
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
在构建机器学习模型时,您需要选择各种超参数,例如层中的 dropout 率或学习率。这些决定会影响模型指标,例如准确率。因此,机器学习工作流程中的一个重要步骤是为您的问题确定最佳超参数,这通常涉及实验。此过程称为“超参数优化”或“超参数调整”。
TensorBoard 中的 HParams 仪表盘提供了一些工具来帮助您确定最佳实验或最有希望的超参数集。
本教程将重点介绍以下步骤
- 实验设置和 HParams 摘要
- 调整 TensorFlow 运行以记录超参数和指标
- 启动运行并将它们全部记录在一个父目录下
- 在 TensorBoard 的 HParams 仪表盘中可视化结果
首先安装 TF 2.0 并加载 TensorBoard 笔记本扩展
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
导入 TensorFlow 和 TensorBoard HParams 插件
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
下载FashionMNIST 数据集并对其进行缩放
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. 实验设置和 HParams 实验摘要
在模型中尝试三个超参数
- 第一个密集层中的单元数
- dropout 层中的 dropout 率
- 优化器
列出要尝试的值,并将实验配置记录到 TensorBoard。此步骤是可选的:您可以提供域信息以在 UI 中启用更精确的超参数过滤,并且可以指定应显示哪些指标。
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
如果您选择跳过此步骤,则可以在使用HParam 值的地方使用字符串文字:例如,使用hparams['dropout'] 而不是hparams[HP_DROPOUT]。
2. 调整 TensorFlow 运行以记录超参数和指标
该模型将非常简单:两个密集层,它们之间有一个 dropout 层。训练代码看起来很熟悉,尽管超参数不再是硬编码的。相反,超参数是在hparams 字典中提供的,并在整个训练函数中使用
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
对于每次运行,使用超参数和最终准确率记录 hparams 摘要
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
在训练 Keras 模型时,可以使用回调,而不是直接编写这些内容
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. 启动运行并将它们全部记录在一个父目录下
您现在可以尝试多个实验,每个实验都使用不同的超参数集进行训练。
为简单起见,使用网格搜索:尝试离散参数的所有组合以及实值参数的下限和上限。对于更复杂的场景,随机选择每个超参数值可能更有效(这称为随机搜索)。可以使用更高级的方法。
运行一些实验,这将花费几分钟
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. 在 TensorBoard 的 HParams 插件中可视化结果
现在可以打开 HParams 仪表盘。启动 TensorBoard,然后单击顶部的“HParams”。
%tensorboard --logdir logs/hparam_tuning
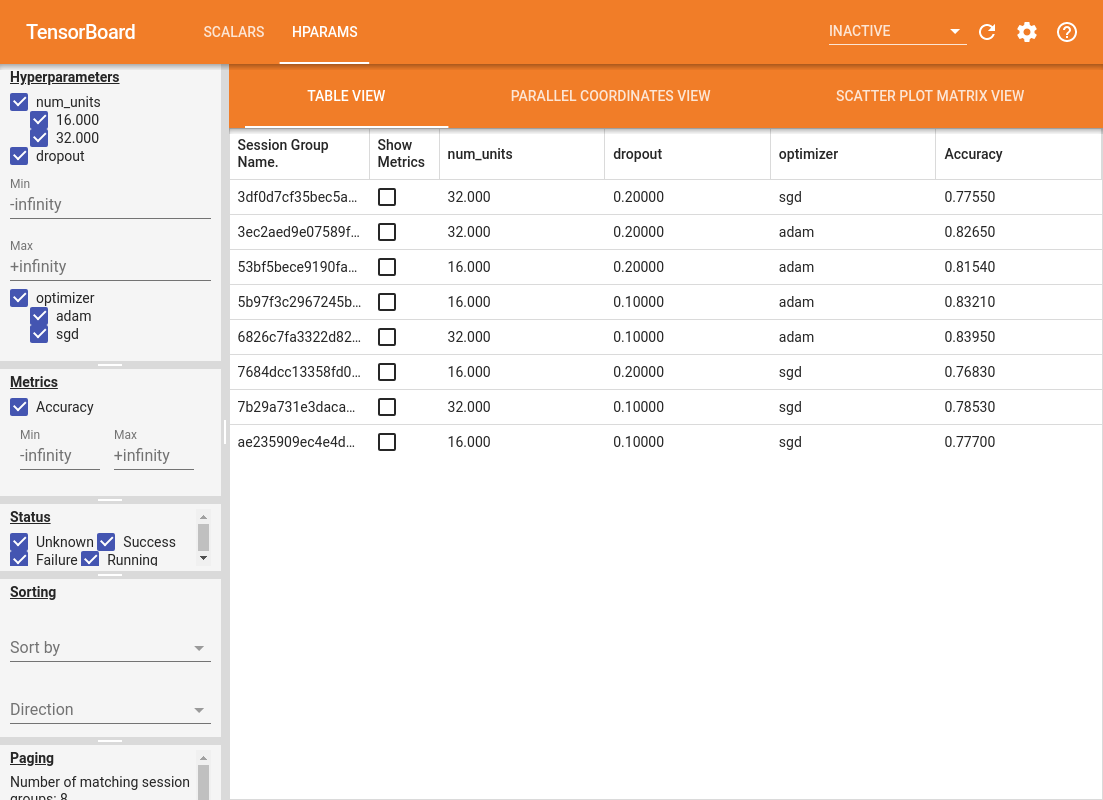
仪表盘的左侧窗格提供了过滤功能,这些功能在 HParams 仪表盘的所有视图中都是有效的
- 过滤在仪表盘中显示哪些超参数/指标
- 过滤在仪表盘中显示哪些超参数/指标值
- 根据运行状态进行过滤(正在运行、成功、...)
- 在表格视图中按超参数/指标排序
- 要显示的会话组数(在有许多实验时对性能很有用)
HParams 仪表盘有三个不同的视图,包含各种有用的信息
- 表格视图列出了运行、它们的超参数及其指标。
- 平行坐标视图将每个运行显示为一条线,穿过每个超参数和指标的轴。单击并拖动鼠标上的任何轴以标记一个区域,这将仅突出显示穿过该区域的运行。这对于确定哪些超参数组最重要很有用。轴本身可以通过拖动来重新排序。
- 散点图视图显示了比较每个超参数/指标与每个指标的图。这有助于识别相关性。单击并拖动以在特定图中选择一个区域,并在其他图中突出显示这些会话。
可以单击表格行、平行坐标线和散点图标记以查看该会话的指标随训练步骤变化的图(尽管在本教程中,每次运行只使用一个步骤)。
要进一步探索 HParams 仪表盘的功能,请下载一组包含更多实验的预生成日志
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
在 TensorBoard 中查看这些日志
%tensorboard --logdir logs/hparam_demo
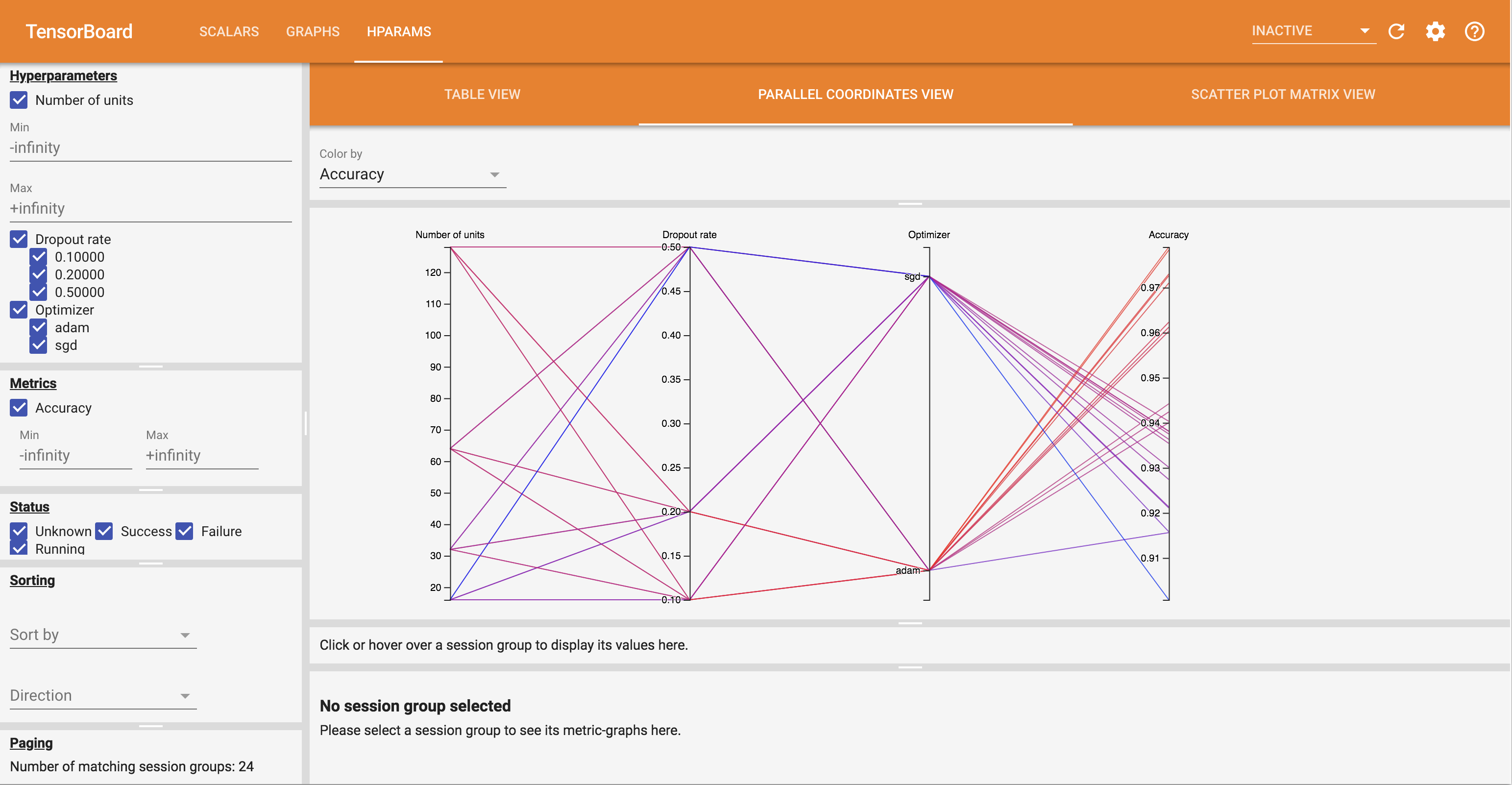
您可以尝试 HParams 仪表盘中的不同视图。
例如,通过进入平行坐标视图并点击拖动精度轴,您可以选择精度最高的运行。由于这些运行在优化器轴上穿过“adam”,您可以得出结论,“adam”在这些实验中比“sgd”表现更好。