
概述
TensorBoard 的主要功能是其交互式 GUI。但是,用户有时希望**以编程方式**读取存储在 TensorBoard 中的数据日志,以进行事后分析和创建日志数据的自定义可视化等目的。
TensorBoard 2.3 通过tensorboard.data.experimental.ExperimentFromDev()支持此用例。它允许以编程方式访问 TensorBoard 的标量日志。此页面演示了此新 API 的基本用法。
设置
为了使用以编程方式的 API,请确保您除了tensorboard之外还安装了pandas。
在本指南中,我们将使用matplotlib和seaborn进行自定义绘图,但您可以选择自己喜欢的工具来分析和可视化DataFrame。
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
将 TensorBoard 标量加载为pandas.DataFrame
将 TensorBoard 日志目录上传到 TensorBoard.dev 后,它将成为我们所说的实验。每个实验都有一个唯一的 ID,可以在实验的 TensorBoard.dev URL 中找到。在下面的演示中,我们将使用 TensorBoard.dev 上的实验:https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df是一个pandas.DataFrame,其中包含实验的所有标量日志。
DataFrame的列为
run:每个运行对应于原始日志目录的子目录。在此实验中,每个运行都来自在 MNIST 数据集上使用给定优化器类型(训练超参数)对卷积神经网络 (CNN) 进行完整训练。此DataFrame包含多个此类运行,这些运行对应于在不同优化器类型下重复的训练运行。tag:这描述了同一行中的value的含义,即该行中的值代表什么指标。在此实验中,我们只有两个唯一的标签:epoch_accuracy和epoch_loss,分别代表准确率和损失指标。step:这是一个数字,反映了对应行在其运行中的序列顺序。这里step实际上指的是纪元数。如果您希望除了step值之外还获取时间戳,则可以在调用get_scalars()时使用关键字参数include_wall_time=True。value:这是感兴趣的实际数值。如上所述,此特定DataFrame中的每个value都是损失或准确率,具体取决于该行的tag。
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
获取透视(宽格式)DataFrame
在我们的实验中,两个标签(epoch_loss和epoch_accuracy)在每个运行中的同一组步骤中存在。这使得可以通过使用pivot=True关键字参数直接从get_scalars()获取“宽格式”DataFrame成为可能。宽格式DataFrame将所有标签都包含为 DataFrame 的列,这在某些情况下(包括这种情况)更方便使用。
但是,请注意,如果所有运行中所有标签的步骤值集不一致,则使用pivot=True会导致错误。
dfw = experiment.get_scalars(pivot=True)
dfw
请注意,宽格式 DataFrame 包含两个标签(指标)作为其列,而不是单个“value”列:epoch_accuracy和epoch_loss。
将 DataFrame 另存为 CSV
pandas.DataFrame与CSV具有良好的互操作性。您可以将其存储为本地 CSV 文件,并在以后重新加载。例如
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
执行自定义可视化和统计分析
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
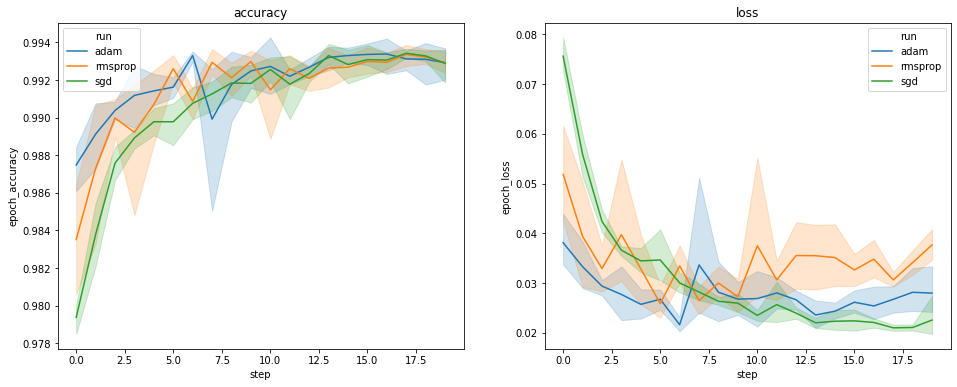
上面的绘图显示了验证准确率和验证损失的时间过程。每条曲线显示了在优化器类型下 5 次运行的平均值。由于seaborn.lineplot()的内置功能,每条曲线还显示了平均值的 ±1 标准差,这让我们清楚地了解了这些曲线的可变性以及三种优化器类型之间差异的显著性。TensorBoard GUI 尚未支持这种可变性可视化。
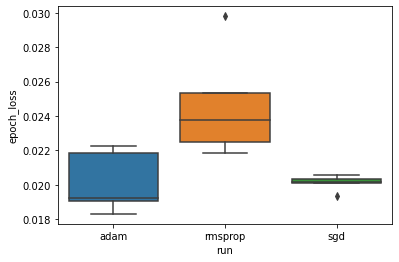
我们想研究以下假设:在“adam”、“rmsprop”和“sgd”优化器之间,最小验证损失存在显著差异。因此,我们提取了每个优化器下最小验证损失的 DataFrame。
然后,我们制作箱线图来可视化最小验证损失的差异。
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
因此,在 0.05 的显著性水平下,我们的分析证实了我们的假设,即与我们实验中包含的其他两种优化器相比,rmsprop 优化器的最小验证损失显著更高(即更差)。
总之,本教程提供了一个示例,说明如何从 TensorBoard.dev 访问标量数据作为 panda.DataFrame。它展示了使用 DataFrame 可以进行的灵活而强大的分析和可视化操作。