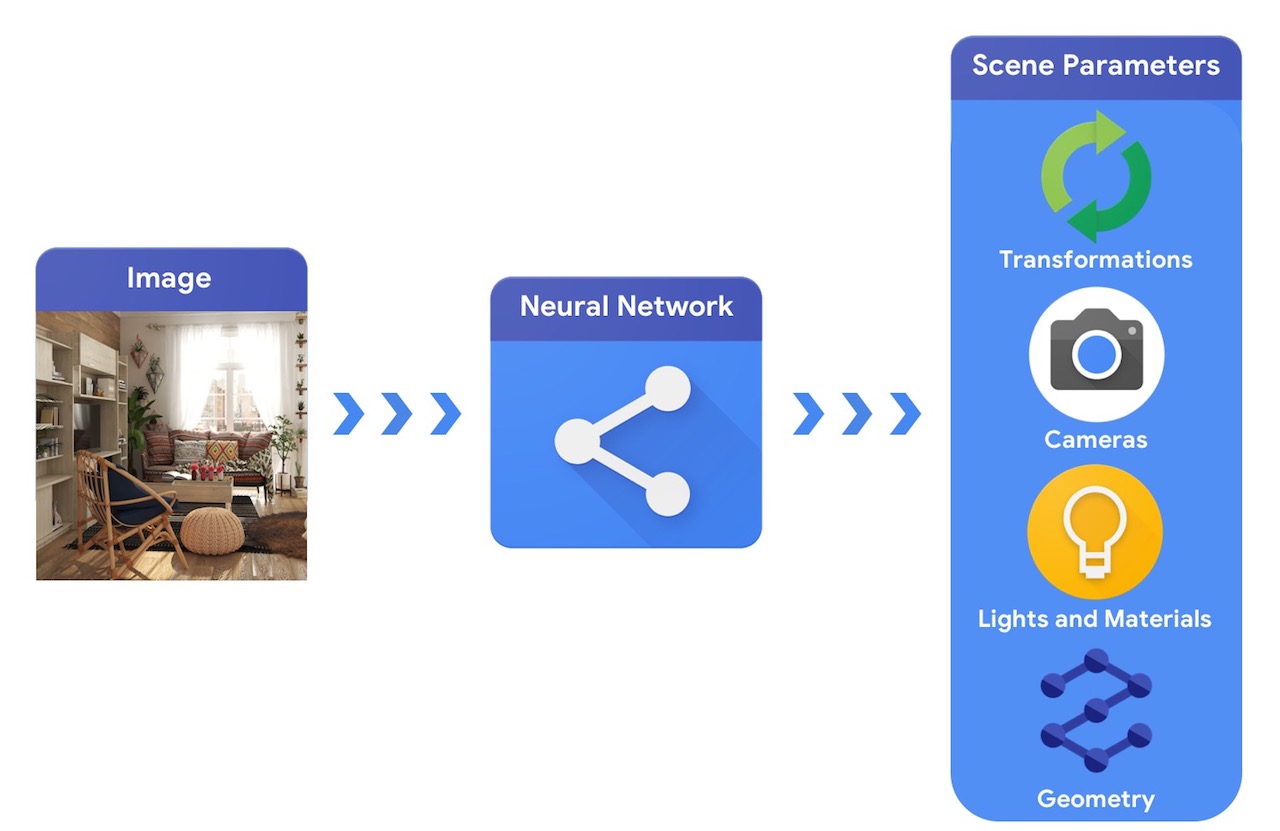
训练能够解决这些复杂 3D 视觉任务的机器学习系统通常需要大量数据。由于标记数据是一个昂贵且复杂的过程,因此拥有能够理解三维世界并在没有太多监督的情况下进行训练的机器学习模型设计机制非常重要。结合计算机视觉和计算机图形技术为利用大量现成的未标记数据提供了独特的机会。如下图所示,这可以通过分析合成来实现,其中视觉系统提取场景参数,图形系统根据这些参数重新渲染图像。如果渲染结果与原始图像匹配,则视觉系统已准确地提取了场景参数。在此设置中,计算机视觉和计算机图形协同工作,形成一个类似于自动编码器的单一机器学习系统,可以以自监督的方式进行训练。
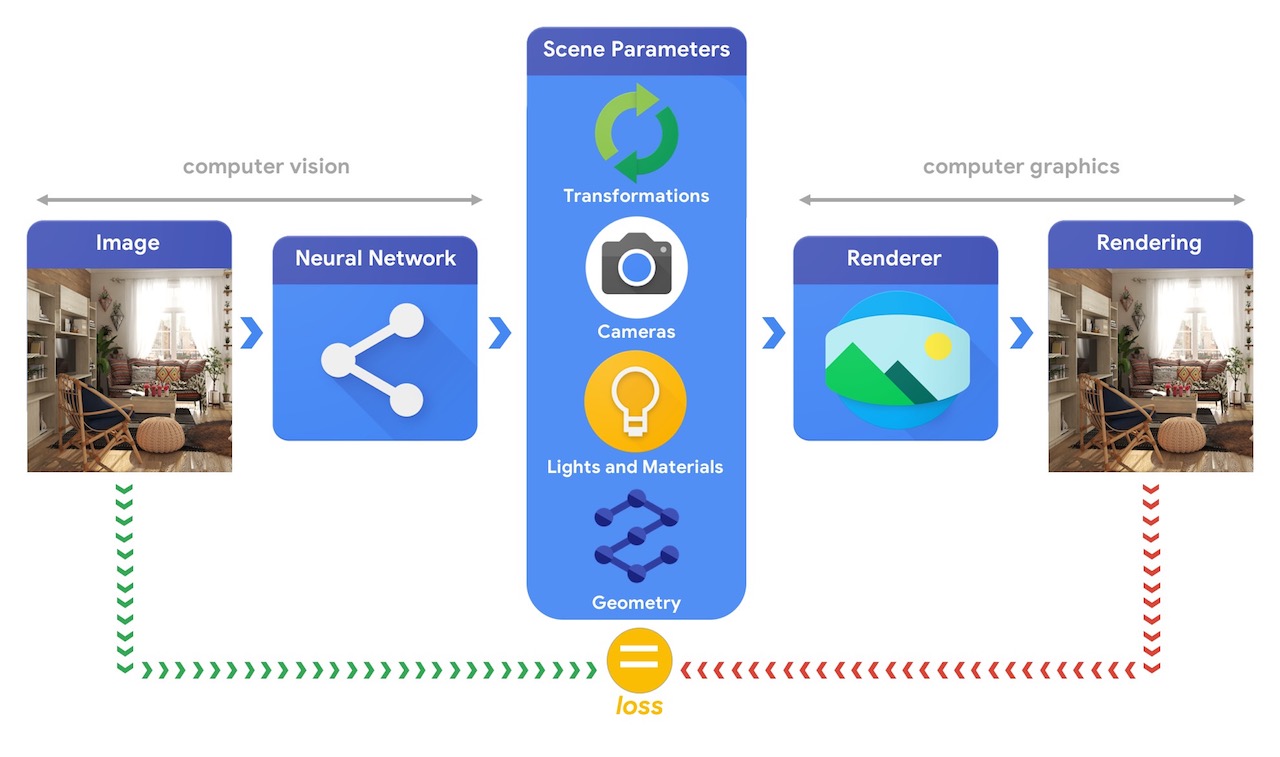
Tensorflow 图形正在开发中,旨在帮助解决这些类型的挑战,为此,它提供了一组可微分图形和几何层(例如相机、反射模型、空间变换、网格卷积)和 3D 视图功能(例如 3D TensorBoard),可用于训练和调试您选择的机器学习模型。