
涉及 NaN 的灾难性事件有时会在 TensorFlow 程序中发生,从而破坏模型训练过程。此类事件的根本原因通常难以理解,特别是对于规模和复杂度不小的模型而言。为了更轻松地调试此类模型错误,TensorBoard 2.3+(以及 TensorFlow 2.3+)提供了一个名为调试器 V2 的专用仪表板。在本教程中,我们将通过一个涉及 TensorFlow 中神经网络的 NaN 错误的真实错误来演示如何使用此工具。
本教程中说明的技术适用于其他类型的调试活动,例如检查复杂程序中的运行时张量形状。本教程重点介绍 NaN,因为它们出现的频率相对较高。
观察错误
我们将调试的 TF2 程序的源代码 在 GitHub 上提供。示例程序也打包到 tensorflow pip 包(版本 2.3+)中,可以通过以下方式调用:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
此 TF2 程序创建了一个多层感知器 (MLP),并对其进行训练以识别 MNIST 图像。此示例故意使用 TF2 的低级 API 来定义自定义层结构、损失函数和训练循环,因为当我们使用此更灵活但更容易出错的 API 时,NaN 错误的可能性高于使用更易于使用但略微不太灵活的高级 API(例如 tf.keras)。
该程序在每个训练步骤后打印测试准确率。我们可以在控制台中看到,测试准确率在第一步后就卡在了接近机会水平(约 0.1)上。这肯定不是模型训练的预期行为:我们期望准确率随着步骤的增加而逐渐接近 1.0(100%)。
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
一个合理的猜测是,这个问题是由数值不稳定性引起的,例如 NaN 或无穷大。但是,我们如何确认这确实是这种情况,以及如何找到生成数值不稳定性的 TensorFlow 操作 (op)?为了回答这些问题,让我们使用调试器 V2 对有问题的程序进行检测。
使用调试器 V2 检测 TensorFlow 代码
tf.debugging.experimental.enable_dump_debug_info() 是调试器 V2 的 API 入口点。它使用一行代码对 TF2 程序进行检测。例如,在程序开头附近添加以下行将导致调试信息写入 /tmp/tfdbg2_logdir 的日志目录 (logdir)。调试信息涵盖了 TensorFlow 运行时的各个方面。在 TF2 中,它包括急切执行的完整历史记录、由 @tf.function 执行的图构建、图的执行、执行事件生成的张量值,以及这些事件的代码位置(Python 堆栈跟踪)。调试信息的丰富性使用户能够缩小范围,找到难以理解的错误。
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
该 tensor_debug_mode 参数控制调试器 V2 从每个急切或图内张量中提取哪些信息。“FULL_HEALTH” 是一种模式,它捕获有关每个浮点类型张量(例如,常见的 float32 和不太常见的 bfloat16 dtype)的以下信息:
- 数据类型
- 秩
- 元素总数
- 将浮点类型元素细分为以下类别:负有限 (
-)、零 (0)、正有限 (+)、负无穷大 (-∞)、正无穷大 (+∞) 和NaN。
“FULL_HEALTH” 模式适用于调试涉及 NaN 和无穷大的错误。有关其他支持的 tensor_debug_mode,请参见下文。
该 circular_buffer_size 参数控制保存到 logdir 的张量事件数量。它默认为 1000,这会导致仅将最后 1000 个张量(在检测到的 TF2 程序结束之前)保存到磁盘。此默认行为通过牺牲调试数据完整性来减少调试器开销。如果需要完整性,就像在本例中一样,我们可以通过将参数设置为负值(例如,这里的 -1)来禁用循环缓冲区。
debug_mnist_v2 示例通过向其传递命令行标志来调用 enable_dump_debug_info()。要再次运行我们有问题的 TF2 程序,并启用此调试检测,请执行以下操作:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
在 TensorBoard 中启动调试器 V2 GUI
使用调试器检测运行程序将在 /tmp/tfdbg2_logdir 创建一个 logdir。我们可以启动 TensorBoard 并将其指向 logdir,方法是:
tensorboard --logdir /tmp/tfdbg2_logdir
在 Web 浏览器中,导航到 TensorBoard 的页面 https://127.0.0.1:6006。“调试器 V2” 插件默认情况下处于非活动状态,因此请从右上角的“非活动插件”菜单中选择它。选择后,它应该如下所示:
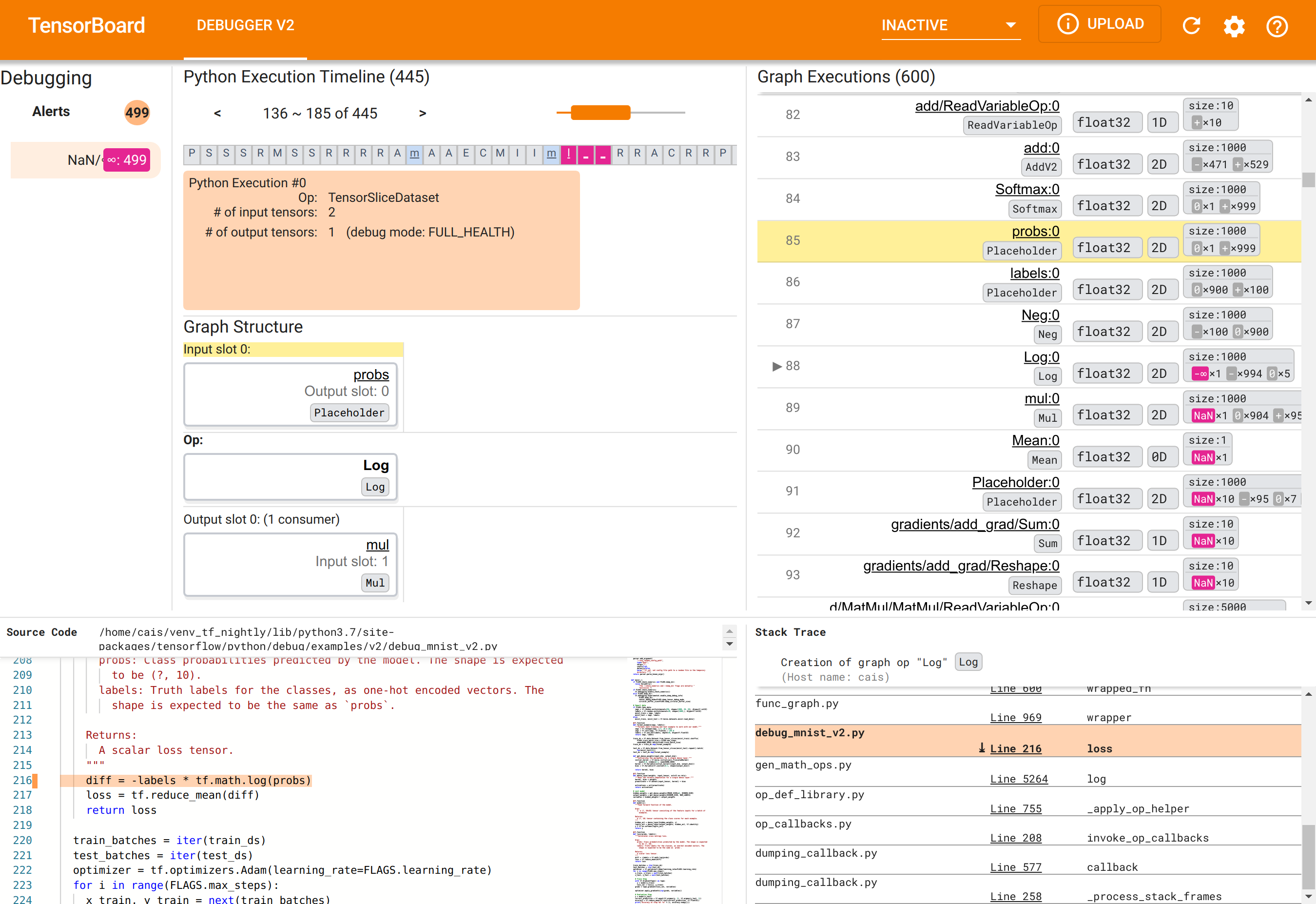
使用调试器 V2 GUI 查找 NaN 的根本原因
TensorBoard 中的调试器 V2 GUI 组织成六个部分:
- 警报: 位于左上角的这一部分包含调试器在检测到的来自已插桩 TensorFlow 程序的调试数据中的“警报”事件列表。每个警报都指示一个需要关注的特定异常。在本例中,此部分突出显示了 499 个 NaN/∞ 事件,并以醒目的粉红色突出显示。这证实了我们的怀疑,即模型由于其内部张量值中存在 NaN 和/或无穷大而无法学习。我们将在稍后深入探讨这些警报。
- Python 执行时间线: 这是顶部中间部分的上半部分。它展示了操作和图的急切执行的完整历史记录。时间线中的每个框都用操作或图名称的首字母标记(例如,“T”代表“TensorSliceDataset”操作,“m”代表“model”
tf.function)。我们可以使用时间线上方的导航按钮和滚动条来浏览此时间线。 - 图执行: 位于 GUI 的右上角,此部分将是我们调试任务的核心。它包含在图内计算的所有浮点类型张量的历史记录(即由
@tf-function编译)。 - 图结构(顶部中间部分的下半部分)、源代码(左下角部分)和堆栈跟踪(右下角部分)最初为空。它们的内容将在我们与 GUI 交互时填充。这三个部分也将在我们的调试任务中发挥重要作用。
在了解了 UI 的组织结构后,让我们采取以下步骤来找出 NaN 出现的原因。首先,单击NaN/∞ 警报部分中的警报。这会自动滚动“图执行”部分中的 600 个图张量列表,并重点关注第 88 个张量,这是一个名为 Log:0 的张量,由 Log(自然对数)操作生成。醒目的粉红色突出显示了 2D float32 张量的 1000 个元素中的一个 -∞ 元素。这是 TF2 程序运行时历史记录中第一个包含 NaN 或无穷大的张量:在此之前计算的张量不包含 NaN 或 ∞;之后计算的许多(实际上是大多数)张量包含 NaN。我们可以通过上下滚动“图执行”列表来确认这一点。此观察结果强烈暗示 Log 操作是此 TF2 程序中数值不稳定的来源。
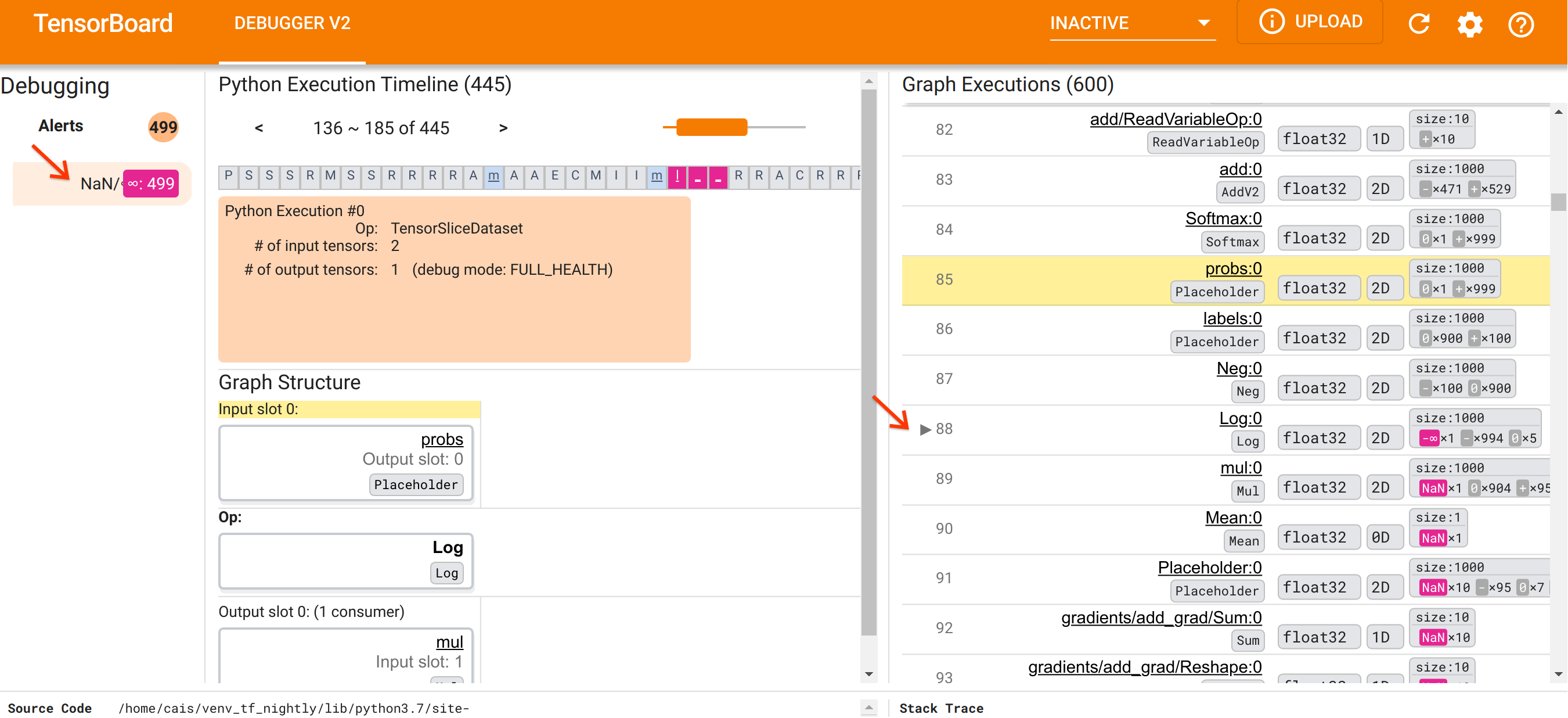
为什么这个 Log 操作会输出 -∞?回答这个问题需要检查操作的输入。单击张量名称(Log:0)会在“图结构”部分中显示一个简单但信息丰富的可视化,展示了 Log 操作在其 TensorFlow 图中的邻近区域。请注意信息流的从上到下的方向。操作本身以粗体显示在中间。在它正上方,我们可以看到一个占位符操作提供了 Log 操作的唯一输入。这个由 probs 占位符生成的张量在“图执行”列表中的位置在哪里?通过使用黄色背景色作为视觉辅助,我们可以看到 probs:0 张量位于 Log:0 张量上方三行,即第 85 行。
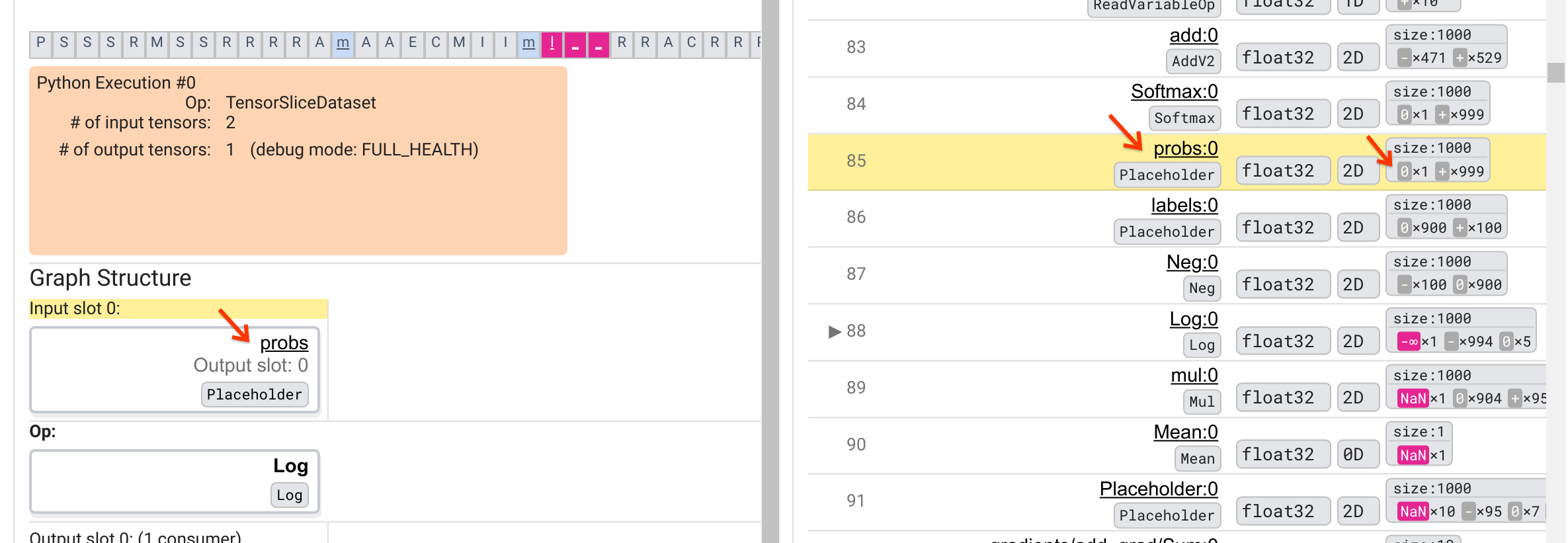
仔细查看第 85 行中 probs:0 张量的数值细分,可以发现其使用者 Log:0 产生 -∞ 的原因:在 probs:0 的 1000 个元素中,有一个元素的值为 0。-∞ 是计算 0 的自然对数的结果!如果我们能够以某种方式确保 Log 操作只接触到正输入,我们将能够阻止 NaN/∞ 的发生。这可以通过对占位符 probs 张量应用裁剪(例如,使用 tf.clip_by_value())来实现。
我们越来越接近解决这个 bug,但还没有完全完成。为了应用修复程序,我们需要知道 Log 操作及其占位符输入在 Python 源代码中的来源。调试器 V2 提供了对跟踪图操作和执行事件到其源代码的一流支持。当我们单击“图执行”中的 Log:0 张量时,“堆栈跟踪”部分将填充 Log 操作创建的原始堆栈跟踪。堆栈跟踪有点大,因为它包含 TensorFlow 内部代码(例如,gen_math_ops.py 和 dumping_callback.py)中的许多帧,对于大多数调试任务,我们可以安全地忽略这些帧。我们感兴趣的帧是 debug_mnist_v2.py 的第 216 行(即我们实际尝试调试的 Python 文件)。单击“第 216 行”会在“源代码”部分中显示相应代码行的视图。
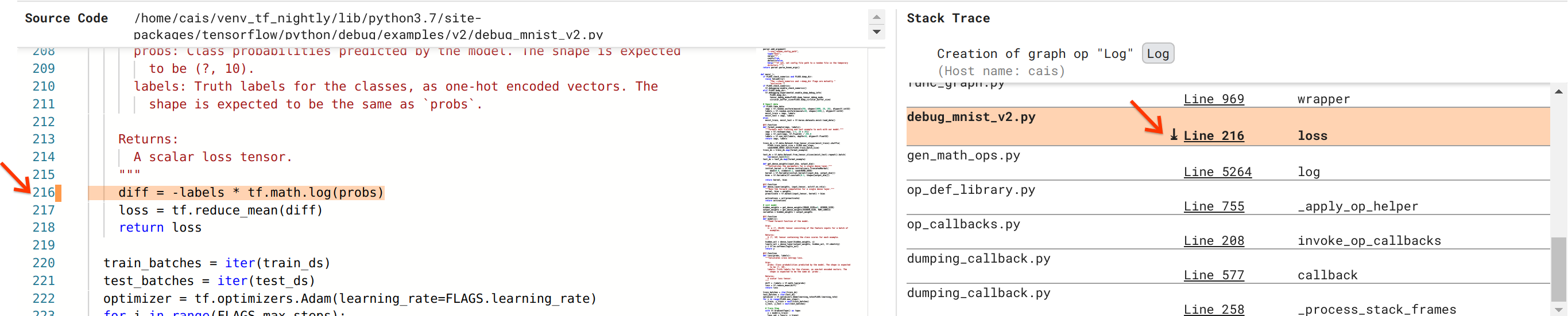
这最终将我们带到了从其 probs 输入创建有问题的 Log 操作的源代码。这是我们使用 @tf.function 装饰的自定义分类交叉熵损失函数,因此被转换为 TensorFlow 图。占位符操作 probs 对应于损失函数的第一个输入参数。Log 操作使用 tf.math.log() API 调用创建。
此 bug 的值裁剪修复程序将类似于
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
它将解决此 TF2 程序中的数值不稳定问题,并使 MLP 成功训练。解决数值不稳定问题的另一种方法是使用 tf.keras.losses.CategoricalCrossentropy。
这结束了我们从观察 TF2 模型 bug 到提出修复 bug 的代码更改的旅程,这得益于调试器 V2 工具的帮助,该工具提供了对已插桩 TF2 程序的急切和图执行历史记录的完整可见性,包括张量值的数值摘要以及操作、张量及其原始源代码之间的关联。
调试器 V2 的硬件兼容性
调试器 V2 支持主流训练硬件,包括 CPU 和 GPU。还支持使用 tf.distributed.MirroredStrategy 进行的多 GPU 训练。对 TPU 的支持仍处于早期阶段,需要调用
tf.config.set_soft_device_placement(True)
在调用 enable_dump_debug_info() 之前。它也可能在 TPU 上存在其他限制。如果您在使用调试器 V2 时遇到问题,请在我们的 GitHub 问题页面 上报告 bug。
调试器 V2 的 API 兼容性
调试器 V2 在 TensorFlow 软件堆栈的较低级别实现,因此与 tf.keras、tf.data 以及构建在 TensorFlow 较低级别之上的其他 API 兼容。调试器 V2 还向后兼容 TF1,尽管对于 TF1 程序生成的调试日志目录,急切执行时间线将为空。
API 使用技巧
关于此调试 API 的一个常见问题是,应该在 TensorFlow 代码中的哪个位置插入对 enable_dump_debug_info() 的调用。通常,应该尽早地在您的 TF2 程序中调用此 API,最好是在 Python 导入行之后,并在图构建和执行开始之前。这将确保完全覆盖为您的模型及其训练提供动力的所有操作和图。
当前支持的 tensor_debug_modes 为:NO_TENSOR、CURT_HEALTH、CONCISE_HEALTH、FULL_HEALTH 和 SHAPE。它们在从每个张量中提取的信息量以及对调试程序的性能开销方面有所不同。请参阅 args 部分 中 enable_dump_debug_info() 的文档。
性能开销
调试 API 会对已插桩的 TensorFlow 程序引入性能开销。开销会因 tensor_debug_mode、硬件类型以及已插桩 TensorFlow 程序的性质而异。作为参考点,在 GPU 上,NO_TENSOR 模式在批次大小为 64 的情况下,在训练 Transformer 模型 期间增加了 15% 的开销。其他 tensor_debug_modes 的百分比开销更高:CURT_HEALTH、CONCISE_HEALTH、FULL_HEALTH 和 SHAPE 模式的开销约为 50%。在 CPU 上,开销略低。在 TPU 上,开销目前更高。
与其他 TensorFlow 调试 API 的关系
请注意,TensorFlow 提供了其他用于调试的工具和 API。您可以在 API 文档页面上的 tf.debugging.* 命名空间 下浏览这些 API。在这些 API 中,最常使用的是 tf.print()。何时应该使用调试器 V2,何时应该改用 tf.print()?tf.print() 在以下情况下很方便
- 我们确切地知道要打印哪些张量,
- 我们确切地知道在源代码中的哪个位置插入这些
tf.print()语句, - 此类张量的数量不多。
对于其他情况(例如,检查许多张量值、检查由 TensorFlow 内部代码生成的张量值以及搜索数值不稳定的来源,如我们上面所示),调试器 V2 提供了一种更快的调试方法。此外,调试器 V2 提供了一种统一的方法来检查急切和图张量。它还提供有关图结构和代码位置的信息,这些信息超出了 tf.print() 的能力。
另一个可用于调试涉及 ∞ 和 NaN 的问题的 API 是 tf.debugging.enable_check_numerics()。与 enable_dump_debug_info() 不同,enable_check_numerics() 不会将调试信息保存到磁盘。相反,它只是在 TensorFlow 运行时监控 ∞ 和 NaN,并在任何操作生成此类错误数值时立即出错,并提供源代码位置。与 enable_dump_debug_info() 相比,它的性能开销更低,但它不提供程序执行历史记录的完整跟踪,也不像调试器 V2 那样提供图形用户界面。