
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
概述
使用 **TensorFlow 图像摘要 API**,您可以轻松地记录张量和任意图像,并在 TensorBoard 中查看它们。这对于对输入数据进行采样和检查,或 可视化层权重 和 生成的张量 非常有用。您还可以将诊断数据记录为图像,这在模型开发过程中可能会有所帮助。
在本教程中,您将学习如何使用图像摘要 API 将张量可视化为图像。您还将学习如何获取任意图像,将其转换为张量,并在 TensorBoard 中可视化它。您将完成一个简单但真实的示例,该示例使用图像摘要来帮助您了解模型的执行情况。
设置
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
# Load the TensorBoard notebook extension.
%load_ext tensorboard
TensorFlow 2.x selected.
from datetime import datetime
import io
import itertools
from packaging import version
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
import sklearn.metrics
print("TensorFlow version: ", tf.__version__)
assert version.parse(tf.__version__).release[0] >= 2, \
"This notebook requires TensorFlow 2.0 or above."
TensorFlow version: 2.2
下载 Fashion-MNIST 数据集
您将构建一个简单的神经网络来对 Fashion-MNIST 数据集中的图像进行分类。该数据集包含 70,000 张 28x28 的灰度时尚产品图像,来自 10 个类别,每个类别有 7,000 张图像。
首先,下载数据
# Download the data. The data is already divided into train and test.
# The labels are integers representing classes.
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = \
fashion_mnist.load_data()
# Names of the integer classes, i.e., 0 -> T-short/top, 1 -> Trouser, etc.
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
可视化单个图像
为了了解图像摘要 API 的工作原理,您现在将简单地将训练集中的第一个训练图像记录到 TensorBoard 中。
在您执行此操作之前,请检查训练数据的形状
print("Shape: ", train_images[0].shape)
print("Label: ", train_labels[0], "->", class_names[train_labels[0]])
Shape: (28, 28) Label: 9 -> Ankle boot
请注意,数据集中每个图像的形状都是形状为 (28, 28) 的秩 2 张量,表示高度和宽度。
但是,tf.summary.image() 期望一个包含 (batch_size, height, width, channels) 的秩 4 张量。因此,需要重新整形张量。
您只记录一张图像,因此 batch_size 为 1。图像为灰度,因此将 channels 设置为 1。
# Reshape the image for the Summary API.
img = np.reshape(train_images[0], (-1, 28, 28, 1))
您现在已准备好记录此图像并在 TensorBoard 中查看它。
# Clear out any prior log data.
!rm -rf logs
# Sets up a timestamped log directory.
logdir = "logs/train_data/" + datetime.now().strftime("%Y%m%d-%H%M%S")
# Creates a file writer for the log directory.
file_writer = tf.summary.create_file_writer(logdir)
# Using the file writer, log the reshaped image.
with file_writer.as_default():
tf.summary.image("Training data", img, step=0)
现在,使用 TensorBoard 检查图像。等待几秒钟,让 UI 启动。
%tensorboard --logdir logs/train_data

"时间序列" 仪表板显示您刚刚记录的图像。它是一双“踝靴”。
图像已缩放到默认大小,以便于查看。如果您想查看未缩放的原始图像,请在右侧“设置”面板底部选中“显示实际图像大小”。
使用亮度和对比度滑块,看看它们如何影响图像像素。
可视化多个图像
记录一个张量很棒,但是如果您想记录多个训练示例怎么办?
只需在将数据传递给 tf.summary.image() 时指定要记录的图像数量即可。
with file_writer.as_default():
# Don't forget to reshape.
images = np.reshape(train_images[0:25], (-1, 28, 28, 1))
tf.summary.image("25 training data examples", images, max_outputs=25, step=0)
%tensorboard --logdir logs/train_data

记录任意图像数据
如果您想可视化不是张量的图像,例如由 matplotlib 生成的图像怎么办?
您需要一些样板代码来将绘图转换为张量,但之后就可以正常工作了。
在下面的代码中,您将使用 matplotlib 的 subplot() 函数将前 25 张图像记录为一个漂亮的网格。然后,您将在 TensorBoard 中查看该网格
# Clear out prior logging data.
!rm -rf logs/plots
logdir = "logs/plots/" + datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer = tf.summary.create_file_writer(logdir)
def plot_to_image(figure):
"""Converts the matplotlib plot specified by 'figure' to a PNG image and
returns it. The supplied figure is closed and inaccessible after this call."""
# Save the plot to a PNG in memory.
buf = io.BytesIO()
plt.savefig(buf, format='png')
# Closing the figure prevents it from being displayed directly inside
# the notebook.
plt.close(figure)
buf.seek(0)
# Convert PNG buffer to TF image
image = tf.image.decode_png(buf.getvalue(), channels=4)
# Add the batch dimension
image = tf.expand_dims(image, 0)
return image
def image_grid():
"""Return a 5x5 grid of the MNIST images as a matplotlib figure."""
# Create a figure to contain the plot.
figure = plt.figure(figsize=(10,10))
for i in range(25):
# Start next subplot.
plt.subplot(5, 5, i + 1, title=class_names[train_labels[i]])
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
return figure
# Prepare the plot
figure = image_grid()
# Convert to image and log
with file_writer.as_default():
tf.summary.image("Training data", plot_to_image(figure), step=0)
%tensorboard --logdir logs/plots
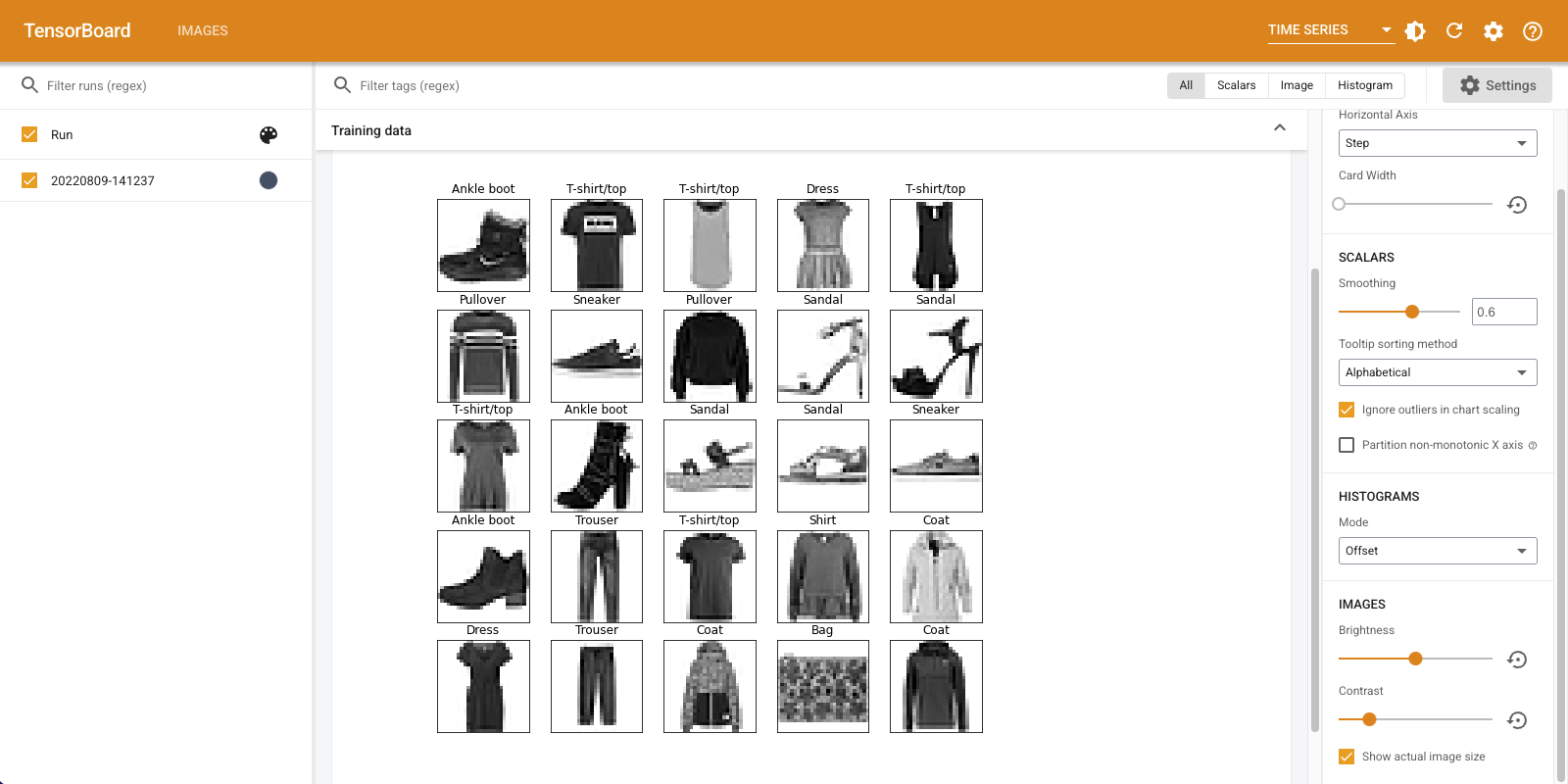
构建图像分类器
现在将所有这些与一个真实的示例结合起来。毕竟,您来这里是为了进行机器学习,而不是绘制漂亮的图片!
您将使用图像摘要来了解在训练 Fashion-MNIST 数据集的简单分类器时模型的执行情况。
首先,创建一个非常简单的模型并对其进行编译,设置优化器和损失函数。编译步骤还指定您希望记录分类器的准确性。
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
在训练分类器时,查看 混淆矩阵 很有用。混淆矩阵为您提供了有关分类器在测试数据上的执行情况的详细知识。
定义一个计算混淆矩阵的函数。您将使用一个方便的 Scikit-learn 函数来执行此操作,然后使用 matplotlib 绘制它。
def plot_confusion_matrix(cm, class_names):
"""
Returns a matplotlib figure containing the plotted confusion matrix.
Args:
cm (array, shape = [n, n]): a confusion matrix of integer classes
class_names (array, shape = [n]): String names of the integer classes
"""
figure = plt.figure(figsize=(8, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion matrix")
plt.colorbar()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=45)
plt.yticks(tick_marks, class_names)
# Compute the labels from the normalized confusion matrix.
labels = np.around(cm.astype('float') / cm.sum(axis=1)[:, np.newaxis], decimals=2)
# Use white text if squares are dark; otherwise black.
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
color = "white" if cm[i, j] > threshold else "black"
plt.text(j, i, labels[i, j], horizontalalignment="center", color=color)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
return figure
您现在已准备好训练分类器并在整个过程中定期记录混淆矩阵。
以下是您将执行的操作
- 创建 Keras TensorBoard 回调 来记录基本指标
- 创建 Keras LambdaCallback 来在每个 epoch 结束时记录混淆矩阵
- 使用 Model.fit() 训练模型,确保传递两个回调
随着训练的进行,向下滚动以查看 TensorBoard 启动。
# Clear out prior logging data.
!rm -rf logs/image
logdir = "logs/image/" + datetime.now().strftime("%Y%m%d-%H%M%S")
# Define the basic TensorBoard callback.
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
file_writer_cm = tf.summary.create_file_writer(logdir + '/cm')
def log_confusion_matrix(epoch, logs):
# Use the model to predict the values from the validation dataset.
test_pred_raw = model.predict(test_images)
test_pred = np.argmax(test_pred_raw, axis=1)
# Calculate the confusion matrix.
cm = sklearn.metrics.confusion_matrix(test_labels, test_pred)
# Log the confusion matrix as an image summary.
figure = plot_confusion_matrix(cm, class_names=class_names)
cm_image = plot_to_image(figure)
# Log the confusion matrix as an image summary.
with file_writer_cm.as_default():
tf.summary.image("epoch_confusion_matrix", cm_image, step=epoch)
# Define the per-epoch callback.
cm_callback = keras.callbacks.LambdaCallback(on_epoch_end=log_confusion_matrix)
# Start TensorBoard.
%tensorboard --logdir logs/image
# Train the classifier.
model.fit(
train_images,
train_labels,
epochs=5,
verbose=0, # Suppress chatty output
callbacks=[tensorboard_callback, cm_callback],
validation_data=(test_images, test_labels),
)
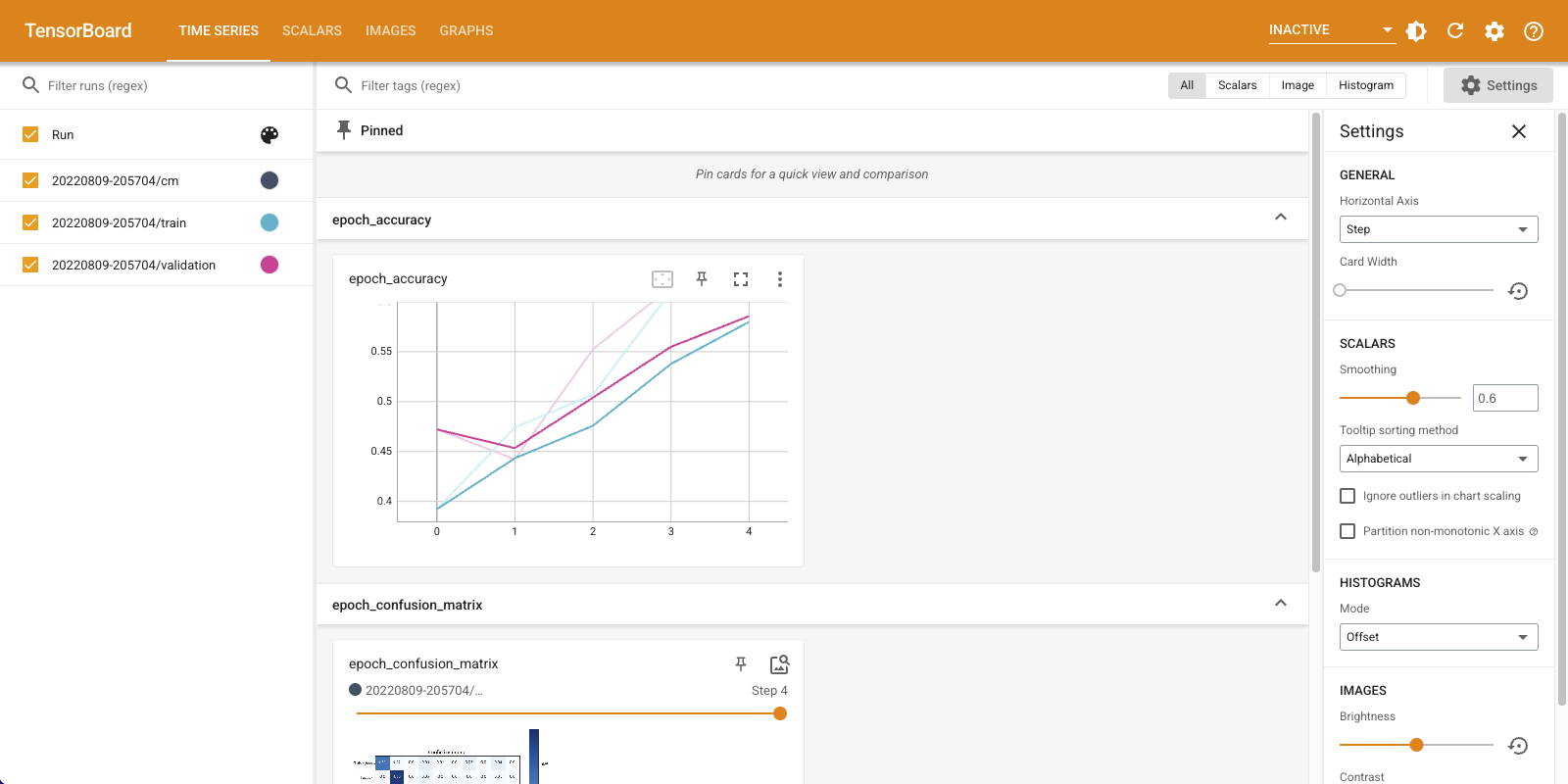
请注意,训练集和验证集的准确性都在上升。这是一个好兆头。但是,模型在数据的特定子集上的执行情况如何?
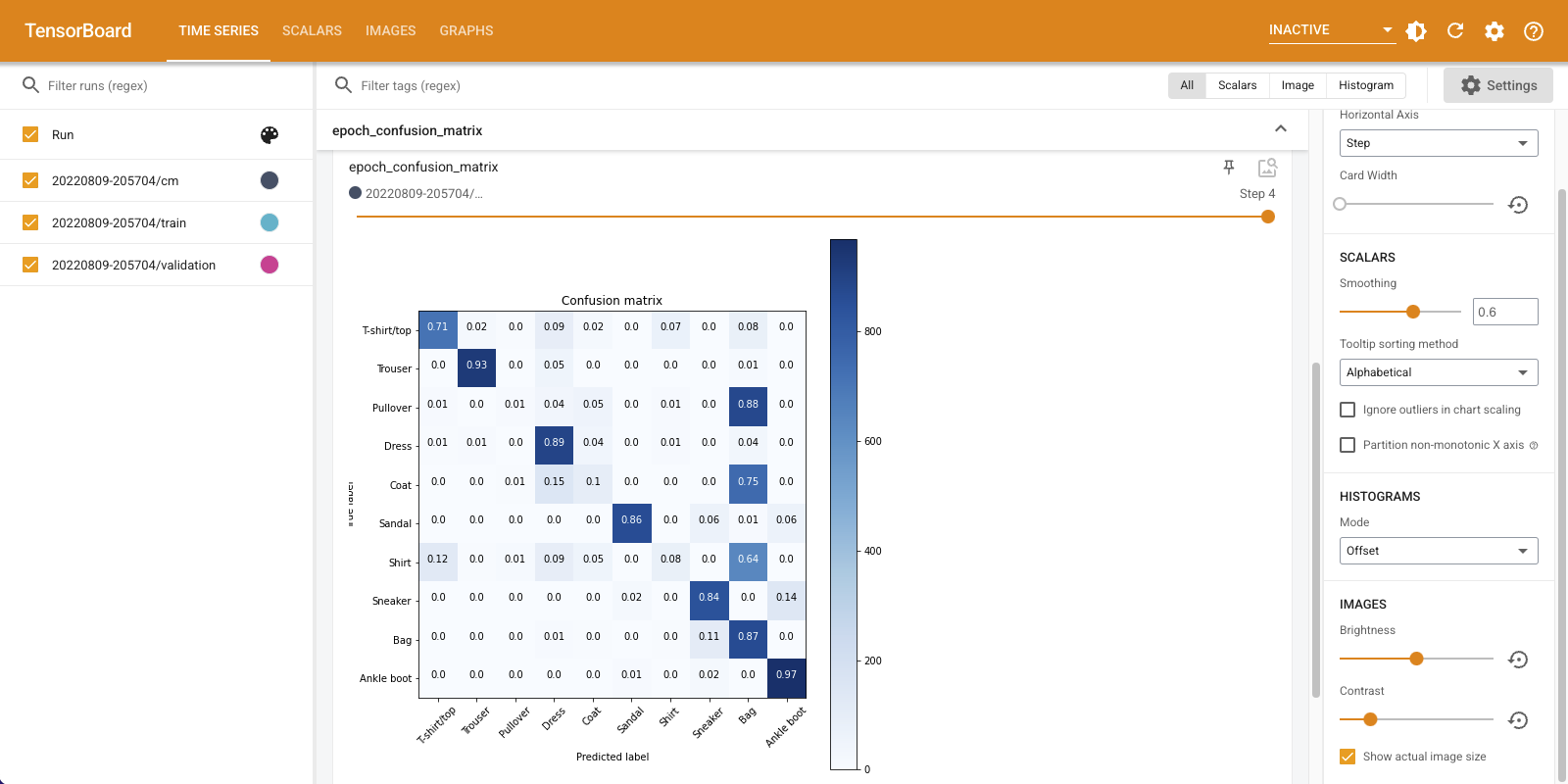
向下滚动“时间序列”仪表板以可视化记录的混淆矩阵。在“设置”面板底部选中“显示实际图像大小”以查看全尺寸的混淆矩阵。
默认情况下,仪表板显示最后记录的步骤或纪元的图像摘要。使用滑块查看更早的混淆矩阵。注意,随着训练的进行,矩阵如何发生显著变化,对角线上的方块变暗,矩阵的其余部分趋向于 0 和白色。这意味着您的分类器随着训练的进行而改进!干得好!
混淆矩阵显示这个简单模型存在一些问题。尽管取得了很大进展,但衬衫、T 恤和套头衫仍然容易混淆。该模型需要进一步改进。
如果您有兴趣,请尝试使用 卷积神经网络 (CNN) 来改进此模型。